【机器学习】集成学习之sklearn中的xgboost基本用法
原创博文,转载请注明出处!本文代码的github地址 博客索引地址
1.数据集
数据集使用sklearn自带的手写数字识别数据集mnist,通过函数datasets导入。mnist共1797个样本,8*8个特征,标签为0~9十个数字。
1 ### 载入数据
2 from sklearn import datasets # 载入数据集
3 digits = datasets.load_digits() # 载入mnist数据集
4 print(digits.data.shape) # 打印输入空间维度
5 print(digits.target.shape) # 打印输出空间维度
6 """
7 (1797, 64)
8 (1797,)
9 """
2.数据集分割
sklearn.model_selection中train_test_split函数划分数据集,其中参数test_size为测试集所占的比例,random_state为随机种子(为了能够复现实验结果而设定)。
1 ### 数据分割
2 from sklearn.model_selection import train_test_split # 载入数据分割函数train_test_split
3 x_train,x_test,y_train,y_test = train_test_split(digits.data, # 特征空间
4 digits.target, # 输出空间
5 test_size = 0.3, # 测试集占30%
6 random_state = 33) # 为了复现实验,设置一个随机数
7
3.模型相关(载入模型--训练模型--模型预测)
XGBClassifier.fit()函数用于训练模型,XGBClassifier.predict()函数为使用模型做预测。
1 ### 模型相关
2 from xgboost import XGBClassifier
3 model = XGBClassifier() # 载入模型(模型命名为model)
4 model.fit(x_train,y_train) # 训练模型(训练集)
5 y_pred = model.predict(x_test) # 模型预测(测试集),y_pred为预测结果
4.性能评估
sklearn.metrics中accuracy_score函数用来判断模型预测的准确度。
1 ### 性能度量
2 from sklearn.metrics import accuracy_score # 准确率
3 accuracy = accuracy_score(y_test,y_pred)
4 print("accuarcy: %.2f%%" % (accuracy*100.0))
5
6 """
7 95.0%
8 """
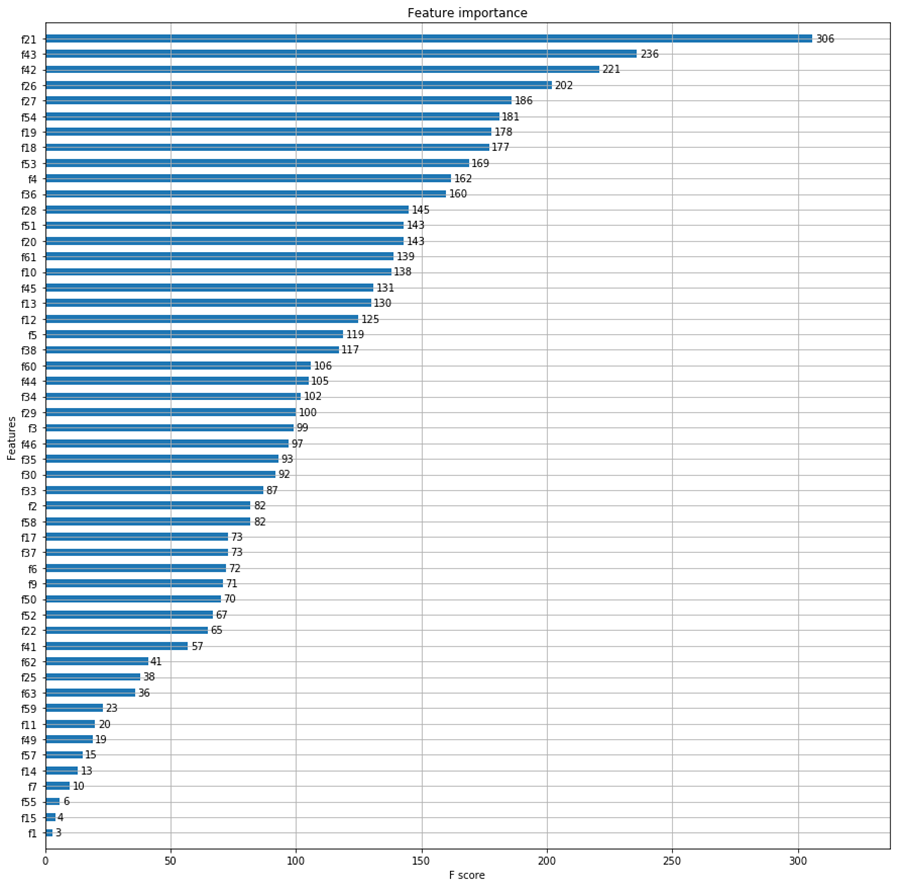
5.特征重要性
xgboost分析了特征的重要程度,通过函数plot_importance绘制图片。
1 ### 特征重要性
2 import matplotlib.pyplot as plt
3 from xgboost import plot_importance
4 fig,ax = plt.subplots(figsize=(10,15))
5 plot_importance(model,height=0.5,max_num_features=64,ax=ax)
6 plt.show()
6.完整代码
1 # -*- coding: utf-8 -*-
2 """
3 ###############################################################################
4 # 作者:wanglei5205
5 # 邮箱:wanglei5205@126.com
6 # 代码:http://github.com/wanglei5205
7 # 博客:http://cnblogs.com/wanglei5205
8 # 目的:xgboost基本用法
9 ###############################################################################
10 """
11 ### load module
12 from sklearn import datasets
13 from sklearn.model_selection import train_test_split
14 from xgboost import XGBClassifier
15 from sklearn.metrics import accuracy_score
16
17 ### load datasets
18 digits = datasets.load_digits()
19
20 ### data analysis
21 print(digits.data.shape) # 输入空间维度
22 print(digits.target.shape) # 输出空间维度
23
24 ### data split
25 x_train,x_test,y_train,y_test = train_test_split(digits.data,
26 digits.target,
27 test_size = 0.3,
28 random_state = 33)
29
30 ### fit model for train data
31 model = XGBClassifier()
32 model.fit(x_train,y_train)
33
34 ### make prediction for test data
35 y_pred = model.predict(x_test)
36
37 ### model evaluate
38 accuracy = accuracy_score(y_test,y_pred)
39 print("accuarcy: %.2f%%" % (accuracy*100.0))
40 """
41 95.0%
42 """
