SQL夯实基础(八):联接运算符算法归类
今天主要介绍三个常用联接运算符算法:合并联接(Merge join),哈希联接(Hash Join)和嵌套循环联接(Nested Loop Join)。(mysql至8.0版本,都只支持Nested Loop Join,下一篇文章我会单独说下mysql对Nested Loop Join的使用)
一个关系可以是:
1 一个表
2 一个索引
3 上一个运算的中间结果(比如上一个联接运算的结果)
当你联接两个关系时,联接算法对两个关系的处理是不同的。在本文剩余部分,我将假定:
外关系是左侧数据集(驱动表),内关系是右侧数据集(非驱动表、被驱动表)。
比如, A JOIN B 是 A 和 B 的联接,这里 A 是外关系,B 是内关系。多数情况下,A JOIN B 的成本跟 B JOIN A 的成本是不同的。
在这一部分,我还将假定外关系有 N 个元素,内关系有 M 个元素。要记住,真实的优化器通过统计知道 N 和 M 的值。
注:N 和 M 是关系的基数。【基数】
驱动表与被驱动表
这里我们叫他外关系和内关系(因为很多文章对这两个概念有不同的命名,很容易混乱):
驱动表,即需要从驱动表中拿出来每条记录,去与被驱动表的所有记录进行匹配探测。
理解驱动表和被驱动表的差异,最本质的问题,需要理解顺序读取和随机读取的差异,内存是适合随机读取的,但是硬盘就不是(固态随机读稍微好些,但是对比顺序读有差距),对于硬盘来说顺序读取的效率比较好。
1、驱动表,作为外层循环,若能只进行一次IO把所有数据拿出来最好,这就比较适合顺序读取,一次性批量的把数据读取出来,这里没考虑缓存等细节。
2、被驱动表,即里层循环,由于需要不断的拿外层循环传进来的每条记录去匹配,所以如果是适合随机读取的,那么效率就会比较高。如果表上有索引,实际上就意味着这个表是适合随机读取的。如果表的数据量较大,且没有索引,那么就不适合多次的随机读取,比较适合一次性的批量读取,就应该作为驱动表。
嵌套循环联接
嵌套循环联接是最简单的。
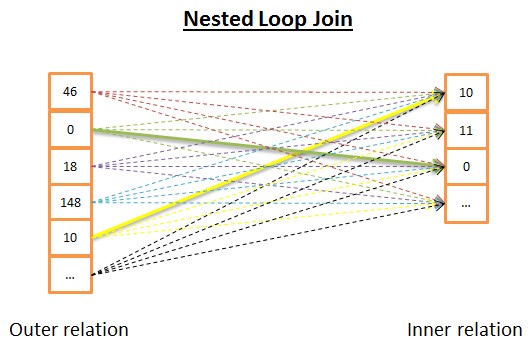
道理如下:
1 针对外关系的每一行
2 查看内关系里的所有行来寻找匹配的行
下面是伪代码:
- nested_loop_join(array outer, array inner)
- for each row a in outer
- for each row b in inner
- if (match_join_condition(a,b))
- write_result_in_output(a,b)
- end if
- end for
- end for
由于这是个双迭代,时间复杂度是 O(N*M)。
在磁盘 I/O 方面, 针对 N 行外关系的每一行,内部循环需要从内关系读取 M 行。这个算法需要从磁盘读取 N+ N*M 行。但是,如果内关系足够小,你可以把它读入内存,那么就只剩下 M + N 次读取。这样修改之后,内关系必须是最小的,因为它有更大机会装入内存。
在CPU成本方面没有什么区别,但是在磁盘 I/O 方面,最好的是每个关系只读取一次。
当然,内关系可以由索引代替,对磁盘 I/O 更有利。
由于这个算法非常简单,下面这个版本在内关系太大无法装入内存时,对磁盘 I/O 更加有利。道理如下:
1 为了避免逐行读取两个关系,
2 你可以成簇读取,把(两个关系里读到的)两簇数据行保存在内存里,
3 比较两簇数据,保留匹配的,
4 然后从磁盘加载新的数据簇来继续比较
5 直到加载了所有数据。
可能的算法如下:
- // improved version to reduce the disk I/O.
