spark-ML基础
一、ML组件
ML的标准API使用管道(pipeline)这样的方式,可以将多个算法或者数据处理过程整合到一个管道或者一个流程里运行,其中包含下面几个部分:
1. dataFrame:用于ML的dataset,保存数据
2. transformer:将一个dataFrame按照某种计算转换成另外一个dataFrame,例如把一个包含特征的dataFrame通过模型预测,生成一个包含特征和预测的dataFrame
3. estimator:根据训练样本进行模型训练(fit),并且得到一个对应的transformer
4. pipeline:将多个transformer和estimator串成一个ML的工作流
5. parameter:transformer和estimator共用一套API来确定参数
transformer
包含特征转换和已学习得到的数据模型,它实现了一个方法transform()
1、一个特征transformer可能将一个dataFrame的某些列映射成新的列,然后输出处理后的新的dataFrame;
2、一个学习得到的模型将读取一个包含特征的dataFrame,对每个样本进行预测,并且把预测结果附加到这个dataFrame,得到一个新的dataFrame
Estimators
主要用于训练模型,实现了一个方法fit(),接受一个包含特征的dataFrame,然后训练得到一个模型,那个模型就是一个transformer
例如:一个LogisticRegression是一个estimator,然后通过调用fit(),得到一个LogisticRegressionModel,这是一个transformer。
每个transformer和estimator都有一个唯一ID,用于保存对应的参数
pipeline
例如一个文本挖掘包含以下三个步骤:
1. 将文本切分成词
2. 将词转换成特征向量
3. 训练得到一个模型,然后用于预测
spark ML将这样一个工作流定义为pipeline,一个pipeline包含多个PipelineStages (transformer和estimator),通过dataFrame在各个stage中进行传递。
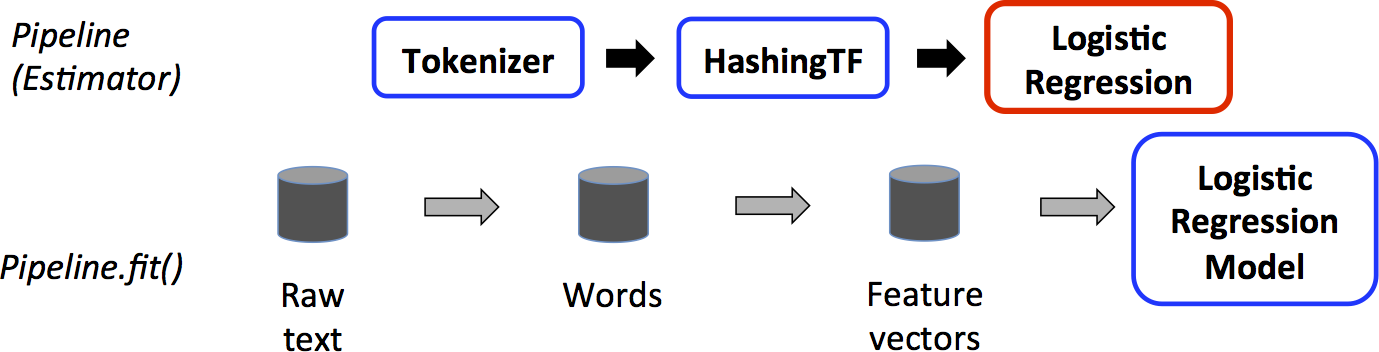
这是一个训练模型的例子,包含了三个步骤,蓝色的是指transformer,红色是estimator
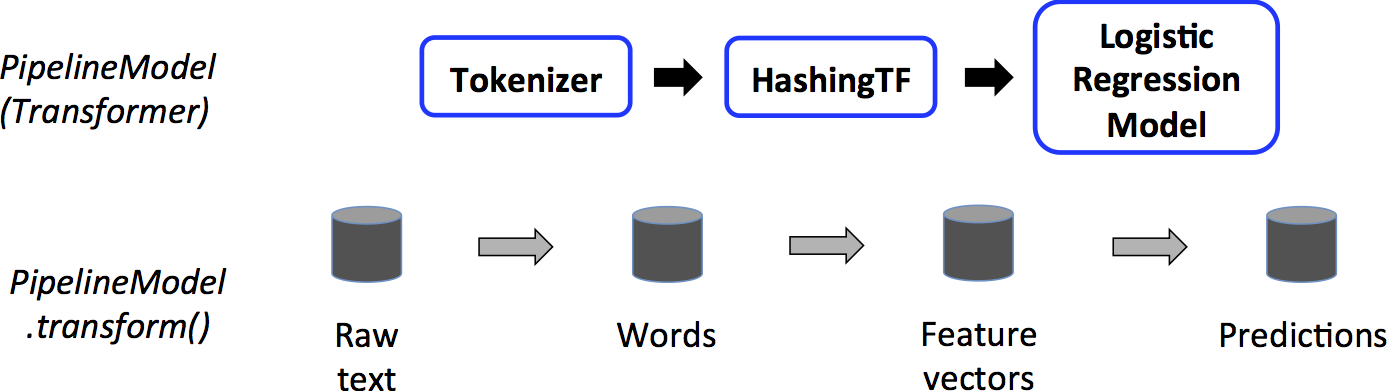
这是一个使用已训练模型预测样本的例子,
Parameters
一个Paramap包含多个(parameter, value)的键值对
有两种方法将参数传给算法:
1. 将参数设置到算法的一个实例,例如lr是LogisticRegression的一个实例,则他可以调用lr.setMaxIter(10)来设置训练循环次数
2. 将paramap作为输入参数,给fit()或者transform(),这些参数会都会覆盖掉原来set的值
我们可以将paramap传给不同实例,例如lr1和lr2是LogisticRegression的两个实例,我们可以建立ParamMap(lr1.maxIter -> 10, lr2.maxIter -> 20)的参数列表,即将两个实例的参数都放在paramMap中
