(转)Polynomial interpolation 多项式插值
This example demonstrates how to approximate a function with a polynomial of degree n_degree by using ridge regression. Concretely, from n_samples 1d points, it suffices to build the Vandermonde matrix, which is n_samples x n_degree+1 and has the following form:
这个例子演示了如何用岭回归去近似一个函数用n_degree级的多项式级数。具体而言,从n_samples 1d个点,这满足去建立一个范德蒙德矩阵,有n_samples行,n_degree+1列。有如下的形式:
[[1,x1,x1∗∗2,x1∗∗3,…],[1,x2,x2∗∗2,x2∗∗3,…],…][[1,x1,x1∗∗2,x1∗∗3,…],[1,x2,x2∗∗2,x2∗∗3,…],…] [[1, x_1, x_1 ** 2, x_1 ** 3, …], \\ [1, x_2, x_2 ** 2, x_2 ** 3, …], …] [[1,x1,x1∗∗2,x1∗∗3,…],[1,x2,x2∗∗2,x2∗∗3,…],…]
Intuitively, this matrix can be interpreted as a matrix of pseudo features (the points raised to some power). The matrix is akin to (but different from) the matrix induced by a polynomial kernel.
直觉上来说,这个矩阵可以被理解为伪特征的矩阵。这些点提升到能量。
这个矩阵类似于(但不同于) 多项式核生成的矩阵。
This example shows that you can do non-linear regression with a linear model, using a pipeline to add non-linear features. Kernel methods extend this idea and can induce very high (even infinite) dimensional feature spaces.
这个例子显示,你可以用线性模型做非线性回归,通过管道来添加非线性特征。核方法扩展了这个想法,可以导出非常高维的(甚至是无限维)的特征空间。
实验过程
- 注意:
- 这里是用高阶多项式来进行岭回归
- 本质上不是我们日常所说的插值,因为插值点其实并不在对应的位置上。
- 这里说的特征,在其实在fit之前只有一个多项式作为了特征。后面说到了这里采用的是岭回归。
# %pylab inline
# 如果是jupyter notebook就把上面一行注释去掉~
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
def f(x):
""" function to approximate by polynomial interpolation"""
return x * np.sin(x)
# generate points used to plot
x_plot = np.linspace(0, 10, 100)
# 随机获取20个插值点
# generate points and keep a subset of them
x = np.linspace(0, 10, 100) # 生成100个数据
rng = np.random.RandomState(0)
rng.shuffle(x) # 随机打乱这个数据
x = np.sort(x[:20]) # 将前20个数据排序
y = f(x) # 放入f之中,获取散点的值
# create matrix versions of these arrays
X = x[:, np.newaxis] # 将该数据提高一个维度
X_plot = x_plot[:, np.newaxis]
colors = ['teal', 'yellowgreen', 'gold'] # 颜色集合
lw = 2 # 线宽度
# 真实数据所构成的曲线
plt.plot(x_plot, f(x_plot), color='cornflowerblue', linewidth=lw,
label="ground truth")
