以股票案例入门基于SVM的机器学习
SVM是Support Vector Machine的缩写,中文叫支持向量机,通过它可以对样本数据进行分类。以股票为例,SVM能根据若干特征样本数据,把待预测的目标结果划分成“涨”和”跌”两种,从而实现预测股票涨跌的效果。
1 通过简单案例了解SVM的分类作用
在Sklearn库里,封装了SVM分类的相关方法,也就是说,我们无需了解其中复杂的算法,即可用它实现基于SVM的分类。通过如下SimpleSVMDemo.py案例,我们来看下通过SVM库实现分类的做法,以及相关方法的调用方式。
1 #!/usr/bin/env python
2 #coding=utf-8
3 import numpy as np
4 import matplotlib.pyplot as plt
5 from sklearn import svm
6 #给出平面上的若干点
7 points = np.r_[[[-1,1],[1.5,1.5],[1.8,0.2],[0.8,0.7],[2.2,2.8],[2.5,3.5],[4,2]]]
8 #按0和1标记成两类
9 typeName = [0,0,0,0,1,1,1]
在第5行里,我们引入了基于SVM的库。在第7行,我们定义了若干个点,并在第9行把这些点分成了两类,比如[-1,1]点是第一类,而[4,2]是第二类。
这里请注意,在第7行定义点的时候,是通过np.r_方法,把数据转换成“列矩阵”,这样做的目的是让数据结构满足fit方法的要求。
10 #建立模型
11 svmTool = svm.SVC(kernel='linear')
12 svmTool.fit(points,typeName) #传入参数
13 #确立分类的直线
14 sample = svmTool.coef_[0] #系数
15 slope = -sample[0]/sample[1] #斜率
16 lineX = np.arange(-2,5,1)#获取-2到5,间距是1的若干数据
17 lineY = slope*lineX-(svmTool.intercept_[0])/sample[1]
在第11行里,我们创建了基于SVM的对象,并指定该SVM模型采用比较常用的“线性核”来实现分类操作。
在第14行,通过fit训练样本。这里fit方法和之前基于线性回归案例中的fit方法是一样的,只不过这里是基于线性核的相关算法,而之前是基于线性回归的相关算法(比如最小二乘法)。训练完成后,通过第14行和第15行的代码,我们得到了能分隔两类样本的直线,包括直线的斜率和截距,并通过第16行和第17行的代码设置了分隔线的若干个点。
18 #画出划分直线
19 plt.plot(lineX,lineY,color='blue',label='Classified Line')
20 plt.legend(loc='best') #绘制图例
21 plt.scatter(points[:,0],points[:,1],c='R')
22 plt.show()
计算完成后,我们通过第19行的plot方法绘制了分隔线,并在第21行通过scatter方法绘制所有的样本点。由于points是“列矩阵”的数据结构,所以是用points[:,0]来获取绘制点的 x坐标,用points[:,1]来获取y坐标,最后是通过第22行的show方法绘制图形。运行上述代码,我们能看到如下图13.8的效果,从中我们能看到,蓝色的边界线能有效地分隔两类样本。
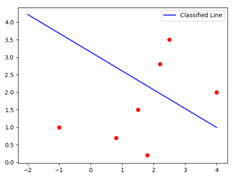
从这个例子中我们能看到,SVM的作用是,根据样本,训练出能划分不同种类数据的边界线,由此实现“分类”的效果。而且,在根据训练样本确定好边界线的参数后,还能根据其它没有明确种类样本,计算出它的种类,以此实现“预测”效果。
2 数据标准化处理
标准化(normalization)处理是将特征样本按一定算法进行缩放,让它们落在某个范围比较小的区间,同时去掉单位限制,让样本数据转换成无量纲的纯数值。
在用机器学习方法进行训练时,一般需要进行标准化处理,原因是Sklearn等库封装的一些机器学习算法对样本有一定的要求,如果有些特征值的数量级偏离大多数特征值的数量级,或者有特征值偏离正态分布,那么预测结果会不准确。
需要说明的是,虽然在训练前对样本进行了标准化处理,改变了样本值,但由于在标准化的过程中是用同一个算法对全部样本进行转换,属于“数据优化”,不会对后继的训练起到不好的作用。
这里我们是通过sklearn库提供的preprocessing.scale方法实现标准化,该方法是让特征值减去平均值然后除以标准差。通过如下ScaleDemo.py案例,我们实际用下preprocessing.scale方法。
1 #!/usr/bin/env python
2 #coding=utf-8
3 from sklearn import preprocessing
4 import numpy as np
5
6 origVal = np.array([[10,5,3],
7 [8,6,12],
8 [14,7,15]])
9 #计算均值
10 avgOrig = origVal.mean(axis=0)
11 #计算标准差
12 stdOrig=origVal.std(axis=0)
13 #减去均值,除以标准差
14 print((origVal-avgOrig)/stdOrig)
