利用sklearn对多分类的每个类别进行指标评价
今天晚上,笔者接到客户的一个需要,那就是:对多分类结果的每个类别进行指标评价,也就是需要输出每个类型的精确率(precision),召回率(recall)以及F1值(F1-score)。
对于这个需求,我们可以用sklearn来解决,方法并没有难,笔者在此仅做记录,供自己以后以及读者参考。
我们模拟的数据如下:
y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海']
y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海']
其中y_true为真实数据,y_pred为多分类后的模拟数据。使用sklearn.metrics中的classification_report即可实现对多分类的每个类别进行指标评价。
示例的Python代码如下:
# -*- coding: utf-8 -*-
from sklearn.metrics import classification_report
y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海']
y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海']
t = classification_report(y_true, y_pred, target_names=['北京', '上海', '成都'])
print(t)
输出结果如下:
precision recall f1-score support
北京 0.75 0.75 0.75 4
上海 1.00 0.67 0.80 3
成都 0.50 0.67 0.57 3
accuracy 0.70 10
macro avg 0.75 0.69 0.71 10
weighted avg 0.75 0.70 0.71 10
需要注意的是,输出的结果数据类型为str,如果需要使用该输出结果,则可将该方法中的output_dict参数设置为True,此时输出的结果如下:
{'北京': {'precision': 0.75, 'recall': 0.75, 'f1-score': 0.75, 'support': 4},
'上海': {'precision': 1.0, 'recall': 0.6666666666666666, 'f1-score': 0.8, 'support': 3},
'成都': {'precision': 0.5, 'recall': 0.6666666666666666, 'f1-score': 0.5714285714285715, 'support': 3},
'accuracy': 0.7,
'macro avg': {'precision': 0.75, 'recall': 0.6944444444444443, 'f1-score': 0.7071428571428572, 'support': 10},
'weighted avg': {'precision': 0.75, 'recall': 0.7, 'f1-score': 0.7114285714285715, 'support': 10}}
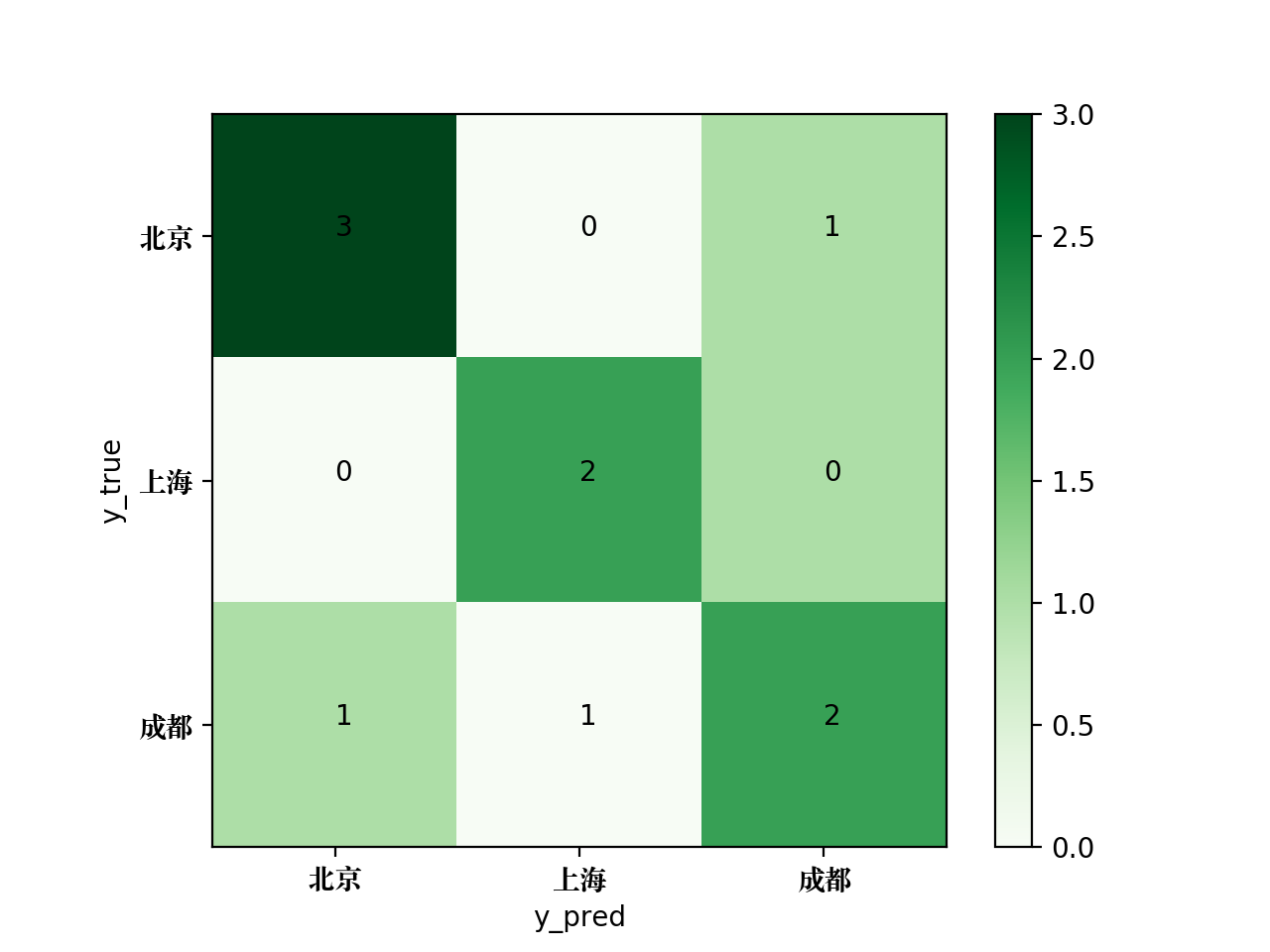
使用confusion_matrix方法可以输出该多分类问题的混淆矩阵,代码如下:
from sklearn.metrics import confusion_matrix
y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海']
y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海']