# 散点图,描出插值点
plt.scatter(x, y, color='navy', s=30, marker='o', label="training points")
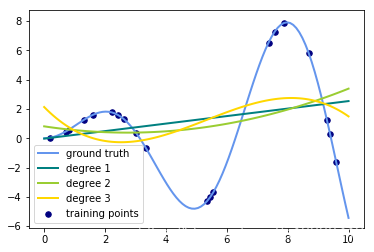
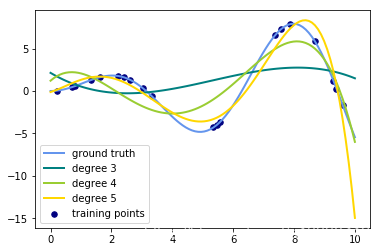
for count, degree in enumerate([3, 4, 5]):
# 用degree的多项式特征结合上岭回归放入到管道之中构建模型
model = make_pipeline(PolynomialFeatures(degree), Ridge())
# print(model)
model.fit(X, y) # 训练模型
y_plot = model.predict(X_plot) # 做出预测
# 描绘出插值曲线
plt.plot(x_plot, y_plot, color=colors[count], linewidth=lw,
label="degree %d" % degree)
plt.legend(loc='lower left')
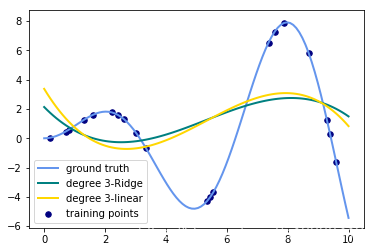
plt.show()将for循环部分改成这样子:
for count, degree in enumerate([3]):
# 用degree的多项式特征结合上岭回归放入到管道之中构建模型
model = make_pipeline(PolynomialFeatures(degree), Ridge())
model.fit(X, y) # 训练模型
y_plot = model.predict(X_plot) # 做出预测
# 描绘出插值曲线
plt.plot(x_plot, y_plot, color=colors[count], linewidth=lw,
label="degree %d-Ridge" % degree)
model = make_pipeline(PolynomialFeatures(degree), LinearRegression())
model.fit(X, y) # 训练模型
y_plot = model.predict(X_plot) # 做出预测
# 描绘出插值曲线
plt.plot(x_plot, y_plot, color=colors[len(colors) - 1 - count], linewidth=lw,
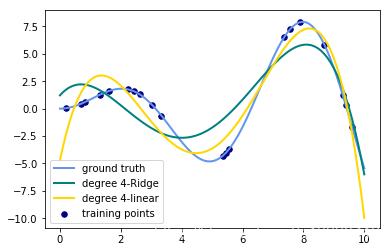
label="degree %d-linear" % degree)输出的图像为:(只需要将数值从3改成其他degree就可以生成其他图片了)
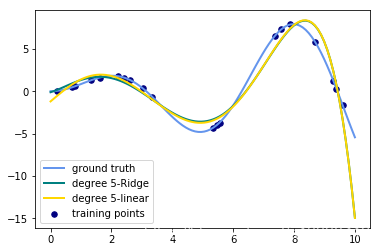
思考
- 观察:会发现岭回归的结果会线性回归的结果稍显波动小些。
- 回答:岭回归多加了一个L2的范数 约束了多项式特征的w的大小。
(转)Polynomial interpolation 多项式插值的更多相关文章
- 多项式函数插值:全域多项式插值(一)单项式基插值、拉格朗日插值、牛顿插值 [MATLAB]
全域多项式插值指的是在整个插值区域内形成一个多项式函数作为插值函数.关于多项式插值的基本知识,见“计算基本理论”. 在单项式基插值和牛顿插值形成的表达式中,求该表达式在某一点处的值使用的Horner嵌 ...
- 【转载】interpolation(插值)和 extrapolation(外推)的区别
根据已有数据以及模型(函数)预测未知区域的函数值,预测的点在已有数据范围内就是interpolation(插值), 范围外就是extrapolation(外推). The Difference Bet ...
- codeforces 955F Cowmpany Cowmpensation 树上DP+多项式插值
给一个树,每个点的权值为正整数,且不能超过自己的父节点,根节点的最高权值不超过D 问一共有多少种分配工资的方式? 题解: A immediate simple observation is that ...
- 【Codechef】Chef and Bike(二维多项式插值)
something wrong with my new blog! I can't type matrixs so I come back. qwq 题目:https://www.codechef.c ...
- 整数拆分 [dp+多项式插值]
题意 $1 \leq n \leq 10^{18}$ $2 \leq m \leq 10^{18}$ $1 \leq k \leq 20$ 思路 n,m较小 首先考虑朴素的$k=1$问题: $f[i] ...
