Hadoop集群分布搭建
一、准备工作
1、最少三台虚拟机或者实体机(官网上是默认是3台),我这边是3台
s1: 10.211.55.18
s2: 10.211.55.19
s3: 10.211.55.20
2、安装JDK
3、配置SSH
4、修改hosts 文件vi /etc/hosts
在文件中添加:
地址 主机名 10.211.55.18 s1 10.211.55.19 s2 10.211.55.20 s3
5、下载hadoop
二、安装hadoop
1、解压hadoop2.9.0
mkdir -r /usr/soft tar -zxvf hadoop2..0.tar.gz -C /usr/soft #解压到/usr/soft
2、配置环境变量(ps:我这边是centos7)
cd /etc/profile.d/ touch hadoop_envi.sh #创建脚本 vi hadoop_envi.sh #编辑脚本
以下都是 hadoop_envi.sh 文件里面内容,也是添加环境变量
HADOOP_INSTALL=/usr/soft/hadoop-2.9. PATH=$PATH:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin export HADOOP_INSTALL export PATH
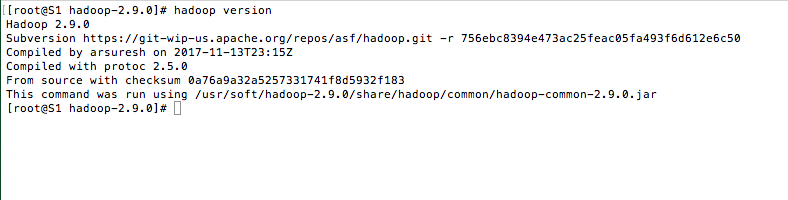
3、测试
hadoop version
三、编写hadoop配置文件,配置文件都在 hadoop2.9.0/etc/hadoop/ 下
1、core-site.xml 通用配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadooptmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
<property>
<name>fs.defaultFS</name> #NameNode ip
<value>hdfs://s1/</value>
</property>
</configuration>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name> #资源管理器的主机
<value>s1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3. hdfs-site.xml 分布式文件相关配置
<configuration> <property>
<name>dfs.name.dir</name>
