机器学习之路--Matplotlib
1.绘制折线图
在pandas里面有一种数据类型为datatime ,可以将不规范的日期改为:xxxx-xx-xx
import pandas as pd
import numpy as np
a = pd.read_csv('UNRATE.csv')
a['DATE'] = pd.to_datetime(a['DATE'])
print(a.head(12))
折线图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
a = pd.read_csv('UNRATE.csv')
b = a[0:12]
plt.plot(b['DATE'],b['VALUE'])
plt.show()
这样就能绘制出一个折线图了
如果横坐标写不下怎么办?我们可以将文字竖着写或者指定一个角度
plt.xticks(rotation = 45) #其中的45表示45°(和数学里面一样)
一般情况下要写横坐标与纵坐标要表达什么,还有标题
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
a = pd.read_csv('UNRATE.csv') #导入文件
b = a[0:12] #将数据的前12条提取出来
plt.plot(b['DATE'],b['VALUE']) #导入横纵坐标的数据
plt.xticks(rotation = 90) #横坐标90
plt.xlabel('Month') #横坐标名称
plt.ylabel('Unemployment Rate') #纵坐标名称
plt.title('Monthly Unemployment Trends, 1948') #标题
plt.show() #展示
输出;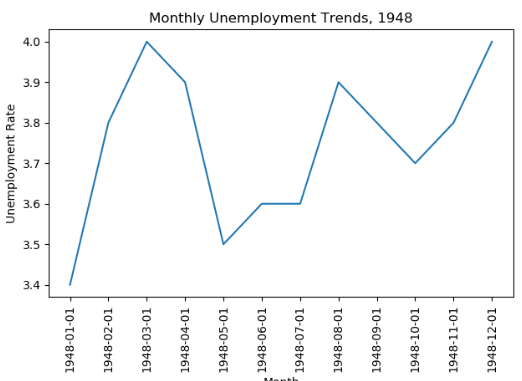
unrate['MONTH'] = unrate['DATE'].dt.month
unrate['MONTH'] = unrate['DATE'].dt.month
fig = plt.figure(figsize=(6,3)) #图的大小 plt.plot(unrate[0:12]['MONTH'], unrate[0:12]['VALUE'], c='red') #c为颜色
plt.plot(unrate[12:24]['MONTH'], unrate[12:24]['VALUE'], c='blue')
#在同一张图上绘制两条折线并进行对比
plt.show()
fig = plt.figure(figsize=(10,6))
colors = ['red', 'blue', 'green', 'orange', 'black']
for i in range(5):
start_index = i*12
end_index = (i+1)*12
subset = unrate[start_index:end_index]
plt.plot(subset['MONTH'], subset['VALUE'], c=colors[i])
#绘制5条折线在一张图中,用颜色加以区分
plt.show()
fig = plt.figure(figsize=(10,6))
colors = ['red', 'blue', 'green', 'orange', 'black']
for i in range(5):
start_index = i*12
end_index = (i+1)*12
subset = unrate[start_index:end_index]
label = str(1948 + i)
plt.plot(subset['MONTH'], subset['VALUE'], c=colors[i], label=label)
plt.legend(loc='best') #legend表示添加图例,loc是图例在折线图中的位置,best表示在系统觉得合适的位置,当然也可以自定义位置,位置的选择请help(legend)
#print help(plt.legend)
plt.show()
输出:
最终版:
fig = plt.figure(figsize=(10,6))
colors = ['red', 'blue', 'green', 'orange', 'black']
for i in range(5):
start_index = i*12
end_index = (i+1)*12
subset = unrate[start_index:end_index] #数据区间
label = str(1948 + i) #图例每次写的折线标题
