Python - 二叉树, 堆, headq 模块
二叉树
概念
二叉树是n(n>=0)个结点的有限集合,该集合或者为空集(称为空二叉树),
或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树组成。
特点
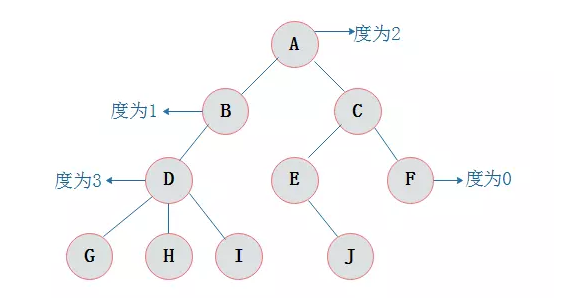
每个结点最多有两颗子树,所以二叉树中不存在度大于2的结点
左子树和右子树是有顺序的,次序不能任意颠倒
即使树中某结点只有一棵子树,也要区分它是左子树还是右子树
性质
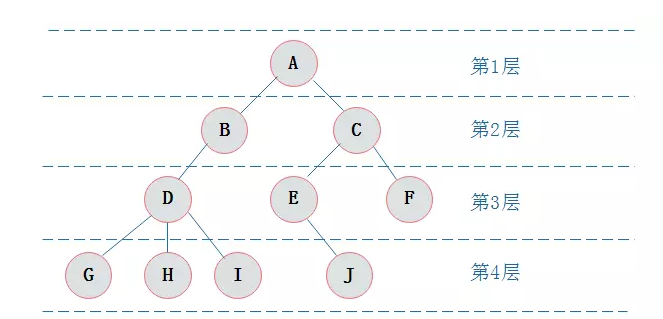
1)在二叉树的第 i 层上最多有 2i-1 个节点 。(i>=1)
(1) 若 i=1,则该结点是二叉树的根,无双亲, 否则,编号为 [i/2] 的结点为其双亲结点;
(2) 若 2i>n,则该结点无左孩子, 否则,编号为 2i 的结点为其左孩子结点;
(3) 若 2i+1>n,则该结点无右孩子结点, 否则,编号为2i+1 的结点为其右孩子结点。
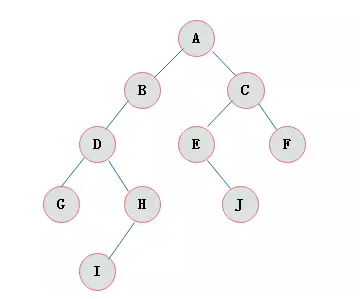
层
度
类型
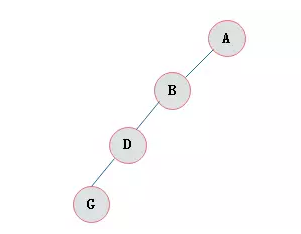
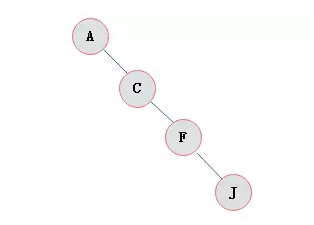
斜树
所有的结点都只有左子树的二叉树叫左斜树。
所有结点都是只有右子树的二叉树叫右斜树。
这两者统称为斜树。
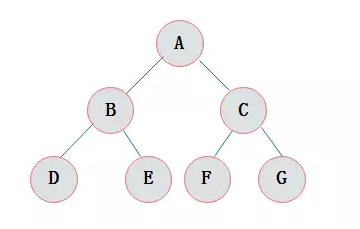
满二叉树
在一棵二叉树中。
如果所有分支结点都存在左子树和右子树,
并且所有叶子都在同一层上,这样的二叉树称为满二叉树。
满二叉树的特点有:
1)叶子只能出现在最下一层。出现在其它层就不可能达成平衡。
2)非叶子结点的度一定是2。
3)在同样深度的二叉树中,满二叉树的结点个数最多,叶子数最多。
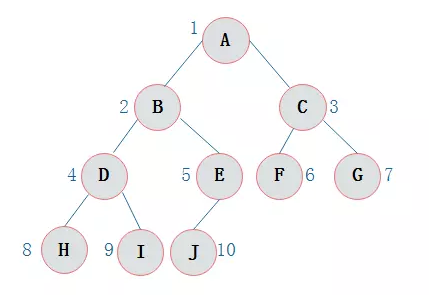
完全二叉树
对一颗具有n个结点的二叉树按层编号
如果编号为 i(1<=i<=n) 的结点与同样深度的满二叉树中编号为 i 的结点在二叉树中位置完全相同
则这棵二叉树称为完全二叉树。
特点
4)如果结点度为1,则该结点只有左孩子,即没有右子树。
5)同样结点数目的二叉树,完全二叉树深度最小。
注:满二叉树一定是完全二叉树,但反过来不一定成立。

存储结构
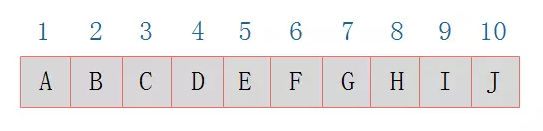
顺序存储
二叉树的顺序存储结构就是使用一维数组存储二叉树中的结点,
并且结点的存储位置,就是数组的下标索引。
二叉链表
既然顺序存储不能满足二叉树的存储需求,那么考虑采用链式存储。
由二叉树定义可知,二叉树的每个结点最多有两个孩子。
因此,可以将结点数据结构定义为一个数据和两个指针域。

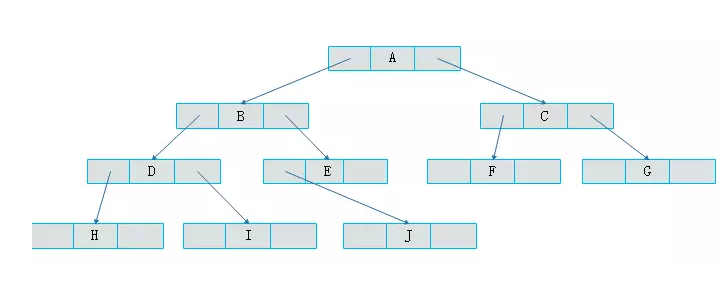
