目标检测-基于Pytorch实现Yolov3(1)- 搭建模型
原文地址:https://www.cnblogs.com/jacklu/p/9853599.html
本人前段时间在T厂做了目标检测的项目,对一些目标检测框架也有了一定理解。其中Yolov3速度非常快,效果也还可以,但在github上还没有完整的基于pytorch的yolov3代码,目前star最多的pytorch yolov3项目只能做预测,没有训练代码,而且我看了它的model写得不是很有层次。自己准备利用接下来的几个周末把这个坑填上。
希望能够帮助开发者了解如何基于Pytorch实现一个强大的目标检测模型,同时可以方便的将模型应用到自己的数据集里。完整的源代码准备在文章结束后考虑发布在github上。
准备的目录:
目标检测-基于Pytorch实现Yolov3(1)- 搭建模型 (model.py,最容易的部分,所以第一篇写这个)
目标检测-基于Pytorch实现Yolov3(2)- 数据预处理及数据加载 (dataloader.py,非常重要的一部分,代码工作量最大,定制化只要在这一部分下功夫)
目标检测-基于Pytorch实现Yolov3(3)- 目标函数 (loss.py,最重要的部分,直接决定了网络的效果,难度也是5部分里最大的)
目标检测-基于Pytorch实现Yolov3(4)- 模型训练 (train.py,前面重要的3部分都做完了,这部分就是写完代码喝茶看曲线的时间)
目标检测-基于Pytorch实现Yolov3(5)- 模型预测 (test.py,检验模型训练好坏,还有一些坑要填)
代码主要参考github上基于keras的yolov3的实现,代码结构非常清晰。
Darknet卷积模块
Yolo系列的作者把yolo网络叫做Darknet,其实其他神经网络库都已经把卷积层写好了,直接堆叠起来即可。
darknet卷积模块是这个模型里最基本的网络单元,包括卷积层、batch norm(BN)层、激活函数,因此类型命名为 DarknetConv2D_BN_Leaky。原keras实现是卷积层加了L2正则化预防过拟合,Pytorch是把这个操作放到了Optimizer中,所以将在第三部分讲解。
用Pytorch需要注意, 如果你训练的时候GPU显存不大,batch size设的很小,这时候你就要考虑训练数据集的分布情况。举个例子,加入你的batch size设成了1,但你数据每张图差别都很大,这会导致你的网络一直在震荡,即使网络能够训练到很低的training loss,
在做预测的时候效果也不好,这主要是BN造成的。因为每批数据的统计量(均值和方差)都不同,而且差别大,这就导致网络训练学不到好的BN层的统计量。如果直接去掉BN层,你会发现网络训练非常慢,所以BN层还是要加的,好在Pytorch里的BN有个接口来控制要不要记住每批训练的统计量,即track_running_stats=True,如果训练的batch size不能设特别大,就把它改成False。
卷积层、BN层说完了,激活函数Yolo里用的是0.1的LeakReLU,本人实验发现和ReLU没什么明显的区别(水论文真是一门艺术,我的水文怎么就不中嘞?)
