[ACM训练] 算法初级 之 数据结构 之 栈stack+队列queue (基础+进阶+POJ 1338+2442+1442)
再次面对像栈和队列这样的相当基础的数据结构的学习,应该从多个方面,多维度去学习。
首先,这两个数据结构都是比较常用的,在标准库中都有对应的结构能够直接使用,所以第一个阶段应该是先学习直接来使用,下一个阶段再去探究具体的实现,以及对基本结构的改造!
C++标准库中的基本使用方法:
栈: #include<stack>
定义栈,以如下形式实现: stack<Type> s; 其中Type为数据类型(如 int,float,char等)
常用操作有:
s.push(item); //将item压入栈顶
s.pop(); //删除栈顶的元素,但不会返回
s.top(); //返回栈顶的元素,但不会删除,,,,,,,,,在出栈时需要进行两步,即先top()获得栈顶元素,再pop()删除栈顶元素
s.size(); //返回栈中元素的个数
s.empty(); //检查栈是否为空,如果为空返回true,否则返回false
最基本的用法就是:
stack<int> st;---------------------------------->栈
int first=1;
st.push(first);//入栈1
int second=2;
st.push(second);//入栈2
first=st.top();//first变成了2
st.pop();//出栈
队列:#include<queue>
queue<int> q; //定义一个 int 型的队列 ---------------------------------->队列
q.empty()//如果队列为空返回true,否则返回false
q.size() //返回队列中元素的个数
q.push() //在队尾压入新元素
q.front() //返回队首元素的值,但不删除该元素
q.pop() //删除队列首元素但不返回其值
q.back()//返回队列尾元素的值,但不删除该元素
另外在队列中还有优先队列,priority_queue<.........>---------------------------------->优先队列
要包含头文件:
#include<functional>
#include<queue>
优先队列支持的操作有:
q.empty() //如果队列为空,则返回true,否则返回false
q.size() //返回队列中元素的个数
q.pop() //删除队首元素,但不返回其值
q.top() //返回具有最高优先级的元素值,但不删除该元素,注意与传统队列的不同以及和栈的相同点
q.push(item) //在基于优先级的适当位置插入新元素
优先队列是我们比较不熟悉的一种结构,下面整体上做一个总结学习:
优先队列是队列的一种,不过它可以按照自定义的一种方式(数据的优先级)来对队列中的数据进行动态的排序,每次的push和pop操作,队列都会动态的调整,以达到我们预期的方式来存储。
例如:我们常用的操作就是对数据排序,优先队列默认的是数据大的优先级高,所以我们无论按照什么顺序push一堆数,最终在队列里总是top出最大的元素。
所以,优先队列在一些定义了权重的地方很有用,priority_queue特别之处在于,允许用户为队列中存储的元素设置优先级。这种队列不是直接将新元素放置在队列尾部,而是放在比它优先级低的元素前面。标准库默认使用<操作符来确定对象之间的优先级关系,所以如果要使用自定义对象,需要重载 < 操作符。
使用上有这么几种类型:
priority_queue<int>que;//采用默认优先级构造队列 priority_queue<int,vector<int>,cmp1>que1;//最小值优先 ,,,,,这里定义底层实现以vector实现
priority_queue<int,vector<int>,cmp2>que2;//最大值优先 priority_queue<int,vector<int>,greater<int> >que3;//最小值优先,另外需注意“>>”会被认为错误,
priority_queue<int,vector<int>,less<int> >que4;//最大值优先 priority_queue<number1>que5; //最小优先级队列 --->针对自定义的数据结构
priority_queue<number2>que6; //最大优先级队列
1、默认优先级队列,默认的优先级是按照数据的大小来决定的。默认为最大值优先的。
2、设置的最小值或者最大值优先队列,使用一个比较结构来标识来表明比较的方式,这里的cmp为:
struct cmp1
{
bool operator ()(int &a,int &b)
{
return a>b;//最小值优先
}
}; struct cmp2
{
bool operator ()(int &a,int &b)
{
return a<b;//最大值优先
}
};
3、采用头文件"functional"内定义的优先级,即greater<int>/less<int>,来标识,除此之外可以不用包含此头文件。
4、或者使用自定义的结构,但结构内需重载操作符<,比如这里的number1和number2:
//自定义数据结构
struct number1
{
int x;
bool operator < (const number1 &a) const
{
return x>a.x;//最小值优先
}
};
struct number2
{
int x;
bool operator < (const number2 &a) const
{
return x<a.x;//最大值优先
}
};
总结,能直接进行数据大小比较的,就是默认为最大值优先a<b,如果要更改,就是用一个cmp,更改为a>b就变成了最小值优先了,而对于无法直接进行比较的数据结构,就自定义一个<运算符重载,制定一个元素进行比较,默认的按照最大值优先,即x<a.x,若要更改就改成x>a.x即可变成最小值优先。
基本用法就是这个样子,需要从题目中进行锻炼,对于栈和队列基本都比较简单,但是对于优先队列就需要重点去掌握了!!!