plt.plot(subset['MONTH'], subset['VALUE'], c=colors[i], label=label)
plt.legend(loc='upper left') #放到左上角
plt.xlabel('Month, Integer') #横坐标标题
plt.ylabel('Unemployment Rate, Percent') #纵坐标标题
plt.title('Monthly Unemployment Trends, 1948-1952') #折线图标题 plt.show()
输出: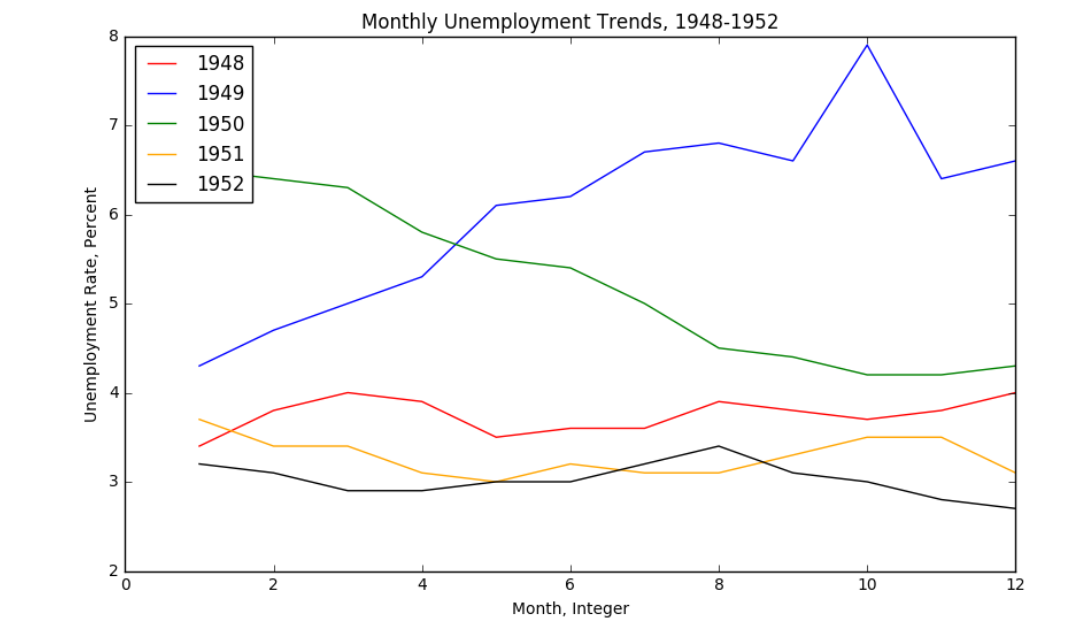
3、条形图与散点图
import pandas as pd
import numpy as np
from numpy import arange
import matplotlib.pyplot as plt
reviews = pd.read_csv('fandango_scores.csv')
cols = ['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars']
norm_reviews = reviews[cols]
num_cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars'] bar_heights = norm_reviews.ix[0, num_cols].values #当前柱的高度
#print bar_heights
bar_positions = arange(5) + 0.75 #0.75是第一个柱离原点的距离 然后每个柱距离为1 一共5个柱
#print bar_positions
fig, ax = plt.subplots()
ax.bar(bar_positions, bar_heights, 0.5) #0.5表示柱子的宽度
plt.show()
num_cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars']
bar_heights = norm_reviews.ix[0, num_cols].values
bar_positions = arange(5) + 0.75
tick_positions = range(1,6)
fig, ax = plt.subplots() ax.bar(bar_positions, bar_heights, 0.5)
ax.set_xticks(tick_positions)
ax.set_xticklabels(num_cols, rotation=45) ax.set_xlabel('Rating Source') #横坐标
ax.set_ylabel('Average Rating') #纵坐标
ax.set_title('Average User Rating For Avengers: Age of Ultron (2015)') #标题
plt.show()
输出: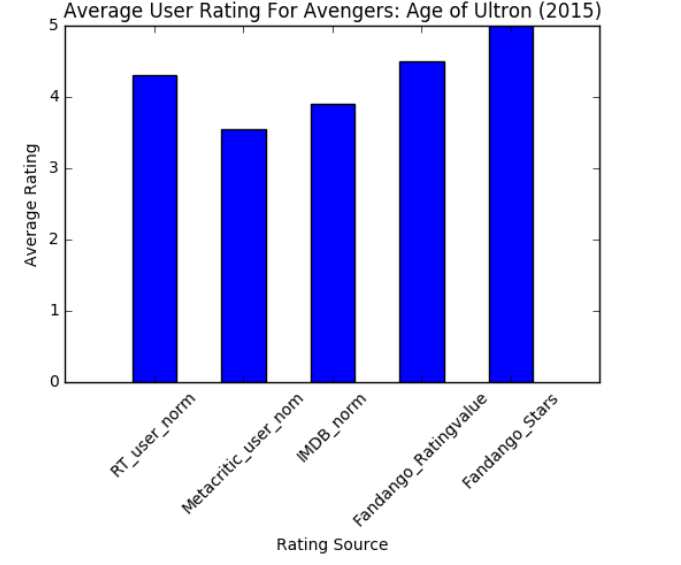
当然,也可以将柱形图变为横着的
import matplotlib.pyplot as plt
from numpy import arange
num_cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars'] bar_widths = norm_reviews.ix[0, num_cols].values
bar_positions = arange(5) + 0.75
tick_positions = range(1,6)
fig, ax = plt.subplots()
ax.barh(bar_positions, bar_widths, 0.5) #需要改变的地方,将bar改为barh ax.set_yticks(tick_positions)
ax.set_yticklabels(num_cols)
ax.set_ylabel('Rating Source')
ax.set_xlabel('Average Rating')
ax.set_title('Average User Rating For Avengers: Age of Ultron (2015)')
plt.show()
输出:
散点图:
fig, ax = plt.subplots()
ax.scatter(norm_reviews['Fandango_Ratingvalue'], norm_reviews #scatter画散点图
