爬虫(七):爬取猫眼电影top100
一:分析网站
目标站和目标数据
目标地址:http://maoyan.com/board/4?offset=20
目标数据:目标地址页面的电影列表,包括电影名,电影图片,主演,上映日期以及评分。
二:上代码
(1):导入相应的包
import requests
from requests.exceptions import RequestException # 处理请求异常
import re
import pymysql
import json
from multiprocessing import Pool
(2):分析网页
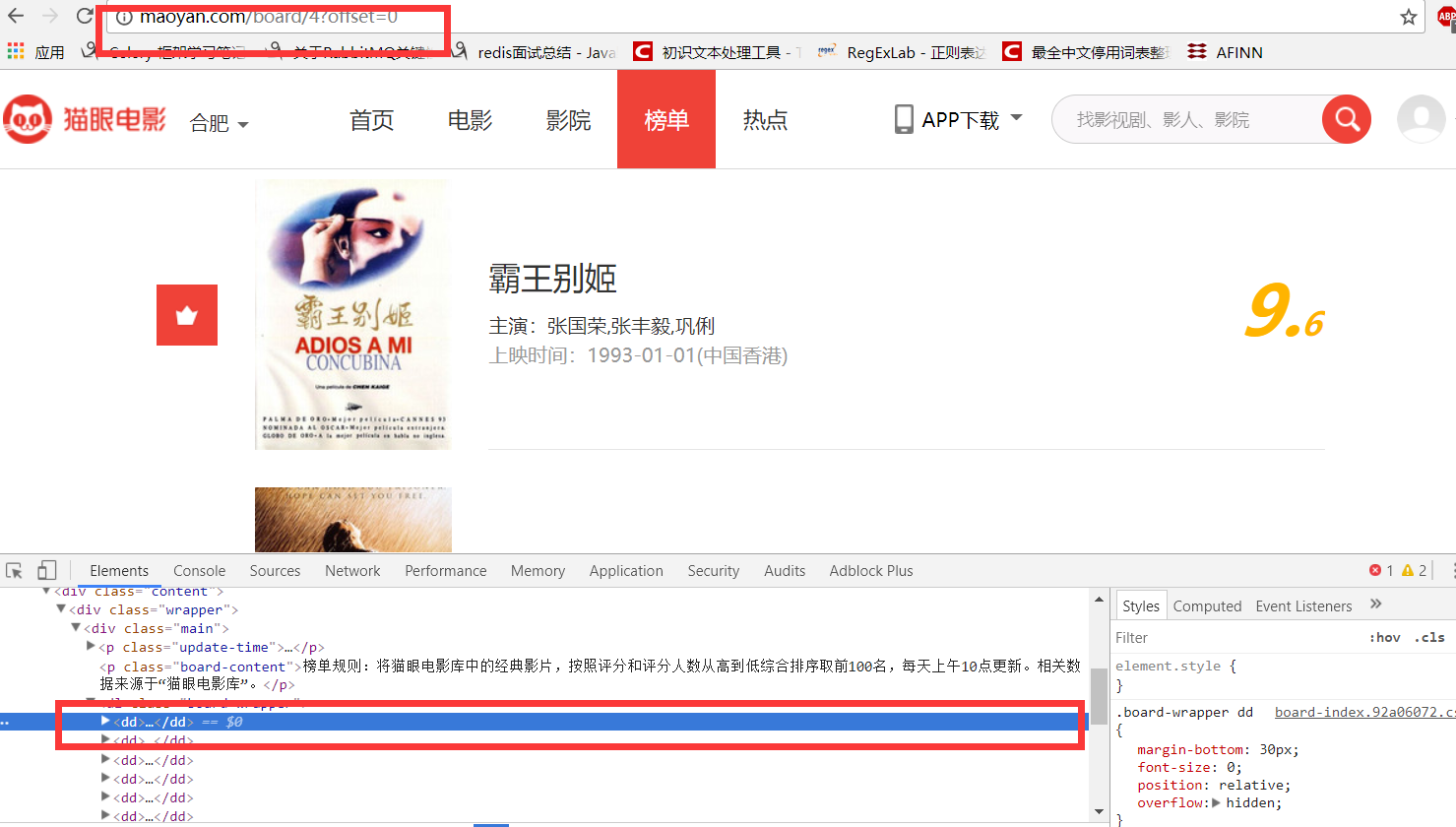
通过检查发现需要的内容位于网页中的<dd>标签内。通过翻页发现url中的参数的变化。
(3):获取html网页
# 获取一页的数据
def get_one_page(url):
# requests会产生异常
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200: # 状态码是200表示成功
return response.text
else:
return None
except RequestException:
return None
(4):通过正则提取需要的信息 --》正则表达式详情
# 解析网页内容
def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?class="name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',
re.S) # re.S可以匹配任意字符包括换行
items = re.findall(pattern, html) # 将括号中的内容提取出来
for item in items:
yield { # 构造一个生成器
'index': item[0].strip(),
'title': item[2].strip(),
'actor': item[3].strip()[3:],
'score': ''.join([item[5].strip(), item[6].strip()]),
'pub_time': item[4].strip()[5:],
'img_url': item[1].strip(),
}
(5):将获取的内容存入mysql数据库
# 连接数据库,首先要在本地创建好数据库
def commit_to_sql(dic):
conn = pymysql.connect(host='localhost', port=3306, user='mydb', passwd='', db='maoyantop100',
charset='utf8')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 设置游标的数据类型为字典
sql = '''insert into movies_top_100(mid,title,actor,score,pub_time,img_url) values("%s","%s","%s","%s","%s","%s")''' % (
dic['index'], dic['title'], dic['actor'], dic['score'], dic['pub_time'], dic['img_url'],)
cursor.execute(sql) # 执行sql语句并返回受影响的行数
# # 提交
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
(6):主程序及运行
def main(url):
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
commit_to_sql(item) if __name__ == '__main__':
urls = ['http://maoyan.com/board/4?offset={}'.format(i) for i in range(0, 100, 10)]