结构很简答,这部分直接上代码,不画图了。
import torch.nn as nn
import torch
class DarknetConv2D_BN_Leaky(nn.Module):
def __init__(self, numIn, numOut, ksize, stride = 1, padding = 1):
super(DarknetConv2D_BN_Leaky, self).__init__()
self.conv1 = nn.Conv2d(numIn, numOut, ksize, stride, padding)#regularizer': l2(5e-4)
self.bn1 = nn.BatchNorm2d(numOut)
self.leakyReLU = nn.LeakyReLU(0.1) def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.leakyReLU(x)
return x
残差模块
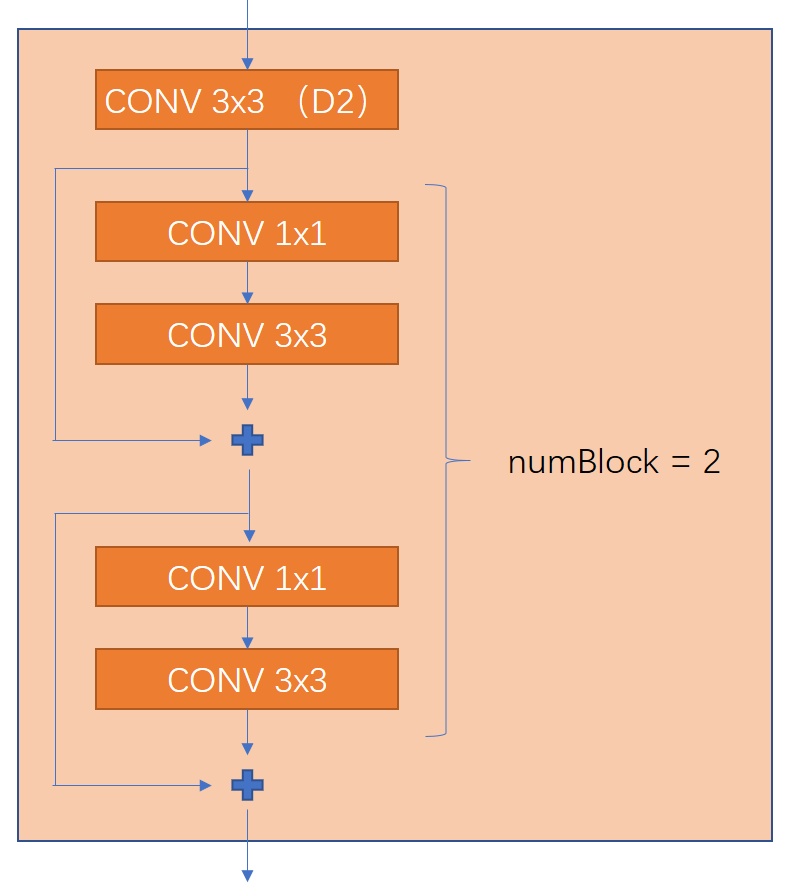
残差模块是借鉴了ResNet,残差模块是为了保证深的模型能够得到很好的训练。残差模块ResidualBlock,对外接口有numIn, numOut, numBlock,分别控制模块的输入通道数,输出通道数(卷积核数)和残差模块的堆叠次数。下图是一个numBlock = 2 的模型,注意这里CONV是指上一部分说的Darknet卷积模块,第一个模块(D2)表示是这个卷积模块stride = 2,及顺便执行了2倍降采样操作。也就是说特征每经过一个残差模块,分辨率降为原来的一半。
class ResidualBlock(nn.Module):
def __init__(self, numIn, numOut, numBlock):
super(ResidualBlock, self).__init__()
self.numBlock = numBlock
self.dark_conv1 = DarknetConv2D_BN_Leaky(numIn, numOut, ksize = 3, stride = 2, padding = 1)
self.dark_conv2 = []
for i in range(self.numBlock):
layers = []
layers.append(DarknetConv2D_BN_Leaky(numOut, numOut//2, ksize = 1, stride = 1, padding = 0))
layers.append(DarknetConv2D_BN_Leaky(numOut//2, numOut, ksize = 3, stride = 1, padding = 1))
self.dark_conv2.append(nn.Sequential(*layers))
self.dark_conv2 = nn.ModuleList(self.dark_conv2)
