Hadoop2.2.0安装配置手册
第一部分 Hadoop 2.2 下载
Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译(10楼评论中提供了一个解决方法链接)。
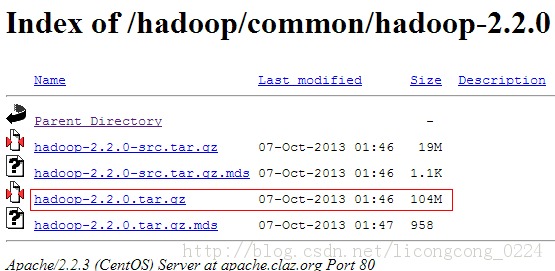
下载地址:http://apache.claz.org/hadoop/common/hadoop-2.2.0/
如下图所示,下载红色标记部分即可。如果要自行编译则下载src.tar.gz.
第二部分 集群环境搭建
1、这里我们搭建一个由三台机器组成的集群:
192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit
192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit
192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit
1.1 上面各列分别为IP、user/passwd、hostname、在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)
vi /etc/hosts
编辑/etc/sysconfig/network文件,更改hostname:
[root@server1 ~]# vi /etc/sysconfig/network
[root@server1 ~]# hostname server2
1.2 Hostname可以在/etc/hostname中修改(ubuntu是在这个路径下,redhat稍有不同)
1.3 这里我们为每台机器新建了一个账户hduser.这里需要给每个账户分配sudo的权限。(切换到root账户,修改/etc/sudoers文件,增加:hduser ALL=(ALL) ALL )
2、修改/etc/hosts 文件,增加三台机器的ip和hostname的映射关系
192.168.0.1 cloud001
192.168.0.2 cloud002
192.168.0.3 cloud003
3、打通cloud001到cloud002、cloud003的SSH无密码登陆
3.1 安装ssh
一般系统是默认安装了ssh命令的。如果没有,或者版本比较老,则可以重新安装:
sodu apt-get install ssh
3.2设置local无密码登陆
安装完成后会在~目录(当前用户主目录,即这里的/home/hduser)下产生一个隐藏文件夹.ssh(ls -a 可以查看隐藏文件)。如果没有这个文件,自己新建即可(mkdir .ssh)。
具体步骤如下:
1、 进入.ssh文件夹
2、 ssh-keygen -t rsa 之后一路回 车(产生秘钥)
3、 把id_rsa.pub 追加到授权的 key 里面去(cat id_rsa.pub >> authorized_keys)
4、 重启 SSH 服 务命令使其生效 :service sshd restart(这里RedHat下为sshdUbuntu下为ssh)
此时已经可以进行ssh localhost的无密码登陆
【注意】:以上操作在每台机器上面都要进行。
3.3设置远程无密码登陆
这里只有cloud001是master,如果有多个namenode,或者rm的话则需要打通所有master都其他剩余节点的免密码登陆。(将001的authorized_keys追加到002和003的authorized_keys)
进入001的.ssh目录
scp authorized_keys hduser@cloud002:~/.ssh/ authorized_keys_from_cloud001
进入002的.ssh目录
cat authorized_keys_from_cloud001>> authorized_keys
至此,可以在001上面sshhduser@cloud002进行无密码登陆了。003的操作相同。
4、安装jdk(建议每台机器的JAVA_HOME路径信息相同)
注意:这里选择下载jdk并自行安装,而不是通过源直接安装(apt-get install)
4.1、下载jkd( http://www.oracle.com/technetwork/java/javase/downloads/index.html)
4.1.1 对于32位的系统可以下载以下两个Linux x86版本(uname -a 查看系统版本)
4.1.2 64位系统下载Linux x64版本(即x64.rpm和x64.tar.gz)

4.2、安装jdk(这里以.tar.gz版本,32位系统为例)
安装方法参考http://docs.oracle.com/javase/7/docs/webnotes/install/linux/linux-jdk.html
4.2.1 选择要安装java的位置,如/usr/目录下,新建文件夹java(mkdirjava)
4.2.2 将文件jdk-7u40-linux-i586.tar.gz移动到/usr/java
4.2.3 解压:tar -zxvf jdk-7u40-linux-i586.tar.gz
4.2.4 删除jdk-7u40-linux-i586.tar.gz(为了节省空间)
至此,jkd安装完毕,下面配置环境变量
4.3、打开/etc/profile(vim /etc/profile)
在最后面添加如下内容:
JAVA_HOME=/usr/java/jdk1.7.0_40(这里的版本号1.7.40要根据具体下载情况修改)
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOMECLASSPATH PATH
4.4、source /etc/profile
4.5、验证是否安装成功:java–version
【注意】每台机器执行相同操作,最后将java安装在相同路径下(不是必须的,但这样会使后面的配置方便很多)
5、关闭每台机器的防火墙
RedHat:
/etc/init.d/iptables stop 关闭防火墙。
chkconfig iptables off 关闭开机启动。
Ubuntu:
ufw disable (重启生效)
第三部分 Hadoop 2.2安装过程
由于hadoop集群中每个机器上面的配置基本相同,所以我们先在namenode上面进行配置部署,然后再复制到其他节点。所以这里的安装过程相当于在每台机器上面都要执行。但需要注意的是集群中64位系统和32位系统的问题。
1、 解压文件
tar zxvf hadoop-2.2.tar.gz
将第一部分中下载的hadoop-2.2.tar.gz解压到/home/hduser路径下(或者将在64位机器上编译的结果存放在此路径下)。然后为了节省空间,可删除此压缩文件,或将其存放于其他地方进行备份。
注意:每台机器的安装路径要相同!!
