【Python】【爬虫】爬取酷狗TOP500
好啦好啦,那我们来拉开我们的爬虫之旅吧~~~
这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的。
环境配置
在此之前需要下载一个谷歌浏览器,下好后由于谷歌搜索是需要翻墙的,可设置打开网页为百度来使用
我们用到的是bs4,要求这两个库来提取,这是简称,全称是BeautifulSoup库。中文名也叫“美丽的汤”,安装也很简单。
:cmd命令行(win + r),输入pip install bs4完成安装,如下图:

请求库同样,pip安装请求
可能遇到的安装错误
如果执行pip install bs4后报错为“ pip不是重置的命令”
这是因为没有把pip的路径加入“环境变量”,加入环境变量即可
构造请求网址
我们是爬取酷狗音乐TOP500的'音乐名','歌手','歌名','播放时间'这几个数据网址如下:
https://www.kugou.com/yy/rank/home/1-8888.html?from=rank
:后只能看到前22名的数据,如下:

网址也叫url,唯一资源定位符,我们观察url如下几个细分:
https:传输协议,一般都是http或https
www.kugou.com:为域名
yy / rank / home / abs:为域名下的子网页
.html:代表此网页是静态的,后面会讲
?:问号后面的一般都是一些请求参数
我们可以看到,其中有一个1-8888这个参数,打开上述网址后我们只能看到前22首歌,想继续查看后面的歌曲就得翻页,就像“淘宝”那样查看下一页商品需要翻页,这里也是一样的道理,把1-8888改成2-8888,就会看到下一页的22首歌,如下:
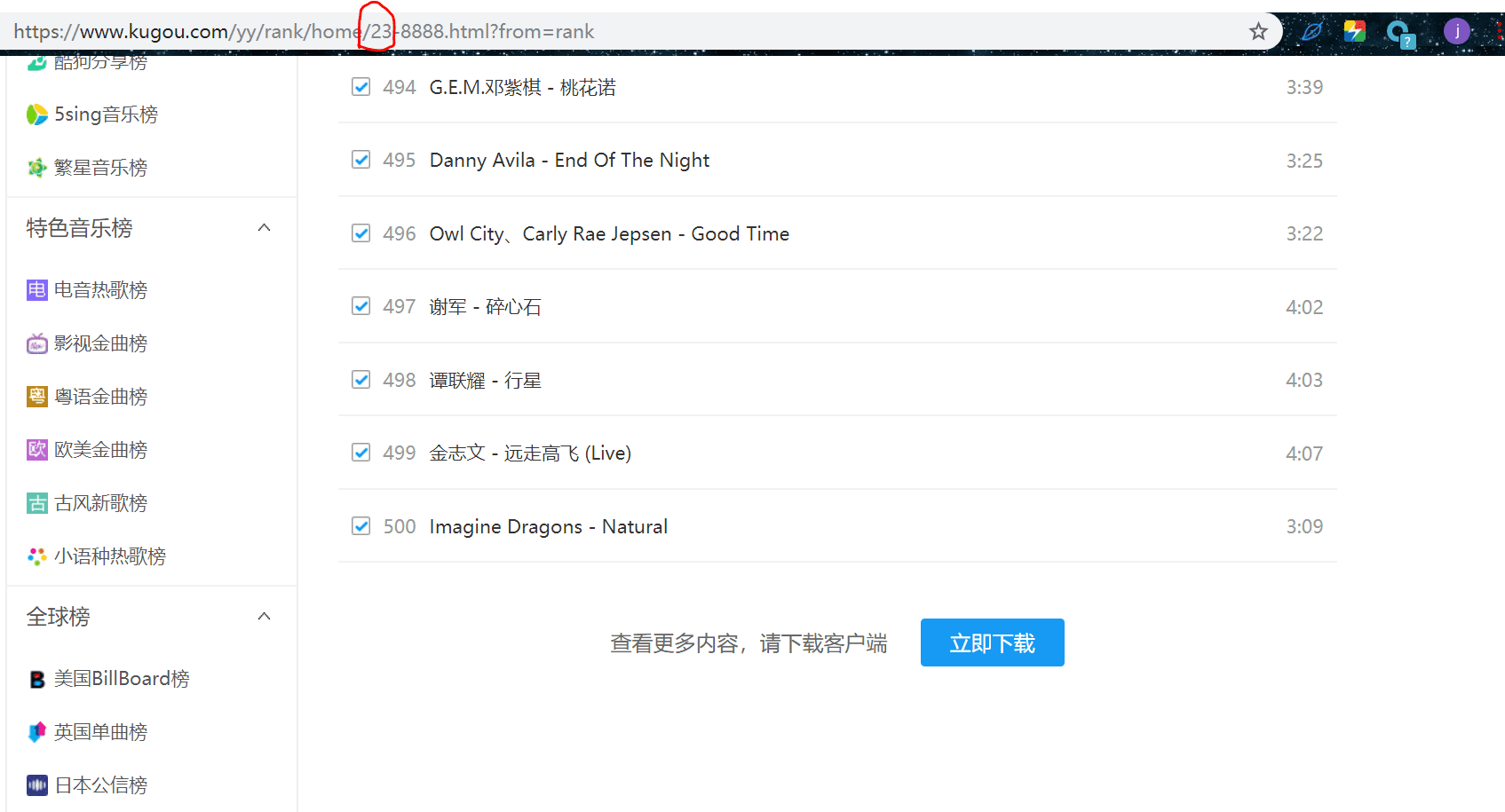
