用sqoop将mysql的数据导入到hive表中
1:先将mysql一张表的数据用sqoop导入到hdfs中
准备一张表

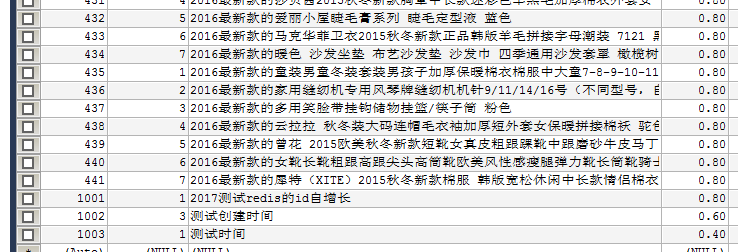
需求 将 bbs_product 表中的前100条数据导 导出来 只要id brand_id和 name 这3个字段
数据存在 hdfs 目录 /user/xuyou/sqoop/imp_bbs_product_sannpy_ 下
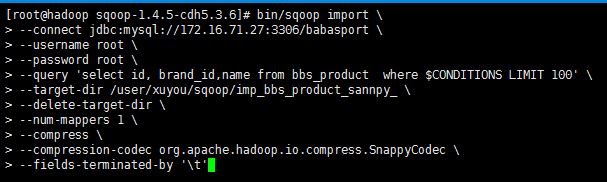
bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--query 'select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100' \
--target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_ \
--delete-target-dir \
--num-mappers 1 \
--compress \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--fields-terminated-by '\t'
ps: 如果导出的数据库是mysql 则可以添加一个 属性 --direct
bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--query 'select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100' \
--target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_ \
--delete-target-dir \
--num-mappers 1 \
--compress \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--direct \
--fields-terminated-by '\t'
加了 direct 属性在导出mysql数据库表中的数据会快一点 执行的是mysq自带的导出功能
第一次执行所需要的时间

第二次执行所需要的时间 (加了direct属性)

执行成功

2:启动hive 在hive中创建一张表
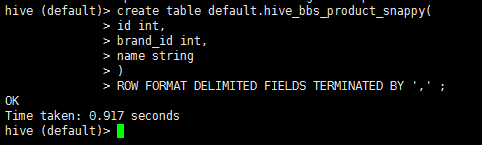
drop table if exists default.hive_bbs_product_snappy ;
create table default.hive_bbs_product_snappy(
id int,
brand_id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
3:将hdfs中的数据导入到hive中
load data inpath '/user/xuyou/sqoop/imp_bbs_product_sannpy_' into table default.hive_bbs_product_snappy ;

4:查询 hive_bbs_product_snappy 表
select * from hive_bbs_product_snappy;

此时hdfs 中原数据没有了

然后进入hive的hdfs存储位置发现

注意 :sqoop 提供了 直接将mysql数据 导入 hive的 功能 底层 步骤就是以上步骤
创建一个文件 touch test.sql 编辑文件 vi test.sql
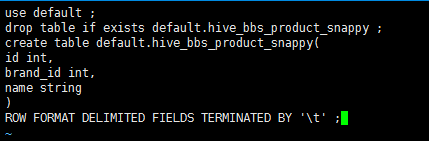
use default;
drop table if exists default.hive_bbs_product_snappy ;
create table default.hive_bbs_product_snappy(
id int,
brand_id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
在 启动hive的时候 执行 sql脚本
bin/hive -f /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/test.sql


执行sqoop直接导入hive的功能
bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--table bbs_product \
--fields-terminated-by '\t' \
--delete-target-dir \
--num-mappers 1 \
--hive-import \
--hive-database default \
--hive-table hive_bbs_product_snappy
看日志输出可以看出 在执行map任务之后 又执行了load data