<value>/home/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/hdsf/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name> #文件块的备份数量 默认3个, 2、3都可以
<value></value>
</property> </configuration>
4. mapre-site.xml 这个问题通过 mapred-site.xml.template复制而来的
<configuration>
<property>
<name>mapreduce.framework.name</name> #MapReduce框架名称
<value>yarn</value>
</property>
</configuration>
5、编辑slave
vi slaves
以下是 slaves 需要添加的内容
s2 #表示s2和s3 为数据节点,s2就是 10.211.55.19,s3就是 10.211.55.20
s3
四、启动hadoop
hadoop namenode -format #

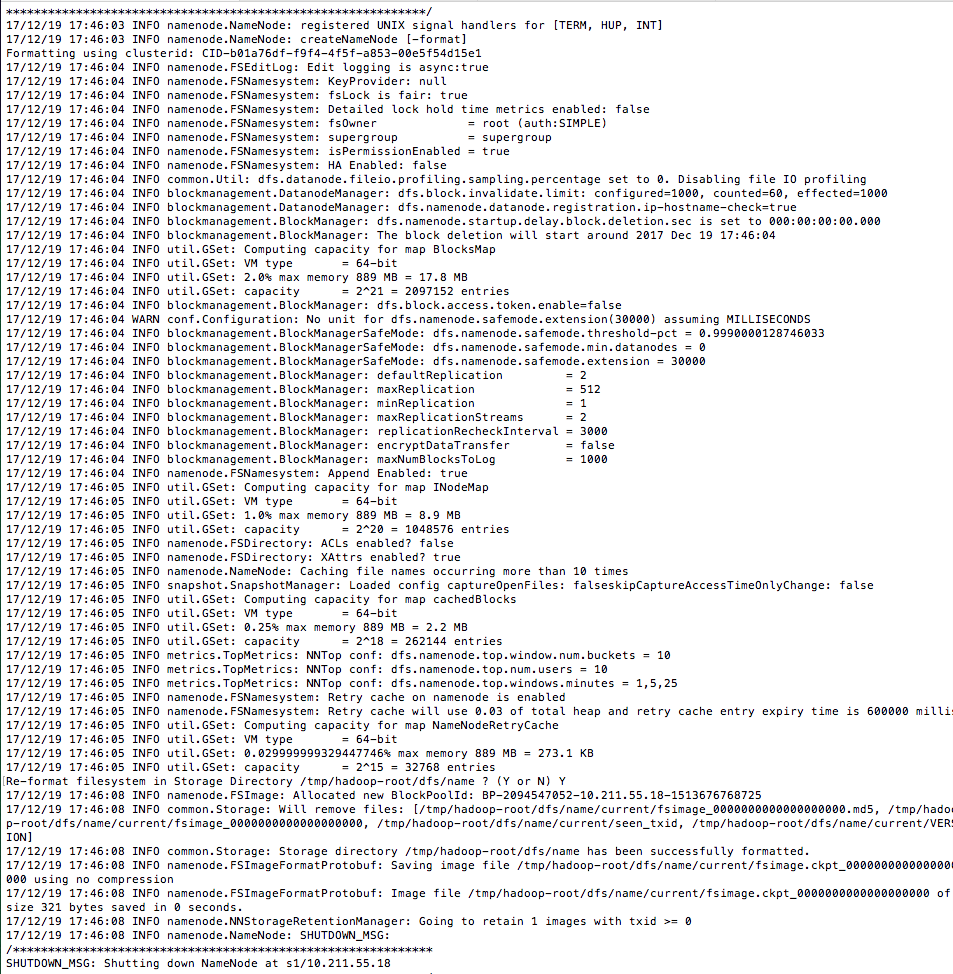
名称节点格式化成功
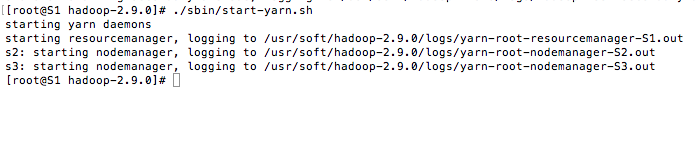
启动 dfs 和 yarn 这两个脚本文件都在 hadoop2.9.0/sbin 下
./sbin/start-dfs.sh

./sbin/start-yarn.sh
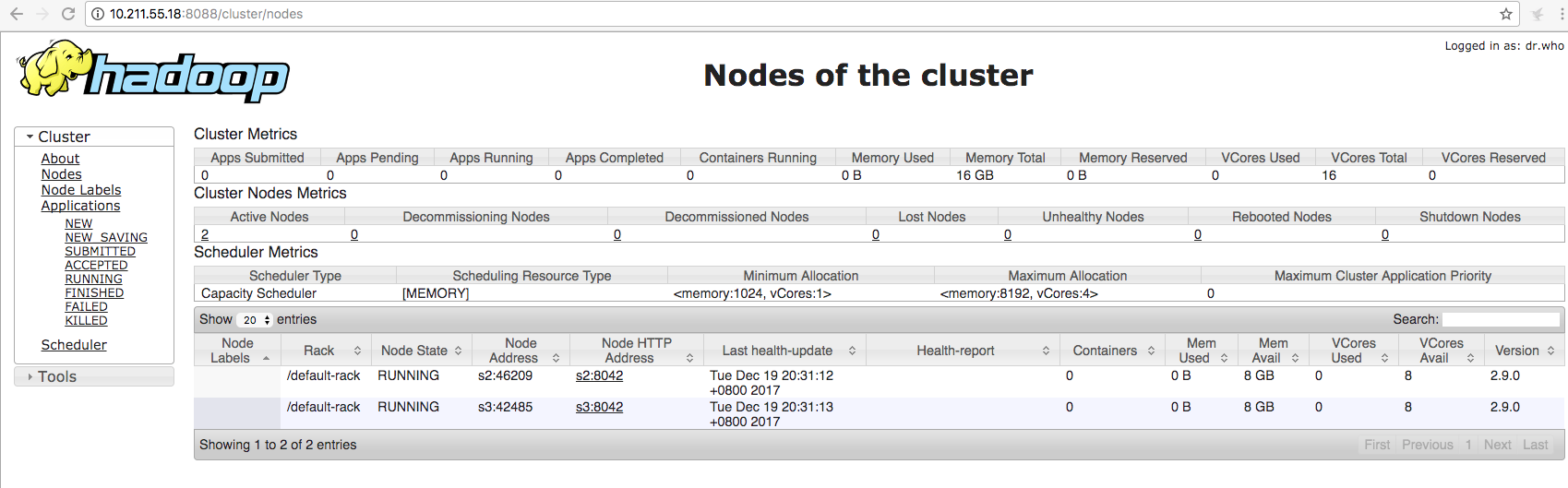
五、测试hadoop
前提:开发8088 和 50070端口 10.211.55.18是namenode 节点
http://10.211.55.18:8088
http://10.211.55.18:50070/

Hadoop集群分布搭建的更多相关文章
- hadoop集群的搭建(分布式安装)
集群 计算机集群是一种计算机系统,他通过一组松散集成的计算机软件和硬件连接起来高度紧密地协同完成计算工作. 集群系统中的单个计算机通常称为节点,通常通过局域网连接. 集群技术的特点: 1.通过多台计算 ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- hadoop集群的搭建与配置(2)
对解压过后的文件进行从命名 把"/usr/hadoop"读权限分配给hadoop用户(非常重要) 配置完之后我们要创建一个tmp文件供以后的使用 然后对我们的hadoop进行配置文 ...