['RT_user_norm'])
ax.set_xlabel('Fandango')
ax.set_ylabel('Rotten Tomatoes')
plt.show()
输出:

画两个散点图:
fig = plt.figure(figsize=(5,10))
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
ax1.scatter(norm_reviews['Fandango_Ratingvalue'], norm_reviews['RT_user_norm'])
ax1.set_xlabel('Fandango')
ax1.set_ylabel('Rotten Tomatoes')
ax2.scatter(norm_reviews['RT_user_norm'], norm_reviews['Fandango_Ratingvalue'])
ax2.set_xlabel('Rotten Tomatoes')
ax2.set_ylabel('Fandango')
plt.show()
输出:
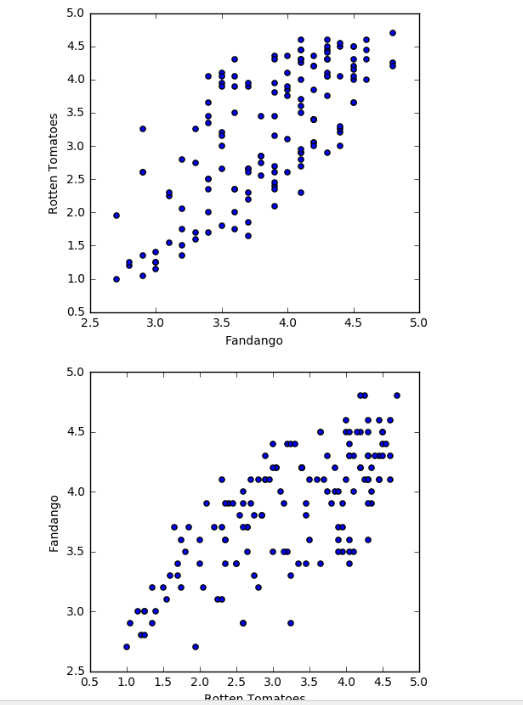
用fig设置参数,ax做实际画图的操作
4、柱形图与盒图
求数据的频数,并可视化
import pandas as pd
import numpy as np
from numpy import arange
import matplotlib.pyplot as plt
reviews = pd.read_csv('fandango_scores.csv')
cols = ['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue']
norm_reviews = reviews[cols]
print(norm_reviews[:5]) #输出数据
fandango_distribution = norm_reviews['Fandango_Ratingvalue'].value_counts() #需要数据
fandango_distribution = fandango_distribution.sort_index() #从小到大排序 imdb_distribution = norm_reviews['IMDB_norm'].value_counts()
imdb_distribution = imdb_distribution.sort_index() print(fandango_distribution) #一组数据的频数,比如4.3出现了6次 表示为:4.3 6
print(imdb_distribution) #另一组数据的频数
fig, ax = plt.subplots()
ax.hist(norm_reviews['Fandango_Ratingvalue']) #画出柱形图
#ax.hist(norm_reviews['Fandango_Ratingvalue'],bins=20) #bins = 20 表示一共有20个柱子
#ax.hist(norm_reviews['Fandango_Ratingvalue'], range=(4, 5),bins=20) #range代表了横坐标的区间
plt.show()
import pandas as pd
import numpy as np
from numpy import arange
import matplotlib.pyplot as plt
reviews = pd.read_csv('fandango_scores.csv')
cols = ['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue']
norm_reviews = reviews[cols] fig = plt.figure(figsize=(5,20))
ax1 = fig.add_subplot(4,1,1)
ax2 = fig.add_subplot(4,1,2)
ax3 = fig.add_subplot(4,1,3)
ax4 = fig.add_subplot(4,1,4)
ax1.hist(norm_reviews['Fandango_Ratingvalue'], bins=20, range=(0, 5))
ax1.set_title('Distribution of Fandango Ratings')
ax1.set_ylim(0, 50) #指定了这组数据的y轴取值区间 ax2.hist(norm_reviews['RT_user_norm'], 20, range=(0, 5))