2、 hadoop配置过程
配置之前,需要在cloud001本地文件系统创建以下文件夹:
~/dfs/name
~/dfs/data
~/temp
这里要涉及到的配置文件有7个:
~/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
~/hadoop-2.2.0/etc/hadoop/yarn-env.sh
~/hadoop-2.2.0/etc/hadoop/slaves
~/hadoop-2.2.0/etc/hadoop/core-site.xml
~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
以上个别文件默认不存在的,可以复制相应的template文件获得。
配置文件1:hadoop-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/java/jdk1.7.0_40)
配置文件2:yarn-env.sh
修改JAVA_HOME值(exportJAVA_HOME=/usr/java/jdk1.7.0_40)
配置文件3:slaves (这个文件里面保存所有slave节点)
写入以下内容:
cloud002
cloud003
配置文件4:core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cloud001:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hduser/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>
配置文件5:hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>cloud001:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hduser/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hduser/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置文件6:mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>cloud001:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cloud001:19888</value>
</property>
</configuration>
配置文件7:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>cloud001:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value> cloud001:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value> cloud001:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value> cloud001:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value> cloud001:8088</value>
</property>
</configuration>
3、复制到其他节点
这里可以写一个shell脚本进行操作(有大量节点时比较方便)
cp2slave.sh
#!/bin/bash
scp–r /home/hduser/hadoop-2.2.0 hduser@cloud002:~/
scp–r /home/hduser/hadoop-2.2.0 hduser@cloud003:~/
注意:由于我们集群里面001是64bit 而002和003是32bit的,所以不能直接复制,而采用单独安装hadoop,复制替换相关配置文件:
Cp2slave2.sh
#!/bin/bash
scp /home/hduser/hadoop-2.2.0/etc/hadoop/slaveshduser@cloud002:~/hadoop-2.2.0/etc/hadoop/slaves
scp /home/hduser/hadoop-2.2.0/etc/hadoop/slaveshduser@cloud003:~/hadoop-2.2.0/etc/hadoop/slaves
scp /home/hduser/hadoop-2.2.0/etc/hadoop/core-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/core-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/core-site.xml hduser@cloud003:~/hadoop-2.2.0/etc/hadoop/core-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/hdfs-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/hdfs-site.xmlhduser@cloud003:~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/mapred-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/mapred-site.xmlhduser@cloud003:~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/yarn-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/yarn-site.xmlhduser@cloud003:~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
4、启动验证
4.1 启动hadoop
进入安装目录: cd ~/hadoop-2.2.0/
格式化namenode:./bin/hdfs namenode –format
启动hdfs: ./sbin/start-dfs.sh
此时在001上面运行的进程有:namenode secondarynamenode
002和003上面运行的进程有:datanode
启动yarn: ./sbin/start-yarn.sh
此时在001上面运行的进程有:namenode secondarynamenoderesourcemanager
002和003上面运行的进程有:datanode nodemanaget
查看集群状态:./bin/hdfs dfsadmin –report
查看文件块组成: ./bin/hdfsfsck / -files -blocks
查看HDFS: http://16.187.94.161:50070
查看RM: http:// 16.187.94.161:8088
4.2 运行示例程序:
先在hdfs上创建一个文件夹
./bin/hdfs dfs –mkdir /input
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarrandomwriter input
PS:dataNode 无法启动是配置过程中最常见的问题,主要原因是多次format namenode 造成namenode 和datanode的clusterID不一致。建议查看datanode上面的log信息。解决办法:修改每一个datanode上面的CID(位于dfs/data/current/VERSION文件夹中)使两者一致。
Hadoop2.2.0安装配置手册的更多相关文章
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程~(心血之作啊~~)
http://blog.csdn.net/licongcong_0224/article/details/12972889 历时一周多,终于搭建好最新版本hadoop2.2集群,期间遇到各种问题,作为 ...
