【集合系列】- 深入浅出的分析IdentityHashMap
作者:炸鸡可乐
原文出处:www.pzblog.cn
一、摘要
在集合系列的第一章,咱们了解到,Map 的实现类有 HashMap、LinkedHashMap、TreeMap、IdentityHashMap、WeakHashMap、Hashtable、Properties等等。

应该有很多人不知道 IdentityHashMap 的存在,其中不乏工作很多年的 Java 开发者,本文主要从数据结构和算法层面,探讨 IdentityHashMap 的实现。
二、简介
IdentityHashMap 的数据结构很简单,底层实际就是一个 Object 数组,但是在存储上并没有使用链表来存储,而是将 K 和 V 都存放在 Object 数组上。

当添加元素的时候,会根据 Key 计算得到散列位置,如果发现该位置上已经有改元素,直接进行新值替换;如果没有,直接进行存放。当元素个数达到一定阈值时,Object 数组会自动进行扩容处理。
打开 IdentityHashMap 的源码,可以看到 IdentityHashMap 继承了AbstractMap 抽象类,实现了Map接口、可序列化接口、可克隆接口。
public class IdentityHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, java.io.Serializable, Cloneable
{
/**默认容量大小*/
private static final int DEFAULT_CAPACITY = 32;
/**最小容量*/
private static final int MINIMUM_CAPACITY = 4;
/**最大容量*/
private static final int MAXIMUM_CAPACITY = 1 << 29;
/**用于存储实际元素的表*/
transient Object[] table;
/**数组大小*/
int size;
/**对Map进行结构性修改的次数*/
transient int modCount;
/**key为null所对应的值*/
static final Object NULL_KEY = new Object();
......
}
可以看到类的底层,使用了一个 Object 数组来存放元素;在对象初始化时,IdentityHashMap 容量大小为64;
public IdentityHashMap() {
//调用初始化方法
init(DEFAULT_CAPACITY);
}
private void init(int initCapacity) {
//数组大小默认为初始化容量的2倍
table = new Object[2 * initCapacity];
}
三、常用方法介绍
3.1、put方法