我们翻到第500首音乐那一页,可以看到页码如下有23页:
到这里我们我们需要提取的数据就知道在哪里了。
在知道了有多少页以及url的含义后,通过以下代码构造所有的url:
urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'
.format(str(i)) for i in range(1, 24)]
构造请求头
什么是请求头?
别人网页区别是人还是机器访问的一种手段,我们设置请求头为浏览器的请求头,对方就会认为我们是人为的访问,从而不会反爬,当然这只是最简单的一种防反爬的手段,一般我们都会带上,代码如下:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/53\
7.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
这并不是一个一个手敲的!!!
我们来看看它在哪里,按F12出现开发者工具,再按F5刷新出现如下图:
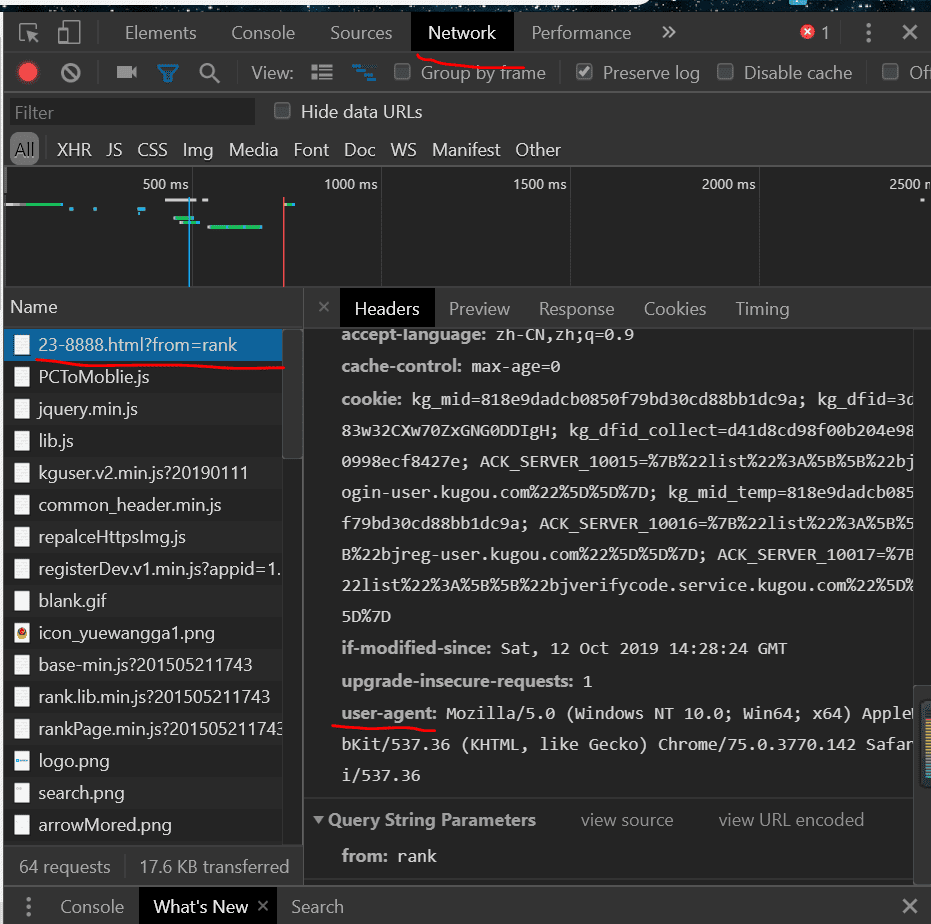
按照红线提示,找到用户代理
最后复制粘贴得到上面的代码
请求访问网页
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return
响应= request.get(URL,headers = headers)
使用请求库的get方法,去访问网页,第一个参数为网址,第二个参数为请求头,请求结果赋值给变量response,其中里面有很多结果,状态响应码,网页二进制代码,二进制等
response.status_code == 200
调用请求结果响应中的status_code查看请求状态码,200代表请求成功,就返回,否则返回一个None,状态码一般有2xx,4xx,3xx,5xx,分别代表请求成功,客户端访问失败,重定向,服务器问题。
