Java NIO学习-预备知识
java NIO加入了Channels、Buffers、Selector。通过他们可以为java的io添加非阻塞IO。
一、对于经典java IO库
1、除了Buffered开头的类,其他均没有加缓冲区,除非手动添加缓冲区
byte[] buffer = new byte[64];
inputStream.read(buffer);
这样是可以使用缓冲区的,且性能比buffered的类都要好(因为buffered要考虑多线程的同步,所以性能没有那么好)
但是使用buffer数组是不确定的,因为不能保证正好取到一行的行末,有时候没有buffered类好用。
2、经典io是标准的同步阻塞模型,即在read的过程中,会阻塞当前线程,直到取完数据。而一个系统,io(磁盘io,网络io等硬件io)往往是系统瓶颈
所以经典的同步阻塞模型,会花很多的时间在系统IO上,高速的CPU与内存就会被白白浪费掉。
CPU到内部缓存速度最快,CPU到内存速度也非常快,而CPU控制硬件IO把IO数据加载到内存中则是非常慢的。
二、NIO带来了哪些新功能
1、四种模型:
(1)、同步阻塞:同步是对于线程而言的,如果进行IO的操作是当前线程,则为同步的,所以同步阻塞会导致当前线程阻塞,一般来说java中会开一个独立的线程进行同步阻塞的操作,以免程序假死。这是经典模型。

同步阻塞IO
用户需要等待read将socket中的数据读取到buffer后,才继续处理接收的数据。整个IO请求的过程中,用户线程是被阻塞的,这导致用户在发起IO请求时,不能做任何事情,对CPU的资源利用率不够。
(2)、同步非阻塞:同样是在一个线程中,不同的在于调用read()方法后立即返回,不阻塞。到底有没有获取数据,仍然需要我们在当前线程中判断read()的返回值,直到read()到值时再进行其他操作。
与同步阻塞相比,阻塞的权限交给了代码编写者,同步阻塞是由jvm进行的阻塞(可能描述不标准),而同步非阻塞,其实还是需要我们在当前线程中轮训是否获取数据了,阻塞权交给了程序员。
代码中往往还是要有阻塞的代码出现,如:
while (inputStream.read(buffer) >=0) {
if (buffer.length>0) {
dosometing();
}
}
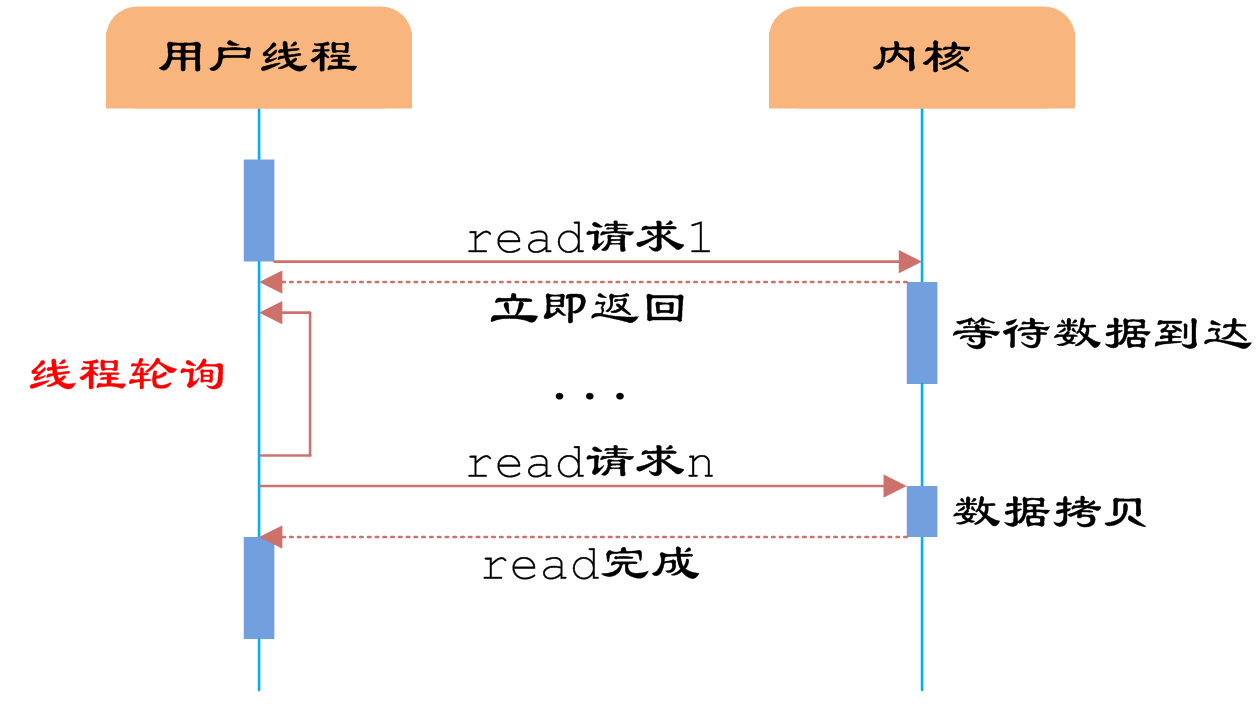
同步非阻塞IO
用户需要不断地调用read,尝试读取socket中的数据,直到读取成功后,才继续处理接收的数据。整个IO请求的过程中,虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
(3)、IO多路复用:
IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题。 
多路分离函数select
用户首先将需要进行IO操作的socket添加到select中,然后阻塞等待select系统调用返回。当数据到达时,socket被激活,select函数返回。用户线程正式发起read请求,读取数据并继续执行。
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
select(socket);
while(1) {
sockets = select();
for(socket in sockets) {
if(can_read(socket)) {
read(socket, buffer);