put 方法是将指定的 key, value 对添加到 map 里。该方法首先会对map做一次查找,通过==判断是否存在key,如果有,则将旧value返回,将新value覆盖旧value;如果没有,直接插入,数组长度+1,返回null。
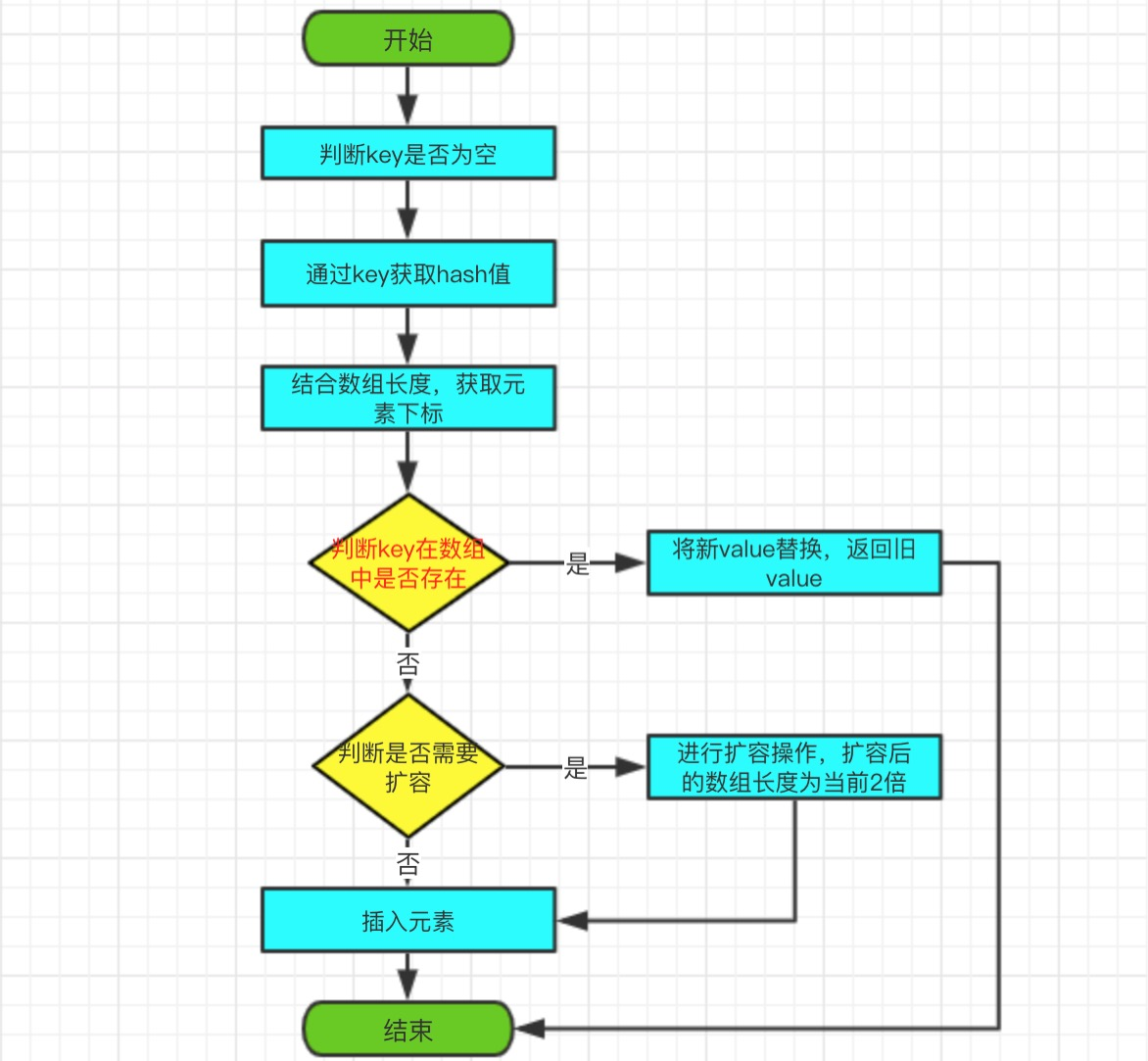
源码如下:
public V put(K key, V value) {
//判断key是否为空,如果为空,初始化一个Object为key
final Object k = maskNull(key);
retryAfterResize: for (;;) {
final Object[] tab = table;
final int len = tab.length;
//通过key、length获取数组小编
int i = hash(k, len);
//循环遍历是否存在指定的key
for (Object item; (item = tab[i]) != null;
i = nextKeyIndex(i, len)) {
//通过==判断,是否数组中是否存在key
if (item == k) {
V oldValue = (V) tab[i + 1];
//新value覆盖旧value
tab[i + 1] = value;
//返回旧value
return oldValue;
}
}
//数组长度 +1
final int s = size + 1;
//判断是否需要扩容
if (s + (s << 1) > len && resize(len))
continue retryAfterResize;
//更新修改次数
modCount++;
//将k加入数组
tab[i] = k;
//将value加入数组
tab[i + 1] = value;
size = s;
return null;
}
}
maskNull 函数,判断 key 是否为空
private static Object maskNull(Object key) {
return (key == null ? NULL_KEY : key);
}
hash 函数,通过 key 获取 hash 值,结合数组长度通过位运算获取数组散列下标
private static int hash(Object x, int length) {
int h = System.identityHashCode(x);
// Multiply by -127, and left-shift to use least bit as part of hash
return ((h << 1) - (h << 8)) & (length - 1);
}
nextKeyIndex 函数,通过 hash 函数计算得到的数组散列下标,进行加2;因为一个 key、value 都存放在数组中,所以一个 map 对象占用两个数组下标,所以加2。
private static int nextKeyIndex(int i, int len) {