可以使用import/export导出模型或者pipeline到磁盘上
二、基本数据结构
完整内容请参考官方文档 https://spark.apache.org/docs/latest/mllib-data-types.html
(一)核心概念
1、本地向量 LocalVecotr
MLlib的本地向量主要分为两种,DenseVector和SparseVector,顾名思义,前者是用来保存稠密向量,后者是用来保存稀疏向量,其创建方式主要有一下三种(三种方式均创建了向量(1.0, 0.0, 2.0):
注意,ml package中有同样的类。
import org.apache.spark.ml.linalg.{Vector, Vectors}//创建一个稠密向量val dv : Vector = Vectors.dense(1.0,0.0,3.0);//创建一个稀疏向量(第一种方式)val sv1: Vector = Vectors.sparse(3, Array(0,2), Array(1.0,3.0));//创建一个稀疏向量(第二种方式)val sv2 : Vector = Vectors.sparse(3, Seq((0,1.0),(2,3.0)))
- 1
- 2
- 3
对于稠密向量:很直观,你要创建什么,就加入什么,其函数声明为Vectors.dense(values : Array[Double])
对于稀疏向量,当采用第一种方式时,3表示此向量的长度,第一个Array(0,2)表示的索引,第二个Array(1.0, 3.0)与前面的Array(0,2)是相互对应的,表示第0个位置的值为1.0,第2个位置的值为3
对于稀疏向量,当采用第二种方式时,3表示此向量的长度,后面的比较直观,Seq里面每一对都是(索引,值)的形式。
tips:由于scala中会默认包含scal.collection.immutalbe.Vector,所以当使用MLlib中的Vector时,需要显式的指明import路径
2、向量标签 LabelVector
向量标签和向量是一起的,简单来说,可以理解为一个向量对应的一个特殊值,这个值的具体内容可以由用户指定,比如你开发了一个算法A,这个算法对每个向量处理之后会得出一个特殊的标记值p,你就可以把p作为向量标签。同样的,更为直观的话,你可以把向量标签作为行索引,从而用多个本地向量构成一个矩阵(当然,MLlib中已经实现了多种矩阵)
其使用代码为:
import org.apache.spark.ml.linalg.Vectorsimport org.apache.spark.ml.feature.LabeledPointval pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
- 1
- 2
- 3
对于pos变量,第一个参数表示这个数据的分类,1.0的具体含义只有你自己知道咯,可以使行索引,可以使特殊值神马的
从文件中直接读入一个LabeledPoint
MLlib提供了一种快捷的方法,可以让用户直接从文件中读取LabeledPoint格式的数据。规定其输入文件的格式为:
label index1:value1 index2:value2.....