# 使用多进程
pool = Pool()
pool.map(main, urls)
(7):最后的结果
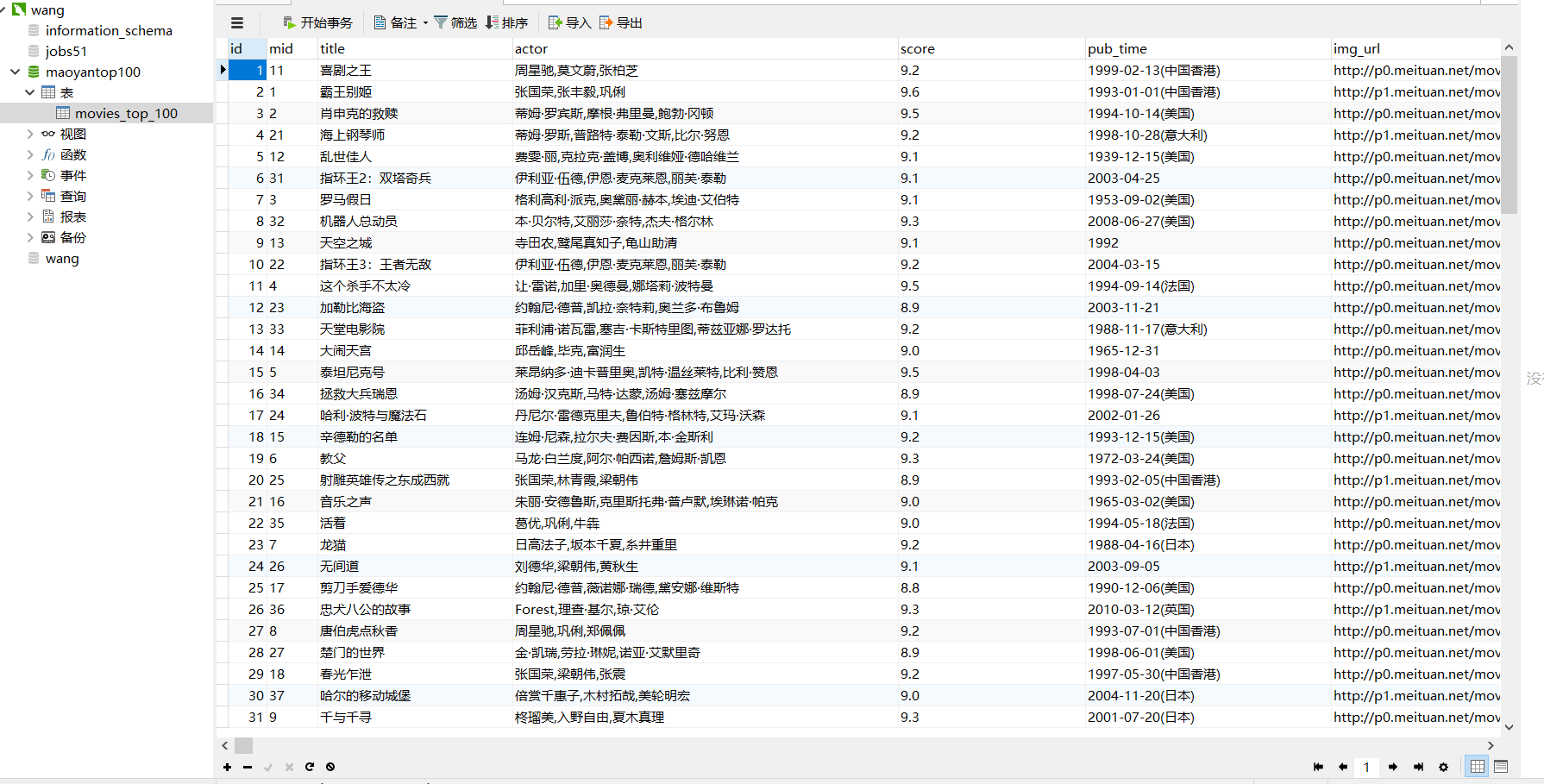
完整代码:
# -*- coding: utf-8 -*-
# @Author : FELIX
# @Date : 2018/4/4 9:29 import requests
from requests.exceptions import RequestException
import re
import pymysql
import json
from multiprocessing import Pool # 连接数据库
def commit_to_sql(dic):
conn = pymysql.connect(host='localhost', port=3306, user='wang', passwd='', db='maoyantop100',
charset='utf8')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 设置游标的数据类型为字典
sql = '''insert into movies_top_100(mid,title,actor,score,pub_time,img_url) values("%s","%s","%s","%s","%s","%s")''' % (
dic['index'], dic['title'], dic['actor'], dic['score'], dic['pub_time'], dic['img_url'],)
cursor.execute(sql) # 执行sql语句并返回受影响的行数
# # 提交
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close() # 获取一页的数据
def get_one_page(url):
# requests会产生异常
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200: # 状态码是200表示成功
return response.text
else:
return None
except RequestException:
return None # 解析网页内容
def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?class="name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',
re.S) # re.S可以匹配任意字符包括换行
items = re.findall(pattern, html) # 将括号中的内容提取出来
for item in items:
yield { # 构造一个生成器
'index': item[0].strip(),
'title': item[2].strip(),
'actor': item[3].strip()[3:],
'score': ''.join([item[5].strip(), item[6].strip()]),
'pub_time': item[4].strip()[5:],
'img_url': item[1].strip(),
}
# print(items) def write_to_file(content):
with open('result.txt', 'a', encoding='utf8')as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n') ii = 0 def main(url):
html = get_one_page(url)
for item in parse_one_page(html):
global ii
print(ii, item)
ii = ii + 1
commit_to_sql(item)