return (i + 2 < len ? i + 2 : 0);
}
resize 函数,通过数组长度,进行扩容处理,扩容之后的长度为当前长度的2倍
private boolean resize(int newCapacity) {
//扩容后的数组长度,为当前数组长度的2倍
int newLength = newCapacity * 2;
Object[] oldTable = table;
int oldLength = oldTable.length;
if (oldLength == 2 * MAXIMUM_CAPACITY) { // can't expand any further
if (size == MAXIMUM_CAPACITY - 1)
throw new IllegalStateException("Capacity exhausted.");
return false;
}
if (oldLength >= newLength)
return false;
Object[] newTable = new Object[newLength];
//将旧数组内容转移到新数组
for (int j = 0; j < oldLength; j += 2) {
Object key = oldTable[j];
if (key != null) {
Object value = oldTable[j+1];
oldTable[j] = null;
oldTable[j+1] = null;
int i = hash(key, newLength);
while (newTable[i] != null)
i = nextKeyIndex(i, newLength);
newTable[i] = key;
newTable[i + 1] = value;
}
}
table = newTable;
return true;
}
3.2、get方法
get 方法根据指定的 key 值返回对应的 value。同样的,该方法会循环遍历数组,通过==判断是否存在key,如果有,直接返回value,因为 key、value 是相邻的存储在数组中,所以直接在当前数组下标+1,即可获取 value;如果没有找到,直接返回null。
值得注意的地方是,在循环遍历中,是通过==判断当前元素是否与key相同,如果相同,则返回value。咱们都知道,在 java 中,==对于对象类型参数,判断的是引用地址,确切的说,是堆内存地址,所以,这里判断的是key的引用地址是否相同,如果相同,则返回对应的 value;如果不相同,则返回null。
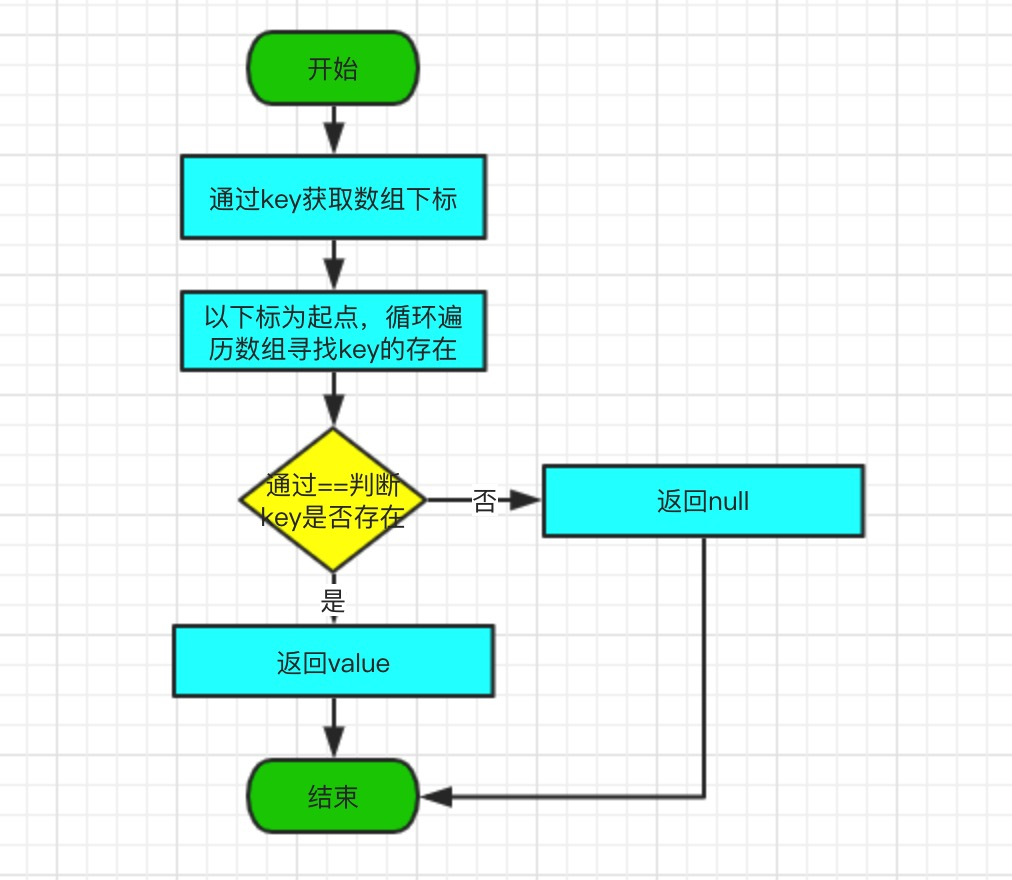
源码如下:
public V get(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
//循环遍历数组,直到找到key或者,数组为空为值
while (true) {