- 1
- 2
然后通过
val spark = SparkSession.builder.appName("NaiveBayesExample").getOrCreate()val data = spark.read.format("libsvm").load("/tmp/ljhn1829/aplus/training_data3")
- 1
- 2
- 3
直接读入即可。
关于libsvm格式的详细说明请见下面内容。
3、本地矩阵
既然是算数运算包,肯定少不了矩阵包,先上代码:
import org.apache.spark.mllib.linalg.{Matrix, Matrices}val dm : Matrix = Matrices.dense(3,2, Array(1.0,3.0,5.0,2.0,4.0,6.0))
- 1
- 2
- 3
上面的代码段创建了一个稠密矩阵:
1.0 2.03.0 4.05.0 6.0
- 1
- 2
- 3
- 4
很明显,创建的时候是将原来的矩阵按照列变成一个一维矩阵之后再初始化的。
稀疏矩阵:
val eye = Matrices.sparse(3, 3, Array(0, 1, 2, 3), Array(0, 1, 2), Array(1, 1, 1))
- 1
- 2
4、分布式矩阵
(ml package未找到类似的类)
MLlib提供了三种分布式矩阵的实现,依据你数据的不同的特点,你可以选择不同类型的数据:
(1)RowMatrix
RowMatrix矩阵只是将矩阵存储起来,要注意的是,此种矩阵不能按照行号访问。(我也不知道为什么这样鸟。。)
import org.apache.spark.mllib.linalg.Vectorimport org.apache.spark.mllib.linalg.distributed.RowMatrixval rows: RDD[Vector] = ...//val mat: RowMatrix = new RowMatrix(rows)val m = mat.numRows()val n = mat.numCols()
- 1
- 2
- 3
RowMatrix要从RDD[Vector]构造,m是mat的行数,n是mat的列
Multivariate summary statistics
顾名思义,这个类里面包含了矩阵中的很多常见信息,怎么使用呢?
import org.apache.spark.mllib.linalg.Matriximport org.apache.spark.mllib.linalg.distributed.RowMatriximport org.apache.spark.mllib.stat.MultivariateStatisticalSummaryval mat: RowMatrix = ..val summy : MultivariateStatisticalSummary = mat.computeColumnSummaryStatistics()println(summy.mean)//平均数
- 1
- 2
- 3
- 4
通过这个类,可以得到平均数,矩阵中非0个数,具体的数据看看帮助文档
(2)IndexedRowMatrix
IndexedRowMatrix矩阵和RowMatrix矩阵的不同之处在于,你可以通过索引值来访问每一行。其他的,没啥区别。。
(3)CoordinateMatrix
当你的数据特别稀疏的时候怎么办?采用这种矩阵吧。先上代码:
import org.apache.spark.mllib.linalg.distributed.{CoordinatedMatrix, MatrixEntry}val entries : RDD[MatrixEntry] = ..val mat: CoordinateMatrix = new CoordinateMatrix(entries)
- 1
- 2
- 3
- 4
- 5
CoordinateMatrix矩阵中的存储形式是(row,col,value),就是原始的最稀疏的方式,所以如果矩阵比较稠密,别用这种数据格式
(二)libsvm数据格式
首先介绍一下 libSVM的数据格式
Label 1:value 2:value …
Label:是类别的标识,比如上节train.model中提到的1 -1,你可以自己随意定,比如-10,0,15。当然,如果是回归,这是目标值,就要实事求是了。
Value:就是要训练的数据,从分类的角度来说就是特征值,数据之间用空格隔开
比如:
-15 1:0.708 2:1056 3:-0.3333
需要注意的是,如果特征值为0,则这列数据可以不写,因此特征冒号前面的(姑且称做序号)可以不连续。如:
-15 1:0.708 3:-0.3333
表明第2个特征值为0,从编程的角度来说,这样做可以减少内存的使用,并提高做矩阵内积时的运算速度。我们平时在matlab中产生的数据都是没有序号的常规矩阵,所以为了方便最好编一个程序进行转化。
spark提供了方便的工具类来加载这些数据
val spark = SparkSession.builder.appName("NaiveBayesExample").getOrCreate()val data = spark.read.format("libsvm").load("/tmp/ljhn1829/aplus/training_data3")
- 1
- 2
- 3
(三)fit()/transform()方法的参数DF包含哪些列
模型抽象为三个基本类,estimators(实现fit方法), transformers(实现transform方法), pipelines,一个正常的模型应该同时实现 fit 和 transform 两个方法
fit 的DataFrame需要包含两列 featuresCol 和 labelCol 默认名字为 label
transform 之前的DataFrame需要有一列名字为features,输出三列(依赖于参数),三列有默认名字,都可以通过setter函数进行设置。
predictedCol 预测的标签,默认名字为 prediction
rawPredictedCol 预测的向量,默认名字为 rawPrediction
probabilityCol 预测的概率,默认名字为 probability
范例1
- import org.apache.log4j.{Level, Logger}
- import org.apache.spark.sql.SparkSession
- object logr {
- def main(args: Array[String]): Unit = {
- import org.apache.spark.ml.classification.LogisticRegression