write_to_file(item) # print(html) if __name__ == '__main__':
urls = ['http://maoyan.com/board/4?offset={}'.format(i) for i in range(0, 100, 10)]
# 使用多进程
pool = Pool()
pool.map(main, urls)
爬虫(七):爬取猫眼电影top100的更多相关文章
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- # 爬虫连载系列(1)--爬取猫眼电影Top100
前言 学习python有一段时间了,之前一直忙于学习数据分析,耽搁了原本计划的博客更新.趁着这段空闲时间,打算开始更新一个爬虫系列.内容大致包括:使用正则表达式.xpath.BeautifulSoup ...
- 爬虫--requests爬取猫眼电影排行榜
'''目标:使用requests分页爬取猫眼电影中榜单栏目中TOP100榜的所有电影信息,并将信息写入文件URL地址:http://maoyan.com/board/4 其中参数offset表示其实条 ...
随机推荐
- java实现HTTP请求 HttpUtil
示例: package com.sensor.utils; import java.net.HttpURLConnection; import java.net.URL; public class H ...
- 多线程使用libcurl
curl默认情况下有两个地方是线程不安全的, 需要特殊处理, 1是curl_global_init 这个函数必须单线程调用, 2是默认多线程调用https会莫名其妙的挂掉, 以下是网上的解决方案 ht ...
- webstrom设置语句中的分号
webstrom可以设置语句默认是否添加分号 setting >editor > Code Style > Javascript
- java使用AES-256-ECB(PKCS7Padding)解密——微信支付退款通知接口指定解密方式
1.场景 在做微信支付退款通知接口时,微信对通知的内容做了加密,并且指定用 AES256 解密,官方指定的解密方式如下: 2.导包 <!-- https://mvnrepository.com/ ...
- netcat瑞士军刀实现电脑远程控制termux
关于nc实现远程控制termux 1.首先termux安装namp pkg install namp 2.windows系统安装netcat 此为netcat下载连接 下载得到zip压缩包,解压得到里 ...
- JavaScript 入门与进阶
JavaScript 介绍 javascript 是运行在浏览器端的脚本语言,javascript 主要解决的是前端与用户交互的问题,包括使用交互 和 数据交互,javascript 是浏览器解释执行 ...
- springboot下@webfilter的使用
启动类加了@ServletComponentScan,无论过滤器类加不加@Componment urlPatterns = {"/test/*"}都可以生效 单使用@Compone ...
- 《你不知道的Javascript》感悟篇—对象属性遍历的那些事
划重点 本篇笔者将重点介绍JavaScript中 getOwnPropertyNames .Object.keys.for ... in 的使用及他们之间的异同点. getOwnPropertyNam ...
- obj = obj || {} 分析这个代码的起到的作用
情况一: <script> function test(obj) { console.log(obj.value) } function student() { this.value = ...
- CSS之选择器相关
一.选择器的作用 选择器就是用来选择标签的,要使用css对HTML页面中的元素实现一对一,一对多或者多对一的控制,这就需要用到CSS选择器. HTML页面中的元素就是通过CSS选择器进行控制的.每一条 ...