针对于优先级队列,有人总结出几点常用的功能:(其实大致就是上面的四种类型的用法)
1、优先队列最基本的功能就是出队时不是按照先进先出的规则,而是按照队列中优先级顺序出队。
知识点:1、一般存放实型类型,可比较大小
2、默认情况下底层以Vector实现
3、默认情况下是大顶堆,也就是大者优先级高,可以自定义优先级比较规则
priority_queue<int> Q;
Q.push();
Q.push();
Q.push();
while(!Q.empty())
{
cout<<Q.top()<<endl;
Q.pop();
}//这样就是一个按照顺序排序的输出
2、可以将一个存放实型类型的数据结构转化为优先队列,这里跟优先队列的构造函数相关,
使用的是 priority_queue(InputIterator first,InputIterator last)
给出了一个容器的开口和结尾,然后把这个容器内容拷贝到底层实现(默认vector)中去构造出优先队列。
int a[]={,,,,};
priority_queue<int> Q(a,a+5);
while(!Q.empty())
{
cout<<Q.top()<<endl;
Q.pop();
}
3、可以定义了一个(Node),底层实现以vector实现(第二个参数),优先级为小顶堆(第三个参数)。
前两个参数没什么说的,很好理解,其中第三个参数,默认有三写法:
小顶堆:greater<TYPE>
大顶堆:less<TYPE> --------->需要使用头文件:#include<functional>
如果想自定义优先级而TYPE不是基本类型,而是复杂类型,例如结构体、类对象,则必须重载其中的operator(),即cmp
经典例题:Ugly Numbers http://poj.org/problem?id=1338
Input
Output
Sample Input
1
2
9
0
Sample Output
1
2
10
此题只使用优先级队列不太能解决问题,解决问题需要两个条件从小到大的排序+无重复,只使用优先级队列可以解决排序,而无重复只能使用自定义逻辑来判断,个人认为使用set能更优雅的解决问题。
下面给出代码,使用set解决问题:
#include <iostream>
#include <cstdio>
#include <set>
#include <cmath> using namespace std; unsigned long result[]; void getUgly()
{
set<unsigned long> s;
s.insert();
s.insert();
s.insert(); int i=;
result[i]=;
unsigned long tmp=;
while(i<)
{
i++;
tmp=*(s.begin());
result[i]=tmp;
s.erase(tmp);
s.insert(tmp*);
s.insert(tmp*);
s.insert(tmp*);
}
} int main()
{
int n; getUgly();
while(cin>>n)
{
if(n==)
break; cout<<result[n-]<<endl;
}
return ;
}
然后再思考一下此题目使用优先级队列完成了排序,再使用什么样的外部逻辑才能解决无重复的问题呢?????
