关于MapReduce的测试
题目:数据清洗以及结果展示
要求:
Result文件数据说明:
Ip:106.39.41.166,(城市)
Date:10/Nov/2016:00:01:02 +0800,(日期)
Day:10,(天数)
Traffic: 54 ,(流量)
Type: video,(类型:视频video或文章article)
Id: 8701(视频或者文章的id)
测试要求:
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
ip: 199.30.25.88
time: 10/Nov/2016:00:01:03 +0800
traffic: 62
文章: article/11325
视频: video/3235
(2)第二阶段:根据提取出来的信息做精细化操作
ip: 城市 city(IP)
time: 2016-11-10 00:01:03
day: 10
traffic: 62
type: article/video
id: 11325
(3)hive数据库表结构:
create table data01(ip string, time string, day string, traffic bigint, type string, id string)
2、数据处理:
·统计最受欢迎的视频/文章的Top10访问次数 (video/article)
·按照地市统计最受欢迎的Top10课程 (ip)
·按照流量统计最受欢迎的Top10课程 (traffic)
3、数据可视化:将统计结果倒入MySql数据库中,通过图形化展示的方式展现出来。
解答:
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
1.1 数据清洗
原始数据格式
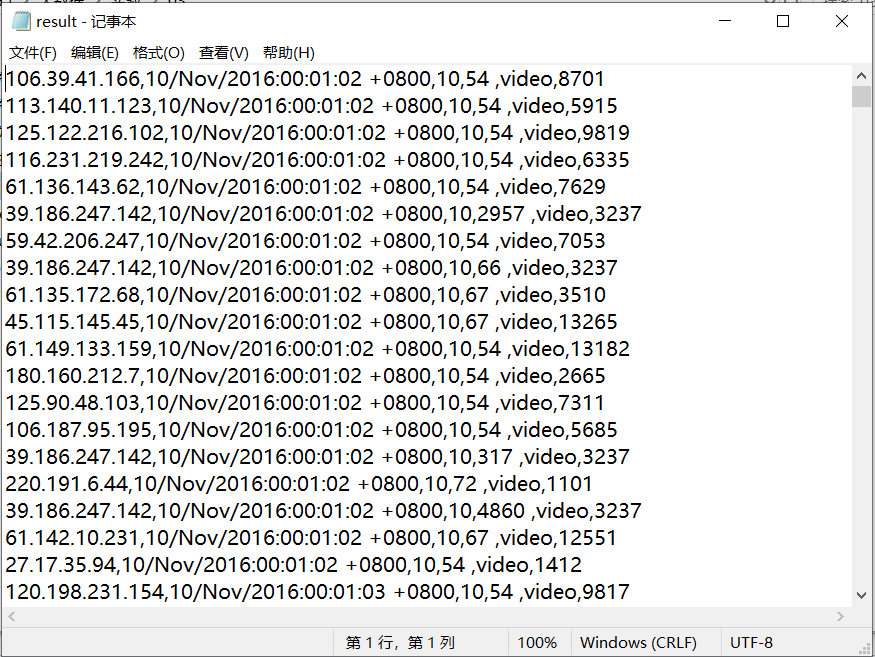
将原始数据文件result.txt上传到HDFS中,然后进行读取清洗
cleanDate.java:(读取清洗)
package com.Use; import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class cleanData {
public static class Map extends Mapper<Object , Text , Text , IntWritable>{
private static Text newKey=new Text();
private static String chage(String data) {
char[] str = data.toCharArray();
String[] time = new String[7];
int j = 0;
int k = 0;
for(int i=0;i<str.length;i++) {
if(str[i]=='/'||str[i]==':'||str[i]==32) {