二叉树实现
定义一个左子树, 定义一个柚子树, 以及值
class BinTree:
def __init__(self,value=None,left=None,right=None):
self.value=value
self.left=left #左子树
self.right=right #右子树
二叉树遍历
先序遍历
先处理根, 之后是左子树, 然后是右子树
中序遍历
先处理左子树, 之后是根, 然后是右子树
后序遍历
先处理左子树, 之后是右子树, 最后是根
代码示例
def preTraverse(root):
'''
先序遍历
'''
if root is not None:
print(root.value)
preTraverse(root.left)
preTraverse(root.right) def midTraverse(root):
'''
中序遍历
'''
if root is not None:
midTraverse(root.left)
print(root.value)
midTraverse(root.right) def afterTraverse(root):
'''
后序遍历
'''
if root is not None:
afterTraverse(root.left)
afterTraverse(root.right)
print(root.value)
堆
最大堆 / 最小堆
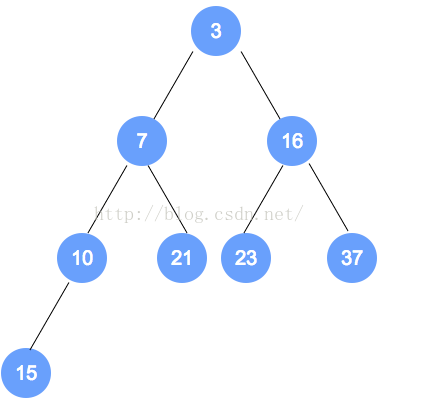
最大 / 小堆是一棵完全二叉树,非叶子结点的值不大 / 小于左孩子和右孩子的值
构建原理
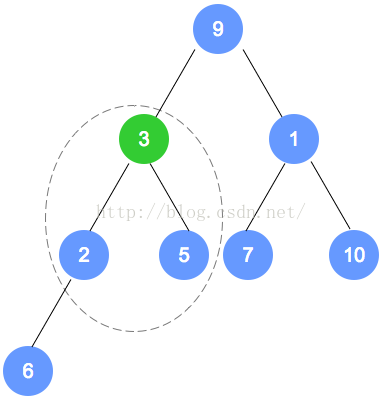
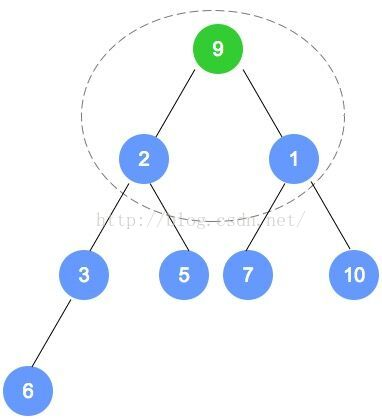
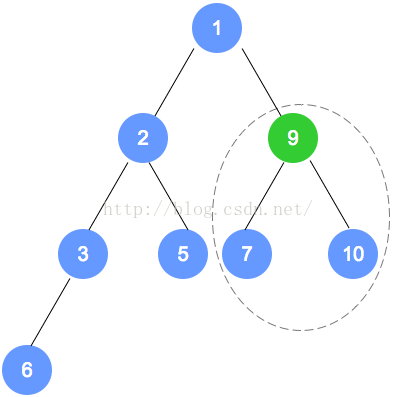
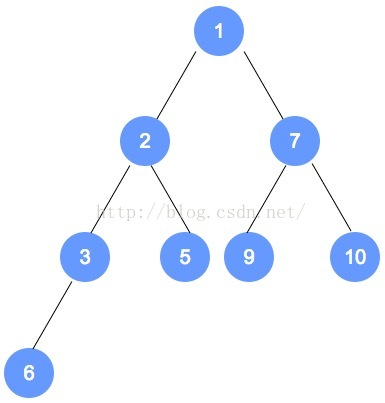
初始数组为:9,3,7,6,5,1,10,2
按照完全二叉树,将数字依次填入。
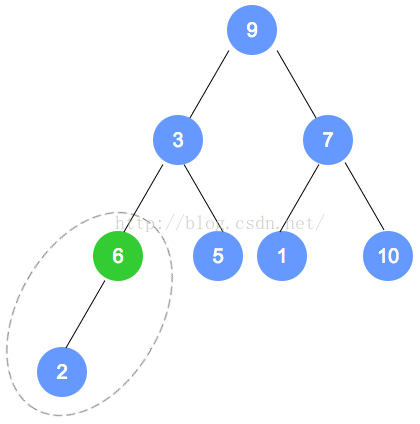
填入后,找到最后一个结点(本示例为数字2的节点),从它的父节点(本示例为数字6的节点)
开始调整。根据性质,小的数字往上移动;至此,第1次调整完成。
注意,被调整的节点,还有子节点的情况,需要递归进行调整。
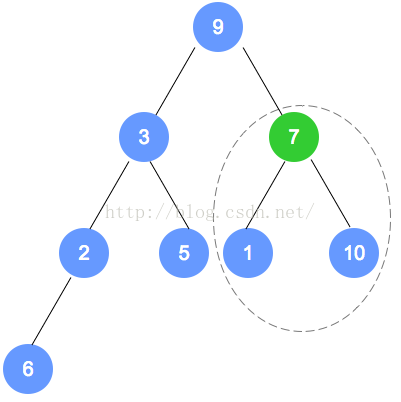
第二次调整,是数字6的节点数组下标小1的节点(比数字6的下标小1的节点是数字7的节点),
用刚才的规则进行调整。以此类推,直到调整到根节点。
元素插入
以上个最小堆为例,插入数字0。
数字0的节点首先加入到该二叉树最后的一个节点,依据最小堆的定义,自底向上,递归调整。
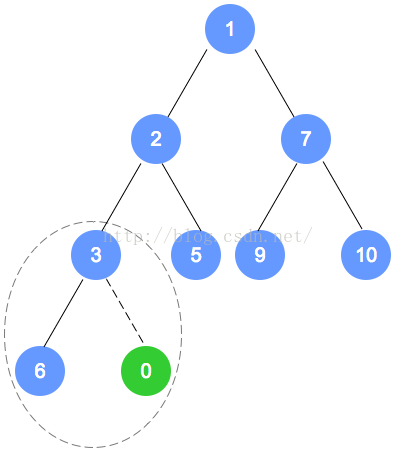