def forward(self, x):
x = self.dark_conv1(x)
for convblock in self.dark_conv2:
residual = x
x = self.convblock(x)
x = x + residual
return x
后端输出模块
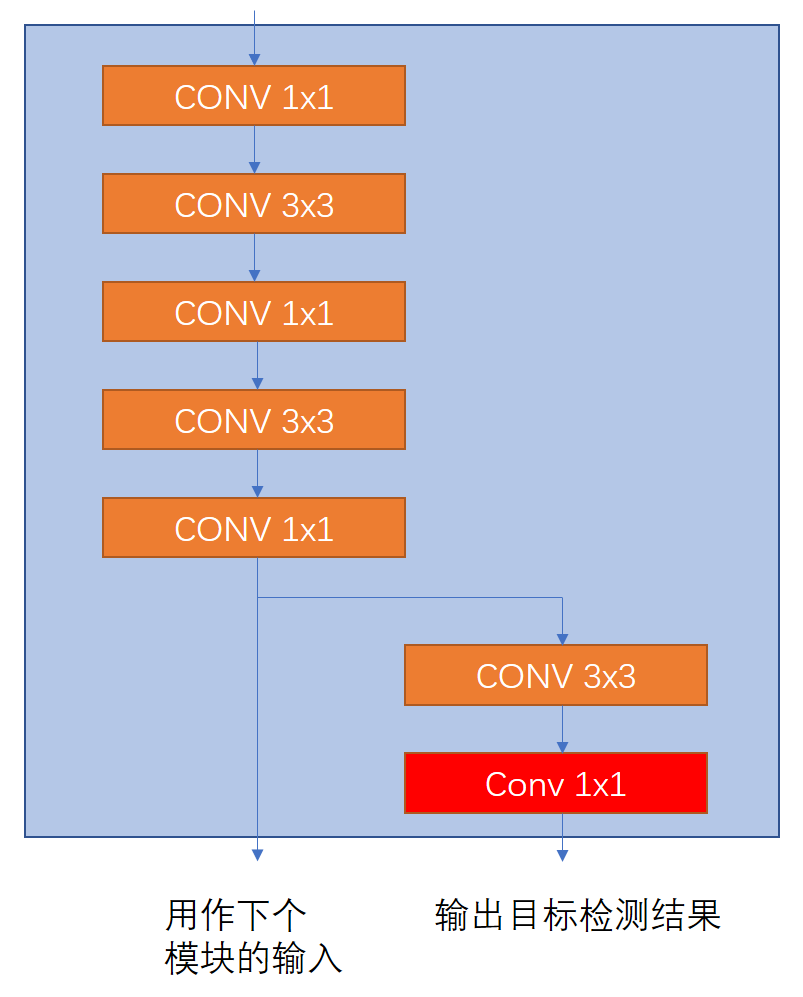
后端输出模块是一个三次降采样(三次升采样在下一部分介绍),这三次降采样+三次升采样,类似Encoder-Decoder的FCN模型。是为了在三种不同尺度上预测。本系列将在voc2007上训练,训练前输入图片要resize到256x256,那么这三种尺度分别是32x32,16x16,8x8。这一部分是因为图片中的目标有大有小,为了保证从不同尺度上找到最好尺度的特征图来进行预测。当然准确提升的同时,由于分辨率有提升,计算量又有一定的增加,索性我们这里的分辨率不大。下图所示为最后输出模块,这个模块有两个输出,一个是用作下一个模块的输入,一个是用于输出目标检测结果,即坐标、类别和目标置信度,这一部分将在下一篇详细介绍。注意红色的Conv不是DarknetConv2D_BN_Leaky,而是指普通的卷积模块。
class LastLayer(nn.Module):
def __init__(self, numIn, numOut, numOut2):
super(LastLayer, self).__init__()
self.dark_conv1 = DarknetConv2D_BN_Leaky(numIn, numOut, ksize = 1, stride = 1, padding = 0)
self.dark_conv2 = DarknetConv2D_BN_Leaky(numOut, numOut*2, ksize = 3, stride = 1, padding = 1)
self.dark_conv3 = DarknetConv2D_BN_Leaky(numOut*2, numOut, ksize = 1, stride = 1, padding = 0)
self.dark_conv4 = DarknetConv2D_BN_Leaky(numOut, numOut*2, ksize = 3, stride = 1, padding = 1)
self.dark_conv5 = DarknetConv2D_BN_Leaky(numOut*2, numOut, ksize = 1, stride = 1, padding = 0) self.dark_conv6 = DarknetConv2D_BN_Leaky(numOut, numOut*2, ksize = 3, stride = 1, padding = 1)
self.conv7 = nn.Conv2d(numOut*2, numOut2, 1, stride = 1, padding = 0) def forward(self, x):
x = self.dark_conv1(x)
