[ML] Decision Tree & Ensembling Metholds
热身:分类问题若干策略
SVM, LR, Decision Tree的比较
同样是分类:SVM、LR、决策树,三者之间有什么优劣势呢?
答:Are decision tree algorithms linear or nonlinear: nonlinear! 更接近 "神经网络"。
一、与"判别式分类"的比较
逻辑回归 LR
LR的优势:
- 对观测样本的概率值输出
- 实现简单高效
- 多重共线性的问题可以通过L2正则化来应对
- 大量的工业界解决方案
- 支持online learning(个人补充)
LR的劣势:
- 特征空间太大时表现不太好
- 对于大量的分类变量无能为力
- 对于非线性特征需要做特征变换
- 依赖所有的样本数据
支持向量机器 SVM
SVM的优点:
- 能够处理大型特征空间
- 能够处理非线性特征之间的相互作用
- 无需依赖整个数据
SVM的缺点:
- 当观测样本很多时,效率并不是很高
- 有时候很难找到一个合适的核函数
决策树
决策树的优点:
- 直观的决策规则
- 可以处理非线性特征
- 考虑了变量之间的相互作用
决策树的缺点:
- 训练集上的效果高度优于测试集,即过拟合[随机森林克服了此缺点]
- 没有将排名分数作为直接结果
二、结论
我总结出了一个工作流程来让大家参考如何决定使用哪个模型:
1. 使用LR试一把总归不会错的,至少是个baseline
2. 看看决策树相关模型例如随机森林,GBDT有没有带来显著的效果提升,即使最终没有用这个模型,也可以用随机森林的结果来去除噪声特征
3. 如果你的特征空间和观测样本都很大,有足够的计算资源和时间,试试SVM吧,
决策树算法
Ref: 算法杂货铺——分类算法之决策树(Decision tree)
一、构造决策树
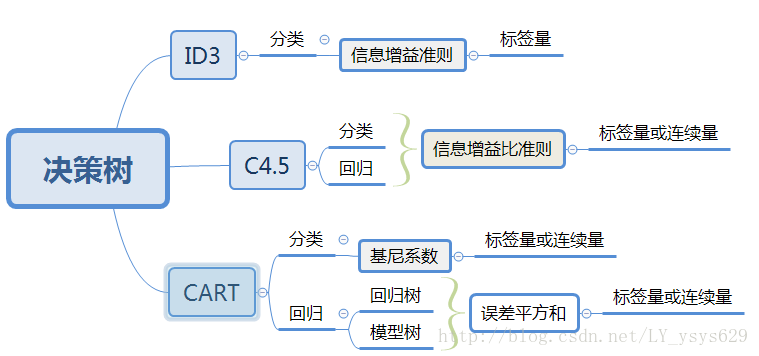
属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。这里介绍ID3和C4.5两种常用算法。
使用属性选择度量来选择将元组最好地划分成不同的类的属性。所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。
二、模型参数
官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeRegressor.html
也可用于 ”回归问题“:回归树,模型树。
决策“森林”
Ensemble method(集成方法),参考博文:机器学习--集成学习(Ensemble Learning)
主流的两种方式
一、Bootstrap Aggregating (缩写:Bagging)
Bootstrap 样本集,“有放回去” 的方式。 举个栗子:构造 Random Forest(随机森林)
(1) 获得 Bootstrap 做为一个 dataset
(2) 随机选择d个特征
开始训练一颗树。

二、Boosting(弱弱变强)
boost算法是基于PAC学习理论(probably approximately correct)而建立的一套集成学习算法(ensemble learning)。
其根本思想在于通过多个简单的弱分类器,构建出准确率很高的强分类器,PAC学习理论证实了这一方法的可行性。
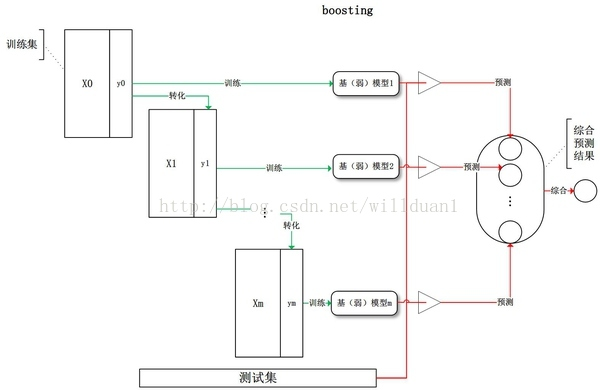
(1)在每一轮如何改变训练数据的权值或概率分布?
通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。
【划分的不好就多重视一点】
(2)通过什么方式来组合弱分类器?
通过加法模型将弱分类器进行 "线性组合",比如如下三种方式:
* AdaBoost(Adaptive boosting)算法:刚开始训练时对每一个训练例赋相等的权重,然后用该算法对训练集训练t轮,每次训练后,对训练失败的训练例赋以较大的权重,也就是让学习算法在每次学习以后更注意学错的样本,从而得到多个预测函数。
通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型。
# AdaBoost Algorithm
from sklearn.ensemble import AdaBoostClassifier
clf = AdaBoostClassifier()
...
