xpath beautiful pyquery三种解析库
这两天看了一下python常用的三种解析库,写篇随笔,整理一下思路。太菜了,若有错误的地方,欢迎大家随时指正。。。。。。。(come on.......)
爬取网页数据一般会经过 获取信息->提取信息->保存信息 这三个步骤。而解析库的使用,则可以帮助我们快速的提取出我们需要的那被部分信息,免去了写复杂的正则表达式的麻烦。在使用解析库的时候,个人理解也会有三个步骤 建立文档树->搜索文档树->获取属性和文本 。
建立文档树:就是把我们获取到的网页源码利用解析库进行解析,只有这样,后面才能使用这个解析库的方法。
搜索文档树:就是在已经建立的文档树里面,利用标签的属性,搜索出我们需要的那部分信息,比如一个包含一部分网页内容的div标签,一个ul标签等。
获取索性和文本:在上一步的基础上,进一步获取到具体某个标签的文本或属性,比如一个a标签的href属性,title属性,或它的文本。
首先,定义一个html的字符串,用它来模拟已经获取到的网页源码
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
xpath解析库:XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言。它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。
1.建立文档树:在获取到网页源码后,只需要使用etree的HTML方法,就可以把复杂的html建立成 一棵文档树了
from lxml import etree
xpath_tree = etree.HTML(html)
这里首先导入lxml库的etree模块,然后声明了一段HTML文本,调用HTML类进行初始化,这样就成功构造了一个XPath解析对象。可以使用type查看一下xpath_tree的类型,是这样的 <class 'lxml.etree._Element'>
2.搜索文档树:先看一下xpath几个常用的规则
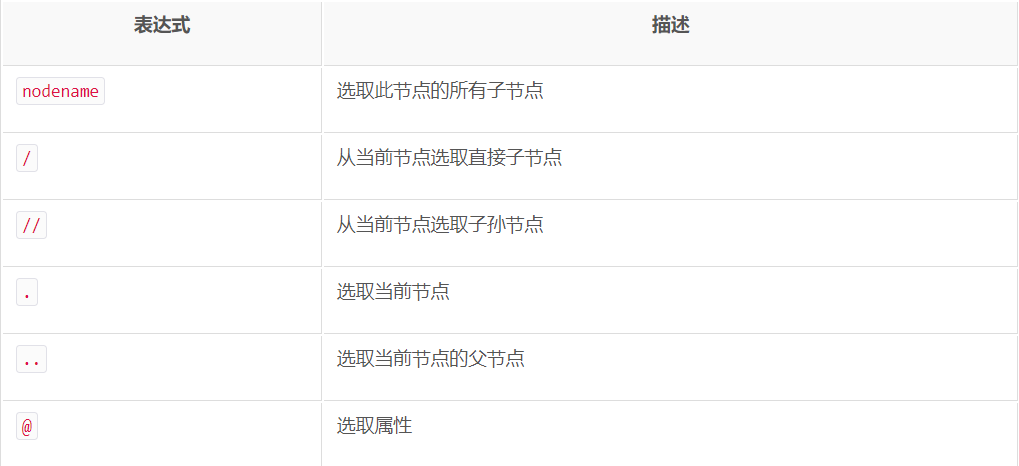
(1)从整个文档树中搜索标签:一般会用//开头的XPath规则来选取所有符合要求的节点。这里以前面的HTML文本为例。例如搜索 ul 标签
xpath_tree = etree.HTML(html)
result = xpath_tree.xpath('ul')
print(result)
print(type(result))
print(type(result[0])) 输出结果如下:
[<Element ul at 0x2322b7e8608>, <Element ul at 0x2322b7e8648>]
<class 'list'>
<class 'lxml.etree._Element'>
上面第二行代码表示从整个文档树中搜索出所有的ul标签,可以看到,返回结果是一个列表,里面的每个元素都是lxml.etree._Element类型,当然,也可以对这个列表进行一个遍历,然后对每个lxml.etree._Element对象进行操作。
(2)搜索当前节点的子节点:比如,找到每一个ul标签里面的 li 标签:
xpath_tree = etree.HTML(html)
result = xpath_tree.xpath('//ul')
for r in result:
li_list = r.xpath('./li')
print(li_list) 输出结果如下:
[<Element li at 0x23433127748>, <Element li at 0x23433127788>, <Element li at 0x23433127a88>, <Element li at 0x23433127988>, <Element li at 0x23433127ac8>]
[<Element li at 0x23433127cc8>, <Element li at 0x23433127d08>, <Element li at 0x23433127d48>, <Element li at 0x23433127d88>, <Element li at 0x23433127dc8>]
第四行代码表示,选取当前的这个ul标签,并获取到它里面的所有li标签。
(3)根据属性过滤:如果你需要根据标签的属性进行一个过滤,则可以这样来做