Object item = tab[i];
//通过==判断,当前数组元素与key相同
if (item == k)
return (V) tab[i + 1];
//数组为空
if (item == null)
return null;
i = nextKeyIndex(i, len);
}
}
3.3、remove方法
remove 的作用是通过 key 删除对应的元素。该方法会循环遍历数组,通过==判断是否存在key,如果有,直接将key、value设置为null,对数组进行重新排列,返回旧 value。
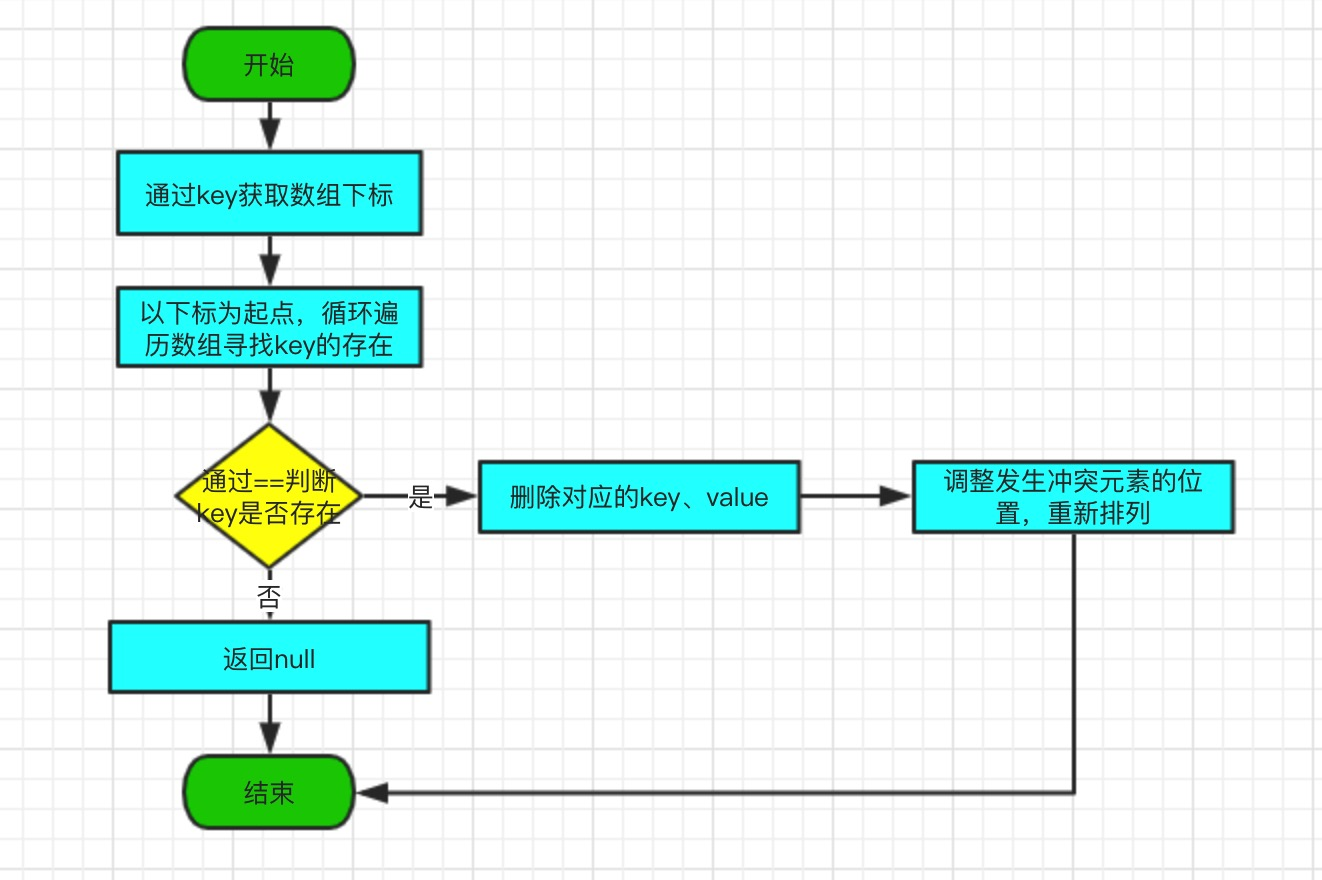
源码如下:
public V remove(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
while (true) {
Object item = tab[i];
if (item == k) {
modCount++;
//数组长度减1
size--;
V oldValue = (V) tab[i + 1];
//将key、value设置为null
tab[i + 1] = null;
tab[i] = null;
//删除该元素后,需要把原来有冲突往后移的元素移到前面来
closeDeletion(i);
return oldValue;
}
if (item == null)
return null;
i = nextKeyIndex(i, len);
}
}
closeDeletion 函数,删除该元素后,需要把原来有冲突往后移的元素移到前面来,对数组进行重写排列;
private void closeDeletion(int d) {
// Adapted from Knuth Section 6.4 Algorithm R
Object[] tab = table;
int len = tab.length;
Object item;
for (int i = nextKeyIndex(d, len); (item = tab[i]) != null;
i = nextKeyIndex(i, len) ) {
int r = hash(item, len);
if ((i < r && (r <= d || d <= i)) || (r <= d && d <= i)) {
tab[d] = item;
tab[d + 1] = tab[i + 1];
tab[i] = null;
tab[i + 1] = null;
d = i;
}
}
}
四、总结
IdentityHashMap的实现不同于HashMap,虽然也是数组,不过IdentityHashMap中没有用到链表,解决冲突的方式是计算下一个有效索引,并且将数据key和value紧挨着存在map中,即table[i]=key、table[i+1]=value;IdentityHashMap允许key、value都为null,当key为null的时候,默认会初始化一个Object对象作为key;IdentityHashMap在保存、删除、查询数据的时候,以key为索引,通过==来判断数组中元素是否与key相同,本质判断的是对象的引用地址,如果引用地址相同,那么在插入的时候,会将value值进行替换;