print(confusion_matrix(y_true, y_pred, labels = ['北京', '上海', '成都']))
输出结果如下:
[[2 0 1]
[0 3 1]
[0 1 2]]
为了将该混淆矩阵绘制成图片,可使用如下的Python代码:
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Daxing Beijing
# time: 2019-11-14 21:52
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import matplotlib as mpl
# 支持中文字体显示, 使用于Mac系统
zhfont=mpl.font_manager.FontProperties(fname="/Library/Fonts/Songti.ttc")
y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海']
y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海']
classes = ['北京', '上海', '成都']
confusion = confusion_matrix(y_true, y_pred)
# 绘制热度图
plt.imshow(confusion, cmap=plt.cm.Greens)
indices = range(len(confusion))
plt.xticks(indices, classes, fontproperties=zhfont)
plt.yticks(indices, classes, fontproperties=zhfont)
plt.colorbar()
plt.xlabel('y_pred')
plt.ylabel('y_true')
# 显示数据
for first_index in range(len(confusion)):
for second_index in range(len(confusion[first_index])):
plt.text(first_index, second_index, confusion[first_index][second_index])
# 显示图片
plt.show()
生成的混淆矩阵图片如下:
本次分享到此结束,感谢大家阅读,也感谢在北京大兴待的这段日子,当然还会再待一阵子~
利用sklearn对多分类的每个类别进行指标评价的更多相关文章
- 利用sklearn对MNIST手写数据集开始一个简单的二分类判别器项目(在这个过程中学习关于模型性能的评价指标,如accuracy,precision,recall,混淆矩阵)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 利用Sklearn实现加州房产价格预测,学习运用机器学习的整个流程(包含很多细节注解)
Chapter1_housing_price_predict .caret, .dropup > .btn > .caret { border-top-color: #000 !impor ...
- 利用sklearn实现k-means
基于上面的一篇博客k-means利用sklearn实现k-means #!/usr/bin/env python # coding: utf-8 # In[1]: import numpy as np ...
- 利用sklearn计算文本相似性
利用sklearn计算文本相似性,并将文本之间的相似度矩阵保存到文件当中.这里提取文本TF-IDF特征值进行文本的相似性计算. #!/usr/bin/python # -*- coding: utf- ...
