利用python爬取王者荣耀英雄皮肤图片
前两天看到同学用python爬下来LOL的皮肤图片,感觉挺有趣的,我也想试试,于是决定来爬一爬王者荣耀的英雄和皮肤图片。
首先,我们找到王者的官网http://pvp.qq.com/web201605/herolist.shtml,我们可以在里面找到王者所有的英雄。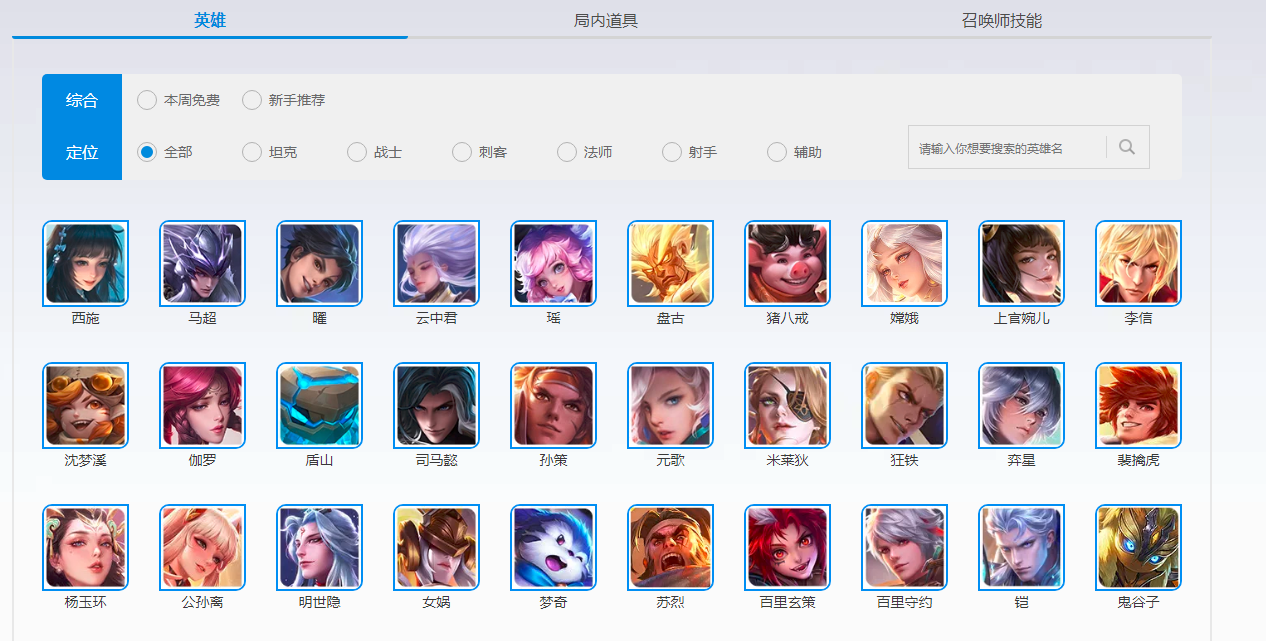
然后,简单的分析一下结构,看看是否有反爬机制。

之后,在上网查阅资料后,发现所有的英雄编号,名字和皮肤都存放在一个叫herolist.json的文件中,但是我打开这个文件却是一堆意义不明的符号,不过这并不影响我们继续。

接下来我们点击进入英雄的详情页面,发现皮肤的地址都是相同格式的
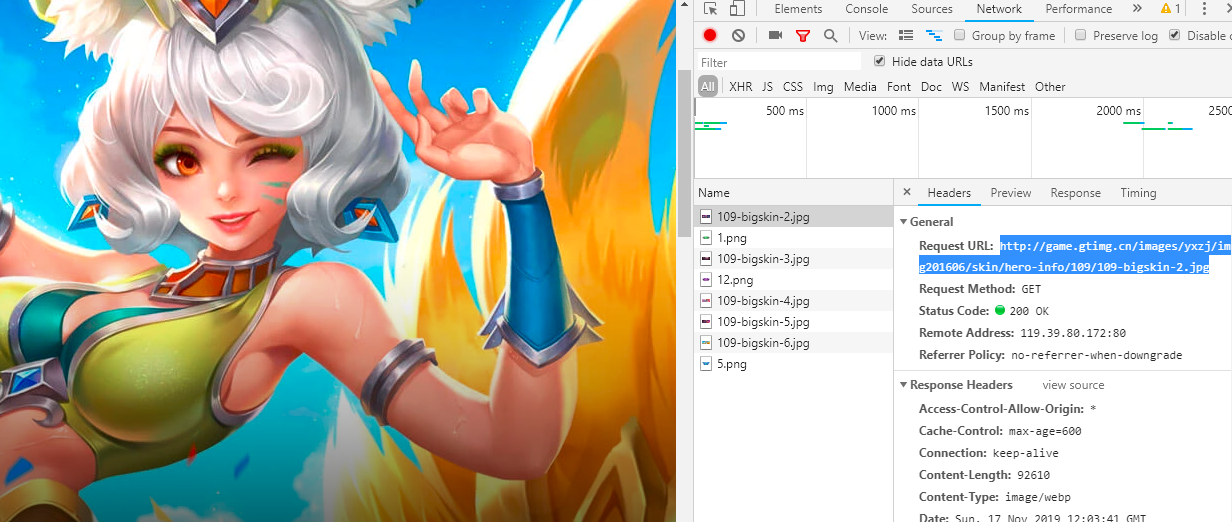
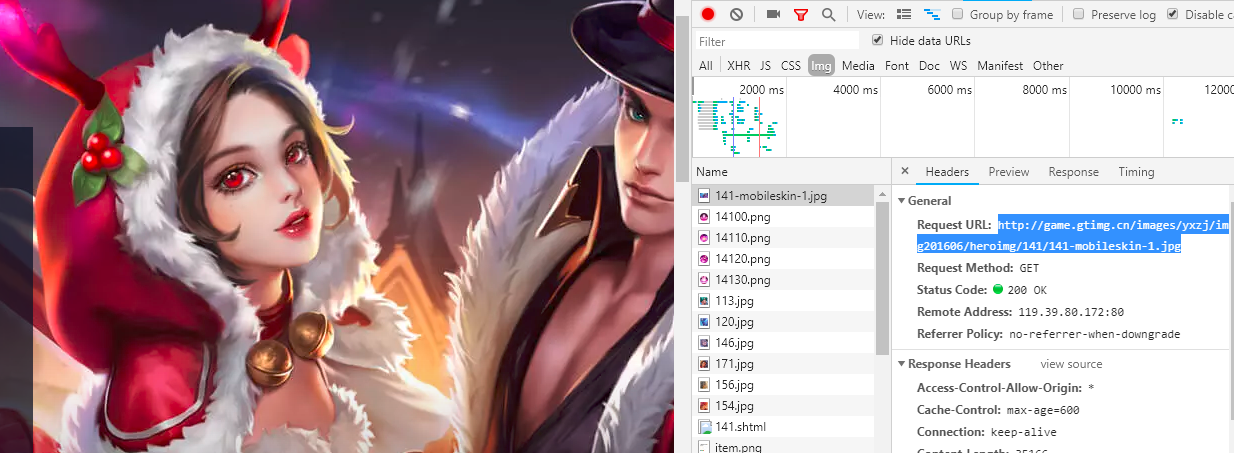
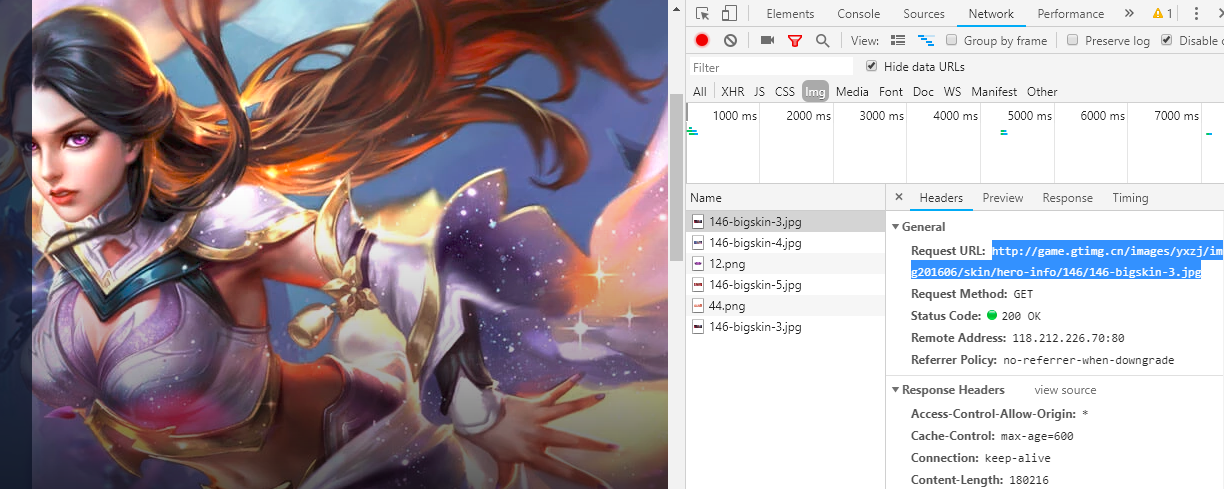
我们不难发现其中的规律,那么接下来我们就要开始写代码了。
完整代码如下:
import requests
import json
import os
import time start = time.time()
url = requests.get('http://pvp.qq.com/web201605/js/herolist.json').content
jsonFile = json.loads(url) # 提取json x = 0 # 计数器,记录下载了多少张图片
# 创建目录
hero_dir = 'D:\wzry\wzry'
if not os.path.exists(hero_dir):
os.mkdir(hero_dir) try: #使用一个简单的异常处理,防止代码在运行时出现错误
for m in range(len(jsonFile) - 1):
ename = jsonFile[m]['ename'] # 编号
cname = jsonFile[m]['cname'] # 英雄名字
skinName = jsonFile[m]['skin_name'].split('|')
skinNumber = len(skinName) # 下载图片,构造图片网址
for bigskin in range(1, skinNumber + 1):
urlPicture = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(ename) + '/' + str(
ename) + '-bigskin-' + str(bigskin) + '.jpg'
picture = requests.get(urlPicture).content # 获取图片的二进制信息
with open(hero_dir + cname + "-" + skinName[bigskin - 1] + '.jpg', 'wb') as f: # 保存图片
f.write(picture)
x = x + 1
print("正在下载第" + str(x) + "张图片")
except Exception:
print()
else:
print()
下面是我的运行结果

利用python爬取王者荣耀英雄皮肤图片的更多相关文章
- Python爬取 | 王者荣耀英雄皮肤海报
这里只展示代码,具体介绍请点击下方链接. Python爬取 | 王者荣耀英雄皮肤海报 import requests import re import os import time import wi ...