x = self.dark_conv2(x)
x = self.dark_conv3(x)
x = self.dark_conv4(x)
x = self.dark_conv5(x) y = self.dark_conv6(x)
y = self.conv7(y)
return x,y
Yolov3模型
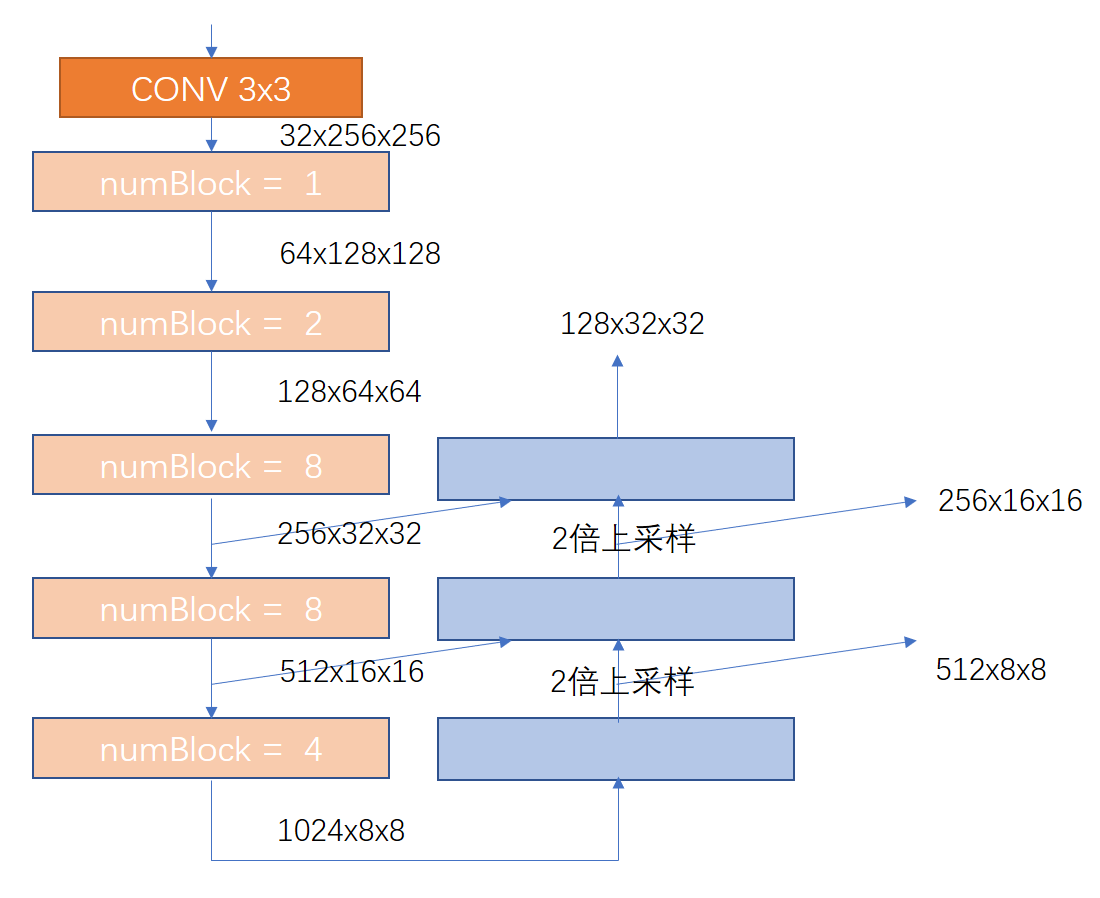
基本的模块已经定义好,Yolov3的模型就是把这些模型叠加起来。注意下图就是Yolov3的简化模型,数字表示该上一个模块的输出特征尺寸(CxHxW),相应的颜色对应相应的模块
class Yolov3(nn.Module):
def __init__(self, numAnchor, numClass):
super(Yolov3, self).__init__()
self.dark_conv1 = DarknetConv2D_BN_Leaky(3, 32, ksize = 3, stride = 1, padding = 1)
self.res1 = ResidualBlock(32, 64, 1)
self.res2 = ResidualBlock(64, 128, 2)
self.res3 = ResidualBlock(128, 256, 8)
self.res4 = ResidualBlock(256, 512, 8)
self.res5 = ResidualBlock(512, 1024, 4) self.last1 = LastLayer(1024, 512, numAnchor*(numClass+5))
self.up1 = nn.Sequential(DarknetConv2D_BN_Leaky(512, 256, ksize = 1, stride = 1, padding = 0),
nn.Upsample(scale_factor=2))
self.last2 = LastLayer(768, 256, numAnchor*(numClass+5))
self.up2 = nn.Sequential(DarknetConv2D_BN_Leaky(256, 128, ksize = 1, stride = 1, padding = 0),
nn.Upsample(scale_factor=2))
self.last3 = LastLayer(384, 128, numAnchor*(numClass+5)) def forward(self, x):
x = self.dark_conv1(x)#32x256x256
x = self.res1(x)#64x128x128
x = self.res2(x)#128x64x64
x3 = self.res3(x)#256x32x32
x4 = self.res4(x3)#512x16x16
x5 = self.res5(x4)#1024x8x8 x,y1 = self.last1(x5)#512x8x8,