在队列中看来是没有办法解决掉重复问题了,但是考虑到从中取数据进行保存时肯定是取小的优先,那么当有两个重复的取出来肯定是连续的,所以在保存数据是向前查看result中是否重复即可。
参考代码:
#include <iostream>
#include <cstdio>
#include <queue>
#include <cmath> using namespace std; unsigned long result[]; void getUgly()
{
priority_queue<unsigned long,vector<unsigned long>,greater<unsigned long> > q; q.push(); int i=;
unsigned long tmp;
while(i<)
{
tmp=q.top();
q.pop(); if(i> && tmp==result[i-])//重复
continue;
result[i++]=tmp; q.push(tmp*);
q.push(tmp*);
q.push(tmp*); }
} int main()
{
int n; getUgly();
while(cin>>n)
{
if(n==)
break; cout<<result[n-]<<endl;
} return ;
}
这里注意这个优先级队列的定义:默认数值大优先
两组三种定义格式:
最小值优先 1、priority_queue<T,vector<T>,greater<T> > q 2、priority_queue<T,vector<T>,cmp1> q 3、priority_queue<TYPE> q
最大值优先 1、priority_queue<T,vector<T>,less<T> > q 2、priority_queue<T,vector<T>,cmp2> q 3、priority_queue<TYPE> q
cmp中需要重载bool operator ()(int &a,int &b){return a>b;//最小值为>,最大值;为<}
TYPE中需要重载bool operator < (const number1 &a) const { return x>a.x;//最小值优先>,最大值优先为<}
只需要记住大致的格式,如果记不住具体的大于或者小于号,调试一下即可!!!
New one: Sequence:http://poj.org/problem?id=2442
Input
Output
Sample Input
1
2 3
1 2 3
2 2 3
Sample Output
3 3 4
几点注意点:
1、看到 non-negative的定义,那么在code中的变量最好定义为 unsigned int/long
2、mxn的矩阵的每行一个的全组合,需要使用栈来实现m个n叉深林的深度优先遍历,或者是用递归来实现遍历,需要重点实现!
全组合实现:
1、使用栈,可以类似二叉树的遍历,但是无法求和。
unsigned int matrix[][];
int m;//实际行数
int n;//实际列数 struct node
{
unsigned int num;
int level;
}; void get_all()
{
stack<node> st; int i=,j=;
node op;
for(;i<n;i++)
{
op.num=matrix[][i];
op.level=;
st.push(op); while(!st.empty())
{
op=st.top();
st.pop();
cout<<op.num<<endl;
if(op.level+<m)
{
op.level+=;
for(j=n-;j>=;j--)
{
op.num=matrix[op.level][j];
st.push(op);
}
}
}
}
}
2、另外还可以使用递归,是用递归是利用了系统堆栈,此方法可以设计一个求和,递归返回。
递归部分设计遗忘严重,先留空!!!
整体参考代码:
Next one: Black Box:http://poj.org/problem?id=1442
Input
Output
Sample Input
7 4
3 1 -4 2 8 -1000 2
1 2 6 6
Sample Output
3
3
1
2
数据最大量超过11位的一定考虑long long 或者unsigned long long,int和long能表示的最大值为-2147483648 ~ +2147483647
留空。。。
这里记录一个经典的关于栈和队列的面试题目:
题目:实现一个栈,带有出栈(pop),入栈(push),取最小元素(getMin)三个方法。要保证这三个方法的时间复杂度都是O(1)。
思路:重点是getMin()函数的设计,普通思路是设计一个额外的整形变量用来保存最小值的索引值,每次入栈的时候都讲最小值与入栈值比较,若更小则更新。
误区:此思路的一个非常关键的思考误区在于,没有考虑出栈情况下,如果恰好是该最小值出栈,那么之后就无法获取最小值了!
进一步思考:就是需要将整个过程中的最小值都保存下来,设置一个额外的栈来保存依次获取的最小值,这样即使当前的最小值出栈了,那么次小的值会变成最小值,仍然在辅助栈的栈顶。
误区:再思考一下此设计的过程,如果依次入栈递增的一个序列,比如3,4,5,6,7,那么在辅助栈中却只能记录下3作为最小值保存,那么直接使用getMin后3就出栈了,那么辅助栈中却没有了最小值的信息了!
再进一步:需要解决此漏洞,可以采用:
使用辅助栈,首先要明确栈是先入后出的结构,对于3,4,5这个栈结构,无法直接出栈3或者4,必须先出栈5才可以!!!