- nested_loop_join_v2(file outer, file inner)
- for each bunch ba in outer
- // ba is now in memory
- for each bunch bb in inner
- // bb is now in memory
- for each row a in ba
- for each row b in bb
- if (match_join_condition(a,b))
- write_result_in_output(a,b)
- end if
- end for
- end for
- end for
- end for
使用这个版本,时间复杂度没有变化,但是磁盘访问降低了:
1 用前一个版本,算法需要 N + N*M 次访问(每次访问读取一行)。
2 用新版本,磁盘访问变为外关系的数据簇数量 + 外关系的数据簇数量 * 内关系的数据簇数量。
3 增加数据簇的尺寸,可以降低磁盘访问。
哈希联接
哈希联接更复杂,不过在很多场合比嵌套循环联接成本低。
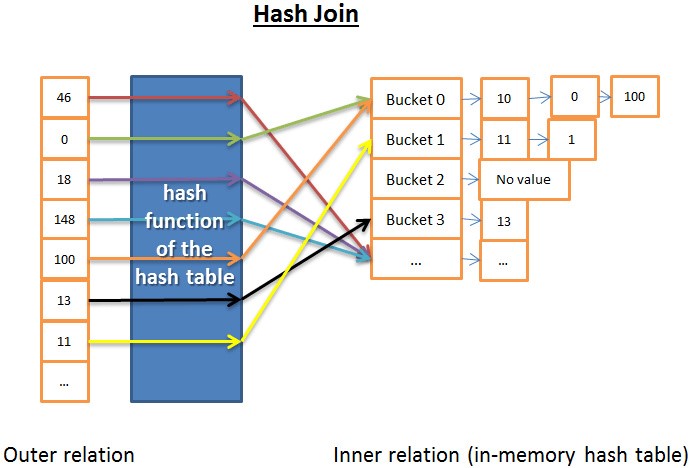
哈希联接的道理是:
1) 读取内关系的所有元素
2) 在内存里建一个哈希表
3) 逐条读取外关系的所有元素
4) (用哈希表的哈希函数)计算每个元素的哈希值,来查找内关系里相关的哈希桶内
5) 是否与外关系的元素匹配。
在时间复杂度方面我需要做些假设来简化问题:
1 内关系被划分成 X 个哈希桶
2 哈希函数几乎均匀地分布每个关系内数据的哈希值,就是说哈希桶大小一致。
3 外关系的元素与哈希桶内的所有元素的匹配,成本是哈希桶内元素的数量。
时间复杂度是 (M/X) * N + 创建哈希表的成本(M) + 哈希函数的成本 * N。如果哈希函数创建了足够小规模的哈希桶,那么复杂度就是 O(M+N)。
还有个哈希联接的版本,对内存有利但是对磁盘 I/O 不够有利。 这回是这样的:
1) 计算内关系和外关系双方的哈希表
2) 保存哈希表到磁盘
3) 然后逐个哈希桶比较(其中一个读入内存,另一个逐行读取)。
合并联接
合并联接是唯一产生排序的联接算法。
注:这个简化的合并联接不区分内表或外表;两个表扮演同样的角色。但是真实的实现方式是不同的,比如当处理重复值时。
1.(可选)排序联接运算:两个输入源都按照联接关键字排序。
2.合并联接运算:排序后的输入源合并到一起。
我们已经谈到过合并排序,在这里合并排序是个很好的算法(但是并非最好的,如果内存足够用的话,还是哈希联接更好)。
然而有时数据集已经排序了,比如:
1 如果表内部就是有序的,比如联接条件里一个索引组织表
2 如果关系是联接条件里的一个索引
3 如果联接应用在一个查询中已经排序的中间结果
这部分与我们研究过的合并排序中的合并运算非常相似。不过这一次呢,我们不是从两个关系里挑选所有元素,而是只挑选相同的元素。道理如下:
1) 在两个关系中,比较当前元素(当前=头一次出现的第一个)
2) 如果相同,就把两个元素都放入结果,再比较两个关系里的下一个元素
3) 如果不同,就去带有最小元素的关系里找下一个元素(因为下一个元素可能会匹配)
4) 重复 1、2、3步骤直到其中一个关系的最后一个元素。
因为两个关系都是已排序的,你不需要『回头去找』,所以这个方法是有效的。
该算法是个简化版,因为它没有处理两个序列中相同数据出现多次的情况(即多重匹配)。真实版本『仅仅』针对本例就更加复杂,所以我才选择简化版。
1 如果两个关系都已经排序,时间复杂度是 O(N+M)
2 如果两个关系需要排序,时间复杂度是对两个关系排序的成本:O(N*Log(N) + M*Log(M))
哪个算法最好?
如果有最好的,就没必要弄那么多种类型了。这个问题很难,因为很多因素都要考虑,比如:
1 空闲内存:没有足够的内存的话就跟强大的哈希联接拜拜吧(至少是完全内存中哈希联接)。
2 两个数据集的大小。比如,如果一个大表联接一个很小的表,那么嵌套循环联接就比哈希联接快,因为后者有创建哈希的高昂成本;如果两个表都非常大,那么嵌套循环联接CPU成本就很高昂。
3 是否有索引:有两个 B+树索引的话,聪明的选择似乎是合并联接。
4 结果是否需要排序:即使你用到的是未排序的数据集,你也可能想用成本较高的合并联接(带排序的),因为最终得到排序的结果后,你可以把它和另一个合并联接串起来(或者也许因为查询用 ORDER BY/GROUP BY/DISTINCT 等操作符隐式或显式地要求一个排序结果)。
5 关系是否已经排序:这时候合并联接是最好的候选项。
6 联接的类型:是等值联接(比如 tableA.col1 = tableB.col2 )? 还是内联接?外联接?笛卡尔乘积?或者自联接?有些联接在特定环境下是无法工作的。
7 数据的分布:如果联接条件的数据是倾斜的(比如根据姓氏来联接人,但是很多人同姓),用哈希联接将是个灾难,原因是哈希函数将产生分布极不均匀的哈希桶。
8 如果你希望联接操作使用多线程或多进程。
SQL夯实基础(八):联接运算符算法归类的更多相关文章
- SQL夯实基础(九)MySQL联接查询算法
书接上文<SQL夯实基础(八):联接运算符算法归类>. 这里先解释下EXPLAIN 结果中,第一行出现的表就是驱动表(Important!). 对驱动表可以直接排序,对非驱动表(的字段排序 ...