process(buffer);
}
}
}
这里select()阻塞时,其实是在轮训等待注册到select中的socket,一旦有一个可读,就解除阻塞。
其中while循环前将socket添加到select监视中,然后在while内一直调用select获取被激活的socket,一旦socket可读,便调用read函数将socket中的数据读取出来。
然而,使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率(后面可以看到,通过channel注册时添加关注事件,SelectionKey中有事件类型)。
IO多路复用模型使用了Reactor设计模式实现了这一机制。
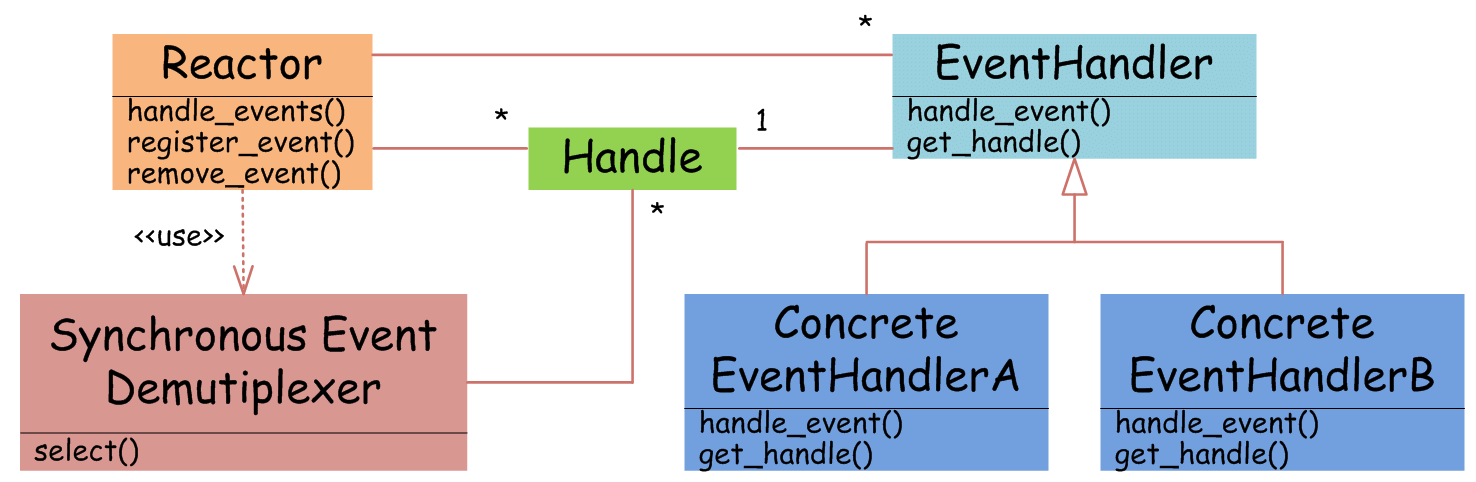
EventHandler抽象类表示IO事件处理器,它拥有IO文件句柄Handle(通过get_handle获取),以及对Handle的操作handle_event(读/写等)。继承于EventHandler的子类可以对事件处理器的行为进行定制。Reactor类用于管理EventHandler(注册、删除等),并使用handle_events实现事件循环,不断调用同步事件多路分离器(一般是内核)的多路分离函数select,只要某个文件句柄被激活(可读/写等),select就返回(阻塞),handle_events就会调用与文件句柄关联的事件处理器的handle_event进行相关操作。

通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。
用户需要重写EventHandler的handle_event函数进行读取数据、处理数据的工作,用户线程只需要将自己的EventHandler注册到Reactor即可。
事件循环不断地调用select获取被激活的socket,然后根据获取socket对应的EventHandler,执行器handle_event函数即可。
IO多路复用是最常使用的IO模型,但是其异步程度还不够“彻底”,因为它使用了会阻塞线程的select系统调用。因此IO多路复用只能称为异步阻塞IO,而非真正的异步IO。
(4)、“真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,事件循环将文件句柄的状态事件通知给用户线程,由用户线程自行读取数据、处理数据。而在异步IO模型中,当用户线程收到通知时,数据已经被内核读取完毕,并放在了用户线程指定的缓冲区内,内核在IO完成后通知用户线程直接使用即可。
异步IO模型使用了Proactor设计模式实现了这一机制。

Proactor模式和Reactor模式在结构上比较相似,不过在用户(Client)使用方式上差别较大。Reactor模式中,用户线程通过向Reactor对象注册感兴趣的事件监听,然后事件触发时调用事件处理函数。而Proactor模式中,用户线程将AsynchronousOperation(读/写等)、Proactor以及操作完成时的CompletionHandler注册到AsynchronousOperationProcessor。AsynchronousOperationProcessor使用Facade模式提供了一组异步操作API(读/写等)供用户使用,当用户线程调用异步API后,便继续执行自己的任务。AsynchronousOperationProcessor 会开启独立的内核线程执行异步操作,实现真正的异步。