- import org.apache.spark.ml.param.ParamMap
- import org.apache.spark.ml.linalg.{Vector, Vectors}
- import org.apache.spark.sql.Row
- val ss=SparkSession.builder().master("local").appName("haha").getOrCreate()
- Logger.getRootLogger.setLevel(Level.WARN)
- val training = ss.createDataFrame(Seq(
- (1.0, Vectors.dense(0.0, 1.1, 0.1)),
- (0.0, Vectors.dense(2.0, 1.0, -1.0)),
- (0.0, Vectors.dense(2.0, 1.3, 1.0)),
- (1.0, Vectors.dense(0.0, 1.2, -0.5))
- )).toDF("label", "features")
- //创建一个LogisticRegression实例,这是一个Estimator.
- val lr = new LogisticRegression()
- //打印参数
- println("LogisticRegression parameters:\n" + lr.explainParams() + "\n")
- //调用实例的set方法设置参数
- lr.setMaxIter()
- .setRegParam(0.01)
- // 学习LogisticRegression模型,model1是一个transformer
- val model1 = lr.fit(training)
- println("Model 1 was fit using parameters: " + model1.parent.extractParamMap)
- // 通过paramap来设置参数
- val paramMap = ParamMap(lr.maxIter -> )
- .put(lr.maxIter, )
- .put(lr.regParam -> 0.1, lr.threshold -> 0.55)
- // 两个ParamMap之间可以相加合并.
- val paramMap2 = ParamMap(lr.probabilityCol -> "myProbability") // Change output column name
- val paramMapCombined = paramMap ++ paramMap2
- val model2 = lr.fit(training, paramMapCombined)
- println("Model 2 was fit using parameters: " + model2.parent.extractParamMap)
- //测试数据
- val test = ss.createDataFrame(Seq(
- (1.0, Vectors.dense(-1.0, 1.5, 1.3)),
- (0.0, Vectors.dense(3.0, 2.0, -0.1)),
- (1.0, Vectors.dense(0.0, 2.2, -1.5))
- )).toDF("label", "features")
- //model2的transform()会只选择features的数据,不会把label数据包含进去
- model2.transform(test)
- .select("features", "label", "myProbability", "prediction")
- .collect()
- .foreach { case Row(features: Vector, label: Double, prob: Vector, prediction: Double) =>
- println(s"($features, $label) -> prob=$prob, prediction=$prediction")
- }
- }
- }
验证
ML里面用CrossValidator类来做交叉验证,这个类包含一个estimator、一堆paramMap、和一个evaluator。
evaluator有三个子类,包括regressionEvaluator, BinaryClassificationEvaluator, MulticlassClassificationEvaluator。
- import org.apache.log4j.{Level, Logger}
- import org.apache.spark.sql.SparkSession
- object logr {
- def main(args: Array[String]): Unit = {
- import org.apache.spark.ml.linalg.Vector
- import org.apache.spark.ml.Pipeline
- import org.apache.spark.ml.classification.LogisticRegression
- import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
- import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
- import org.apache.spark.ml.tuning.{ParamGridBuilder, CrossValidator}
- import org.apache.spark.sql.Row
- val ss = SparkSession.builder().master("local").appName("haha").getOrCreate()
- Logger.getRootLogger.setLevel(Level.WARN)
- val training = ss.createDataFrame(Seq(
- (0L, "a b c d e spark", 1.0),
- (1L, "b d", 0.0),
- (2L, "spark f g h", 1.0),
- (3L, "hadoop mapreduce", 0.0),
- (4L, "b spark who", 1.0),
- (5L, "g d a y", 0.0),
- (6L, "spark fly", 1.0),
- (7L, "was mapreduce", 0.0),
- (8L, "e spark program", 1.0),