clf.fit(x_train,y_train)
clf.predict(x_test)
* GBDT(Gradient Boost Decision Tree),每一次的计算是为了减少上一次的残差,GBDT在残差减少(负梯度)的方向上建立一个新的模型。
# Gradient Boosting
from sklearn.ensemble import GradientBoostingClassifier
clf = GradientBoostingClassifier()
# n_estimators = 100 (default)
# loss function = deviance(default) used in Logistic Regression
clf.fit(x_train,y_train)
clf.predict(x_test)
* XGBoost (Extreme Gradient Boosting),掀起了一场数据科学竞赛的风暴。
# XGBoost
from xgboost import XGBClassifier
clf = XGBClassifier()
# n_estimators = 100 (default)
# max_depth = 3 (default)
clf.fit(x_train,y_train)
clf.predict(x_test)
两者的综合对比
一、Bagging,Boosting 二者之间的区别
1)样本选择上
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
二、决策树与算法框架进行结合
1)Bagging + 决策树 = 随机森林
2)AdaBoost + 决策树 = 提升树 Boosting Tree
3)Gradient Boosting + 决策树 = GBDT
第三种融合策略
一、Stacking(有层次的融合模型)
Ref: 数据挖掘竞赛利器-Stacking和Blending方式
用不同特征训练出来的三个GBDT模型进行融合时,我们会将三个GBDT作为基层模型,在其上在训练一个次学习器(通常为线性模型LR)【有点像mlp】
/* continue ... */
[ML] Decision Tree & Ensembling Metholds的更多相关文章
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
- Spark2 ML包之决策树分类Decision tree classifier详细解说
所用数据源,请参考本人博客http://www.cnblogs.com/wwxbi/p/6063613.html 1.导入包 import org.apache.spark.sql.SparkSess ...
- OpenCV码源笔记——Decision Tree决策树
来自OpenCV2.3.1 sample/c/mushroom.cpp 1.首先读入agaricus-lepiota.data的训练样本. 样本中第一项是e或p代表有毒或无毒的标志位:其他是特征,可以 ...
- (转)Decision Tree
Decision Tree:Analysis 大家有没有玩过猜猜看(Twenty Questions)的游戏?我在心里想一件物体,你可以用一些问题来确定我心里想的这个物体:如是不是植物?是否会飞?能游 ...
- Spark MLlib - Decision Tree源码分析
http://spark.apache.org/docs/latest/mllib-decision-tree.html 以决策树作为开始,因为简单,而且也比较容易用到,当前的boosting或ran ...
- 决策树Decision Tree 及实现
Decision Tree 及实现 标签: 决策树熵信息增益分类有监督 2014-03-17 12:12 15010人阅读 评论(41) 收藏 举报 分类: Data Mining(25) Pyt ...
- Gradient Boosting Decision Tree学习
Gradient Boosting Decision Tree,即梯度提升树,简称GBDT,也叫GBRT(Gradient Boosting Regression Tree),也称为Multiple ...
- 使用Decision Tree对MNIST数据集进行实验
使用的Decision Tree中,对MNIST中的灰度值进行了0/1处理,方便来进行分类和计算熵. 使用较少的测试数据测试了在对灰度值进行多分类的情况下,分类结果的正确率如何.实验结果如下. #Te ...
- Sklearn库例子1:Sklearn库中AdaBoost和Decision Tree运行结果的比较
DisCrete Versus Real AdaBoost 关于Discrete 和Real AdaBoost 可以参考博客:http://www.cnblogs.com/jcchen1987/p/4 ...
随机推荐
- Kotlin重新学习及入门示例
在2017和2018其实已经对Kotlin的基础语法进行了一些学习,但是!!如今已经是2019年,中间间断时间已经很长了,所以准备接下来从0再次出发深入系统完整的来审视一下该语言,毕境如今它的地位是越 ...
- Jmeter性能测试NoHttpResponseException (the target server failed to respond)
采用JMeter做Http性能测试时,在高并发请求的情况下,服务器端并无异常,但是Jmeter端报错NoHttpResponseException (the target server failed ...
- 在idea中如何将一个项目打成war包
s会用clean+package两个组合命令.来进行打包,我的war直接打在了target下面.然后,随时可以找到.war文件
- LoadRunner在Controller场景中配置获取Windows Resources
一.首先需要在被监控Windows服务器端(只支持Windows)进行如下设置: 启动服务: Remote Procedure Call (RPC) RemoteRegistry 操作方法: 按Win ...
- 移动端自适应js
window.addEventListener('resize', setHtmlFontSize) setHtmlFontSize(); function setHtmlFontSize() { v ...
- 有关Django的smallDemo
注: 电脑为Mac,Python解释器为3.5.4 数据库使用的是pymysql模块代替mysqldb 功能: 运行服务器,在login登录界面输入用户名和密码,post到服务器, 通过数据库判断用户 ...
- Selenium3学习中遇到的问题
pytesseract识别验证码 TesseractNotFoundError: tesseract is not installed or it's not in your path brew in ...
- 十八.搭建Nginx服务器、配置网页认证、基于域名的虚拟主机、ssl虚拟主机
配置要求: client:192.168.4.10 proxy:192.168.4.5(eth0) 192.168.2.5(eth1) web1:192.168.2.100 web2:192.168. ...
- BZOJ 4300: 绝世好题 二进制
对于每一个数字拆位,然后维护一个大小为 30 左右的桶即可. code: #include <bits/stdc++.h> #define N 100006 #define setIO(s ...
- Ubuntu下Django+uWSGI+nginx部署
本文采用uwsgi+nginx来部署django 这种方式是将nginx作为服务端前端,将接受web所有的请求,统一管理,Nginx把所有的静态请求自己处理,然后把所有非静态请求通过uwsgi传递给D ...