Scala 学习之路(十二)—— 类型参数
一、泛型
Scala支持类型参数化,使得我们能够编写泛型程序。
1.1 泛型类
Java中使用<>符号来包含定义的类型参数,Scala则使用[]。
class Pair[T, S](val first: T, val second: S) {
override def toString: String = first + ":" + second
}
object ScalaApp extends App {
// 使用时候你直接指定参数类型,也可以不指定,由程序自动推断
val pair01 = new Pair("heibai01", 22)
val pair02 = new Pair[String,Int]("heibai02", 33)
println(pair01)
println(pair02)
}
1.2 泛型方法
函数和方法也支持类型参数。
object Utils {
def getHalf[T](a: Array[T]): Int = a.length / 2
}
二、类型限定
2.1 类型上界限定
Scala和Java一样,对于对象之间进行大小比较,要求被比较的对象实现java.lang.Comparable接口。所以如果想对泛型进行比较,需要限定类型上界为java.lang.Comparable,语法为S <: T,代表类型S是类型T的子类或其本身。示例如下:
// 使用 <: 符号,限定T必须是Comparable[T]的子类型
class Pair[T <: Comparable[T]](val first: T, val second: T) {
// 返回较小的值
def smaller: T = if (first.compareTo(second) < 0) first else second
}
// 测试代码
val pair = new Pair("abc", "abcd")
println(pair.smaller) // 输出 abc
扩展:如果你想要在Java中实现类型变量限定,需要使用关键字extends来实现,等价的Java代码如下:
public class Pair<T extends Comparable<T>> { private T first; private T second; Pair(T first, T second) { this.first = first; this.second = second; } public T smaller() { return first.compareTo(second) < 0 ? first : second; } }
2.2 视图界定
在上面的例子中,如果你使用Int类型或者Double等类型进行测试,点击运行后,你会发现程序根本无法通过编译:
val pair1 = new Pair(10, 12)
val pair2 = new Pair(10.0, 12.0)
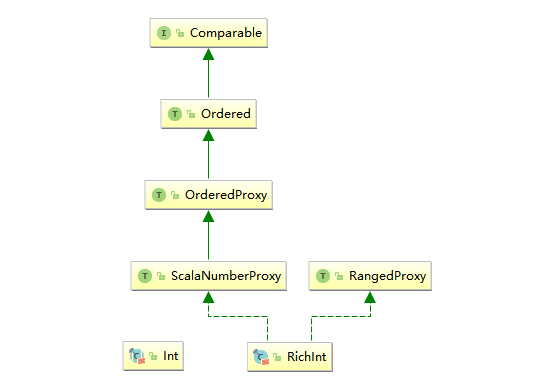
之所以出现这样的问题,是因为Scala中的Int类并没有实现Comparable接口。在Scala中直接继承Comparable接口的是特质Ordered,它在继承compareTo方法的基础上,额外定义了关系符方法,源码如下:
// 除了compareTo方法外,还提供了额外的关系符方法
trait Ordered[A] extends Any with java.lang.Comparable[A] {
def compare(that: A): Int
def < (that: A): Boolean = (this compare that) < 0
def > (that: A): Boolean = (this compare that) > 0
def <= (that: A): Boolean = (this compare that) <= 0
def >= (that: A): Boolean = (this compare that) >= 0
def compareTo(that: A): Int = compare(that)
}
之所以在日常的编程中之所以你能够执行3>2这样的判断操作,是因为程序执行了定义在Predef中的隐式转换方法intWrapper(x: Int),将Int类型转换为RichInt类型,而RichInt间接混入了Ordered特质,所以能够进行比较。
// Predef.scala
@inline implicit def intWrapper(x: Int) = new runtime.RichInt(x)
要想解决传入数值无法进行比较的问题,可以使用视图界定。语法为T <% U,代表T能够通过隐式转换转为U,即允许Int型参数在无法进行比较的时候转换为RichInt类型。示例如下:
// 视图界定符号 <%
class Pair[T <% Comparable[T]](val first: T, val second: T) {
// 返回较小的值
def smaller: T = if (first.compareTo(second) < 0) first else second
}
注:由于直接继承Java中Comparable接口的是特质Ordered,所以如下的视图界定和上面是等效的:
// 隐式转换为Ordered[T] class Pair[T <% Ordered[T]](val first: T, val second: T) { def smaller: T = if (first.compareTo(second) < 0) first else second }
2.3 类型约束
如果你用的Scala是2.11+,会发现视图界定已被标识为废弃。官方推荐使用类型约束(type constraint)来实现同样的功能,其本质是使用隐式参数进行隐式转换,示例如下:
// 1.使用隐式参数隐式转换为Comparable[T]
class Pair[T](val first: T, val second: T)(implicit ev: T => Comparable[T])
def smaller: T = if (first.compareTo(second) < 0) first else second
}
// 2.由于直接继承Java中Comparable接口的是特质Ordered,所以也可以隐式转换为Ordered[T]
class Pair[T](val first: T, val second: T)(implicit ev: T => Ordered[T]) {
def smaller: T = if (first.compareTo(second) < 0) first else second
}
当然,隐式参数转换也可以运用在具体的方法上:
object PairUtils{
def smaller[T](a: T, b: T)(implicit order: T => Ordered[T]) = if (a < b) a else b
}
2.4 上下文界定
上下文界定的形式为T:M,其中M是一个泛型,它要求必须存在一个类型为M[T]的隐式值,当你声明一个带隐式参数的方法时,需要定义一个隐式默认值。所以上面的程序也可以使用上下文界定进行改写:
class Pair[T](val first: T, val second: T) {
// 请注意 这个地方用的是Ordering[T],而上面视图界定和类型约束,用的是Ordered[T],两者的区别会在后文给出解释
def smaller(implicit ord: Ordering[T]): T = if (ord.compare(first, second) < 0) first else second
}
// 测试
val pair= new Pair(88, 66)
println(pair.smaller) //输出:66
在上面的示例中,我们无需手动添加隐式默认值就可以完成转换,这是因为Scala自动引入了Ordering[Int]这个隐式值。为了更好的说明上下文界定,下面给出一个自定义类型的比较示例:
// 1.定义一个人员类
class Person(val name: String, val age: Int) {
override def toString: String = name + ":" + age
}
// 2.继承Ordering[T],实现自定义比较器,按照自己的规则重写比较方法
class PersonOrdering extends Ordering[Person] {
override def compare(x: Person, y: Person): Int = if (x.age > y.age) 1 else -1
}
class Pair[T](val first: T, val second: T) {
def smaller(implicit ord: Ordering[T]): T = if (ord.compare(first, second) < 0) first else second
}
object ScalaApp extends App {
val pair = new Pair(new Person("hei", 88), new Person("bai", 66))
// 3.定义隐式默认值,如果不定义,则下一行代码无法通过编译
implicit val ImpPersonOrdering = new PersonOrdering
println(pair.smaller) //输出: bai:66
}
2.5 ClassTag上下文界定
这里先看一个例子:下面这段代码,没有任何语法错误,但是在运行时会抛出异常:Error: cannot find class tag for element type T, 这是由于Scala和Java一样,都存在类型擦除,即泛型信息只存在于代码编译阶段,在进入 JVM 之前,与泛型相关的信息会被擦除掉。对于下面的代码,在运行阶段创建Array时,你必须明确指明其类型,但是此时泛型信息已经被擦除,导致出现找不到类型的异常。
object ScalaApp extends App {
def makePair[T](first: T, second: T) = {
// 创建以一个数组 并赋值
val r = new Array[T](2); r(0) = first; r(1) = second; r
}
}
Scala针对这个问题,提供了ClassTag上下文界定,即把泛型的信息存储在ClassTag中,这样在运行阶段需要时,只需要从ClassTag中进行获取即可。其语法为T : ClassTag,示例如下:
import scala.reflect._
object ScalaApp extends App {
def makePair[T : ClassTag](first: T, second: T) = {
val r = new Array[T](2); r(0) = first; r(1) = second; r
}
}
2.6 类型下界限定
2.1小节介绍了类型上界的限定,Scala同时也支持下界的限定,语法为:U >: T,即U必须是类型T的超类或本身。
// 首席执行官
class CEO
// 部门经理
class Manager extends CEO
// 本公司普通员工
class Employee extends Manager
// 其他公司人员
class OtherCompany
object ScalaApp extends App {
// 限定:只有本公司部门经理以上人员才能获取权限
def Check[T >: Manager](t: T): T = {