- sklearn CART决策树分类
sklearn CART决策树分类 决策树是一种常用的机器学习方法,可以用于分类和回归.同时,决策树的训练结果非常容易理解,而且对于数据预处理的要求也不是很高. 理论部分 比较经典的决策树是ID3.C ...
- OC分类(类目/类别) 和 类扩展 - 全解析
OC分类(类目/类别) 和 类扩展 - 全解析 具体见: oschina -> MyDemo -> 011.FoundationLog-OC分类剖析 http://blog.csdn. ...
- sklearn特征选择和分类模型
sklearn特征选择和分类模型 数据格式: 这里.原始特征的输入文件的格式使用libsvm的格式,即每行是label index1:value1 index2:value2这样的稀疏矩阵的格式. s ...
- Flutter实战视频-移动电商-21.分类页_类别信息接口调试
21.分类页_类别信息接口调试 先解决一个坑 取消上面的GridVIew的回弹效果.就是在拖这个gridview的时候有一个滚动的效果 physics: NeverScrollableScrollPh ...
- sklearn实现多分类逻辑回归
sklearn实现多分类逻辑回归 #二分类逻辑回归算法改造适用于多分类问题1.对于逻辑回归算法主要是用回归的算法解决分类的问题,它只能解决二分类的问题,不过经过一定的改造便可以进行多分类问题,主要的改 ...
随机推荐
- ASP.NET Core MVC+EF Core项目实战
项目背景 本项目参考于<Pro Entity Framework Core 2 for ASP.NET Core MVC>一书,项目内容为party邀请答复. 新建项目 本项目开发工具为V ...
- Windows之Java开发环境快速搭建
说明:Node.js非必须,通常中小公司或创业公司,基本上都要求全栈. 补充说明: 除此之外,当公司固定JDK.Maven.Idea.Git.Node.js及其相关IDE等版本时,运维人员或者Team ...
- 使用laravel快速构建vuepress管理器
使用laravel快速构建vuepress管理器 介绍 刚刚学了下laravel感觉很方便,最近也在用vuepress做个人博客,但是感觉每次写文章管理文章不是特别方便,就使用laravel写了这个v ...
- 二叉查找树的平衡(DSW算法)
树适合于表示某些领域的层次结构(比如Linux的文件目录结构),使用树进行查找比使用链表快的多,理想情况下树的查找复杂度O(log(N)),而链表为O(N),但理想情况指的是什么情况呢?一般指树是完全 ...
- mysql 插入string类型变量时候,需要注意的问题,妈的,害我想了好几个小时!!
很多人在用php+MySQL做网站往数据库插入数据时发现如下错误: 注册失败!Unknown column '1a' in 'field list' 结果发现用数字提交是没有问题的,其他如char型就 ...
- 关于jsp页面的复选框(checkbox)取值的获取问题
复选框的取值问题可以使用js和jQuery来获取: jQuery API : each(callback) :以每一个匹配的元素作为上下文来执行一个函数. :checked :匹配所有选中的被选中元素 ...
- block中self会造成循环引用问题
将代码块中的 self换成unsafeSelf __unsafe_unretained 与 __weak 99%相同 __weak 当对象释放之后 会自动设置为nil 而__unsafe_unreta ...
- 系统默认的alert弹出框总会带有域名
最近在开发Hybrid APP时发现用系统默认的alert弹出框总会带有域名,用户体验就比较不好了.想了一种办法来解决就是覆盖alert的方法. (function(){ window.a ...
- golang数据结构之循环链表
循环链表还是挺有难度的: 向链表中插入第一条数据的时候如何进行初始化. 删除循环链表中的数据时要考虑多种情况. 详情在代码中一一说明. 目录结构如下: circleLink.go package li ...
- Semaphore回顾
用途 在多线程访问可变变量时,是非线程安全的.可能导致程序崩溃.此时,可以通过使用信号量(semaphore)技术,保证多线程处理某段代码时,后面线程等待前面线程执行,保证了多线程的安全性.使用方法记 ...