当异步IO操作完成时,AsynchronousOperationProcessor将用户线程与AsynchronousOperation一起注册的Proactor和CompletionHandler取出,然后将CompletionHandler与IO操作的结果数据一起转发给Proactor,Proactor负责回调每一个异步操作的事件完成处理函数handle_event。虽然Proactor模式中每个异步操作都可以绑定一个Proactor对象,但是一般在操作系统中,Proactor被实现为Singleton模式,以便于集中化分发操作完成事件。

异步IO模型中,用户线程直接使用内核提供的异步IO API发起read请求,且发起后立即返回,继续执行用户线程代码。不过此时用户线程已经将调用的AsynchronousOperation和CompletionHandler注册到内核,然后操作系统开启独立的内核线程去处理IO操作。当read请求的数据到达时,由内核负责读取socket中的数据,并写入用户指定的缓冲区中。最后内核将read的数据和用户线程注册的CompletionHandler分发给内部Proactor,Proactor将IO完成的信息通知给用户线程(一般通过调用用户线程注册的完成事件处理函数),完成异步IO。
用户需要重写CompletionHandler的handle_event函数进行处理数据的工作,参数buffer表示Proactor已经准备好的数据,用户线程直接调用内核提供的异步IO API,并将重写的CompletionHandler注册即可。
相比于IO多路复用模型,异步IO并不十分常用,不少高性能并发服务程序使用IO多路复用模型+多线程任务处理的架构基本可以满足需求。况且目前操作系统对异步IO的支持并非特别完善,更多的是采用IO多路复用模型模拟异步IO的方式(IO事件触发时不直接通知用户线程,而是将数据读写完毕后放到用户指定的缓冲区中)。Java7之后已经支持了异步IO,感兴趣的读者可以尝试使用。
这个模式被NodeJS使用,而系统支持程度上,Windows提供了IOCP进行异步IO,Linux提供的是epoll,FreeBSD提供了kqueue。
- 只有IOCP是asynchronous I/O,其他机制或多或少都会有一点阻塞。
- select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
- epoll, kqueue是Reacor模式,IOCP是Proactor模式。
- java nio包是select模型。。
Java NIO学习-预备知识的更多相关文章
- Java NIO 学习笔记(六)----异步文件通道 AsynchronousFileChannel
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
- Java NIO 学习笔记(一)----概述,Channel/Buffer
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
- Java NIO学习与记录(八): Reactor两种多线程模型的实现
Reactor两种多线程模型的实现 注:本篇文章例子基于上一篇进行:Java NIO学习与记录(七): Reactor单线程模型的实现 紧接着上篇Reactor单线程模型的例子来,假设Handler的 ...
