hadoop--presto安装部署
系统环境:hadoop + hive已经配置完成
1、下载presto:https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.167/presto-server-0.167.tar.gz
2、解压安装
# tar -zxvf presto-server-0.167.tar.gz -C /usr/local/
/usr/local/presto-server-0.167则为安装目录,另外Presto还需要数据目录,数据目录最好不要在安装目录里面,方便后面Presto的版本升级。
3、配置presto
在安装目录里创建etc目录。这目录会有以下配置(自己创建):
结点属性(Node Properties):每个结点的环境配置
JVM配置(JVM Config):Java虚拟机的命令行选项
配置属性(Config Properties):Persto server的配置
Catelog属性(Catalog Properties):配置Connector(数据源)
(1)结点属性(Node Properties)
结点属性文件etc/node.properties,包含每个结点的配置。一个结点是一个Presto实例。这文件一般是在Presto第一次安装时创建的。以下是最小配置:
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/var/presto/data
解释:
node.environment: 环境名字,Presto集群中的结点的环境名字都必须是一样的。
node.id: 唯一标识,每个结点的标识都必须是为一的。就算重启或升级Presto都必须还保持原来的标识。
node.data-dir: 数据目录,Presto用它来保存log和其他数据
eg:
node.environment=production
node.id=master-presto-coordinator
node.data-dir=/usr/local/presto-server-0.167/data #data需要自己手动创建

(2)JVM配置(JVM Config)
JVM配置文件etc/jvm.config,包含启动Java虚拟机时的命令行选项。格式是每一行是一个命令行选项。此文件数据是由shell解析,所以选项中包含空格或特殊字符会被忽略。
以下是参考配置:
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
备注:以上参数都是官网参数,实际环境需要调整
(3)配置属性(Config Properties)
配置属性文件etc/config.properties,包含Presto server的配置。Presto server可以同时为coordinator和worker,但一个大集群里最好就是只指定一台机器为coordinator。
以下是coordinator的最小配置:
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://example.net:8080
以下是worker的最小配置:
coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
discovery.uri=http://example.net:8080
如果适用于测试目的,需要将一台机器同时配置为coordinator和worker,则使用以下配置:
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
query.max-memory=5GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://example.net:8080
解释:
coordinator: 是否运行该实例为coordinator(接受client的查询和管理查询执行)。
node-scheduler.include-coordinator:coordinator是否也作为work。对于大型集群来说,在coordinator里做worker的工作会影响查询性能。
http-server.http.port:指定HTTP端口。Presto使用HTTP来与外部和内部进行交流。
query.max-memory: 查询能用到的最大总内存
query.max-memory-per-node: 查询能用到的最大单结点内存
discovery-server.enabled: Presto使用Discovery服务去找到集群中的所有结点。每个Presto实例在启动时都会在Discovery服务里注册。这样可以简化部署,不需要额外的服务,Presto的coordinator内置一个Discovery服务。也是使用HTTP端口。
discovery.uri: Discovery服务的URI。将example.net:8080替换为coordinator的host和端口。这个URI不能以斜杠结尾,这个错误需特别注意,不然会报404错误。
另外还有以下属性:
jmx.rmiregistry.port: 指定JMX RMI的注册。JMX client可以连接此端口
jmx.rmiserver.port: 指定JXM RMI的服务器。可通过JMX监听。
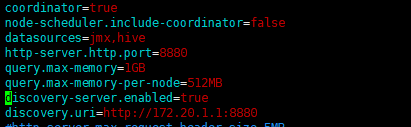
eg:server配置
coordinator=true
node-scheduler.include-coordinator=false
datasources=jmx,hive
http-server.http.port=8880
query.max-memory=1GB
query.max-memory-per-node=512MB
discovery-server.enabled=true
discovery.uri=http://172.20.1.1:8880
client配置
coordinator=false
http-server.http.port=8880
query.max-memory=1GB
query.max-memory-per-node=512MB
discovery-server.enabled = true
discovery.uri=http://172.20.1.1:8880

(4)日志级别
创建文件log.properties
填入内容:
com.facebook.presto=INFO
备注:日志级别有四种,DEBUG, INFO, WARN and ERROR
(5)连接设置
这里只说一下hive的,其实官网写的很清楚,如果有用到其他的,可以点一下官网连接:https://prestodb.io/docs/current/connector.html
hive connector配置如下:
a、创建存放链接配置文件的文件夹,在之前etc目录下创建catalog
b、放入一个jmx的配置文件,jmx.properties,配置内容:connector.name=jmx (通过jmx管理connector)
c、配置一个hive connector的配制文件,hive.properties,内容如下:
在etc目录下创建catalog目录
# mkdir catalog
# cd catalog
# touch hive.properties
connector.name=hive-hadoop2 #取个连接名
hive.metastore.uri=thrift://172.20.1.1:9083 #配置metastore连接
hive.config.resources=/usr/local/hadoop-2.9.1/conf/core-site.xml,/usr/local/hadoop-2.9.1/conf/hdfs-site.xml #指明hadoop的配置文件,主要是设计hdfs
hive.allow-drop-table=true #给删表权限
其他配置如下可参考官网:https://prestodb.io/docs/current/connector/hive.html https://prestodb.io/docs/current/connector/hive-security.html
eg:

(6)
这些都配置好后,就要启动presto,步骤如下:
a、在bin目录下启动服务:bin/launcher start bin/launcher start
b、命令行启动:下载启动jar包:presto-cli-0.191-executable.jar,下载链接为: https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.191/presto-cli-0.191-executable.jar
c、下载下来后改个名字为presto,放在bin目录下,然后给个执行权限:chmod +x presto ,
d、连接hive,并启动:./presto --server localhost:8080 --catalog hive --schema default
e、如果要关闭presto服务,执行:bin/launcher stop
借鉴:https://blog.csdn.net/u012551524/article/details/79013194
hadoop--presto安装部署的更多相关文章
- PRESTO安装部署和参数说明(一)
PRESTO部署和参数说明(一) 一,概要 在部署和使用presto的过程中,在此记录一下部署记录和使用记录以及需要注意的事项.本人使用的presto版本是0.214,3台redhat虚拟机.使用背景 ...
- Hadoop学习---安装部署
hadoop框架 Hadoop使用主/从(Master/Slave)架构,主要角色有NameNode,DataNode,secondary NameNode,JobTracker,TaskTracke ...
- Hadoop之中的一个:Hadoop的安装部署
说到Hadoop不得不说云计算了,我这里大概说说云计算的概念,事实上百度百科里都有,我仅仅是copy过来,好让我的这篇hadoop博客内容不显得那么单调.骨感.云计算近期今年炒的特别火,我也是个刚開始 ...
- hadoop分布式安装部署详细视频教程(网盘附配好环境的CentOS虚拟机文件/hadoop配置文件)
参考资源下载:http://pan.baidu.com/s/1ntwUij3视频安装教程:hadoop安装.flvVirtualBox虚拟机:hadoop.part1-part5.rarhadoop文 ...
- hadoop(二)hadoop的安装部署
系统版本 : 64位CentOS6.6 hadoop版本: 1.2.1 jdk版本: jdk1.6.0_45 环境准备 1.主机分配 主机名 ip master 1.0.0.0.10 slave1 1 ...
- hadoop分布式安装部署具体视频教程(网盘附配好环境的CentOS虚拟机文件/hadoop配置文件)
參考资源下载:http://pan.baidu.com/s/1ntwUij3视频安装教程:hadoop安装.flvVirtualBox虚拟机:hadoop.part1-part5.rarhadoop文 ...
- hadoop 简单安装部署
hadoop第一课:虚拟机搭建和安装hadoop及启动 hadoop第二课:hdfs集群集中管理和hadoop文件操作 hadoop第三课:java开发hdfs hadoop第四课:Yarn和Map/ ...
- 安装部署Apache Hadoop (本地模式和伪分布式)
本节内容: Hadoop版本 安装部署Hadoop 一.Hadoop版本 1. Hadoop版本种类 目前Hadoop发行版非常多,有华为发行版.Intel发行版.Cloudera发行版(CDH)等, ...
- 记一次Hadoop安装部署过程
实验名称:Hadoop安装部署 一.实验环境: 虚拟机数量:3个 (1个master,2个slave:slave01,slave02) 主节点master信息: 操作系统:CentOS7.5 软件包位 ...
- Hadoop.之.入门部署
一.课程目标 ->大数据是什么?大数据能做什么? ->什么是Hadoop?Hadoop的设计思想? ->Hadoop如何解决大数据的问题?(什么是hdfs与yarn.MapReduc ...
随机推荐
- Go 终端读写 && 文件读写、copy
终端读写 操作终端相关文件句柄常量 os.Stdin(standard):标准输入 os.Stdout:标准输出 os.Stderr:标准错误输出 标准输出 demo:直接输出和 判断之后输出的结果不 ...
- Ubuntu安装opencv3.4.4教程
1 去官网下载opencv 在本教程中选用的是opencv3.4.4,下载链接 http://opencv.org/releases.html ,选择sources. 2 解压 unzip openc ...
- AJAX with JSP and Servlet(代码)
欢迎任何形式的转载,但请务必注明出处. 本章内容来自YouTube需翻墙(点击进入视频学习) 服务器配置等可以参看我其他文章.注释等后续再加 效果图 结构 <body> <fie ...
- jquery sortable的拖动方法示例详解
转自:https://hb-keepmoving.iteye.com/blog/1154618 所有的事件回调函数都有两个参数:event和ui,浏览器自有event对象,和经过封装的ui对象 u ...
- [#Linux] CentOS 7 禁用笔记本的触摸板
安装 xorg-x11-apps yum install xorg-x11-apps 查看对应设备的 id xinput –list 关闭 touchpad xinput set-int-prop 1 ...
- Linux命令——column
参考:Viewing Linux output in columns 功能 column命令把他的输入格式化多列显示.输入可以是文件,也可以是标准输入. 列优先,从左到右 显示的时候首先填满最左列,然 ...
- redis3.2 aof重写
redis关闭aof,缩容,redis实例一直在重写. 原因也是redis3.2的bug,aof重写是没有判断aof是否开启. redis缩容后改变的是redis重写的min_size,缩容之前,实例 ...
- 【OF框架】缓存Session/Cookies/Cache代码调用api,切换缓存到Redis
准备 缓存服务在应用开发中最常用的功能,特别是Session和Cookies,Cache部分业务开发过程会使用到. 在负载均衡环境下,缓存服务需要存储到服务器. 缓存默认实现在内存在,可以通过配置切换 ...
- IDEA快捷键之关闭标签页和选定单词
下面所说的快捷键仅作为演示使用,个人可根据喜好自行设置 使用Alt + W 选中某个单词 点击IDEA左上角的File 打开Settings 在左侧点击KeyMap 打开右侧的Editor Actio ...
- 使用Wireshark对手机抓包设置说明
一.原因 1.手机目前没有类似的抓包工具可以直接对手机进行抓包 2.一般数据交换的路线是:手机——>运营商——>服务器,可以在手机和运营商中间加一道网卡变成:手机——>PC网卡——& ...