tensorflow在文本处理中的使用——skip-gram & CBOW原理总结
摘自:http://www.cnblogs.com/pinard/p/7160330.html
先看下列三篇,再理解此篇会更容易些(个人意见)
- 词向量基础
CBOW与Skip-Gram用于神经网络语言模型
词向量基础
用词向量来表示词并不是word2vec的首创,在很久之前就出现了。最早的词向量是很冗长的,它使用是词向量维度大小为整个词汇表的大小,对于每个具体的词汇表中的词,将对应的位置置为1。比如我们有下面的5个词组成的词汇表,词"Queen"的序号为2, 那么它的词向量就是(0,1,0,0,0)(0,1,0,0,0)。同样的道理,词"Woman"的词向量就是(0,0,0,1,0)(0,0,0,1,0)。这种词向量的编码方式我们一般叫做1-of-N representation或者one hot representation.
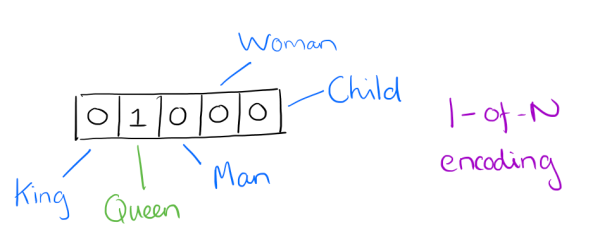
One hot representation用来表示词向量非常简单,但是却有很多问题。最大的问题是我们的词汇表一般都非常大,比如达到百万级别,这样每个词都用百万维的向量来表示简直是内存的灾难。这样的向量其实除了一个位置是1,其余的位置全部都是0,表达的效率不高,能不能把词向量的维度变小呢?
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
比如下图我们将词汇表里的词用"Royalty","Masculinity", "Femininity"和"Age"4个维度来表示,King这个词对应的词向量可能是(0.99,0.99,0.05,0.7)(0.99,0.99,0.05,0.7)。当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。
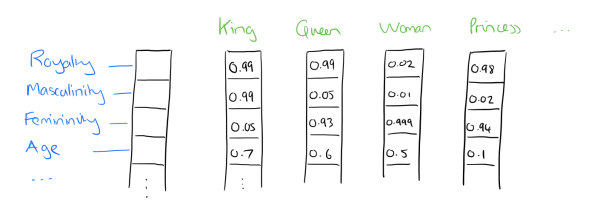
有了用Dristributed representation表示的较短的词向量,我们就可以较容易的分析词之间的关系了,比如我们将词的维度降维到2维,有一个有趣的研究表明,用下图的词向量表示我们的词时,我们可以发现:
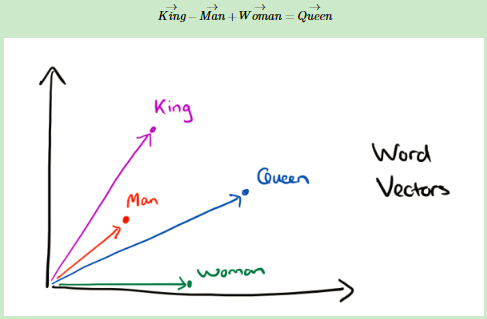
可见我们只要得到了词汇表里所有词对应的词向量,那么我们就可以做很多有趣的事情了。不过,怎么训练得到合适的词向量呢?一个很常见的方法是使用神经网络语言模型。
CBOW与Skip-Gram用于神经网络语言模型
在word2vec出现之前,已经有用神经网络DNN来用训练词向量进而处理词与词之间的关系了。采用的方法一般是一个三层的神经网络结构(当然也可以多层),分为输入层,隐藏层和输出层(softmax层)。
这个模型是如何定义数据的输入和输出呢?一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型。
- CBOW模型:训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。
- Skip-Gram模型:和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。
******************************************************************************************************************************
- CBOW模型
- input:我们的上下文大小取值为4,上下文对应的词有8个,前后各4个,这8个词是我们模型的输入。由于CBOW使用的是词袋模型,因此这8个词都是平等的,也就是不考虑他们和我们关注的词之间的距离大小,只要在我们上下文之内即可。
- output:期望输出词是"Learning",输出是所有词的softmax概率(训练的目标是期望训练样本特定词对应的softmax概率最大)
- Network:对应的CBOW神经网络模型输入层有8个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。
- 这样当我们有新的需求,要求出某8个词对应的最可能的输出中心词时,我们可以通过一次DNN前向传播算法并通过softmax激活函数找到概率最大的词对应的神经元即可。
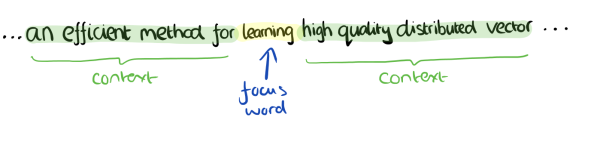
- Skip-Gram模型
- input:特定的这个词"Learning"是我们的输入
- output:我们的上下文大小取值为4,8个上下文词是我们的输出
- Network:我们的输入是特定词, 输出是softmax概率排前8的8个词,对应的Skip-Gram神经网络模型输入层有1个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。
- 这样当我们有新的需求,要求出某1个词对应的最可能的8个上下文词时,我们可以通过一次DNN前向传播算法得到概率大小排前8的softmax概率对应的神经元所对应的词即可。