15 scaledVal=preprocessing.scale(origVal)
16 #直接输出preprocessing.scale后的结果
17 print(scaledVal)
在第6行里,我们初始化了一个长宽各为3的矩阵,在第10行,通过mean方法计算了该矩阵的均值,在第12行则通过std方法计算标准差。
第14行是用原始值减去均值,再除以标准差,在第17行,是直接输出preprocessing.scale的结果。第14行和第17行的输出结果相同,均是下值,从中我们验证了标准化的具体做法。
1 [[-0.26726124 -1.22474487 -1.37281295]
2 [-1.06904497 0. 0.39223227]
3 [ 1.33630621 1.22474487 0.98058068]]
3 预测股票涨跌
在之前的案例中,我们用基于SVM的方法,通过一维直线来分类二维的点。据此可以进一步推论:通过基于SVM的方法,我们还可以分类具有多个特征值的样本。
比如可以通过开盘价、收盘价、最高价、最低价和成交量等特征值,用SVM的算法训练出这些特征值和股票“涨“和“跌“的关系,即通过特征值划分指定股票“涨”和“跌”的边界,这样的话,一旦输入其它的股票特征数据,即可预测出对应的涨跌情况。在如下的PredictStockBySVM.py案例中,我们给出了基于SVM预测股票涨跌的功能。
1 #!/usr/bin/env python
2 #coding=utf-8
3 import pandas as pd
4 from sklearn import svm,preprocessing
5 import matplotlib.pyplot as plt
6 origDf=pd.read_csv('D:/stockData/ch13/6035052018-09-012019-05-31.csv',encoding='gbk')
7 df=origDf[['Close', 'Low','Open' ,'Vol','Date']]
8 #diff列表示本日和上日收盘价的差
9 df['diff'] = df["Close"]-df["Close"].shift(1)
10 df['diff'].fillna(0, inplace = True)
11 #up列表示本日是否上涨,1表示涨,0表示跌
12 df['up'] = df['diff']
13 df['up'][df['diff']>0] = 1
14 df['up'][df['diff']<=0] = 0
15 #预测值暂且初始化为0
16 df['predictForUp'] = 0
第6行里,我们从指定文件读取了包含股票信息的csv文件,该csv格式的文件其实是从网络数据接口获取得到的,具体做法可以参考前面博文。
从第9行里,我们设置了df的diff列为本日收盘价和前日收盘价的差值,通过第12行到第14行的代码,我们设置了up列的值,具体是,如果当日股票上涨,即本日收盘价大于前日收盘价,则up值是1,反之如果当日股票下跌,up值则为0。
在第16行里,我们在df对象里新建了表示预测结果的predictForUp列,该列的值暂且都设置为0,在后继的代码里,将根据预测结果填充这列的值。
17 #目标值是真实的涨跌情况
18 target = df['up']
19 length=len(df)
20 trainNum=int(length*0.8)
21 predictNum=length-trainNum
22 #选择指定列作为特征列
23 feature=df[['Close', 'High', 'Low','Open' ,'Volume']]
24 #标准化处理特征值
25 feature=preprocessing.scale(feature)
在第18行里,我们设置训练目标值是表示涨跌情况的up列,在第20行,设置了训练集的数量是总量的80%,在第23行则设置了训练的特征值,请注意这里去掉了日期这个不相关的列,而且,在第25行,对特征值进行了标准化处理。
26 #训练集的特征值和目标值
27 featureTrain=feature[1:trainNum-1]
28 targetTrain=target[1:trainNum-1]
29 svmTool = svm.SVC(kernel='liner')
30 svmTool.fit(featureTrain,targetTrain)
在第27行和第28行里,我们通过截取指定行的方式,得到了特征值和目标值的训练集,在第26行里,以线性核的方式创建了SVM分类器对象svmTool。
在第30行里,通过fit方法,用特征值和目标值的训练集训练svmTool分类对象。从上文里我们已经看到,训练所用的特征值是开盘收盘价、最高最低价和成交量,训练所用的目标值是描述涨跌情况的up列。在训练完成后,svmTool对象中就包含了能划分股票涨跌的相关参数。
31 predictedIndex=trainNum
32 #逐行预测测试集
33 while predictedIndex<length:
34 testFeature=feature[predictedIndex:predictedIndex+1]
35 predictForUp=svmTool.predict(testFeature)