- Java NIO学习笔记
Java NIO学习笔记 一 基本概念 IO 是主存和外部设备 ( 硬盘.终端和网络等 ) 拷贝数据的过程. IO 是操作系统的底层功能实现,底层通过 I/O 指令进行完成. 所有语言运行时系统提供执 ...
- 零拷贝详解 Java NIO学习笔记四(零拷贝详解)
转 https://blog.csdn.net/u013096088/article/details/79122671 Java NIO学习笔记四(零拷贝详解) 2018年01月21日 20:20:5 ...
- Java NIO 学习笔记(七)----NIO/IO 的对比和总结
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
- Java NIO 学习笔记(五)----路径、文件和管道 Path/Files/Pipe
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
- Java NIO 学习笔记(四)----文件通道和网络通道
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
- Java NIO 学习笔记(三)----Selector
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
随机推荐
- linux rar安装
1.wget http://www.rarsoft.com/rar_CN/rarlinux-3.9.3.tar.gz 2.tar 3.make && make install; 4.需 ...
- 关于网格比较工具metro使用的几点注意事项
Metro作为一个非常好用的简化网格比较工具,在科研界几乎算是标准了.不过很多比较牛的作者会使用自己设计的一些比较算法,但是如果metro够用了也就不必那么麻烦了,毕竟Metro使用的方法还算是很成熟 ...
- 2.Hadoop集群搭建之Hadoop(包含HDFS和Yarn)安装
前期准备 下载JDK 6.0以上版本 下载Hadoop 2.4.1 1. 安装JDK 因为Hadoop是Java开发的,所以需要安装JDK,建议JDK 6.0以上. 解压JDK tar -zxvf J ...
- strncmp memcmp区别
内部实现:前者逐每个字符进行比较,并判当前字符是否为0: 后者逐内存块进行比较. 效率:后者自然要优,不论从内部实现上,还是系统优化上. 场景:后者无法替代前者.在项目中遇到一种情况,两个字符串比较, ...
- java求最长公共子串的长度
1这道题目就是给定两个字符串,然后求这两个字符串的最长公共子串的最大长度,假设我的f()方法是来求两个字符串的最大公共子串,从头开始逐一比较,如果相等,则 继续调用这个方法,使得递归的长度+1,如果不 ...
- 【SPOJ - SUBLEX】Lexicographical Substring Search 【后缀自动机+dp】
题意 给出一个字符串和q个询问,每个询问给出一个整数k,输出第k大得子串. 分析 建后缀自动机,利用匹配边来解决.设d[v]为从状态v开始有多少不同的路径.这个显然是可以递推出来的.然后对于每个询问, ...
- 【HDU 6191】Query on A Tree 【可持久化字典树】
题目 给出一棵有n个结点的树,树根是1,每个结点给出一个value.然后给出q个询问,每个询问给出两个整数u和x,你要在以u结点为根的子树中找出一个结点v,使得val[v] xor x最大, 并输出这 ...
- SQL 中怎么查询数据库中具有的表、存储过程、试图数目、总触发器数、作业数
用户表:select count(*) 总表数 from sysobjects where xtype='u' 刚才那个是用户表,下面这个是系统表加用户表: select count(*) 总表数 f ...
- redis 面试题2
使用过Redis分布式锁么,它是什么回事? 先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放. 这时候对方会告诉你说你回答得不错,然后接着问如果在setnx之后执行 ...
- word 标题序号
设置标题的序号. 1>设置二级标题的序号 步骤一: 步骤二: 步骤三: 步骤四: 2>设置三级标题的序号 程序员的基础教程:菜鸟程序员