查询 hive 数据

用sqoop将mysql的数据导入到hive表中的更多相关文章
- 用sqoop将mysql的数据导入到hive表
一.先将mysql一张表的数据用sqoop导入到hdfs 1.1.先在mysql中准备一张测试用的表 mysql> desc user_info; +-----------+---------- ...
- 11.把文本文件的数据导入到Hive表中
先在hive里面创建一个表 create table mydb2.t3(id int,name string,age int) row format delimited fields terminat ...
- 使用 sqoop 将mysql数据导入到hive表(import)
Sqoop将mysql数据导入到hive表中 先在mysql创建表 CREATE TABLE `sqoop_test` ( `id` ) DEFAULT NULL, `name` varchar() ...
- 使用spark将内存中的数据写入到hive表中
使用spark将内存中的数据写入到hive表中 hive-site.xml <?xml version="1.0" encoding="UTF-8" st ...
- MYSQL(将数据加载到表中)
1. 创建和选择数据库 mysql> CREATE DATABASE menagerie; mysql> USE menagerie Database changed 2. 创建表 mys ...
- 把HDFS上的数据导入到Hive中
1. 首先下载测试数据,数据也可以创建 http://files.grouplens.org/datasets/movielens/ml-latest-small.zip 2. 数据类型与字段名称 m ...
- 如何将hive表中的数据导出
近期经常将现场的数据带回公司测试,所以写下该文章,梳理一下思路. 1.首先要查询相应的hive表,比如我要将c_cons这张表导出,我先查出hive中是否有这张表. 查出数据,证明该表在hive中存在 ...
- Talend 将Oracle中数据导入到hive中,根据系统时间设置hive分区字段
首先,概览下任务图: 流程是,先用tHDFSDelete将hdfs上的文件删除掉,然后将oracle中的机构表中的数据导入到HDFS中:建立hive连接->hive建表->tJava获取系 ...
- 将DataFrame数据如何写入到Hive表中
1.将DataFrame数据如何写入到Hive表中?2.通过那个API实现创建spark临时表?3.如何将DataFrame数据写入hive指定数据表的分区中? 从spark1.2 到spark1.3 ...
随机推荐
- sed条件不修改匹配
sed '/^echo/!s/text/subtext/g' 如果是以echo开始行首的行就不进行替换. 参考sed substitution conditional
- Scrum 项目 5.0
5.0--------------------------------------------------- 1.团队成员完成自己认领的任务. 2.燃尽图:理解.设计并画出本次Sprint的燃尽图的理 ...
- crontab笔记
* * * * * root rm -f /var/spool/cron/lastrun/cron.hourly > out.file 第一部分:执行的周期与时间 ...
- $(document).click() 在苹果手机上不能正常运行解决方案
本来是如下一段跳转代码,发现在安卓和微信开发者工具上都能正常运行,但是苹果手机就不行了. $(document).on('click', '.url', function(){ location.hr ...
- sql 两列数据交换
MSSQL的处理方法 update table1 set field_1 = field_2, field_2 = field_1 可是MySQL就不能这样写,不然一列会覆盖另一列记录 MyS ...
- java 集合 父类的使用子类的方法时候 底层自动转型为子类的数据类型
跟继承多态不一样 继承多态需要显示转型
- POJ 3276 Face The Right Way(前缀和优化)
题意:有长度为N的01串,有一个操作可以选择连续K个数字取反,求最小的操作数和最小的K使得最后变成全1串.(N<=5000) 由于K是不定的,无法高斯消元. 考虑枚举K,求出最小的操作数. 显然 ...
- 【bzoj5173】[Jsoi2014]矩形并 扫描线+二维树状数组区间修改区间查询
题目描述 JYY有N个平面坐标系中的矩形.每一个矩形的底边都平行于X轴,侧边平行于Y轴.第i个矩形的左下角坐标为(Xi,Yi),底边长为Ai,侧边长为Bi.现在JYY打算从这N个矩形中,随机选出两个不 ...
- android面试(4)---文件存储
1.sharePreference? SharedPreferences类,它是一个轻量级的存储类,特别适合用于保存软件配置参数. SharedPreferences保存数据,其背后是用xml文件存放 ...
- 【Mybatis】<foreach>标签在mybatis中的使用
mapper.xml如下: <select id="selectCkspcb" parameterType="java.util.Map" resultT ...