36 df.ix[predictedIndex,'predictForUp']=predictForUp
37 predictedIndex = predictedIndex+1
在第33行的while循环里,我们通过predictedIndex索引值,依次遍历测试集。
在遍历过程中,通过第35行的predict方法,用训练好的svmTool分类器,逐行预测测试集中的股票涨跌情况,并在第36行里,把预测结果设置到df对象的predictForUp列中。
38 #该对象只包含预测数据,即只包含测试集
39 dfWithPredicted = df[trainNum:length]
40 #开始绘图,创建两个子图
41 figure = plt.figure()
42 #创建子图
43 (axClose, axUpOrDown) = figure.subplots(2, sharex=True)
44 dfWithPredicted['Close'].plot(ax=axClose)
45 dfWithPredicted['predictForUp'].plot(ax=axUpOrDown,color="red", label='Predicted Data')
46 dfWithPredicted['up'].plot(ax=axUpOrDown,color="blue",label='Real Data')
47 plt.legend(loc='best') #绘制图例
48 #设置x轴坐标标签和旋转角度
49 major_index=dfWithPredicted.index[dfWithPredicted.index%2==0]
50 major_xtics=dfWithPredicted['Date'][dfWithPredicted.index%2==0]
51 plt.xticks(major_index,major_xtics)
52 plt.setp(plt.gca().get_xticklabels(), rotation=30)
53 plt.title("通过SVM预测603505的涨跌情况")
54 plt.rcParams['font.sans-serif']=['SimHei']
55 plt.show()
由于在之前的代码里,我们只设置测试集的predictForUp列,并没有设置训练集的该列数据,所以在第39行里,用切片的手段,把测试集数据放置到dfWithPredicted对象中,请注意这里切片的起始和结束值是测试集的起始和结束索引值。至此完成了数据准备工作,在之后的代码里,我们将用matplotlib库开始绘图。
在第43行里,我们通过subplots方法设置了两个子图,并通过sharex=True让这两个子图的x轴具有相同的刻度和标签。在第44行代码里,在axClose子图中,我们用plot方法绘制了收盘价的走势。在第45行代码里,在axUpOrDown子图中,我们绘制了预测到的涨跌情况,而在第46行里,还是在axUpOrDown子图里,绘制了这些天的股票真实的涨跌情况。
在第49行到第52行的代码里,我们设置了x标签的文字以及旋转角度,这样做的目的是让标签文字看上去不至于太密集。在第53行里,我们设置了中文标题,由于要显示中文,所以需要第54行的代码,最后在55行通过show方法展示了图片。运行上述代码,能看到如下图所示的效果。
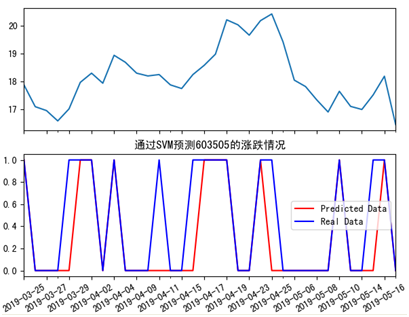
其中上图展示了收盘价,下图的蓝色线条表示真实的涨跌情况,0表示跌,1表示上涨,而红色则表示预测后的结果。
4 结论
对比一下,虽有偏差,但大体相符。综上所述,本案例是数学角度,演示了通过SVM分类的做法,包括如果划分特征值和目标值,如何对样本数据进行标准化处理,如何用训练数据训练SVM,还有如何用训练后的结果预测分类结果。
5 总结和版权说明
本文是给程序员加财商系列,之前还有两篇博文
有不少网友转载和想要转载我的博文,本人感到十分荣幸,这也是本人不断写博文的动力。关于本文的版权有如下统一的说明,抱歉就不逐一回复了。
1 本文可转载,无需告知,转载时请用链接的方式,给出原文出处,别简单地通过文本方式给出,同时写明原作者是hsm_computer。
2 在转载时,请原文转载 ,谢绝洗稿。否则本人保留追究法律责任的权利。
以股票案例入门基于SVM的机器学习的更多相关文章
- Quartz应用实践入门案例二(基于java工程)
在web应用程序中添加定时任务,Quartz的简单介绍可以参看博文<Quartz应用实践入门案例一(基于Web应用)> .其实一旦学会了如何应用开源框架就应该很容易将这中框架应用与自己的任 ...
- Httpd服务入门知识-Httpd服务常见配置案例之基于客户端来源地址实现访问控制
Httpd服务入门知识-Httpd服务常见配置案例之基于客户端来源地址实现访问控制 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Options 1>.OPTIONS指 ...
- Httpd服务入门知识-Httpd服务常见配置案例之基于用户账号实现访问控制
Httpd服务入门知识-Httpd服务常见配置案例之基于用户账号实现访问控制 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.基于用户的访问控制概述 认证质询: WWW-Auth ...