time[k] = data.substring(j,i);
j = i+1;
k++;
}
}
time[k] = data.substring(j, data.length()); switch(time[1]) { case "Jan":time[1]="01";break; case
"Feb":time[1]="02";break; case "Mar":time[1]="03";break; case
"Apr":time[1]="04";break; case "May":time[1]="05";break; case
"Jun":time[1]="06";break; case "Jul":time[1]="07";break; case
"Aug":time[1]="08";break; case "Sep":time[1]="09";break; case
"Oct":time[1]="10";break; case "Nov":time[1]="11";break; case
"Dec":time[1]="12";break; } data = time[2]+"-"+time[1]+"-"+time[0]+" "+time[3]+":"+time[4]+":"+time[5];
return data;
}
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
String line=value.toString();
System.out.println(line);
String arr[]=line.split(","); String ip = arr[0];
String date = arr[1];
String day = arr[2];
String traffic = arr[3];
String type = arr[4];
String id = arr[5]; date = chage(date);
traffic = traffic.substring(0, traffic.length()-1); newKey.set(ip+'\t'+date+'\t'+day+'\t'+traffic+'\t'+type);
//newKey.set(ip+','+date+','+day+','+traffic+','+type);
int click=Integer.parseInt(id);
context.write(newKey, new IntWritable(click));
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>{
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
for(IntWritable val : values){
context.write(key, val);
