HDFS NameNode重启优化
http://tech.meituan.com/namenode-restart-optimization.html
一、背景
在Hadoop集群整个生命周期里,由于调整参数、Patch、升级等多种场景需要频繁操作NameNode重启,不论采用何种架构,重启期间集群整体存在可用性和可靠性的风险,所以优化NameNode重启非常关键。
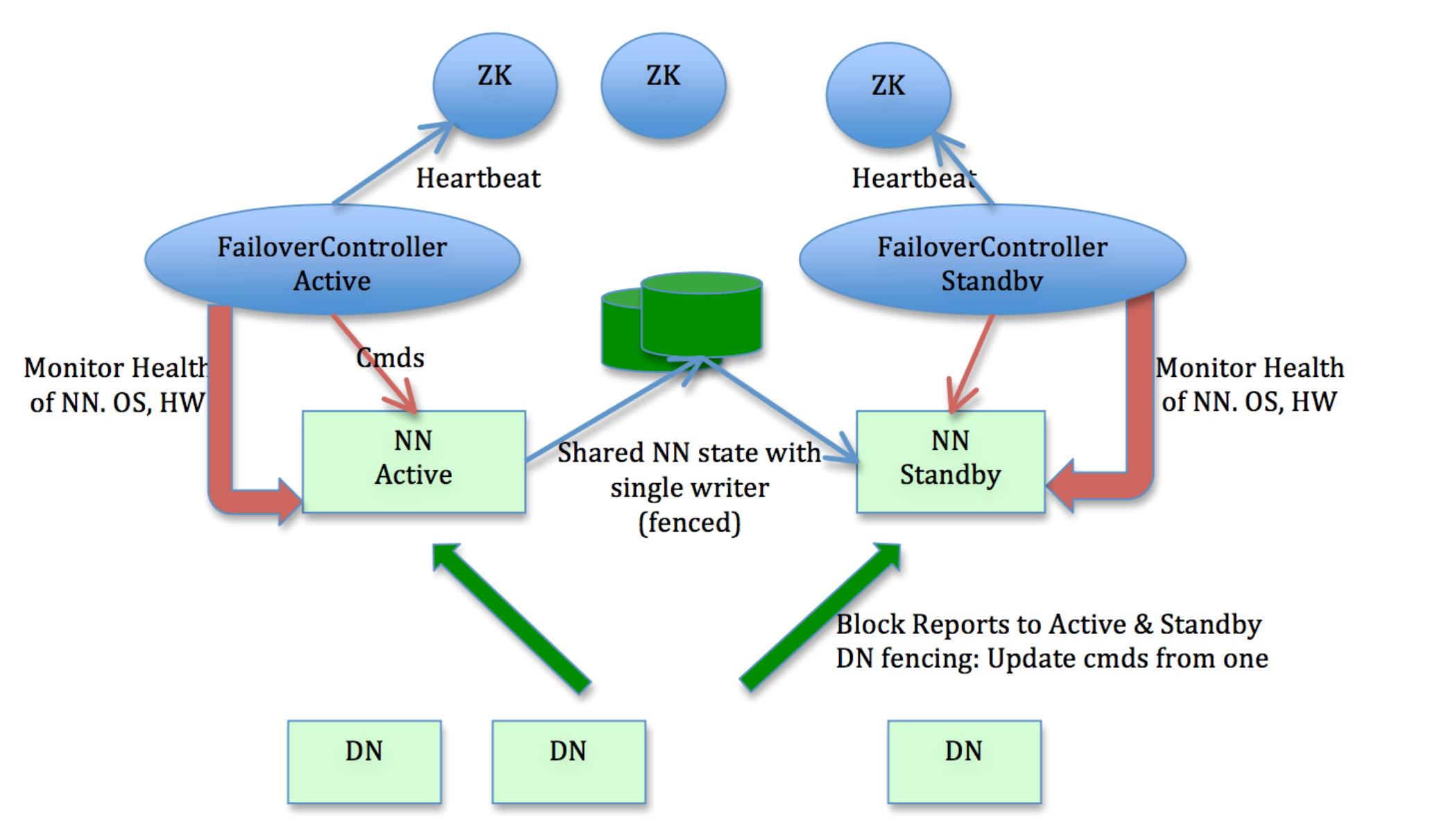
本文基于Hadoop-2.x和HA with QJM社区架构和系统设计(如图1所示),通过梳理NameNode重启流程,并在此基础上,阐述对NameNode重启优化实践。
二、NameNode重启流程
在HDFS的整个运行期里,所有元数据均在NameNode的内存集中管理,但是由于内存易失特性,一旦出现进程退出、宕机等异常情况,所有元数据都会丢失,给整个系统的数据安全会造成不可恢复的灾难。为了更好的容错能力,NameNode会周期进行CheckPoint,将其中的一部分元数据(文件系统的目录树Namespace)刷到持久化设备上,即二进制文件FSImage,这样的话即使NameNode出现异常也能从持久化设备上恢复元数据,保证了数据的安全可靠。
但是仅周期进行CheckPoint仍然无法保证所有数据的可靠,如前次CheckPoint之后写入的数据依然存在丢失的问题,所以将两次CheckPoint之间对Namespace写操作实时写入EditLog文件,通过这种方式可以保证HDFS元数据的绝对安全可靠。
事实上,除Namespace外,NameNode还管理非常重要的元数据BlocksMap,描述数据块Block与DataNode节点之间的对应关系。NameNode并没有对这部分元数据同样操作持久化,原因是每个DataNode已经持有属于自己管理的Block集合,将所有DataNode的Block集合汇总后即可构造出完整BlocksMap。
HA with QJM架构下,NameNode的整个重启过程中始终以SBN(StandbyNameNode)角色完成。与前述流程对应,启动过程分以下几个阶段:
- 加载FSImage;
- 回放EditLog;
- 执行CheckPoint(非必须步骤,结合实际情况和参数确定,后续详述);
- 收集所有DataNode的注册和数据块汇报。
默认情况下,NameNode会保存两个FSImage文件,与此对应,也会保存对应两次CheckPoint之后的所有EditLog文件。一般来说,NameNode重启后,通过对FSImage文件名称判断,选择加载最新的FSImage文件及回放该CheckPoint之后生成的所有EditLog,完成后根据加载的EditLog中操作条目数及距上次CheckPoint时间间隔(后续详述)确定是否需要执行CheckPoint,之后进入等待所有DataNode注册和元数据汇报阶段,当这部分数据收集完成后,NameNode的重启流程结束。
从线上NameNode历次重启时间数据看,各阶段耗时占比基本接近如图2所示。

图2 NameNode重启各阶段耗时占比
经过优化,在元数据总量540M(目录树240M,数据块300M),超过4K规模的集群上重启NameNode总时间~35min,其中加载FSImage耗时~15min,秒级回放EditLog,数据块汇报耗时~20min,基本能够满足生产环境的需求。
2.1 加载FSImage