println("获得审核权限")
t
}
// 错误写法: 省略泛型参数后,以下所有人都能获得权限,显然这是不正确的
Check(new CEO)
Check(new Manager)
Check(new Employee)
Check(new OtherCompany)
// 正确写法,传入泛型参数
Check[CEO](new CEO)
Check[Manager](new Manager)
/*
* 以下两条语句无法通过编译,异常信息为:
* do not conform to method Check's type parameter bounds(不符合方法Check的类型参数边界)
* 这种情况就完成了下界限制,即只有本公司经理及以上的人员才能获得审核权限
*/
Check[Employee](new Employee)
Check[OtherCompany](new OtherCompany)
}
2.7 多重界定
类型变量可以同时有上界和下界。 写法为 :
T > : Lower <: Upper;不能同时有多个上界或多个下界 。但可以要求一个类型实现多个特质,写法为 :
T < : Comparable[T] with Serializable with Cloneable;你可以有多个上下文界定,写法为
T : Ordering : ClassTag。
三、Ordering & Ordered
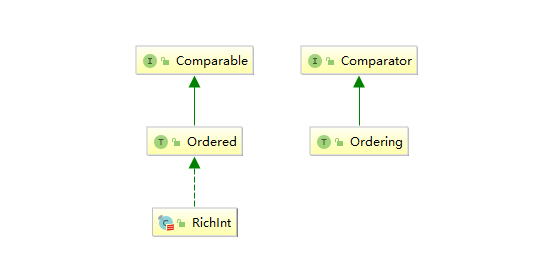
上文中使用到Ordering和Ordered特质,它们最主要的区别在于分别继承自不同的Java接口:Comparable和Comparator:
- Comparable:可以理解为内置的比较器,实现此接口的对象可以与自身进行比较;
- Comparator:可以理解为外置的比较器;当对象自身并没有定义比较规则的时候,可以传入外部比较器进行比较。
为什么Java中要同时给出这两个比较接口,这是因为你要比较的对象不一定实现了Comparable接口,而你又想对其进行比较,这时候当然你可以修改代码实现Comparable,但是如果这个类你无法修改(如源码中的类),这时候就可以使用外置的比较器。同样的问题在Scala中当然也会出现,所以Scala分别使用了Ordering和Ordered来继承它们。
下面分别给出Java中Comparable和Comparator接口的使用示例:
3.1 Comparable
import java.util.Arrays;
// 实现Comparable接口
public class Person implements Comparable<Person> {
private String name;
private int age;
Person(String name,int age) {this.name=name;this.age=age;}
@Override
public String toString() { return name+":"+age; }
// 核心的方法是重写比较规则,按照年龄进行排序
@Override
public int compareTo(Person person) {
return this.age - person.age;
}
public static void main(String[] args) {
Person[] peoples= {new Person("hei", 66), new Person("bai", 55), new Person("ying", 77)};
Arrays.sort(peoples);
Arrays.stream(peoples).forEach(System.out::println);
}
}
输出:
bai:55
hei:66
ying:77
3.2 Comparator
import java.util.Arrays;
import java.util.Comparator;
public class Person {
private String name;
private int age;
Person(String name,int age) {this.name=name;this.age=age;}
@Override
public String toString() { return name+":"+age; }
public static void main(String[] args) {
Person[] peoples= {new Person("hei", 66), new Person("bai", 55), new Person("ying", 77)};
// 这里为了直观直接使用匿名内部类,实现Comparator接口
//如果是Java8你也可以写成Arrays.sort(peoples, Comparator.comparingInt(o -> o.age));
Arrays.sort(peoples, new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.age-o2.age;
}
});
Arrays.stream(peoples).forEach(System.out::println);
}
}
使用外置比较器还有一个好处,就是你可以随时定义其排序规则:
// 按照年龄大小排序
Arrays.sort(peoples, Comparator.comparingInt(o -> o.age));
Arrays.stream(peoples).forEach(System.out::println);
// 按照名字长度倒序排列
Arrays.sort(peoples, Comparator.comparingInt(o -> -o.name.length()));