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf=new Configuration();
System.out.println("start");
Job job =new Job(conf,"cleanData");
job.setJarByClass(cleanData.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in=new Path("hdfs://192.168.137.112:9000/tutorial/in/result.txt");
Path out=new Path("hdfs://192.168.137.112:9000/tutorial/out");
FileInputFormat.addInputPath(job,in);
FileOutputFormat.setOutputPath(job,out);
System.exit(job.waitForCompletion(true) ? 0 : 1); }
}
CleanData
清洗后格式
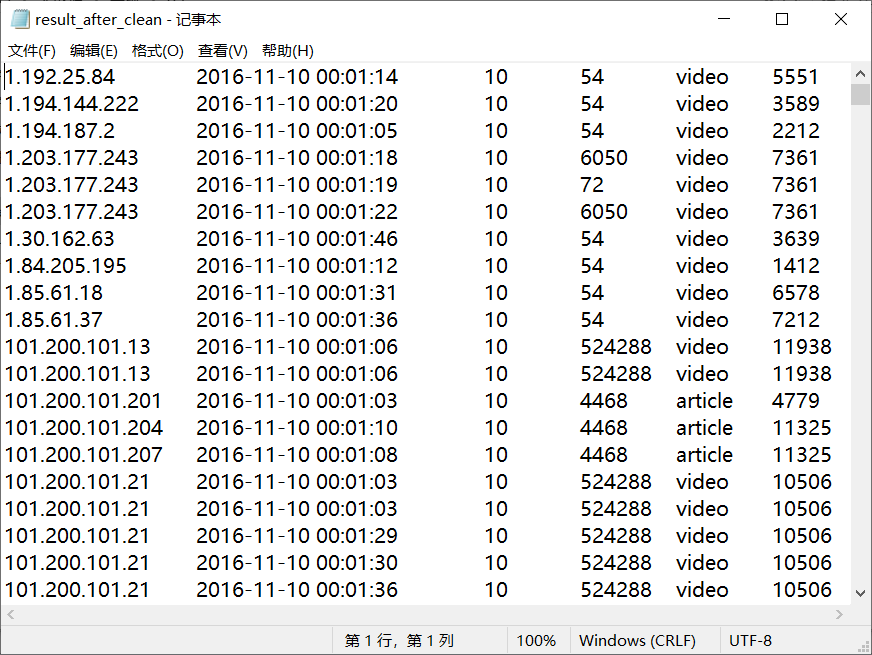
2、数据处理:
2.1统计最受欢迎的视频/文章的Top10访问次数 (video/article)
读取清洗后数据的.txt文件进行mapreduce
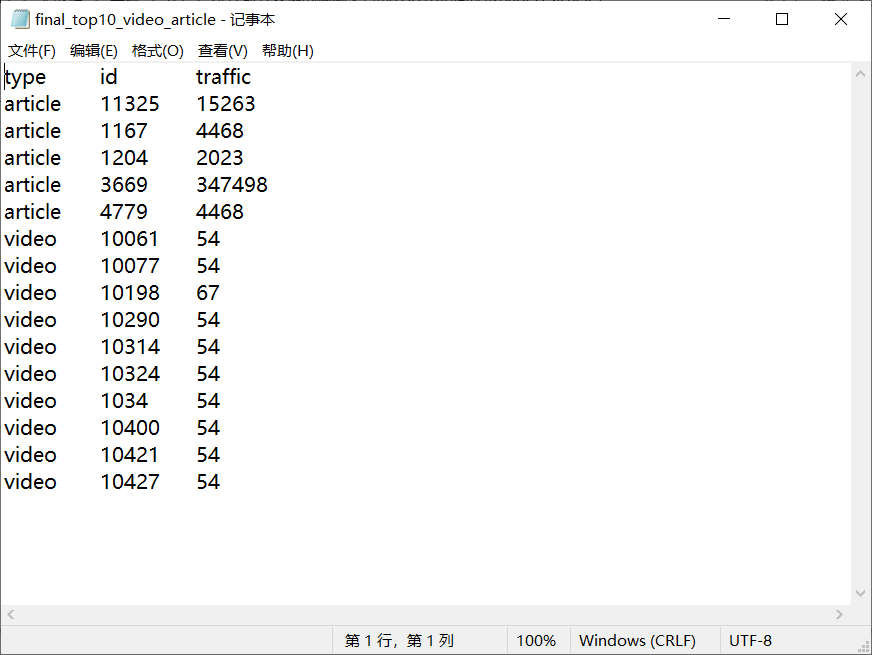
2.2按照地市统计最受欢迎的Top10课程 (ip)
读取清洗后数据的.txt文件进行mapreduce
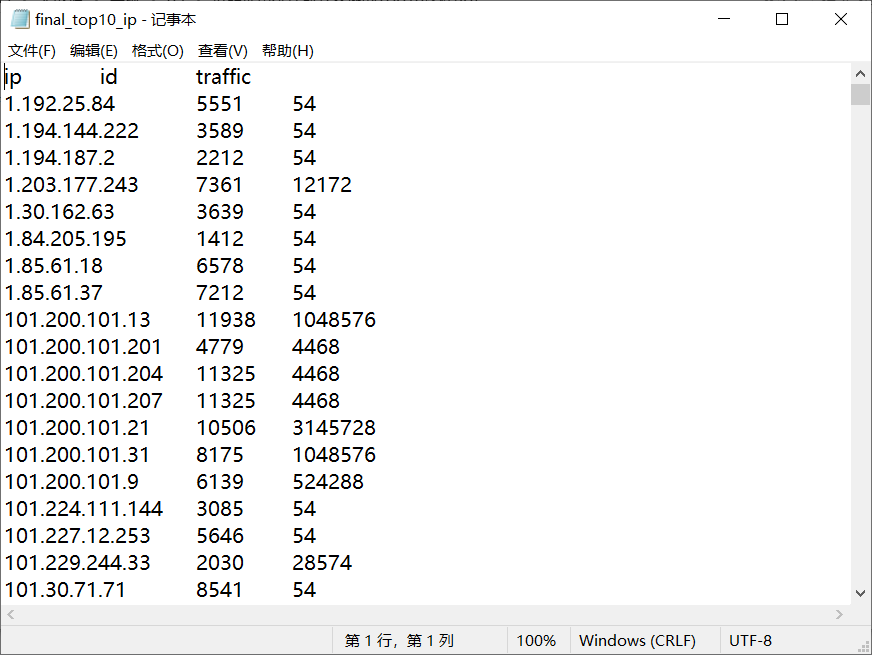
2.3按照流量统计最受欢迎的Top10课程 (traffic)
读取清洗后数据的.txt文件进行mapreduce
3、数据可视化:将统计结果倒入MySql数据库中,通过图形化展示的方式展现出来。
2.2的统计结果:图形化展示暂未写出
2.1、2.3的统计结果:将统计结果的.txt导入到mysql数据库中,用EChart图形化进行可视化
-----------------------------------------------------------------------------------------------------------------------------
1、2题的代码:https://github.com/457352727/DSJ_tutorial01
3题的代码:https://github.com/457352727/DSJ_tutorial01_web
关于MapReduce的测试的更多相关文章
- mapreduce课堂测试结果
package mapreduce; import java.io.IOException; import java.util.StringTokenizer; import org.apache.h ...