x = self.up1(x)#256x16x16
x = torch.cat((x, x4), 1)#768x16x16
x,y2 = self.last2(x)#256x16x16
x = self.up2(x)#128x32x32
x = torch.cat((x, x3), 1)#384x32x32
x,y3 = self.last3(x)#128x32x32 return y1,y2,y3
到这里模型已经完成,模型代码结构非常清晰。有人可能会问,为什么要这种堆叠方式,其实我自己也觉得模型没什么特别的地方,自己根据新的需求定义网络结构完全可以,但是要注意模型深度增加时如何保证收敛,如何加速模型训练,同时输出特征的分辨率要计算好。
参考资料
Yolov3 论文:https://pjreddie.com/media/files/papers/YOLOv3.pdf
Yolov3 Keras实现:https://github.com/qqwweee/keras-yolo3
我的博客即将同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=28tgpk9aapxc4
目标检测-基于Pytorch实现Yolov3(1)- 搭建模型的更多相关文章
- 从零开始实现SSD目标检测(pytorch)(一)
目录 从零开始实现SSD目标检测(pytorch) 第一章 相关概念概述 1.1 检测框表示 1.2 交并比 第二章 基础网络 2.1 基础网络 2.2 附加网络 第三章 先验框设计 3.1 引言 3 ...
- 目标检测(七)YOLOv3: An Incremental Improvement
项目地址 Abstract 该技术报告主要介绍了作者对 YOLOv1 的一系列改进措施(注意:不是对YOLOv2,但是借鉴了YOLOv2中的部分改进措施).虽然改进后的网络较YOLOv1大一些,但是检 ...
- Win10 + YOLOv3 环境配置,编译,实现目标检测----How to compile YOLOv3 on Windows
其他比较好的参考链接: 环境配置: 环境配置的最终图片列表:https://blog.csdn.net/shanglianlm/article/details/80322718 视频讲解YOLOv1: ...
- 目标检测复习之YOLO系列
目标检测之YOLO系列 YOLOV1: blogs1: YOLOv1算法理解 blogs2: <机器爱学习>YOLO v1深入理解 网络结构 激活函数(leaky rectified li ...
- 目标检测论文解读1——Rich feature hierarchies for accurate object detection and semantic segmentation
背景 在2012 Imagenet LSVRC比赛中,Alexnet以15.3%的top-5 错误率轻松拔得头筹(第二名top-5错误率为26.2%).由此,ConvNet的潜力受到广泛认可,一炮而红 ...