Arrays.stream(peoples).forEach(System.out::println);
3.3 上下文界定的优点
这里再次给出上下文界定中的示例代码作为回顾:
// 1.定义一个人员类
class Person(val name: String, val age: Int) {
override def toString: String = name + ":" + age
}
// 2.继承Ordering[T],实现自定义比较器,这个比较器就是一个外置比较器
class PersonOrdering extends Ordering[Person] {
override def compare(x: Person, y: Person): Int = if (x.age > y.age) 1 else -1
}
class Pair[T](val first: T, val second: T) {
def smaller(implicit ord: Ordering[T]): T = if (ord.compare(first, second) < 0) first else second
}
object ScalaApp extends App {
val pair = new Pair(new Person("hei", 88), new Person("bai", 66))
// 3.在当前上下文定义隐式默认值,这就相当于传入了外置比较器
implicit val ImpPersonOrdering = new PersonOrdering
println(pair.smaller) //输出: bai:66
}
使用上下文界定和Ordering带来的好处是:传入Pair中的参数不一定需要可比较,只要在比较时传入外置比较器即可。
需要注意的是由于隐式默认值二义性的限制,你不能像上面Java代码一样,在同一个上下文作用域中传入两个外置比较器,即下面的代码是无法通过编译的。但是你可以在不同的上下文作用域中引入不同的隐式默认值,即使用不同的外置比较器。
implicit val ImpPersonOrdering = new PersonOrdering
println(pair.smaller)
implicit val ImpPersonOrdering2 = new PersonOrdering
println(pair.smaller)
四、通配符
在实际编码中,通常需要把泛型限定在某个范围内,比如限定为某个类及其子类。因此Scala和Java一样引入了通配符这个概念,用于限定泛型的范围。不同的是Java使用?表示通配符,Scala使用_表示通配符。
class Ceo(val name: String) {
override def toString: String = name
}
class Manager(name: String) extends Ceo(name)
class Employee(name: String) extends Manager(name)
class Pair[T](val first: T, val second: T) {
override def toString: String = "first:" + first + ", second: " + second
}
object ScalaApp extends App {
// 限定部门经理及以下的人才可以组队
def makePair(p: Pair[_ <: Manager]): Unit = {println(p)}
makePair(new Pair(new Employee("heibai"), new Manager("ying")))
}
目前Scala中的通配符在某些复杂情况下还不完善,如下面的语句在Scala 2.12 中并不能通过编译:
def min[T <: Comparable[_ >: T]](p: Pair[T]) ={}
可以使用以下语法代替:
type SuperComparable[T] = Comparable[_ >: T]
def min[T <: SuperComparable[T]](p: Pair[T]) = {}
参考资料
- Martin Odersky . Scala编程(第3版)[M] . 电子工业出版社 . 2018-1-1
- 凯.S.霍斯特曼 . 快学Scala(第2版)[M] . 电子工业出版社 . 2017-7
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Scala 学习之路(十二)—— 类型参数的更多相关文章
- zigbee学习之路(十二):zigbee协议原理介绍
一.前言 从今天开始,我们要正式开始进行zigbee相关的通信实验了,我所使用的协议栈是ZStack 是TI ZStack-CC2530-2.3.0-1.4.0版本,大家也可以从TI的官网上直接下载T ...
- Scala 学习之路(二)—— 基本数据类型和运算符
一.数据类型 1.1 类型支持 Scala 拥有下表所示的数据类型,其中Byte.Short.Int.Long和Char类型统称为整数类型,整数类型加上Float和Double统称为数值类型.Scal ...
- Object-c学习之路十二(OC的copy)
oc中的拷贝分为:copy(浅拷贝)和mutablecopy(深拷贝). 浅拷贝也为指针拷贝,拷贝后原来的对象计数器会+1: 深拷贝为对象拷贝,原来的对象计数器不变. 注意:自定义对象拷贝时要实现NS ...
- Scala学习之路 (二)使用IDEA开发Scala
目前Scala的开发工具主要有两种:Eclipse和IDEA,这两个开发工具都有相应的Scala插件,如果使用Eclipse,直接到Scala官网下载即可http://scala-ide.org/do ...