【机器学习】集成学习之sklearn中的xgboost基本用法的更多相关文章
- 【集成学习】sklearn中xgboost模块的XGBClassifier函数
# 常规参数 booster gbtree 树模型做为基分类器(默认) gbliner 线性模型做为基分类器 silent silent=0时,不输出中间过程(默认) silent=1时,输出中间过程 ...
- 【集成学习】sklearn中xgboost模块中plot_importance函数(绘图--特征重要性)
直接上代码,简单 # -*- coding: utf-8 -*- """ ################################################ ...
- 【集成学习】sklearn中xgboot模块中fit函数参数详解(fit model for train data)
参数解释,后续补上. # -*- coding: utf-8 -*- """ ############################################## ...
- [机器学习]集成学习--bagging、boosting、stacking
集成学习简介 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务. 如何产生"好而不同"的个体学习器,是集成学习研究的核心. 集成学习的思路是通过 ...
- 大白话5分钟带你走进人工智能-第32节集成学习之最通俗理解XGBoost原理和过程
目录 1.回顾: 1.1 有监督学习中的相关概念 1.2 回归树概念 1.3 树的优点 2.怎么训练模型: 2.1 案例引入 2.2 XGBoost目标函数求解 3.XGBoost中正则项的显式表达 ...
- 机器学习——集成学习(Bagging、Boosting、Stacking)
1 前言 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(errorrate < ...
- 机器学习--集成学习(Ensemble Learning)
一.集成学习法 在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好) ...
- python大战机器学习——集成学习
集成学习是通过构建并结合多个学习器来完成学习任务.其工作流程为: 1)先产生一组“个体学习器”.在分类问题中,个体学习器也称为基类分类器 2)再使用某种策略将它们结合起来. 通常使用一种或者多种已有的 ...
- 机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning) 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测 ...
随机推荐
- hibernate关联非主键注解配置
现在有两张表:一张t_s_user用户表和t_s_user_serial_number用户序号表 CREATE TABLE `t_s_user` ( `id` ) NOT NULL, `email` ...
- tomcat监控,自动重启shell脚本
tomcat监控,自动重启shell脚本如下,取名 monitor_tomcat.sh: #!/bin/sh # func:自动监控tomcat脚本并且执行重启操作 # 获取tomcat进程ID(其中 ...
- list<>泛型的意义
泛型就是指定一个自定类或数据类型例如(int)并命名一个XXX集合名,所有这个类型的数据可以加入这个XXXX集合名,组成一个集合. private list<可放例int数据类型或自定类> ...
- ubuntu16.04 python3.5 opencv的安装与卸载(转载)
转载https://blog.csdn.net/qq_37541097/article/details/79045595 Ubuntu16.04 自带python2.7和python3.5两个版本,默 ...
- MU puzzle
2017-08-06 20:49:38 writer:pprp 三种操作: 1.MUI -> MUIUI 2.MUUU -> MU 3.MUIII -> MUU 分析:有两个操作:将 ...
- 一款简单易用的.Net 断言测试框架 : Shouldly
GitHub地址:https://github.com/shouldly/shouldly Shouldly的官方文档:http://docs.shouldly-lib.net/ Nuget安装: 在 ...
- oracle 顺序号生成函数。仿Sequence
问题提出自项目中的老代码:一个Bill表,存储所有的表单信息,比如:员工入职单,离职单等等.(别喷,我知道要分多个表.但领导的意愿你是没办法违背的)表单的单据号是以四个字母+年月日+数字顺序号来表示. ...
- Codeforces Round #241 (Div. 2) B. Art Union 基础dp
B. Art Union time limit per test 1 second memory limit per test 256 megabytes input standard input o ...
- C5 标准IO库:APUE 笔记
C5 :标准IO库 在第三章中,所有IO函数都是围绕文件描述符展开,文件描述符用于后续IO操作.由于文件描述符相关的操作是不带缓冲的IO,需要操作者本人指定缓冲区分配.IO长度等,对设备环境要求一定的 ...
- 搞懂分布式技术11:分布式session解决方案与一致性hash
搞懂分布式技术11:分布式session解决方案与一致性hash session一致性架构设计实践 原创: 58沈剑 架构师之路 2017-05-18 一.缘起 什么是session? 服务器为每个用 ...