IdentityHashMap 测试例子:
public static void main(String[] args) {
Map<String, String> identityMaps = new IdentityHashMap<String, String>();
identityMaps.put(new String("aa"), "aa");
identityMaps.put(new String("aa"), "bb");
identityMaps.put(new String("aa"), "cc");
identityMaps.put(new String("aa"), "cc");
//输出添加的元素
System.out.println("数组长度:"+identityMaps.size() + ",输出结果:" + identityMaps);
}
输出结果:
数组长度:4,输出结果:{aa=aa, aa=cc, aa=bb, aa=cc}
尽管key的内容是一样的,但是key的堆地址都不一样,所以在插入的时候,插入了4条记录。
五、参考
1、JDK1.7&JDK1.8 源码
2、简书 - 骑着乌龟去看海 - IdentityHashMap源码解析
3、博客园 - leesf - IdentityHashMap源码解析
【集合系列】- 深入浅出的分析IdentityHashMap的更多相关文章
- 【集合系列】- 深入浅出的分析TreeMap
一.摘要 在集合系列的第一章,咱们了解到,Map的实现类有HashMap.LinkedHashMap.TreeMap.IdentityHashMap.WeakHashMap.Hashtable.Pro ...
- 【集合系列】- 深入浅出的分析 Hashtable
一.摘要 在集合系列的第一章,咱们了解到,Map 的实现类有 HashMap.LinkedHashMap.TreeMap.IdentityHashMap.WeakHashMap.Hashtable.P ...
- 【集合系列】- 深入浅出分析HashMap
一.摘要 在集合系列的第一章,咱们了解到,Map的实现类有HashMap.LinkedHashMap.TreeMap.IdentityHashMap.WeakHashMap.Hashtable.Pro ...
- 【集合系列】- 深入浅出分析LinkedHashMap
一.摘要 在集合系列的第一章,咱们了解到,Map的实现类有HashMap.LinkedHashMap.TreeMap.IdentityHashMap.WeakHashMap.Hashtable.Pro ...