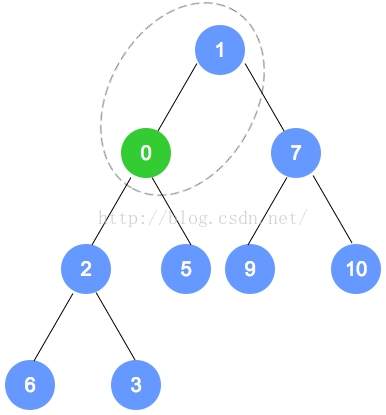
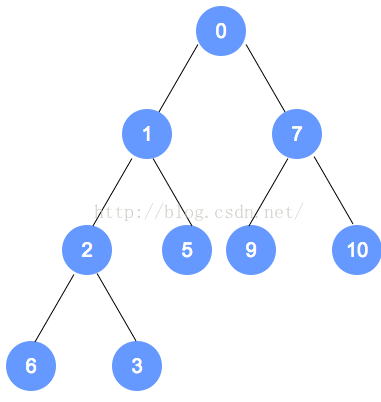
元素删除
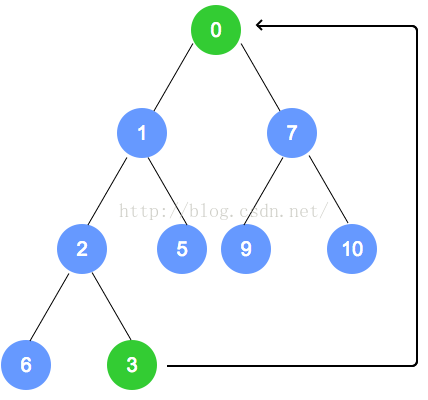
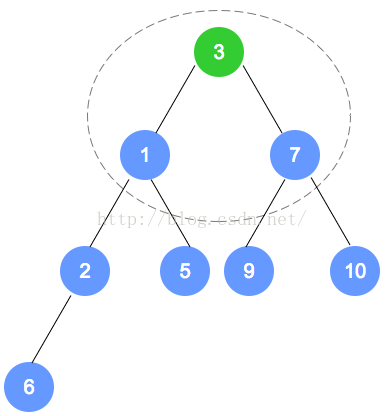
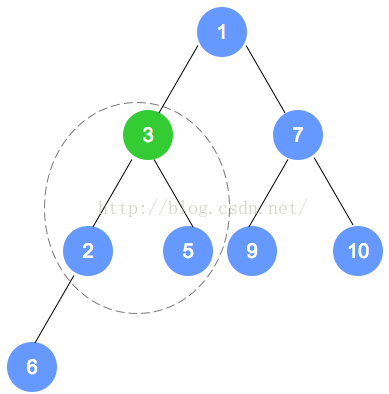
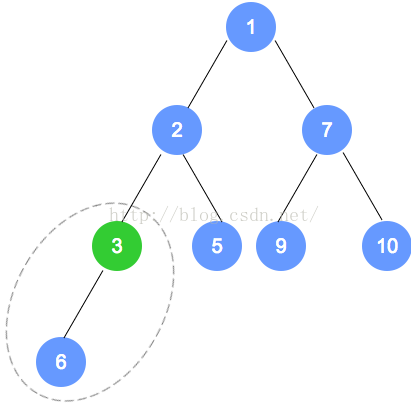
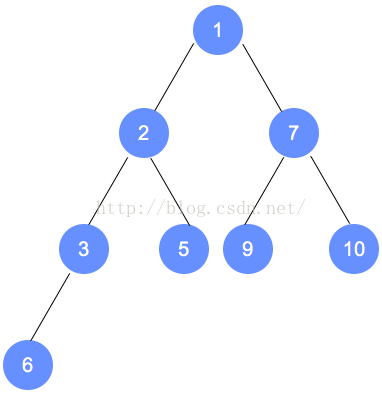
代码实现
最小堆
class MinHeap(object):
"""最小堆""" def __init__(self):
self.data = [] # 创建堆
self.count = len(self.data) # 元素数量 # def __init__(self, arr):
# self.data = copy.copy(arr)
# self.count = len(self.data)
# i = self.count / 2
# while i >= 1:
# self.shiftDown(i)
# i -= 1 def size(self):
return self.count def isEmpty(self):
return self.count == 0 def insert(self, item):
# 插入元素入堆
self.data.append(item)
self.count += 1
self.shiftup(self.count) def shiftup(self, count):
# 将插入的元素放到合适位置,保持最小堆
while count > 1 and self.data[(count / 2) - 1] > self.data[count - 1]:
self.data[(count / 2) - 1], self.data[count - 1] = self.data[count - 1], self.data[(count / 2) - 1]
count /= 2 def extractMin(self):
# 出堆
if self.count > 0:
ret = self.data[0]
self.data[0], self.data[self.count - 1] = self.data[self.count - 1], self.data[0]
self.data.pop()
self.count -= 1
self.shiftDown(1)
return ret def shiftDown(self, count):
# 将堆的索引位置元素向下移动到合适位置,保持最小堆
while 2 * count <= self.count:
# 证明有孩子
j = 2 * count
if j + 1 <= self.count:
# 证明有右孩子
if self.data[j] < self.data[j - 1]:
j += 1
if self.data[count - 1] <= self.data[j - 1]:
# 堆的索引位置已经小于两个孩子节点,不需要交换了
break
self.data[count - 1], self.data[j - 1] = self.data[j - 1], self.data[count - 1]
count = j
最大堆
"""
最大堆
""" class MaxHeap(object):
# def __init__(self):
# self.data = [] # 创建堆
# self.count = len(self.data) # 元素数量 def __init__(self, arr):
self.data = copy.copy(arr)
self.count = len(self.data)
i = self.count / 2
while i >= 1:
self.shiftDown(i)
i -= 1 def size(self):
return self.count def isEmpty(self):
return self.count == 0 def insert(self, item):
# 插入元素入堆
self.data.append(item)
self.count += 1
self.shiftup(self.count) def shiftup(self, count):
# 将插入的元素放到合适位置,保持最大堆
while count > 1 and self.data[(count / 2) - 1] < self.data[count - 1]:
self.data[(count / 2) - 1], self.data[count - 1] = self.data[count - 1], self.data[(count / 2) - 1]
count /= 2 def extractMax(self):
# 出堆
if self.count > 0:
ret = self.data[0]
self.data[0], self.data[self.count - 1] = self.data[self.count - 1], self.data[0]
self.data.pop()
self.count -= 1
self.shiftDown(1)
return ret def shiftDown(self, count):
# 将堆的索引位置元素向下移动到合适位置,保持最大堆
while 2 * count <= self.count:
# 证明有孩子
j = 2 * count
if j + 1 <= self.count:
# 证明有右孩子
if self.data[j] > self.data[j - 1]:
j += 1