xpath_tree = etree.HTML(html)
result = xpath_tree.xpath('//ul')
for r in result:
li_list = r.xpath('./li[@class="item-0"]')
print(li_list) 输出结果如下:
[<Element li at 0x15c436695c8>, <Element li at 0x15c436698c8>]
[<Element li at 0x15c43669988>, <Element li at 0x15c436699c8>]
与之前的代码相比,旨在第四行的后面加了 [@class="item-0"] ,它表示找到当前ul标签下所有class属性值为item-0的li标签,当然,也可以在整个文档树搜索某个标签时,在标签后面加上某个属性,进行过滤,下面例子中有用到
(4)获取文本:获取具体某个标签的文本内容
xpath_tree = etree.HTML(html)
result = xpath_tree.xpath('//ul[@class="list"]')
for r in result:
li_list = r.xpath('./li[@class="item-0"]')
for li in li_list:
print(li.xpath('./text()')) 输出结果如下:
['first item']
[]
['first item']
[]
首先,在第二行的ul标签后面加了属性过滤,但因为两个ul标签的class属性值都是list,所以结果没加之前是一样的。然后又加了一个for循环,用来获取列表里面每一个元素的文本,因为第二个li标签里面没有文本内容,所以是空
(5)获取属性:获取具体某个标签的某个属性内容
xpath_tree = etree.HTML(html)
result = xpath_tree.xpath('//ul[@class="list"]')
for r in result:
li_list = r.xpath('./li[@class="item-0"]')
for li in li_list:
print(li.xpath('./@class')) 输出结果如下:
['item-0']
['item-0']
['item-0']
['item-0']
把第六行的text()方法换成@符号,并在后面加上想要的属性,就获取到了该属性的属性值。
这是xpath这个解析库基本的使用方法,也有一些没说到的地方,大家可以看一下静谧大佬的文章。https://cuiqingcai.com/5545.html
另外两个解析库,放在后面两篇随笔里面
beautifulsoup解析库:https://www.cnblogs.com/liangxiyang/p/11302525.html
pyquery解析库:https://www.cnblogs.com/liangxiyang/p/11303142.html
*************************不积跬步,无以至千里。*************************
xpath beautiful pyquery三种解析库的更多相关文章
- (最全)Xpath、Beautiful Soup、Pyquery三种解析库解析html 功能概括
一.Xpath 解析 xpath:是一种在XMl.html文档中查找信息的语言,利用了lxml库对HTML解析获取数据. Xpath常用规则: nodename :选取此节点的所有子节点 // : ...
- Qt中三种解析xml的方式
在下面的随笔中,我会根据xml的结构,给出Qt中解析这个xml的三种方式的代码.虽然,这个代码时通过调用Qt的函数实现的,但是,很多开源的C++解析xml的库,甚至很多其他语言解析xml的库,都和下面 ...
- JSON的三种解析方式
一.什么是JSON? JSON是一种取代XML的数据结构,和xml相比,它更小巧但描述能力却不差,由于它的小巧所以网络传输数据将减少更多流量从而加快速度. JSON就是一串字符串 只不过元素会使用特定 ...
- Android平台中实现对XML的三种解析方式
本文介绍在Android平台中实现对XML的三种解析方式. XML在各种开发中都广泛应用,Android也不例外.作为承载数据的一个重要角色,如何读写XML成为Android开发中一项重要的技能. 在 ...