- 在我的新书里,尝试着用股票案例讲述Python爬虫大数据可视化等知识
我的新书,<基于股票大数据分析的Python入门实战>,预计将于2019年底在清华出版社出版. 如果大家对大数据分析有兴趣,又想学习Python,这本书是一本不错的选择.从知识体系上来看, ...
- 完整的验证码识别流程基于svm(若是想提升,可优化)
字符型图片验证码识别完整过程及Python实现 首先很感觉这篇文章的作者,将这篇文章写的这么好.我呢,也是拿来学习,觉得太好,所以忍不住就进行了转载. 因为我个人现在手上也有个验证码识别的项目,只是难 ...
- 【原创】基于SVM作短期时间序列的预测
[面试思路拓展] 对时间序列进行预测的方法有很多, 但如果只有几周的数据,而没有很多线性的趋势.各种实际的背景该如何去预测时间序列? 或许可以尝试下利用SVM去预测时间序列,那么如何提取预测的特征呢? ...
- AJAX应用【股票案例】
股票案例 我们要做的是股票的案例,它能够无刷新地更新股票的数据.当鼠标移动到具体的股票中,它会显示具体的信息. 我们首先来看一下要做出来的效果: 服务器端分析 首先,从效果图我们可以看见很多股票基本信 ...
- Shiro 核心功能案例讲解 基于SpringBoot 有源码
Shiro 核心功能案例讲解 基于SpringBoot 有源码 从实战中学习Shiro的用法.本章使用SpringBoot快速搭建项目.整合SiteMesh框架布局页面.整合Shiro框架实现用身份认 ...
- AJAX应用【股票案例、验证码校验】
一.股票案例 我们要做的是股票的案例,它能够无刷新地更新股票的数据.当鼠标移动到具体的股票中,它会显示具体的信息. 我们首先来看一下要做出来的效果: 1.1服务器端分析 首先,从效果图我们可以看见很多 ...
随机推荐
- Noip 2016 愤怒的小鸟 题解
[NOIP2016]愤怒的小鸟 时间限制:1 s 内存限制:256 MB [题目描述] Kiana最近沉迷于一款神奇的游戏无法自拔. 简单来说,这款游戏是在一个平面上进行的. 有一架弹弓位于(0, ...
- ServiceFabric极简文档-1.3删除群集
删除群集 若要删除群集,请运行包文件夹中的 RemoveServiceFabricCluster.ps1 Powershell 脚本,并传入 JSON 配置文件的路径. 可以选择性地指定删除日志的位置 ...
- 当没有接口时、不可继承时,如果使用mock方案进行单元测试
原版代码: import java.io.IOException; import java.io.InputStream; import java.net.HttpURLConnection; imp ...
- Gin 框架 - 使用 logrus 进行日志记录
目录 概述 日志格式 Logrus 使用 推荐阅读 概述 上篇文章分享了 Gin 框架的路由配置,这篇文章分享日志记录. 查了很多资料,Go 的日志记录用的最多的还是 github.com/sirup ...
- 【排序函数讲解】sort-C++
c++标准库里的排序函数,用于对给定区间所有元素进行排序.头 文件是#include 使用 Sort()在具体实现中规避了经典快速排序可能出现的.会导 致实际复杂度退化到 o(n²)的极端情况.它根据 ...
- 个人永久性免费-Excel催化剂功能第33波-报表形式数据结构转标准数据源
一般来说,如果有标准的数据源结构,对后续的分析工作将会带来极大的方便.但现实中,许多的原始数据并不预期那样,一个主题的数据已经干净地存放在一个工作表中.今天Excel催化剂再次送上批量化操作,将不规则 ...
- hdu6406 Taotao Picks Apples(线段树)
Taotao Picks Apples 题目传送门 解题思路 建立一颗线段树,维护当前区间内的最大值maxx和可摘取的苹果数num.最大值很容易维护,主要是可摘取的苹果数怎么合并.合并左右孩子时,左孩 ...
- linux初学者-iptables篇
linux初学者-iptables篇 iptables是防火墙的一种,是用来设置.维护和检查linux内核的IP过滤规则的,可以完成封包过滤.封包重定向和网络地址转换(NAT)等功能. iptabl ...
- Java emoji持久化mysql
好久没有更新博客了,今天和大家分享一个关于emoji表情持久化问题,相信做web开发的都遇到过这样的问题,因为我们知道mysql的utf-8字符集保存不了保存不了表情字符,这是为什么呢?因为普通的字符 ...
- java 第二章
变量:变量就是代表程序运行时存放数据的地方 数据存放在:磁盘,内存卡,U盘,光盘,内存条,固态硬盘,机械硬盘等 字节:8个二进制位构成1个"字节(Byte)",它是存储空间的基本计 ...