- 数值计算方法实验之newton多项式插值 (Python 代码)
一.实验目的 在己知f(x),x∈[a,b]的表达式,但函数值不便计算或不知f(x),x∈[a,b]而又需要给出其在[a,b]上的值时,按插值原则f(xi)=yi (i=0,1,……, n)求出简单函 ...
- 数值计算方法实验之Hermite 多项式插值 (Python 代码)
一.实验目的 在已知f(x),x∈[a,b]的表达式,但函数值不便计算,或不知f(x),x∈[a,b]而又需要给出其在[a,b]上的值时,按插值原则f(xi)= yi(i= 0,1…….,n)求出简单 ...
- 数值计算方法实验之Newton 多项式插值(MATLAB代码)
一.实验目的 在己知f(x),x∈[a,b]的表达式,但函数值不便计算或不知f(x),x∈[a,b]而又需要给出其在[a,b]上的值时,按插值原则f(xi)=yi (i=0,1,……, n)求出简单函 ...
- 数值计算方法实验之Lagrange 多项式插值 (Python 代码)
一.实验目的 在已知f(x),x∈[a,b]的表达式,但函数值不便计算,或不知f(x),x∈[a,b]而又需要给出其在[a,b]上的值时,按插值原则f(xi)= yi(i= 0,1…….,n)求出简单 ...
随机推荐
- ES6对数组的扩展(简要总结)
文章目录 数组的扩展(ES6) 1. 扩展运算符 2. Array.from 3. Array.of() 4. copyWithin() 5. find() 和 findIndex() 6. fill ...
- excel中生成32位随机id
记录下如何在EXCEL中利用公式生成32位的随机id(无符号,只有数字和小写字母). ,,)),),"",DEC2HEX(RANDBETWEEN(,,)),),"&quo ...
- python GUI编程tkinter示例之目录树遍历工具
摘录 python核心编程 本节我们将展示一个中级的tkinter应用实例,这个应用是一个目录树遍历工具:它会从当前目录开始,提供一个文件列表,双击列表中任意的其他目录,就会使得工具切换到新目录中,用 ...
- 使用 Docker 和 Nginx 打造高性能的二维码服务
使用 Docker 和 Nginx 打造高性能的二维码服务 本文将演示如何使用 Docker 完整打造一个基于 Nginx 的高性能二维码服务,以及对整个服务镜像进行优化的方法.如果你的网络状况良好, ...
- git 版本检出checkout的方法笔记
想检出指定版本,比如回退版本,将代码检出到老代码 git checkout 版本号 git reflog git checkout 标签名 1.git log 查看版本信息,复制版本号,执行git ...
- 【原创】你的Redis怎么持久化的
引言 (本文改编自生活真实案例,如有类同,绝不是巧合!) 端午节,烟哥正在一边愉快的学习.... 突然,微信一阵抖动.原来是老刘呼唤烟哥!善良的烟哥本以为人家是要约我出去玩!然而,打开微信一看,出现下 ...
- 局域网地址为什么是192.168.X.X?为什么连上公司的VPN就上不了网?
注:本文主要目的是给程序员讲述一些局域网/VPN的基本知识,并不涉及到具体的实操.关于如何安装VPN服务器.配置VPN客户端及修改Windows路由表等具体实操内容,请自行搜索. RFC 局域网地址为 ...
- CMake工程找不到相应的cuDNN版本的问题
(1) 去官网下载相应的版本,因为电脑之前安装的是 CUDA8. ,找跟 CUDA 版本兼容的 cuDNN 下载即可,我选择的是 cuDNN v7.(Deb) 和 cuDNN v7.1.4 Deve ...
- git clone 仓库的部分代码
对于较大的代码仓库来说,如果只是想查看和学习其中部分源代码,选择性地下载部分路径中的代码就显得很实用了,这样可以节省大量等待时间. 比如像 Chromium 这种,仓库大小好几 G 的. clone ...
- centos安装go环境
centos安装go环境 1,下载合适的go安装包 https://studygolang.com/dl 2 上传到 centos服务器的 /usr/local下然后解压 3.设置go的环境变量 ...