所以辅助栈要随数据栈同时出栈或进栈就不用直接排序保存所有数据了,可以按照以下思路:(参考自这里)
辅助栈和数据栈同时出栈和入栈,第一次入栈时均入栈第一个元素,再次入栈,先直接入栈数据栈,针对辅助栈先将要入栈数据与辅助栈栈顶元素进行比较,如果<栈顶元素,则同时入栈辅助栈,否则将栈顶元素复制一份再次入栈辅助栈即可。出栈时二者同时出栈即可。而getMin()只是用来获取当前的数据栈中的最小值即可,并不需要将其出栈。如图:
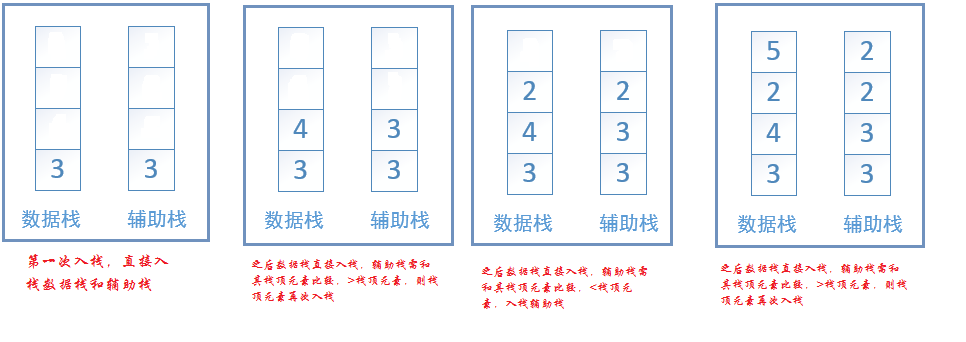
C++实现:
#include <iostream>
#include <cstdio>
#include <stack>
using namespace std; template <typename T>//使用模板类T
class StackWithMin
{
public:
stack<T> dataStack;
stack<T> minStack; void push(T t)//入栈,数据栈直接入栈,辅助栈需要比较大小后入栈
{
dataStack.push(t);
if(minStack.size()== || t<minStack.top())
minStack.push(t);
else
minStack.push(minStack.top());
} T top()
{
return dataStack.top();
} void pop()//出栈时数据栈和辅助栈同时操作即可,仍然设计遵循标准用法
{
dataStack.pop();
minStack.pop();
} T getMin()
{
return minStack.top();
}
}; int main()
{
StackWithMin<int> mstack; int eles[] = {,,,};
for (int i=;i<;i++)
mstack.push(eles[i]); cout<<mstack.getMin()<<endl;//
mstack.pop();//
mstack.pop();//
cout<<mstack.getMin()<<endl;//
mstack.push();
cout<<mstack.getMin()<<endl;// return ;
}
拓展:带取最小值的队列
实现一个队列,带有出队(deQueue),入队(enQueue),取最小元素(getMin)三个方法。要保证这三个方法的时间复杂度都尽可能小。
与上面相似,实现为:
没有想好实现方式,先暂时留空。
下面是牛客网关于队列和栈的学习相关总结
[ACM训练] 算法初级 之 数据结构 之 栈stack+队列queue (基础+进阶+POJ 1338+2442+1442)的更多相关文章
- [ACM训练] 算法初级 之 搜索算法 之 广度优先算法BFS (POJ 3278+1426+3126+3087+3414)
BFS算法与树的层次遍历很像,具有明显的层次性,一般都是使用队列来实现的!!! 常用步骤: 1.设置访问标记int visited[N],要覆盖所有的可能访问数据个数,这里设置成int而不是bool, ...
- [ACM训练] 算法初级 之 搜索算法 之 深度优先算法DFS (POJ 2251+2488+3083+3009+1321)
对于深度优先算法,第一个直观的想法是只要是要求输出最短情况的详细步骤的题目基本上都要使用深度优先来解决.比较常见的题目类型比如寻路等,可以结合相关的经典算法进行分析. 常用步骤: 第一道题目:Dung ...
- [ACM训练] 算法初级 之 基本算法 之 枚举(POJ 1753+2965)
先列出题目: 1.POJ 1753 POJ 1753 Flip Game:http://poj.org/problem?id=1753 Sample Input bwwb bbwb bwwb bww ...