if self.data[count - 1] >= self.data[j - 1]:
# 堆的索引位置已经大于两个孩子节点,不需要交换了
break
self.data[count - 1], self.data[j - 1] = self.data[j - 1], self.data[count - 1]
count = j
heapq 模块
官方文档 这里
Python 自带的用于堆结构方便的模块
创建堆 - 最小堆
单个添加创建堆 - heappush
import heapq data = [1,5,3,2,8,5]
heap = [] for n in data:
heapq.heappush(heap, n)
对已存在的序列转化为堆 - heapify
import heapq data = [1,5,3,2,8,5]
heapq.heapify(data)
对多个序列转化为堆 - merge
import heapq num1 = [32, 3, 5, 34, 54, 23, 132]
num2 = [23, 2, 12, 656, 324, 23, 54]
num1 = sorted(num1)
num2 = sorted(num2) res = heapq.merge(num1, num2)
print(list(res)) # [2, 3, 5, 12, 23, 23, 23, 32, 34, 54, 54, 132, 324, 656]
创建堆 - 最大堆
用法同最小堆, 创建的时候将所有的值取相反数
然后在取出堆顶, 在进行取反, 即可获得原值
import heapq data = [1, 5, 3, 2, 8, 5]
li = []
for i in data:
heapq.heappush(li, -i) print(li) # [-8, -5, -5, -1, -2, -3]
print(-li[0]) #
访问堆内容
查看最小值 - [0]
import heapq data = [1, 5, 3, 2, 8, 5]
heapq.heapify(data) print(data[0]) #
弹出最小值 - heappop
会改变原数据, 类似于列表的 pop
import heapq data = [1, 5, 3, 2, 8, 5]
heapq.heapify(data) print(heapq.heappop(data)) #
print(data) # [2, 5, 3, 5, 8]
向堆内推送值 - heappush
import heapq data = [1, 5, 3, 2, 8, 5]
heapq.heapify(data) heapq.heappush(data, 10)
print(data) # [1, 2, 3, 5, 8, 5, 10]
弹出最小值并加入一个值 - heappushpop
弹出最小值, 添加新值, 且自动排序保持是最小堆
import heapq data = [1, 5, 3, 2, 8, 5]