- HADOOP2.2.0安装配置指南
一. 集群环境搭建 这里我们搭建一个由三台机器组成的集群: Ip地址 用户名/密码 主机名 集群中角色 操作系统版本 192.168.0.1 hadoop/hadoop Hadoop-mast ...
- linux上hadoop2.4.0安装配置
1 环境准备 安装java-1.6(jdk) 安装ssh 1.1 安装jdk (1)下载安装jdk 在/usr/lib下创建java文件夹,输入命令: cd /usr/lib mkdir java 输 ...
- hadoop2.4.0 安装配置 (2)
hdfs-site.xml 配置如下: <?xml version="1.0" encoding="UTF-8"?> <?xml-styles ...
- Hadoop2.6.0安装 — 集群
文 / vincentzh 原文连接:http://www.cnblogs.com/vincentzh/p/6034187.html 这里写点 Hadoop2.6.0集群的安装和简单配置,一方面是为自 ...
- Hadoop-2.4.0安装和wordcount执行验证
Hadoop-2.4.0安装和wordcount执行验证 下面描写叙述了64位centos6.5机器下,安装32位hadoop-2.4.0,并通过执行 系统自带的WordCount样例来验证服务正确性 ...
- CentOS 7.0安装配置Vsftp服务器
一.配置防火墙,开启FTP服务器需要的端口 CentOS 7.0默认使用的是firewall作为防火墙,这里改为iptables防火墙. 1.关闭firewall: systemctl stop fi ...
- CentOS 7.0安装配置LAMP服务器(Apache+PHP+MariaDB)
CentOS 7.0默认使用的是firewall作为防火墙,这里改为iptables防火墙. 1.关闭firewall: systemctl stop firewalld.service #停止fir ...
- QC邮件转发工具Mail Direct安装配置手册
QC邮件转发工具Mail Direct安装配置手册 2010-06-11 10:00:56| 分类: 软件测试 | 标签: |举报 |字号大中小 订阅 QC邮件转发工具安装配置手册 由于公司没有独立的 ...
随机推荐
- [MEF] 学习之一 入门级的简单Demo(转)
MEF 的精髓在于插件式开发,方便扩展. 我学东西,习惯性的先搞的最简单的Demo出来,看看有没有好玩的东东,然后继续深入.这个博文,不谈大道理,看demo说事儿. 至于概念,请google ,大把大 ...
- Cockpit 服务化管理工具
Cockpit 是红帽开发的网页版图像化服务管理工具,优点是无需中间层,且可以管理多种服务. 根据其项目主站描述,Cockpit 有如下特点: 从易用性考虑设计,方便管理人员使用,而不是仅仅的终端命令 ...
- 谈谈JS中的高级函数
博客原文地址:Claiyre的个人博客如需转载,请在文章开头注明原文地址 在JavaScript中,函数的功能十分强大.它们是第一类对象,也可以作为另一个对象的方法,还可以作为参数传入另一个函数,不仅 ...
- ubuntu 修改分辨率为自定义分辨率
在ubuntu14.04虚拟机上修改自定义大小的桌面屏幕分辨率,使用的命令:cvt,xrandr 0.首先查看下当前已经提供的分辨率设置:xrandr -q root@xxx:/home/xxx/De ...
- winform 控件随页面大小进行自适应
这个功能网上很多人在问,也有不少人给出过答案,经过实际使用,觉得网上这段代码实现的效果比较好,记录一下 核心代码就是下面这个类 using System; using System.Collectio ...
- springMvc架构简介
什么是spring 关于spring的定义无论是从官方还是市面上已经很多能够清晰明了的做出解释了.我姑且简单定义它为一个轻量级的控制反转(IoC)和面向切面(AOP)的容器,Java 开发框架,至于控 ...
- GOF23设计模式之命令模式(command)
一.命令模式概述 将一个请求封装到一个对象,从而使得可用不同的请求对客户进行参数化. 二.命令模式结构 (1)Command 抽象命令类 (2)ConcreteCommand 具体命令类 (3)Inv ...
- py基础2--列表,元祖,字典,集合,文件
本节内容 列表.元祖操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 三元运算&生成式&成员运算&解压法&队列堆栈&数据类型转换 1. 列表操作 ...
- HDU2546题解
解题思路:先对价格排序(顺序或倒序都可以),然后,对前n-1(从1开始.排序方式为顺序)做容量为m(卡上余额)-5的01背包(背包体积和价值相等).假设dp[i][j]表示从前i个背包中挑选体积不超过 ...
- PHP5.3安装Zend Guard Loader代替Zend Optimizer
Zend Optimizer/3.3.3 解密加代码优化,提高PHP应用程序的执行速度,显著降低服务器的CPU负载. Zend Guard Loader/5.5.0/6.0 解密加代码优化,提 ...