- 【集合系列】- 深入浅出的分析 WeakHashMap
一.摘要 在集合系列的第一章,咱们了解到,Map 的实现类有 HashMap.LinkedHashMap.TreeMap.IdentityHashMap.WeakHashMap.Hashtable.P ...
- 【集合系列】- 深入浅出的分析 Properties
一.摘要 在集合系列的第一章,咱们了解到,Map 的实现类有 HashMap.LinkedHashMap.TreeMap.IdentityHashMap.WeakHashMap.Hashtable.P ...
- 【集合系列】- 深入浅出的分析 Set集合
一.摘要 关于 Set 接口,在实际开发中,其实很少用到,但是如果你出去面试,它可能依然是一个绕不开的话题. 言归正传,废话咱们也不多说了,相信使用过 Set 集合类的朋友都知道,Set集合的特点主要 ...
- 【集合系列】- 深入浅出分析 ArrayDeque
一.摘要 在 jdk1.5 中,新增了 Queue 接口,代表一种队列集合的实现,咱们继续来聊聊 java 集合体系中的 Queue 接口. Queue 接口是由大名鼎鼎的 Doug Lea 创建,中 ...
- Java 集合系列08之 List总结(LinkedList, ArrayList等使用场景和性能分析)
概要 前面,我们学完了List的全部内容(ArrayList, LinkedList, Vector, Stack). Java 集合系列03之 ArrayList详细介绍(源码解析)和使用示例 Ja ...
随机推荐
- redis之PubSub
前面我们讲了 Redis 消息队列的使用方法,但是没有提到 Redis 消息队列的不足之处,那就是它不支持消息的多播机制. 消息多播 消息多播允许生产者生产一次消息,中间件负责将消息复制到多个消息队列 ...
- day04整理
目录 内容回顾 变量 什么是变量 变量的组成 变量名的命名规范 注释 单行注释 多行注释 turtle库的使用 一.数据类型基础 一.数字类型 (一)整形 (二)浮点型 二.字符串类型 (一)作用:姓 ...
- IDEA配置tomcat报错
昨晚想Eclipse转IDEA,谁知道在tomcat就卡住了,难受.今天一下就解决了,记录一下(没有保存错误信息的截图[/敲打]). 问题描述: 运行的时候tomcat卡在Deployment of ...
- RESTFul API最佳实践
RESTful API最佳实践 RESTful API 概述 基本概念 REST 英文全称:Representational State Transfer,直译为:表现层状态转移.首次是由Roy Th ...
- PHP获取当前时间
PHP获取系统当前时间,有date()可以使用. 但date()当前系统时间是格林威治时间,比我们所在的时区晚了整整8个小时.以前处理这个问题时,只是简单的把获取的当前系统的时间戳加上8个小时的时间, ...
- 学习笔记03http协议
1.浏览器就是一个sokect客户端,使用http协议与服务器进行交流.http请求:请求头:(请求方法)sp(url)sp http/1.x <cr><lf>(通用头类型名) ...
- Go 程序的性能监控与分析 pprof
你有没有考虑过,你的goroutines是如何被go的runtime系统调度的?是否尝试理解过为什么在程序中增加了并发,但并没有给它带来更好的性能?go执行跟踪程序可以帮助回答这些疑问,还有其他和其有 ...
- CSPS模拟 67
炸分炸的厉害.(当然这跟b哥定律无关 话说好久没人嘲笑我菜了,快飘的不知道到哪了. 谁能讽我两句我不要面子的. 另外在博客上写些没用的东西好浪费精力啊我又不想当网红 主要是考试的时候心态不稳. 以为T ...
- bzoj1004 card
明知是burnside然而根本不会然后无耻地颓了题解后一脸傻气的我: 直接套公式???为啥方案数==等价类数量啊??? skyh:显然啊(狂笑)(hey wxy!他问为啥方案书等于等价类数量!) wx ...
- 通过ISO镜像简单搭建本地yum仓库
本文参考链接:https://segmentfault.com/a/1190000015155966 *有时候在我们本地搭建一些Linux上的程序运行环境或者安装一些软件的时候,难免会遇到需要使用yu ...