heapq.heapify(data) print(heapq.heappushpop(data, 1)) #
print(data) # [1, 2, 3, 5, 8, 5]
弹出最小值并加入一个值 - heapreplace
弹出最小值, 添加新值, 且自动排序保持是最小堆
是 heappushpop 的高效版本, 在py3 中适用
import heapq data = [1, 5, 3, 2, 8, 5]
heapq.heapify(data) print(heapq.heapreplace(data, 10)) #
print(data) # [2, 5, 3, 10, 8, 5]
k 值问题 - nlargest / nsmallest
找出堆中最小 / 大的 k 个值
import heapq data = [1, 5, 3, 2, 8, 5] heapq.heapify(data)
print(data) # [1, 2, 3, 5, 8, 5]
print(heapq.nlargest(2, data)) # [8, 5]
print(heapq.nsmallest(2, data)) # [1, 2]
可以接收一个参数 key , 用于指定选项进行选取
用法类似于 sorted 的 key
import heapq
from pprint import pprint
portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
cheap = heapq.nsmallest(3, portfolio, key=lambda s: s['price'])
expensive = heapq.nlargest(3, portfolio, key=lambda s: s['price'])
pprint(cheap)
pprint(expensive) """
输出:
[{'name': 'YHOO', 'price': 16.35, 'shares': 45},
{'name': 'FB', 'price': 21.09, 'shares': 200},
{'name': 'HPQ', 'price': 31.75, 'shares': 35}]
[{'name': 'AAPL', 'price': 543.22, 'shares': 50},
{'name': 'ACME', 'price': 115.65, 'shares': 75},
{'name': 'IBM', 'price': 91.1, 'shares': 100}]
"""
Python - 二叉树, 堆, headq 模块的更多相关文章
- Python多线程(threading模块)
线程(thread)是操作系统能够进行运算调度的最小单位.它被包含在进程之中,是进程中的实际运作单位.一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务. ...