- (9L, "a e c l", 0.0),
- (10L, "spark compile", 1.0),
- (11L, "hadoop software", 0.0)
- )).toDF("id", "text", "label")
- val tokenizer = new Tokenizer()
- .setInputCol("text")
- .setOutputCol("words")
- val hashingTF = new HashingTF()
- .setInputCol(tokenizer.getOutputCol)
- .setOutputCol("features")
- val lr = new LogisticRegression()
- .setMaxIter()
- val pipeline = new Pipeline()
- .setStages(Array(tokenizer, hashingTF, lr))
- // ParamGridBuilder创建参数grid,保存所有要做验证的参数
- val paramGrid = new ParamGridBuilder()
- .addGrid(hashingTF.numFeatures, Array(, , ))
- .addGrid(lr.regParam, Array(0.1, 0.01))
- .build()
- // 这里将pipeline作为一个estimator传递给cv,这里默认的评估是ROC
- val cv = new CrossValidator()
- .setEstimator(pipeline)
- .setEvaluator(new BinaryClassificationEvaluator)
- .setEstimatorParamMaps(paramGrid)
- .setNumFolds() // Use 3+ in practice
- // 训练模型,选择最优参数
- val cvModel = cv.fit(training)
- val test = ss.createDataFrame(Seq(
- (4L, "spark i j k"),
- (7L, "apache hadoop")
- )).toDF("id", "text")
- // cvModel将会用最优的参数进行预测
- cvModel.transform(test)
- .select("id", "text", "probability", "prediction")
- .collect()
- .foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
- println(s"($id, $text) --> prob=$prob, prediction=$prediction")
- }
- }
- }
- ML中除了cv以外,还有一种指定样本划分的验证方式,TrainValidationSplit 类,默认是0.75,即3/4用于做训练,1/4用于做测试。其他跟cv一样
- import org.apache.log4j.{Level, Logger}
- import org.apache.spark.sql.SparkSession
- import org.apache.spark.ml.evaluation.RegressionEvaluator
- import org.apache.spark.ml.regression.LinearRegression
- import org.apache.spark.ml.tuning.{ParamGridBuilder, TrainValidationSplit}
- object logr {
- def main(args: Array[String]): Unit = {
- val ss = SparkSession.builder().master("local").appName("haha").getOrCreate()
- Logger.getRootLogger.setLevel(Level.WARN)
- val data = ss.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt")
- val Array(training, test) = data.randomSplit(Array(0.9, 0.1), seed = )
- val lr = new LinearRegression()
- val paramGrid = new ParamGridBuilder()
- .addGrid(lr.regParam, Array(0.1, 0.01))
- .addGrid(lr.fitIntercept)
- .addGrid(lr.elasticNetParam, Array(0.0, 0.5, 1.0))
- .build()
- // 创建trainValidationSplit类
- val trainValidationSplit = new TrainValidationSplit()
- .setEstimator(lr)
- .setEvaluator(new RegressionEvaluator)
- .setEstimatorParamMaps(paramGrid)
- // 指定划分百分比
- .setTrainRatio(0.8)
- val model = trainValidationSplit.fit(training)
- model.transform(test)
- .select("features", "label", "prediction")
- .show()
- }
- }
spark-ML基础的更多相关文章
- Spark ML下实现的多分类adaboost+naivebayes算法在文本分类上的应用
1. Naive Bayes算法 朴素贝叶斯算法算是生成模型中一个最经典的分类算法之一了,常用的有Bernoulli和Multinomial两种.在文本分类上经常会用到这两种方法.在词袋模型中,对于一 ...
- Spark ML源码分析之二 从单机到分布式
前一节从宏观角度给大家介绍了Spark ML的设计框架(链接:http://www.cnblogs.com/jicanghai/p/8570805.html),本节我们将介绍,Spar ...
- Spark ML源码分析之四 树
之前我们讲过,在Spark ML中所有的机器学习模型都是以参数作为划分的,树相关的参数定义在treeParams.scala这个文件中,这里构建一个关于树的体系结构.首先,以Decis ...