ax2.set_title('Distribution of Rotten Tomatoes Ratings')
ax2.set_ylim(0, 50) ax3.hist(norm_reviews['Metacritic_user_nom'], 20, range=(0, 5))
ax3.set_title('Distribution of Metacritic Ratings')
ax3.set_ylim(0, 50) ax4.hist(norm_reviews['IMDB_norm'], 20, range=(0, 5))
ax4.set_title('Distribution of IMDB Ratings')
ax4.set_ylim(0, 50) plt.show()
输出:(在ml里run一下,太长了)
盒图(四分图,找中位数):
import pandas as pd
import numpy as np
from numpy import arange
import matplotlib.pyplot as plt
reviews = pd.read_csv('fandango_scores.csv')
cols = ['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue']
norm_reviews = reviews[cols]
fig, ax = plt.subplots()
ax.boxplot(norm_reviews['RT_user_norm'])
ax.set_xticklabels(['Rotten Tomatoes'])
ax.set_ylim(0, 5)
plt.show()
输出:
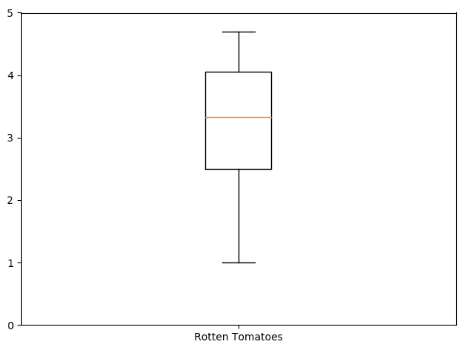
这样,就可以清晰的看到中位数的位置以及大致的数据区间
也可以在一张图上放入多张盒图,这样就可以区分各个属性的特征了
import pandas as pd
import numpy as np
from numpy import arange
import matplotlib.pyplot as plt
reviews = pd.read_csv('fandango_scores.csv')
cols = ['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue']
norm_reviews = reviews[cols]
num_cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue']
fig, ax = plt.subplots()
ax.boxplot(norm_reviews[num_cols].values)
ax.set_xticklabels(num_cols, rotation=90)
ax.set_ylim(0,5)
plt.show()
输出:
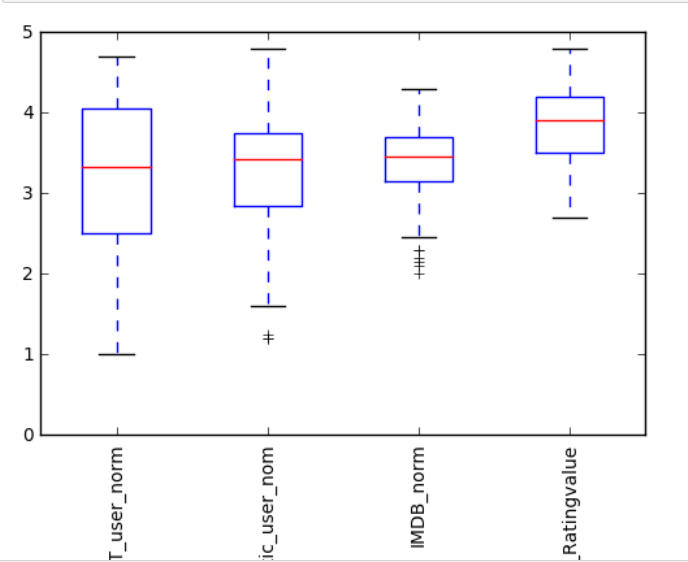
5、闲的蛋疼系列:
可以将坐标轴去掉:
for key,spine in ax.spines.items():
spine.set_visible(False) #去掉横纵坐标轴的线
可以去掉坐标轴的锯齿:
ax.tick_params(bottom="off", top="off", left="off", right="off")
6、最后的一些方法
*****一般在做图时为了让图中表达的清晰,让图尽量在一行或两行
fig = plt.figure(figsize=(12, 12)) #figsize参数调试
在作图时的颜色可以用自己定义的颜色
#Color
import pandas as pd
import matplotlib.pyplot as plt women_degrees = pd.read_csv('percent-bachelors-degrees-women-usa.csv')
major_cats = ['Biology', 'Computer Science', 'Engineering', 'Math and Statistics'] cb_dark_blue = (0/255, 107/255, 164/255) #自定义颜色,注意格式
cb_orange = (255/255, 128/255, 14/255) fig = plt.figure(figsize=(12, 12)) for sp in range(0,4):
ax = fig.add_subplot(2,2,sp+1)