以上就是神经网络语言模型中如何用CBOW与Skip-Gram来训练模型与得到词向量的大概过程。但是这和word2vec中用CBOW与Skip-Gram来训练模型与得到词向量的过程有很多的不同。
问题:
word2vec为什么 不用现成的DNN模型,要继续优化出新方法呢?最主要的问题是DNN模型的这个处理过程非常耗时。我们的词汇表一般在百万级别以上,这意味着我们DNN的输出层需要进行softmax计算各个词的输出概率的的计算量很大。有没有简化一点点的方法呢?可以去此处找答案
tensorflow在文本处理中的使用——skip-gram & CBOW原理总结的更多相关文章
- tensorflow在文本处理中的使用——Doc2Vec情感分析
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——CBOW词嵌入模型
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——skip-gram模型
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——Word2Vec预测
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——TF-IDF算法
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——词袋
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——辅助函数
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- TensorFlow实现文本情感分析详解
http://c.biancheng.net/view/1938.html 前面我们介绍了如何将卷积网络应用于图像.本节将把相似的想法应用于文本. 文本和图像有什么共同之处?乍一看很少.但是,如果将句 ...
- jQuery文本框中的事件应用
jQuery文本框中的事件应用 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "ht ...
随机推荐
- linuxtoy.org资源
https://linuxtoy.org/archives.html Archives 在 Android 系统上安装 Debian Linux 与 R (2015-07-14) Pinos:实现摄像 ...
- 【JZOJ4919】【NOIP2017提高组模拟12.10】神炎皇
题目描述 神炎皇乌利亚很喜欢数对,他想找到神奇的数对. 对于一个整数对(a,b),若满足a+b<=n且a+b是ab的因子,则成为神奇的数对.请问这样的数对共有多少呢? 数据范围 对于100%的数 ...
- MSSQL → 02:数据库结构
一.数据库的组成 在SQL Server 2008中,用户如何访问及使用数据库,就需要正确了解数据库中所有对象及其设置.数据库就像一个容器,它里面除了存放着数据的表之外,还有视图.存储过程.触发器.约 ...
- 找顺数【数位dp】
输出1到n中含有6的数的个数. 样例输入 100 样例输出 19 找规律感觉好难想(好像是什么100以内有19个,200以内有19*2个,600以内115个,700以内214个...,1000以内有2 ...
- pycahrm安装说明
从官网下载http://www.jetbrains.com/pycharm/download/other.html(PS:现在需要翻墙可以直接用文件夹里的那个) 下载完成后双击文件 第二步:双击已下载 ...
- Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第十三章:计算着色器(The Compute Shader)
原文:Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第十三章:计算着色器(The Compute Shader) 代码工程 ...
- Effective C++: 04设计与声明
18:让接口容易被正确使用,不易被误用 1:理想上,如果客户企图使用某个接口而却没有获得他所预期的行为,这个代码不该通过编译:如果代码通过了编译,它的作为就该是客户所想要的. 2:许多客户端的错误可以 ...
- UVa 825【简单dp,递推】
UVa 825 题意:给定一个网格图(街道图),其中有一些交叉路口点不能走.问从西北角走到东南角最短走法有多少种.(好像没看到给数据范围...) 简单的递推吧,当然也就是最简单的动归了.显然最短路长度 ...
- Django框架form表单配合ajax注册
总结一下,其实form组件的主要功能如下: 生成页面可用的HTML标签 对用户提交的数据进行校验 保留上次输入内容 下面是写的登录页面的实例 1:views视图中的代码 # 注册页面 def regi ...
- 实现ios后台缩略图模糊的一种方法
http://blog.sina.com.cn/s/blog_64cfe8f00102ux5t.html 今天玩手机(Iphone)发现应用切换支付宝会变模糊,不禁感叹,细节处理的太到位了. 怎么 ...