返回response.text
返回响应结果的text,代表返回网页html源码
解析网页
在上面返回了一个响应后,我们需要解析网页html源码,需要结构化,可以提取
html = BeautifulSoup(html)
提取数据
我们来提取排名,鼠标放在排名这个元素这里,右键检查:
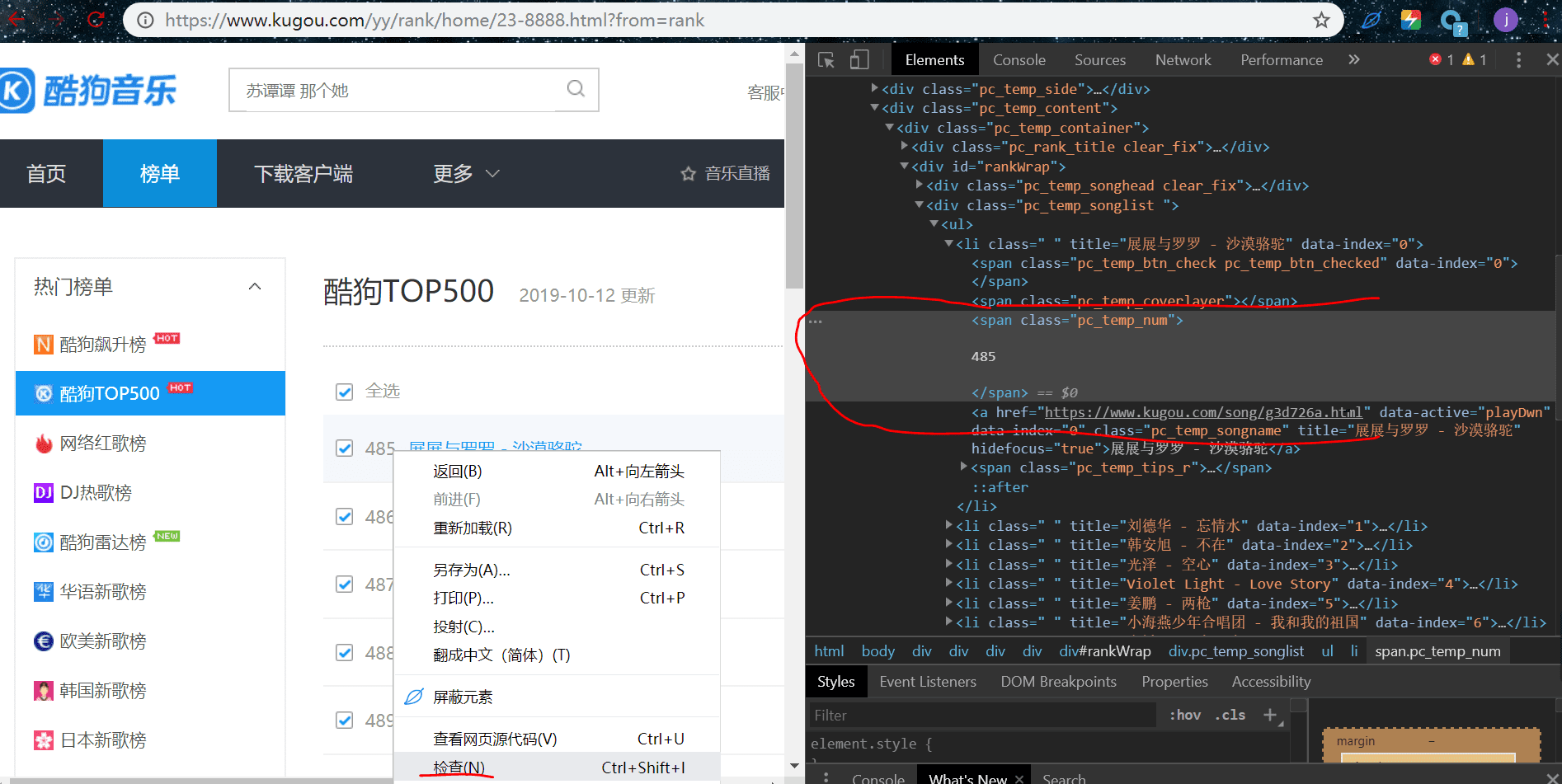
li:nth-child(1)需要改成li,因为nth-child(在右边可以看到一串二进制。其中有个高两个,就是刚刚那个排名的元素,快捷跟随提示选择然后复制过去,其中li:nth-child(1) 1)是获取li标签下的一条数据,我们是要获取这一页的所有排名
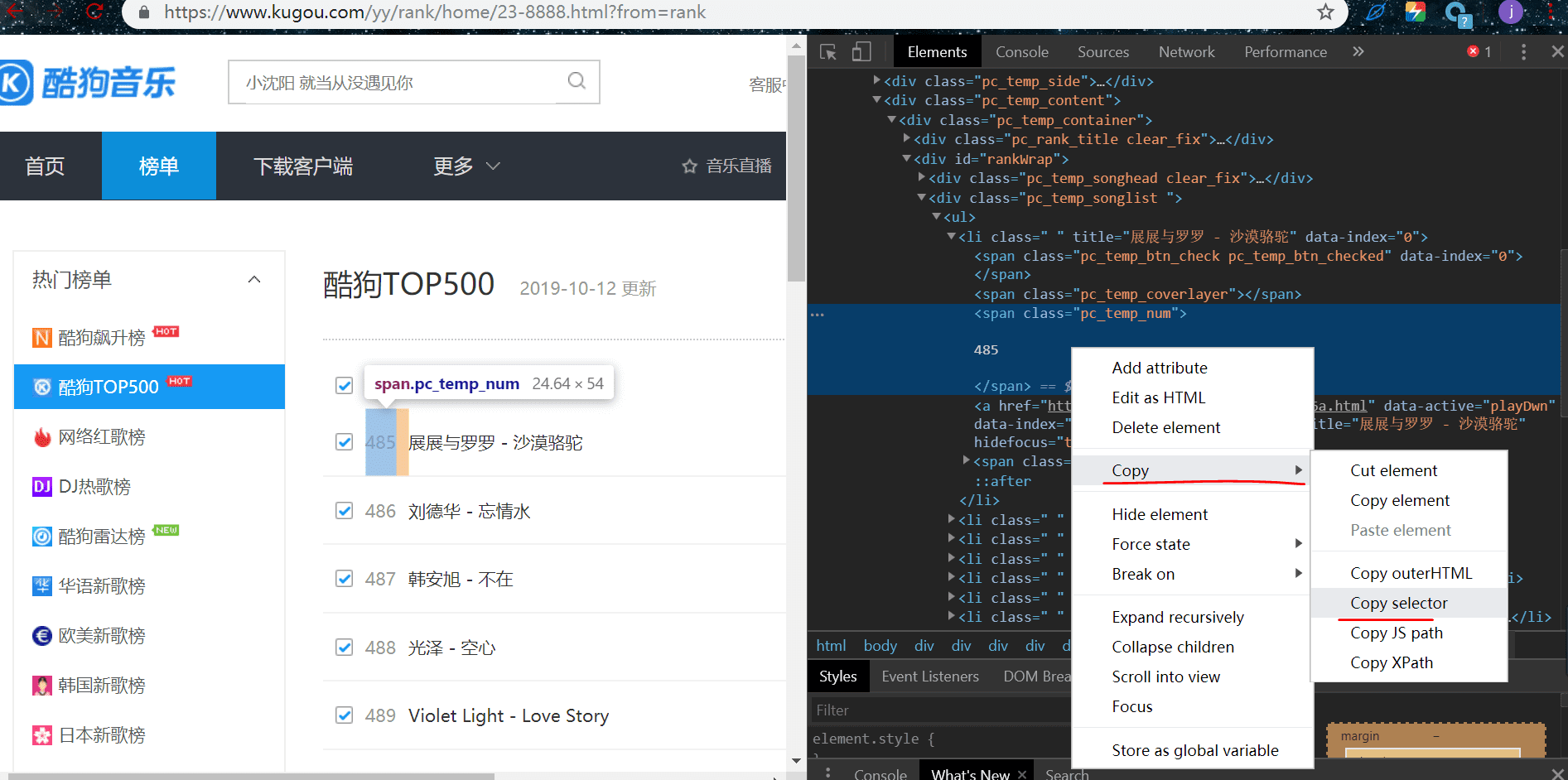
# 排名
ranks = html.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_num')
同样的方法提取歌手歌名,播放时间
# 歌手 + 歌名
names = html.select('#rankWrap > div.pc_temp_songlist > ul > li > a')
# 播放时间
times = html.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_tips_r > span')
获得数据
for r,n,t in zip(ranks,names,times):
r = r.get_text().replace('\n','').replace('\t','').replace('\r','')
n = n.get_text()
t = t.get_text().replace('\n','').replace('\t','').replace('\r','')