- SQL夯实基础(五):索引的数据结构
数据量达到十万级别以上的时候,索引的设置就显得异常重要,而如何才能更好的建立索引,需要了解索引的结构等基础知识.本文我们就来讨论索引的结构. 二叉搜索树:binary search tree 1.所有 ...
- SQL夯实基础(六):MqSql Explain
关系型数据库中,互联网相关行业使用最多的无疑是mysql,虽然我们C# Developer很多用的都是sql server ,但是学习一些mysql方面的知识也是必要的,他山之石么. 先上一个expl ...
- SQL夯实基础(四):子查询及sql优化案例
首先我们先明确一下sql语句的执行顺序,如下有前至后执行: (1)from (2) on (3) join (4) where (5)group by (6) avg,sum... (7 ...
- SQL夯实基础(三):聚合函数详解
一.GROUP BY Having 聊聚合函数,首先肯定要弄清楚group by 和having 的用法. SELECT id, COUNT(course) as numcourse, AVG(sc ...
- SQL夯实基础(二):连接操作中使用on与where筛选的差异
一.on筛选和where筛选 在连接查询语法中,另人迷惑首当其冲的就要属on筛选和where筛选的区别了,如果在我们编写查询的时候, 筛选条件的放置不管是在on后面还是where后面, 查出来的结果总 ...
- SQL夯实基础(一):inner join、outer join和cross join的区别
一.数据构建 先建表,再说话 create database Test use Test create table A ( AID ,) primary key, name ), age int ) ...
- MySQL联接查询算法(NLJ、BNL、BKA、HashJoin)
一.联接过程介绍 为了后面一些测试案例,我们事先创建了两张表,表数据如下: 1 2 3 4 CREATE TABLE t1 (m1 int, n1 char(1)); CREATE TABLE t ...
- .NET面试题解析(11)-SQL语言基础及数据库基本原理
系列文章目录地址: .NET面试题解析(00)-开篇来谈谈面试 & 系列文章索引 本文内容涉及到基本SQL语法,数据的基本存储原理,数据库一些概念.数据优化等.抱砖引玉,权当一个综合复习! ...
随机推荐
- 缓存技术内部交流_03_Cache Aside
参考资料: http://www.ehcache.org/documentation/3.2/caching-patterns.html http://www.ehcache.org/document ...
- [spring mvc]Hello World入门
1.新建项目 File->New->Other,选择Dynamic web project: 项目建好之后,目录结构如下: 2.WEB-INF/web.xml 中配置 dispatcher ...
- MVVM模式的3种command总结[1]--DelegateCommand
MVVM模式的3种command总结[1]--DelegateCommand 查了不少资料,大概理清楚的就是有3种.当然类名可以自己取了,不过为了便于记忆和区分,还是和看到的文章里面用一样的类名. 1 ...
- 创建一个最简单的SpringBoot应用
已经来实习了一段时间了,从开始接触到SpringBoot框架到现在一直都感觉SpringBoot框架实在是为我们带来了巨大遍历之处,之前一直在用并没有总结一下,现在有空从零开始写点东西,也算是对基础的 ...
- 十四 web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
打码接口文件 # -*- coding: cp936 -*- import sys import os from ctypes import * # 下载接口放目录 http://www.yundam ...
- SOUI中启用拖文件
本文所用SOUI版本为1.0版本,在拖文件上与一般的消息略有不同. 1.添加拖文件消息响应 先与常规添加消息相同. class CMainFrm : public SHostWnd { public: ...
- vue组件间传值
父传子 1.父组件:在子组件容器内绑定数据 <router-view :unusedOrderNum="num1" :usedOrderNum="num2" ...
- 007PHP基础知识——类型转换 外部变量
<?php /**类型转换 */ /*1.自由转换*/ /*2.强制转换:不改变原变量,生成新的变量*/ //转换为字符串: /*$a=100; $b=(string)$a; var_dump( ...
- laravel中Crypt加密方法
使用Crypt::encrypt对数据进行加密,要引入 use Illuminate\Support\Facades\Crypt;; 对使用Crypt::encrypt加密的数据进行解密的方法时:C ...
- C++复习9.面向对象编程
C++ 面向对象编程概述 20131001 一些基本概念:封装.继承.组合.虚函数.抽象基类.动态绑定.多态性等等 1.一个笑话:如果坐在后排聊天的同学能够像中间打牌的同学那样安静的话,那么就不会影响 ...