- Spark ML 几种 归一化(规范化)方法总结
规范化,有关之前都是用 python写的, 偶然要用scala 进行写, 看到这位大神写的, 那个网页也不错,那个连接图做的还蛮不错的,那天也将自己的博客弄一下那个插件. 本文来源 原文地址:htt ...
- Spark ML Pipeline简介
Spark ML Pipeline基于DataFrame构建了一套High-level API,我们可以使用MLPipeline构建机器学习应用,它能够将一个机器学习应用的多个处理过程组织起来,通过在 ...
- 朴素贝叶斯算法源码分析及代码实战【python sklearn/spark ML】
一.简介 贝叶斯定理是关于随机事件A和事件B的条件概率的一个定理.通常在事件A发生的前提下事件B发生的概率,与在事件B发生的前提下事件A发生的概率是不一致的.然而,这两者之间有确定的关系,贝叶斯定理就 ...
- Spark ML源码分析之三 分类器
前面跟大家扯了这么多废话,终于到具体的机器学习模型了.大部分机器学习的教程,总要从监督学习开始讲起,而监督学习的众多算法当中,又以分类算法最为基础,原因在于分类问题非常的单纯直接,几乎 ...
- Extending sparklyr to Compute Cost for K-means on YARN Cluster with Spark ML Library
Machine and statistical learning wizards are becoming more eager to perform analysis with Spark MLli ...
- Spark ML源码分析之一 设计框架解读
本博客为作者原创,如需转载请注明参考 在深入理解Spark ML中的各类算法之前,先理一下整个库的设计框架,是非常有必要的,优秀的框架是对复杂问题的抽象和解剖,对这种抽象的学习本身 ...
- 使用spark ml pipeline进行机器学习
一.关于spark ml pipeline与机器学习 一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的 ...
随机推荐
- redis消息队列先进先出需要注意什么?
通常使用一个list来实现队列操作,这样有一个小限制,所以的任务统一都是先进先出,如果想优先处理某个任务就不太好处理了,这就需要让队列有优先级的概念,我们就可以优先处理高级别的任务,实现方式有以下几种 ...
- 二进制操作(1)–Bytes
1,Bytes的单元被当作字符串处理. 例如: 有些介绍会声称上述程序会得到这样的结果:b'\x00\x00\x00\x00' 在python v2.7.10上是得不到此结果的. 实际上,如果 typ ...
- dubbo入门学习(二)-----dubbo hello world
一.dubbo hello world入门示例 1.提出需求 某个电商系统,订单服务需要调用用户服务获取某个用户的所有地址: 我们现在需要创建两个服务模块进行测试: 模块 功能 订单服务web模块 创 ...
- Jeecms之查询实现
现有一需求如下: 按时间段查询及留言状态(已回复,未回复,已审批)来查询留言. 当时的想法是这样子的,首先要把查询的条件通过页面传递到后台.于是在后台管理中找看有没有类似的功能,费了半 ...
- YUM配置文件
创建容器,位置在/etc/yum.repos.d,扩展名必须是.repo #cd /etc/yum.repos.d #vim yum.repo 新建一个仓库文件,名字可以随便定义,在 ...
- windows搭建rabbitmq ha
1.安装erlang22.0 rabbitmq 3.7.15 2.bin下执行命令:rabbitmq-plugins enable rabbitmq_management3.替换.erlang.coo ...
- js校验文本框只能输入数字(包括小数)
form表单 <form method="POST" action=""> <input type="text" id=& ...
- Java数据结构和算法(六)--二叉树
什么是树? 上面图例就是一个树,用圆代表节点,连接圆的直线代表边.树的顶端总有一个节点,通过它连接第二层的节点,然后第二层连向更下一层的节点,以此递推 ,所以树的顶端小,底部大.和现实中的树是相反的, ...
- HTML 语法简要总结
HTML基本语法 认识网页 网页主要由文字.图像和超链接等元素构成.当然,除了这些元素,网页中还可以包含音频.视频以及Flash等. 常见浏览器内核介绍 浏览器是网页运行的平台,常用的浏览器有IE.火 ...
- WPF:数据绑定--PropertyChangeNotification属性更改通知
PropertyChangeNotification属性更改通知 实现效果:1.拍卖金额自动随属性值变化而通知界面绑定的值变化. 关键词 : INotifyPropertyChanged Obse ...