- 使用deque模块固定队列长度,用headq模块来查找最大或最小的N个元素以及实现一个优先级排序的队列
一. deque(双端队列) 1. 使用 deque(maxlen=N)会新建一个固定大小的队列.当新的元素加入并且这个队列已满的时候,最老的元素会自动被移除掉 >>> from c ...
- Python 单向队列Queue模块详解
Python 单向队列Queue模块详解 单向队列Queue,先进先出 '''A multi-producer, multi-consumer queue.''' try: import thread ...
- Python(五)模块
本章内容: 模块介绍 time & datetime random os sys json & picle hashlib XML requests ConfigParser logg ...
- [转载]Python中的sys模块
#!/usr/bin/python # Filename: cat.py import sys def readfile(filename): '''Print a file to the stand ...
- Python安装包或模块的多种方式汇总
windows下安装python第三方包.模块汇总如下(部分方式同样适用于其他平台): 1. windows下最常见的*.exe,*msi文件,直接运行安装即可: 2. 安装easy_install, ...
- Python 五个常用模块资料 os sys time re built-in
1.os模块 os模块包装了不同操作系统的通用接口,使用户在不同操作系统下,可以使用相同的函数接口,返回相同结构的结果. os.name:返回当前操作系统名称('posix', 'nt', ' ...
- Python中的random模块,来自于Capricorn的实验室
Python中的random模块用于生成随机数.下面介绍一下random模块中最常用的几个函数. random.random random.random()用于生成一个0到1的随机符点数: 0 < ...
- python函数和常用模块(三),Day5
递归 反射 os模块 sys模块 hashlib加密模块 正则表达式 反射 python中的反射功能是由以下四个内置函数提供:hasattr.getattr.setattr.delattr,改四个函数 ...
随机推荐
- BootStrap【四、插件】
BootStrap插件基于: 1.BootStrap.js 2.BootStrap.js基于JQuery data属性 1.通过data属性控制页面交互 2.$(document).off('.dat ...
- myBatis的坑 01 %的坑 框架内置的小BUG
<select id="queryUserLikeUserName" resultType="cn.itcast.pojo.User"> selec ...
- 解决Ubuntu下ssh无法启动
Ubuntu ssh一直无法启动. 通过 systemctl status ssh.service 查看到的错误是 Dec 16 13:35:22 iZm5eckxl2tqyka9eoe7b3Z ...
- JSONObject fromObject() 需要引入的包
1. maven项目 在pom.xml中添加以下依赖: <dependency> <groupId>net.sf.json-lib</groupId> <ar ...
- linux和unix下crontab的使用
在LINUX中,周期执行的任务一般由cron这个守护进程来处理 [ps -ef | grep cron].cron读取一个或多个配置文件,这些配置文件中包含了命令行及其调用时间.cron的配置文件称为 ...
- CSS基础学习-15-1.CSS 浏览器内核
- NMI是什么
NMI是什么 2016/02/28 vmunix NMI(non-maskable interrupt),就是不可屏蔽的中断.根据Intel的Software Developer手册Volume 3, ...
- STMStudio-stm32软件的应用笔记
上次编写中,已经提到该软件的功能了,可以增加调试手段. 编译出axf文件-keil和out文件-iar,注意keil在output文件名是,不能有"."既NL_ZKTP3_V1.0 ...
- 题解 [BZOJ4144] Petrol
题目描述 有一张 n 个点 m 条边的无向图,其中有 s 个点上有加油站.有 Q 次询问(a,b,c), 问能否开一辆油箱容积为 c 的车从 a 走到 b.(a,b均为加油站) 输入格式 第一 ...
- Java中判断两个Long类型是否相等
在项目中将两个long类型的值比较是否相等,结果却遇到了疑问? 下面就陪大家看看一个神奇的现象! 1.1问题?为什么同样的类型,同样的值,却不相等呢? 1.2那么我们就需要探索一下源码了 源码中显示, ...