# The color for each line is assigned here.
ax.plot(women_degrees['Year'], women_degrees[major_cats[sp]], c=cb_dark_blue, label='Women')
ax.plot(women_degrees['Year'], 100-women_degrees[major_cats[sp]], c=cb_orange, label='Men')
for key,spine in ax.spines.items():
spine.set_visible(False)
ax.set_xlim(1968, 2011)
ax.set_ylim(0,100)
ax.set_title(major_cats[sp])
ax.tick_params(bottom="off", top="off", left="off", right="off") plt.legend(loc='upper right')
plt.show()
如果要让线的宽度改变,让
ax.plot(women_degrees['Year'], women_degrees[major_cats[sp]], c=cb_dark_blue, label='Women', linewidth=10) #linewidth是改变线宽度的参数
ax.plot(women_degrees['Year'], 100-women_degrees[major_cats[sp]], c=cb_orange, label='Men', linewidth=10)
最终附上一波此例完整版:(其中有在图中某一坐标上标出此点名称):
import pandas as pd
import numpy as np
from numpy import arange
import matplotlib.pyplot as plt
women_degrees = pd.read_csv('percent-bachelors-degrees-women-usa.csv')
major_cats = ['Biology', 'Computer Science', 'Engineering', 'Math and Statistics']
stem_cats = ['Engineering', 'Computer Science', 'Psychology', 'Biology', 'Physical Sciences', 'Math and Statistics']
cb_dark_blue = (0/255, 107/255, 164/255)
cb_orange = (255/255, 128/255, 14/255)
fig = plt.figure(figsize=(18, 3)) for sp in range(0, 6):
ax = fig.add_subplot(1, 6, sp + 1)
ax.plot(women_degrees['Year'], women_degrees[stem_cats[sp]], c=cb_dark_blue, label='Women', linewidth=3)
ax.plot(women_degrees['Year'], 100 - women_degrees[stem_cats[sp]], c=cb_orange, label='Men', linewidth=3)
for key, spine in ax.spines.items():
spine.set_visible(False)
ax.set_xlim(1968, 2011)
ax.set_ylim(0, 100)
ax.set_title(stem_cats[sp])
ax.tick_params(bottom="off", top="off", left="off", right="off")
plt.legend(loc='upper right')
plt.show()
fig = plt.figure(figsize=(18, 3)) for sp in range(0, 6):
ax = fig.add_subplot(1, 6, sp + 1)
ax.plot(women_degrees['Year'], women_degrees[stem_cats[sp]], c=cb_dark_blue, label='Women', linewidth=3)
ax.plot(women_degrees['Year'], 100 - women_degrees[stem_cats[sp]], c=cb_orange, label='Men', linewidth=3)
for key, spine in ax.spines.items():
spine.set_visible(False)
ax.set_xlim(1968, 2011)
ax.set_ylim(0, 100)
ax.set_title(stem_cats[sp])
ax.tick_params(bottom="off", top="off", left="off", right="off") if sp == 0: #设置if语句后会对需要的图上加点的名称
ax.text(2005, 87, 'Men') #在坐标(2005,87)处标men
ax.text(2002, 8, 'Women')
elif sp == 5:
ax.text(2005, 62, 'Men')
ax.text(2001, 35, 'Women')
plt.show()
输出:

机器学习之路--Matplotlib的更多相关文章
- 机器学习之路--KNN算法
机器学习实战之kNN算法 机器学习实战这本书是基于python的,如果我们想要完成python开发,那么python的开发环境必不可少: (1)python3.52,64位,这是我用的python ...