- Java学习之路(十二):IO流<二>
字符流 字符流是可以直接读写字符的IO流 使用字符流从文件中读取字符的时候,需要先读取到字节数据,让后在转换为字符 使用字符流向文件中写入字符时,需要把字符转为字节在写入文件 Reader和Write ...
- 嵌入式Linux驱动学习之路(十二)按键驱动-poll机制
实现的功能是在读取按键信息的时候,如果没有产生按键,则程序休眠在read函数中,利用poll机制,可以在没有退出的情况下让程序自动退出. 下面的程序就是在读取按键信息的时候,如果5000ms内没有按键 ...
- IOS学习之路十二(UITableView下拉刷新页面)
今天做了一个下拉刷新的demo,主要用到了实现的开源框架是:https://github.com/enormego/EGOTableViewPullRefresh 运行结果如下: 实现很简单下载源代码 ...
- Java学习之路(十二):IO流<三>
复习:序列流 序列流可以把多个字节输入整合成一个,从序列流中读取到数据时,将从被整合的第一个流开始读取,读完这个后,然后开始读取第二个流,依次向后推. 详细见上一篇文章 ByteArrayOutput ...
- Java学习之路(十二):IO流
IO流的概述及其分类 IO流用来处理设备之间的数据传输,Java对数据的操作是通过流的方式 Java用于操作流的类都在IO包中 流按流向分为两种:输入流(读写数据) 输出流(写数据) 流按操作 ...
- java痛苦学习之路[十二]JSON+ajax+Servlet JSON数据转换和传递
1.首先client须要引入 jquery-1.11.1.js 2.其次javawebproject里面须要引入jar包 [commons-beanutils-1.8.0.jar.commons-c ...
随机推荐
- 李开复:VC看不上你的五个原因
[编者按]:此文是李开复先生发表于其LinkedIn主页上的一篇文章,简单列举了五条与VC接触常忽略的经验.如果你是一位正准备和VC谈判取得资金上帮助的创业者,那么应该避免企业家常常犯下的五条错误. ...
- StreamDM:基于Spark Streaming、支持在线学习的流式分析算法引擎
StreamDM:基于Spark Streaming.支持在线学习的流式分析算法引擎 streamDM:Data Mining for Spark Streaming,华为诺亚方舟实验室开源了业界第一 ...
- Java高级应用(一个)-文件夹监控服务
最近.在研究一些比较成熟的框架.他们还发现,他们中的一些相当不错的文章.现在,对于一些在你们中间一个简单的翻译(版的英文文章,非常有帮助). 译:原文链接 你有没有发现,当你编辑一个文件.同一时候使用 ...
- python 教程 第十三章、 特殊的方法
第十三章. 特殊的方法 1) 特殊的方法 __init__(self,...) 这个方法在新建对象恰好要被返回使用之前被调用. __del__(self) 恰好在对象要被删除之前调用. __st ...
- AngularJS 计时器
<div ng-controller="MyController"> <!--显示$scope.clock的now属性--> <h1>hello ...
- ios 时间戳 当前时间 相互转化
1.今天在做一个webservice的接口的时候,被要求传一个时间戳过去,然后就是开始在Google上找 2.遇到两个问题,一,当前时间转化为时间戳,二,获取的当前时间和系统的时间相差8个小时 一,转 ...
- JAVASCRIPT高程笔记-------第八章 浏览器BOM对象
8.1 window对象--表示一个浏览器的实例 在全局作用域中声明的任何变量.函数都会变成window对象的属性和方法,与之直接定义window对象的属性的区别是 window.xxx 可以通过 ...
- PostSharp-4.3.33安装包_KeyGen发布
PostSharp-4.3.33安装包_KeyGen发布 请低调使用. PostSharp安装及注册步骤截图.rar 请把浏览器主页设置为以下地址支持本人.https://www.duba.com/? ...
- ELINK编程器典型场景之远程镜像
当不想直接提供Hex/Bin等二进制程序文件给用户时,通过生成远程镜像功能将程序文件加密后,再提供给用户自行脱机下载来达到远程更新的目的. 远程镜像生成的一般步骤为由客户端提供SN码,本地依据SN码加 ...
- Z-Order
The z-order of a window indicates the window's position in a stack of overlapping windows. This wind ...