如前述,FSImage文件记录了HDFS整个目录树Namespace相关的元数据。从Hadoop-2.4.0起,FSImage开始采用Google Protobuf编码格式描述(HDFS-5698),详细描述文件见fsimage.proto。根据描述文件和实现逻辑,FSImage文件格式如图3所示。

图3 FSImage文件格式
从fsimage.proto和FSImage文件存储格式容易看到,除了必要的文件头部校验(MAGIC)和尾部文件索引(FILESUMMARY)外,主要包含以下核心数据:
- NS_INFO(NameSystemSection):记录HDFS文件系统的全局信息,包括NameSystem的ID,当前已经分配出去的最大Block ID以及Transaction ID等信息;
- INODE(INodeSection):整个目录树所有节点数据,包括INodeFile/INodeDirectory/INodeSymlink等所有类型节点的属性数据,其中记录了如节点ID,节点名称,访问权限,创建和访问时间等等信息;
- INODE_DIR(INodeDirectorySection):整个目录树中所有节点之间的父子关系,配合INODE可构建完整的目录树;
- FILES_UNDERCONSTRUCTION(FilesUnderConstructionSection):尚未完成写入的文件集合,主要为重启时重建Lease集合;
- SNAPSHOT(SnapshotSection):记录Snapshot数据,快照是Hadoop 2.1.0引入的新特性,用于数据备份、回滚,以防止因用户误操作导致集群出现数据问题;
- SNAPSHOT_DIFF(SnapshotDiffSection):执行快照操作的目录/文件的Diff集合数据,与SNAPSHOT一起构建较完整的快照管理能力;
- SECRET_MANAGER(SecretManagerSection):记录DelegationKey和DelegationToken数据,根据DelegationKey及由DelegationToken构造出的DelegationTokenIdentifier方便进一步计算密码,以上数据可以完善所有合法Token集合;
- CACHE_MANAGER(CacheManagerSection):集中式缓存特性全局信息,集中式缓存特性是Hadoop-2.3.0为提升数据读性能引入的新特性;
- STRING_TABLE(StringTableSection):字符串到ID的映射表,维护目录/文件的Permission字符到ID的映射,节省存储空间。
NameNode执行CheckPoint时,遵循Protobuf定义及上述文件格式描述,重启加载FSImage时,同样按照Protobuf定义的格式从文件流中读出相应数据构建整个目录树Namespace及其他元数据。将FSImage文件从持久化设备加载到内存并构建出目录树结构后,实际上并没有完全恢复元数据到最新状态,因为每次CheckPoint之后还可能存在大量HDFS写操作。
2.2 回放EditLog
NameNode在响应客户端的写请求前,会首先更新内存相关元数据,然后再把这些操作记录在EditLog文件中,可以看到内存状态实际上要比EditLog数据更及时。
记录在EditLog之中的每个操作又称为一个事务,对应一个整数形式的事务编号。在当前实现中多个事务组成一个Segment,生成独立的EditLog文件,其中文件名称标记了起止的事务编号,正在写入的EditLog文件仅标记起始事务编号。EditLog文件的格式非常简单,没再通过Google Protobuf描述,文件格式如图4所示。