- python 爬取王者荣耀英雄皮肤代码
import os, time, requests, json, re, sys from retrying import retry from urllib import parse "& ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- python学习--第二天 爬取王者荣耀英雄皮肤
今天目的是爬取所有英雄皮肤 在爬取所有之前,先完成一张皮肤的爬取 打开anacond调出编译器Jupyter Notebook 打开王者荣耀官网 下拉找到位于网页右边的英雄/皮肤 点击[+更多] 进入 ...
- Python 爬取 "王者荣耀.英雄壁纸" 过程中的矛和盾
1. 前言 学习爬虫,最好的方式就是自己编写爬虫程序. 爬取目标网站上的数据,理论上讲是简单的,无非就是分析页面中的资源链接.然后下载.最后保存. 但是在实施过程却会遇到一些阻碍. 很多网站为了阻止爬 ...
- 用Python爬取"王者农药"英雄皮肤
0.引言 作为一款现象级游戏,王者荣耀,想必大家都玩过或听过,游戏里中各式各样的英雄,每款皮肤都非常精美,用做电脑壁纸再合适不过了.本篇就来教大家如何使用Python来爬取这些精美的英雄皮肤. 1.环 ...
- 用Python爬取"王者农药"英雄皮肤 原
padding: 10px; border-bottom: 1px solid #d3d3d3; background-color: #2e8b57; } .second-menu-item { pa ...
- python爬取王者荣耀全英雄皮肤
import os import requests url = 'https://pvp.qq.com/web201605/js/herolist.json' herolist = requests. ...
- python 爬取王者荣耀高清壁纸
代码地址如下:http://www.demodashi.com/demo/13104.html 一.前言 打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面 ...
随机推荐
- python中的raise用法
date ; 2019-08-22 15:10:56 try: s = None if s is None: print("s shi kong de ") raise NameE ...
- TCP和TLS/SSL会话细节
TCP数据段格式说明TCP建立连接和断开连接细节Https如何保证通信安全一次Https网络请求通信细节网络数据包分析工具wireshark的使用问题:SYN.ACK.FIN具体含义是什么?TCP建立 ...
- aar api 导出
import fsys; import math; var pidMap = {}; math.randomize(); fsys.enum( "~\lib", "*.* ...
- Python数据处理pdf (中文版带书签)、原书代码、数据集
Python数据处理 前言 xiii第1 章 Python 简介 11.1 为什么选择Python 41.2 开始使用Python 41.2.1 Python 版本选择 51.2.2 安装Python ...
- Flink 滑动窗口使用触发器会触发多个窗口的计算
之前有小伙伴在群里说:滑动窗口使用触发器让每条数据都触发一次计算 但是他并没有得到预期的结果:每条数据都触发一次计算,输出一条结果,而是每天数据都输出了很多条结果 为什么会这样呢? 写了个小案例,来解 ...
- 无法嵌入互操作类型"NationalInstruments.TestStand.Interop.UI.ExecutionViewOptions"。请改用适用的接口
参考一下文章说明, 修改Interop.UI动态库的引入属性为 False,不再报错: VS2010,VS2012,VS2013中,无法嵌入互操作类型“……”,请改用适用的接口的解决方法 在VS2 ...
- CTF 资源
1.<CTF 工具集>包括web工具.渗透环境.隐形工具.逆向工具.漏洞扫描工具.sql注入工具.暴力破解工具.加解密工具等等. 参考地址:https://www.ctftools.com ...
- python:datetime.datetime is not JSON serializable 报错问题解决
问题: 项目使用django开发,返回的数据中有时间字段,当json.dumps()时提示:datetime.datetime is not JSON serializable 解决: import ...
- Arcgis javascript api 动态图层自图层可见性设置
Arcgis javascript api 动态图层自图层可见性设置 子图层管理 rest服务 sublayers sublayer ArcGISDynamicMapServiceLayer 本文主要 ...
- 2019年Java面试题基础系列228道(4)
1.Java 中能创建 volatile 数组吗? 能,Java 中可以创建 volatile 类型数组,不过只是一个指向数组的引用,而不是整个数组.我的意思是,如果改变引用指向的数组,将会受到 vo ...