- python 下的数据结构与算法---4:线形数据结构,栈,队列,双端队列,列表
目录: 前言 1:栈 1.1:栈的实现 1.2:栈的应用: 1.2.1:检验数学表达式的括号匹配 1.2.2:将十进制数转化为任意进制 1.2.3:后置表达式的生成及其计算 2:队列 2.1:队列的实 ...
- 学习javascript数据结构(一)——栈和队列
前言 只要你不计较得失,人生还有什么不能想法子克服的. 原文地址:学习javascript数据结构(一)--栈和队列 博主博客地址:Damonare的个人博客 几乎所有的编程语言都原生支持数组类型,因 ...
- python数据结构之栈与队列
python数据结构之栈与队列 用list实现堆栈stack 堆栈:后进先出 如何进?用append 如何出?用pop() >>> >>> stack = [3, ...
- 用JS描述的数据结构及算法表示——栈和队列(基础版)
前言:找了上课时数据结构的教程来看,但是用的语言是c++,所以具体实现在网上搜大神的博客来看,我看到的大神们的博客都写得特别好,不止讲了最基本的思想和算法实现,更多的是侧重于实例运用,一边看一边在心里 ...
- 算法与数据结构(二) 栈与队列的线性和链式表示(Swift版)
数据结构中的栈与队列还是经常使用的,栈与队列其实就是线性表的一种应用.因为线性队列分为顺序存储和链式存储,所以栈可以分为链栈和顺序栈,队列也可分为顺序队列和链队列.本篇博客其实就是<数据结构之线 ...
- Swift 算法实战之路:栈和队列
这期的内容有点剑走偏锋,我们来讨论一下栈和队列.Swift语言中没有内设的栈和队列,很多扩展库中使用Generic Type来实现栈或是队列.笔者觉得最实用的实现方法是使用数组,本期主要内容有: 栈和 ...
随机推荐
- Bootstrap 中的 Typeahead 组件 -- AutoComplete
Bootstrap 中的 Typeahead 组件就是通常所说的自动完成 AutoComplete,功能很强大,但是,使用上并不太方便.这里我们将介绍一下这个组件的使用. 第一,简单使用 首先,最简单 ...
- DIR 按文件名中数字大小进行排序
@echo off set arg=%1 if "%arg%" == "" set arg=* if "%arg%" == "-h ...
- JS Date.parse() 函数详解
Date.parse()函数用于分析一个包含日期的字符串,并返回该日期与 1970 年 1 月 1 日午夜之间相差的毫秒数. 该函数属于Date对象,所有主流浏览器均支持该函数. 语法 Date.pa ...
- SQL(横表和纵表)行列转换,PIVOT与UNPIVOT的区别和使用方法举例,合并列的例子
使用过SQL Server 2000的人都知道,要想实现行列转换,必须综合利用聚合函数和动态SQL,具体实现起来需要一定的技巧,而在SQL Server 2005中,使用新引进的关键字PIVOT/UN ...
- sha1散列(C语言)
/** * \file sha1.h * * \brief SHA-1 cryptographic hash function * * Copyright (C) 2006-2010, Brainsp ...
- 接触PHP快4个月
就要下班了,接触php快4个月,掌握的不好,需要实战,看到自己博客空空的,就mark一下吧!下班了...
- 浅谈display:flex
display:flex 意思是弹性布局 首先flex的出现是为了解决哪些问题呢? 一.页面行排列布局 像此图左右两个div一排显示 可以用浮动的布局方式 html部分 css部分 这种布局有两个缺点 ...
- win10下安装mysql5.7.16(解压缩版)
注:本文涉及的是解压缩版的安装 安装教程 下载mysql 地址是:http://dev.mysql.com/downloads/mysql/ 解压缩下载的文件 修改ini文件(在解压缩后的mysql文 ...
- 模拟搭建Web项目的真实运行环境(四)
本篇介绍如何部署mongodb环境,主要分为三个部分: 第一部分 介绍如何在ubuntu下安装mongodb, 第二部分 介绍如何在windows下安装使用MongoChef客户端, 第三部分 介绍在 ...
- C#操作XML之读取数据
List<Ztree> ZTreeList = new List<Ztree>(); XDocument MenuConfigDoc = XDocument.Load(&quo ...