- python 机器学习三剑客 之 Matplotlib
Matplotlib介绍: Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形 . 通过 Matplotlib,开发者可以仅需要几 ...
- 机器学习三剑客之Matplotlib基本操作
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形 . 通过 Matplotlib,可以仅需要几行代码,便可以生成绘图,线型图, ...
- 机器学习三剑客之matplotlib 数据绘图展示
线型图: #导包 import matplotlib.pyplot as plt #导入字体库 from matplotlib.font_manager import FontProperties # ...
- 机器学习之路:python 多项式特征生成PolynomialFeatures 欠拟合与过拟合
分享一下 线性回归中 欠拟合 和 过拟合 是怎么回事~为了解决欠拟合的情 经常要提高线性的次数建立模型拟合曲线, 次数过高会导致过拟合,次数不够会欠拟合.再建立高次函数时候,要利用多项式特征生成器 生 ...
- 机器学习之路:python 集成回归模型 随机森林回归RandomForestRegressor 极端随机森林回归ExtraTreesRegressor GradientBoostingRegressor回归 预测波士顿房价
python3 学习机器学习api 使用了三种集成回归模型 git: https://github.com/linyi0604/MachineLearning 代码: from sklearn.dat ...
- 机器学习之路:python k近邻回归 预测波士顿房价
python3 学习机器学习api 使用两种k近邻回归模型 分别是 平均k近邻回归 和 距离加权k近邻回归 进行预测 git: https://github.com/linyi0604/Machine ...
- 机器学习之路:python线性回归分类器 LogisticRegression SGDClassifier 进行良恶性肿瘤分类预测
使用python3 学习了线性回归的api 分别使用逻辑斯蒂回归 和 随机参数估计回归 对良恶性肿瘤进行预测 我把数据集下载到了本地,可以来我的git下载源代码和数据集:https://gith ...
- 我的机器学习之路--anaconda环境搭载
网上许多教程比较晦涩难懂,本教程按照笔者(新手)自己的视角记录,希望给大家一些帮助 1.安装anaconda 目前比较推荐的机器学习环境为anaconda. Anaconda指的是一个开源的Pytho ...
随机推荐
- @codeforces - 1205E@ Expected Value Again
目录 @description@ @solution@ @part - 1@ @part - 2@ @part - 3@ @solution@ @details@ @description@ 给定两个 ...
- @bzoj - 4524@ [Cqoi2016]伪光滑数
目录 @description@ @solution@ @version - 1@ @version - 2@ @accepted code@ @version - 1@ @version - 2@ ...
- linux 一些简单操作
vim ----三种模式 1.命令模式 2.输出模式 3.底线命令模式 w(e) 移动光标到下一个单词 b 移动到光标上一个单词 数字0 移动到本行开头 $ 移动光 ...
- 神经网络入门——6and感知机
AND 感知器练习 AND 感知器的权重和偏置项是什么? 把权重(weight1, weight2)和偏置项 bias 设置成正确的值,使得 AND 可以实现上图中的运算. 在这个例子 ...
- Python--day30--软件开发架构
软件开发架构: C/S架构: B/S架构: B/S架构和C/S架构的关系:
- 洛谷P1809 过河问题 经典贪心问题
作者:zifeiy 标签:贪心 题目链接:https://www.luogu.org/problem/P1809 我们假设第 \(i\) 个人过河的耗时是 \(t[i]\) ,并且 \(t[i]\) ...
- Python--day46--用户管理设计方案介绍
1,基于用户权限管理: 2,基于角色的权限管理: 开始一个项目如果要100天的,可能70天都在设计,比如设计数据库表结构,最后30天才是写代码.设计是最难的,写代码是最简单的. 还有一个重要的一点,写 ...
- Python--day43--补充之主键和外键
主键只有一个,但是可以用两列不为空的值组成:
- Python--day41--条件
1,条件 #锁 #acquire release#一个条件被创建之初 默认有一个False状态#False状态 会影响wait一直处于等待状态#notify(int数据类型) 造钥匙 代码示例:条件. ...
- 【codeforces 766D】Mahmoud and a Dictionary
time limit per test4 seconds memory limit per test256 megabytes inputstandard input outputstandard o ...