- hadoop集群的搭建
hadoop集群的搭建 1.ubuntu 14.04更换成阿里云源 刚刚开始我选择了nat模式,所有可以连通网络,但是不能ping通,我就是想安装一下mysql,因为安装手动安装mysql太麻烦了,然 ...
- 关于hadoop集群管理系统搭建的规划说明
Hadoop集群管理系统搭建是每个入门级新手都非常头疼的事情,因为你可能花费了很久的时间在搭建运行环境,最终却不知道什么原因无法创建成功.但对新手来说,运行环境搭建不成功的概率还蛮高的. 在之前的分享 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- Hadoop集群上搭建Ranger
There are two types of people in the world. I hate both of them. Hadoop集群上搭建Ranger 在搭建Ranger工程之前,需要完 ...
随机推荐
- 【工具】java发送验证码邮件
文章目录 前言 配置邮箱服务器 代码实现 发送随机验证码与验证 后记 前言 要实现 可以设置格式,附件,抄送等功能,就跟真人操控邮箱发送邮件一样的功能,或许比较难,博主没研究,博主暂时没用到那些功能, ...
- maven基础和基本使用
maven介绍 Maven是基于项目对象模型(POM project object model)实现的,可以通过一小段描述信息(配置)来管理项目的构建,报告和文档的软件项目管理工具. 具体作用: 项目 ...
- Python完成迪杰斯特拉算法并生成最短路径
def Dijkstra(network,s,d):#迪杰斯特拉算法算s-d的最短路径,并返回该路径和代价 print("Start Dijstra Path……") path=[ ...
- MAMP PRO 在osx 10.10 错误处理
新更新的osx10.10之后,启动MAMP会发现Apache无法启动, 处理如下: 1.cd /Applications/MAMP/Library/bin 2.mv envvars _envvars ...
- 前端require代码抽离小技巧
DEMO 文件目录结构 plugin.js // /CommonJS规范 // var exports = module.exports; exports.test = function () { c ...
- Linux磁盘管理系列 — 磁盘配额管理
一.磁盘管理的概念 Linux系统是多用户任务操作系统,在使用系统时,会出现多用户共同使用一个磁盘的情况,如果其中少数几个用户占用了大量的磁盘空间,势必压缩其他用户的磁盘的空间和使用权限.因此,系统管 ...
- MySQL 体系结构及存储引擎
MySQL 原理篇 MySQL 索引机制 MySQL 体系结构及存储引擎 MySQL 语句执行过程详解 MySQL 执行计划详解 MySQL InnoDB 缓冲池 MySQL InnoDB 事务 My ...
- javascript 之 扩展对象
注意点:在js中常见的几种方进行扩展 第一种:ES6提供的 Object.assign(); 第二种:ES5提供的 extend()方法 第三种:Object对象提供的 defineProperty( ...
- Docker可视化管理工具portainer的简单应用
portainer简介 略 安装portainer $ docker pull portainer/portainer$ docker volume create portainer_data $ d ...
- vue+iview tables多个分页实现
如果一个页面有多个分页那么可以把每个page和pageSize放到一个对象中,如下: dataList: { name: 'dataList', // 方便取到dataList对象 id: null, ...