- 使用Python实现Hadoop MapReduce程序
转自:使用Python实现Hadoop MapReduce程序 英文原文:Writing an Hadoop MapReduce Program in Python 根据上面两篇文章,下面是我在自己的 ...
- Hadoop系列(三):hadoop基本测试
下面是对hadoop的一些基本测试示例 Hadoop自带测试类简单使用 这个测试类名叫做 hadoop-mapreduce-client-jobclient.jar,位置在 hadoop/share/ ...
- 为集群配置Impala和Mapreduce
FROM: http://www.importnew.com/5881.html -- 扫描加关注,微信号: importnew -- 原文链接: Cloudera 翻译: ImportNew.com ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop 全分布模式 平台搭建
现将博客搬家至CSDN,博主改去CSDN玩玩~ 传送门:http://blog.csdn.net/sinat_28177969/article/details/54138163 Ps:主要答疑区在本帖 ...
- hadoop-ha QJM 架构部署
公司之前老的hadoop集群namenode有单点风险,最近学习此链接http://www.binospace.com/index.php /hdfs-ha-quorum-journal-manage ...
- Cloudera Hadoop 5& Hadoop高阶管理及调优课程(CDH5,Hadoop2.0,HA,安全,管理,调优)
1.课程环境 本课程涉及的技术产品及相关版本: 技术 版本 Linux CentOS 6.5 Java 1.7 Hadoop2.0 2.6.0 Hadoop1.0 1.2.1 Zookeeper 3. ...
- Ambari安装之部署单节点集群
前期博客 大数据领域两大最主流集群管理工具Ambari和Cloudera Manger Ambari架构原理 Ambari安装之Ambari安装前准备(CentOS6.5)(一) Ambari安装之部 ...
随机推荐
- hdu 1576
老生常谈的问题 利用同余的思想 抽象出表达式 bx+9973y=n 然后用bx+9973y=1(题目给出了gcd(b,9973)=1) 求出基础解 y0 bx+9973y=n 的 基础解y=n*y0 ...
- id和class的区别
id和class是定义css样式用到的,不同的是定义样式时的写法不一样,使用id选择样式时,定义的格式为 #main{width:20px;} ,使用class时用到的是 .main{width:20 ...
- Android 直连SQL
在工作中遇到需求需要Android直接连接SQL,看了一些人说不建议直连,但我对性能没有要求,甚至说只要在局域网内能够使用就行,简单说把手机当作一个简单的移动操作点. 代码的话,网上都有比如: htt ...
- 关于mysql installer 的安装和环境变量配置
MySQL针对不同的用户提供了2中不同的版本: MySQL Community Server:社区版.由MySQL开源社区开发者和爱好者提供技术支持,对开发者开放源代码并提供免费下载. MySQL E ...
- tensorflow-解决3个问题
问题一:对特征归一化 Min-Max Scaling: X′=a+(X−Xmin)(b−a)/(Xmax−Xmin) # Problem 1 - Implement Min-Max scaling f ...
- 上传图片,语音,和富文本(webuploader,dropzone, froala)
首先是上传图片,使用的百度webuploader 自己修改后可以实例化多个uploader对象: HTML: <!DOCTYPE html> <html xmlns="ht ...
- windows环境下,kafka常用命令
创建topics kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partition 3 - ...
- Action向视图传值的6种方式(转)
在使用ASP.NET MVC进行项目开发时,经常会碰到从Action向视图传值的问题,今天我就把我所知道的方式总结了一下,分成了以下六种: 1.使用ViewData进行传值 在Action中,有如下代 ...
- linux获取某一个网卡的ipv4地址
ip a show ens33 | grep inet | grep -v inet6 | awk '{print $2}' | awk -F '/' '{print $1}'
- PAT Basic 1021 个位数统计 (15 分)
给定一个 k 位整数 1 (0, ,, dk−1>0),请编写程序统计每种不同的个位数字出现的次数.例如:给定 0,则有 2 个 0,3 个 1,和 1 个 3. 输入格式: 每个输入包含 ...