用了zip函数,意思是把对应的排名,歌名歌手,播放时间打包,可以这样理解zip函数的结果是一个列表[(排名,歌手歌名,播放时间),(排名,歌手歌名,播放时间)。。。。。]
每一次循环的r,n,t一次对应元组中的元素
get_text()
我们提取到的是这个数据所在的标签信息,并不是实际数据,所以需要使用get_text()获得实际数据
.replace('\ n','')。replace('\ t','')。replace('\ r','')
去掉实际数据中多余的字符串
最后把数据打包成字典打印
结束
到这里我们的关键步骤就完成了,大家好好理解一下,很容易的。
在这里说一下,这种提取方式是不会常见的,因为效果很不健壮,可能过几天被人网页改了改结构,就不能使用了,这里只是让大家初步了解一下爬虫的大致提取流程,后面会使用其他更健壮的方法的。
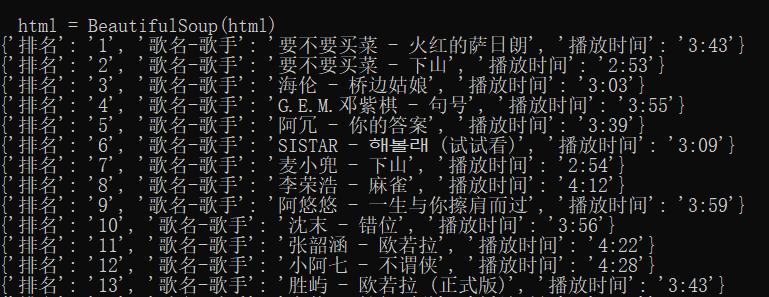
运行结果:
最终代码
import requests
import time
from bs4 import BeautifulSoup def get_html(url):
'''
获得 HTML
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/53\
7.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return def get_infos(html):
'''
提取数据
'''
html = BeautifulSoup(html)
# 排名
ranks = html.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_num')
# 歌手 + 歌名
names = html.select('#rankWrap > div.pc_temp_songlist > ul > li > a')
# 播放时间
times = html.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_tips_r > span') # 打印信息
for r,n,t in zip(ranks,names,times):
r = r.get_text().replace('\n','').replace('\t','').replace('\r','')
n = n.get_text()
t = t.get_text().replace('\n','').replace('\t','').replace('\r','')
data = {
'排名': r,
'歌名-歌手': n,
'播放时间': t
}
print(data) def main():
'''
主接口
'''
urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'
.format(str(i)) for i in range(1, 24)]
for url in urls:
html = get_html(url)
get_infos(html)
time.sleep(1) if __name__ == '__main__':
main()
【Python】【爬虫】爬取酷狗TOP500的更多相关文章
- 使用Xpath爬取酷狗TOP500的歌曲信息
使用xpath爬取酷狗TOP500的歌曲信息, 将排名.歌手名.歌曲名.歌曲时长,提取的结果以文件形式保存下来.参考网址:http://www.kugou.com/yy/rank/home/1-888 ...