- 爬虫的三种解析方式(正则解析, xpath解析, bs4解析)
一 : 正则解析 : 常用正则回顾: 单字符: . : 除换行符以外的所有字符 [] : [aoe] [a-w] 匹配集合中任意一个字符 \d : 数字 [0-9] \D : 非数字 \w : 非数字 ...
- 【Android学习】XML文本的三种解析方式(通过搭建本地的Web项目提供XML文件)
XML为一种可扩展的标记语言,是一种简单的数据存储语言,使用一系列简单的标记来描述. 一.SAX解析 即Simple API for XML,以事件的形式通知程序,对Xml进行解析. 1.首先在Web ...
- windows phone中三种解析XML的方法
需求如下, 项目需要将一段xml字符串中的信息提取出来 <?xml version=""1.0"" encoding=""UTF-8& ...
- python爬虫之数据的三种解析方式
一.正则解析 单字符: . : 除换行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一个字符 \d :数字 [0-9] \D : 非数字 \w :数字.字母.下划线.中文 \W : 非\ ...
- Python_XML的三种解析方法
什么是XML? XML 指可扩展标记语言(eXtensible Markup Language). XML 被设计用来传输和存储数据. XML是一套定义语义标记的规则,这些标记将文档分成许多部件并对这 ...
随机推荐
- java 获取客户端的ip地址
import javax.servlet.http.HttpServletRequest; import java.net.InetAddress; import java.net.UnknownHo ...
- 5分钟快速部署ownCloud私有云盘存储系统
ownCloud 是一个开源免费专业的私有云存储项目,它能帮你快速在个人电脑或服务器上架设一套专属的私有云文件同步网盘,可以像 Dropbox 那样实现文件跨平台同步.共享.版本控制.团队协作等等.o ...
- HTTP 学习笔记03
通用信息头 Cache-Control : no-cache(不缓存当前请求) [*] Connection:close(返回当前请求后立即断开)[*] Date:...(HTTP消息产生的时间) P ...
- [AI开发]目标跟踪之行为分析
基于视频结构化的应用中,目标在经过跟踪算法后,会得到一个唯一标识和它对应的运动轨迹,利用这两个数据我们可以做一些后续工作:测速(交通类应用场景).计数(交通类应用场景.安防类应用场景)以及行为检测(交 ...
- (转)Java 8 中的 Streams API 详解
为什么需要 Stream Stream 作为 Java 8 的一大亮点,它与 java.io 包里的 InputStream 和 OutputStream 是完全不同的概念.它也不同于 StAX 对 ...
- Design Principles (设计原则)
这是我在2018年4月写的英语演讲稿,可惜没人听得懂(实际上就没几个人在听). 文章的内容是我从此前做过的项目中总结出来的经验,从我们的寝室铃声入手,介绍了可扩展性.兼容性与可复用性等概念,最后提出良 ...
- 嵊州D4T2 硬币 有人来教教我吗!
嵊州D4T2 硬币 [问题描述] 卡拉赞的展览馆被入侵了. 展览馆是一条长长的通道,依次摆放着 n 个展柜(从西到东编号依次 为 1—n). 入侵者玛克扎尔在第 n 个展柜东边召唤了一个传送门,一共施 ...
- .NET Core 学习资料精选:入门
开源跨平台的.NET Core,还没上车的赶紧的,来不及解释了-- 本系列文章,主要分享一些.NET Core比较优秀的社区资料和微软官方资料.我进行了知识点归类,让大家可以更清晰的学习.NET Co ...
- SQL Server Form子查询、链接查询
所用数据表:用户,钱包,订单 一.from子查询 --查询钱包里金额大于30000 and User_ID = Users.ID) ) 二.链接查询 内连接(inner join)外连接(left/r ...
- 20190127-Orleans与SF小伙伴的部分问答
Orleans 怎么部署到服务器? 方式1:Orleans 服务端寄宿在Web应用中,将Web应用部署到服务器 方式2:通过SF/K8s部署到服务器 不同服务器上的谷仓和谷如何调配? 由Orleans ...