- zz目标检测
deep learning分类 目标检测-HyperNet-论文笔记 06-06 基础DL模型-Deformable Convolutional Networks-论文笔记 06-05 基础DL模型- ...
- PyTorch专栏(八):微调基于torchvision 0.3的目标检测模型
专栏目录: 第一章:PyTorch之简介与下载 PyTorch简介 PyTorch环境搭建 第二章:PyTorch之60分钟入门 PyTorch入门 PyTorch自动微分 PyTorch神经网络 P ...
- 基于Intel OpenVINO的搭建及应用,包含分类,目标检测,及分割,超分辨
PART I: 搭建环境OPENVINO+Tensorflow1.12.0 I: l_openvino_toolkit_p_2019.1.094 第一步常规安装参考链接:https://docs.op ...
- GPU端到端目标检测YOLOV3全过程(下)
GPU端到端目标检测YOLOV3全过程(下) Ubuntu18.04系统下最新版GPU环境配置 安装显卡驱动 安装Cuda 10.0 安装cuDNN 1.安装显卡驱动 (1)这里采用的是PPA源的安装 ...
随机推荐
- utuntu 安装python3.5
如果想要升级Utuntu系统中的python版本,请不要卸载原先的版本. 桌面环境中的需要依赖于python相关,卸载之后会出现意想不到问题. (1)sudo add-apt-repository p ...
- H Hip To Be Square Day5——NWERC2012
这个题目巨坑啊.调试的时间加起来绝对超过1天整. 不过终于调试出来了,真心感动地尿流满面啊. 题目的意思是给你一个区间[A,B],可以从区间里选出任意多个整数,使得这些整数的积是一个不超过 2^126 ...
- 后缀树的线性在线构建-Ukkonen算法
Ukkonen算法是一个非常直观的算法,其思想精妙之处在于不断加字符的过程中,用字符串上的一段区间来表示一条边,并且自动扩展,在需要的时候把边分裂.使用这个算法的好处在于它非常好写,代码很短,并且它是 ...
- CGLib动态代理引起的空指针异常
一个同事将公司的开发框架基于最新的Spring.Tomcat.Java版本作了部分修改,拿来开发运行之后,发现一个奇怪的空指针异常. 还原一下当时的场景,代码大概如下,所有的Servlet继承自Bas ...
- 关于在springmvc下使用@RequestBody报http status 415的错误解决办法
网上有很多原因,进行整理后主要有以下几类 springmvc添加配置.注解: pom.xml添加jackson包引用: Ajax请求时没有设置Content-Type为application/json ...
- java中初始化块、静态初始化块和构造方法
(所谓的初始化方法init()是另一回事, 在构造方法之后执行, 注意不要混淆) 在Java中,有两种初始化块:静态初始化块和非静态初始化块.它们都是定义在类中,用大括号{}括起来,静态代码块在大括号 ...
- C++11线程使用总结
std::thread 在 <thread> 头文件中声明,因此使用 std::thread 需包含 <thread> 头文件. <thread> 头文件摘要 &l ...
- Linux(一)——认识Linux
一.Linux介绍 (安装的是Centos6.7) 1.Linux 系统是一套免费使用和自由传播的类 Unix 操作系统(主要用在服务器上),是一个基于 POSIX 和 UNIX 的多用户.多任务.支 ...
- 理解PV操作和信号量
对于信号量,可以认为是一个仓库,有两个概念,容量和当前的货物个数. P操作从仓库拿货,如果仓库中没有货,线程一直等待,直到V操作,往仓库里添加了货物,为了避免P操作一直等待下去,会有一个超时时间. V ...
- 全国排名的问题(linq 的连表查询 等同于sql的left join)
前言:要获得全国排名,(因为权限问题,显示的数据不是全国的数据,而是某个分区的数据,因此,不能获得数据后排序得到排名) 显示本部的员工积分并且获得在全国的排名. 我的思路:获得显示的员工信息集合1,获 ...