- 爬虫实例学习——爬取酷狗TOP500数据
酷狗网址:https://www.kugou.com/yy/rank/home/1-8888.html?from=rank 环境:eclipse+pydev import requests from ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
- Python爬取酷狗飙升榜前十首(100)首,写入CSV文件
酷狗飙升榜,写入CSV文件 爬取酷狗音乐飙升榜的前十首歌名.歌手.时间,是一个很好的爬取网页内容的例子,对爬虫不熟悉的读者可以根据这个例子熟悉爬虫是如何爬取网页内容的. 需要用到的库:requests ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
随机推荐
- 安全 - 内容安全策略(CSP)(未完)
威胁 跨站脚本攻击(Cross-site scripting) 跨站脚本攻击Cross-site scripting (XSS)是一种安全漏洞,攻击者可以利用这种漏洞在网站上注入恶意的客户端代码. 攻 ...
- LeetCode 965. 单值二叉树 (遍历二叉树)
题目链接:https://leetcode-cn.com/problems/univalued-binary-tree/ 如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树. 只有给定的树是 ...
- Qt Gui 第十章
一.QListWidget.QTableWidget和QTreeWidget QTableWidget的item默认是可以编辑,其他两个的item默认是不可编辑.如果要将QTableWidget设置成 ...
- BLE直接Data channel抓包方法汇总
之前一致在做一些有关与BLE安全研究的“基础设施建设”工作,我们知道,在BLE进入跳频之后,所有的固定标志都会消失,但是是不是意味着没办法了?不是的.我会提出一些恢复出来的方法. 首先,前导码分析,B ...
- (CPSCA's)CPOJC+VIJOS
Coding Plus System Core Association 建立的Coding Plus Online Judge China 在Vijos上初步落脚,让我们拭目以待,等待暑假期间ACM1 ...
- Python原来这么好学-1.3节: 知识要点总结与内容复习
这是一本教同学们彻底学通Python的高质量学习教程,认真地学习每一章节的内容,每天只需学好一节,帮助你成为一名卓越的Python程序员: 本教程面向的是零编程基础的同学,非科班人士,以及有一定编 ...
- poj1141题解
题意 空序列是规则序列:用小括号(或者方括号)把一个规则序列括起来依然是规则序列:两个规则序列并列在一起仍然是规则序列. 给出一个括号字符串S,求一个规则序列ANS,满足S是ANS的子序列且ans尽可 ...
- IP地址分类及其相关计算问题
IP地址分类及其相关计算问题 公网IP和子网IP 公网IP: • A类:1.0.0.0 到 127.255.255.255 主要分配 给大量主机而局域网网络数量较少的大型网络 • B类:128.0.0 ...
- 微信小程序自定义顶部导航
注释:自定义导航需要自备相应图片 一.设置自定义顶部导航 Navigation是小程序的顶部导航组件,当页面配置navigationStyle设置为custom的时候可以使用此组件替代原生导航栏. 1 ...
- numpy 中array 和ndrray的区别联系
numpy.array() 标明array只是一个方法 ndarray 是类名,是一个实例. a=numpy.array(b) #这是把变量b转换为数组a,这里array()是个方法,a的类型 ...