图4 EditLog文件格式
一个完整的EditLog文件包括四个部分内容,分别是:
- LAYOUTVERSION:版本信息;
- OP_START_LOG_SEGMENT:标识文件开始;
- RECORD:顺序逐个记录HDFS写操作的事务内容;
- OP_END_LOG_SEGMENT:标记文件结束。
NameNode加载FSImage完成后,即开始对该FSImage文件之后(通过比较FSImage文件名称中包含的事务编号与EditLog文件名称的起始事务编号大小确定)生成的所有EditLog严格按照事务编号从小到大逐个遵循上述的格式进行每一个HDFS写操作事务回放。
NameNode加载完所有必需的EditLog文件数据后,内存中的目录树即恢复到了最新状态。
2.3 DataNode注册汇报
经过前面两个步骤,主要的元数据被构建,HDFS的整个目录树被完整建立,但是并没有掌握数据块Block与DataNode之间的对应关系BlocksMap,甚至对DataNode的情况都不掌握,所以需要等待DataNode注册,并完成对从DataNode汇报上来的数据块汇总。待汇总的数据量达到预设比例(dfs.namenode.safemode.threshold-pct)后退出Safemode。
NameNode重启经过加载FSImage和回放EditLog后,所有DataNode不管进程是否发生过重启,都必须经过以下两个步骤:
- DataNode重新注册RegisterDataNode;
- DataNode汇报所有数据块BlockReport。
对于节点规模较大和元数据量较大的集群,这个阶段的耗时会非常可观。主要有三点原因:
- 处理BlockReport的逻辑比较复杂,相对其他RPC操作耗时较长。图5对比了BlockReport和AddBlock两种不同RPC的处理时间,尽管AddBlock操作也相对复杂,但是对比来看,BlockReport的处理时间显著高于AddBlock处理时间;
- NameNode对每一个BlockReport的RPC请求处理都需要持有全局锁,也就是说对于BlockReport类型RPC请求实际上是串行处理;
- NameNode重启时所有DataNode集中在同一时间段进行BlockReport请求。

图5 BlockReport和AddBlock两个RPC处理时间对比
之前我们在NameNode内存全景一文中详细描述过Block在NameNode元数据中的关键作用及与Namespace/DataNode/BlocksMap的复杂关系,从中也可以看出,每个新增Block需要维护多个关系,更何况重启过程中所有Block都需要建立同样复杂关系,所以耗时相对较高。
三、重启优化
根据前面对NameNode重启过程的简单梳理,在各个阶段可以适当的实施优化以加快NameNode重启过程。
HDFS-7097 解决重启过程中SBN执行CheckPoint时不能处理BlockReport请求的问题
Fix:2.7.0
Hadoop-2.7.0版本前,SBN(StandbyNameNode)在执行CheckPoint操作前会先获得全局读写锁fsLock,在此期间,BlockReport请求由于不能获得全局写锁会持续处于等待状态,直到CheckPoint完成后释放了fsLock锁后才能继续。NameNode重启的第三个阶段,同样存在这种情况。而且对于规模较大的集群,每次CheckPoint时间在分钟级别,对整个重启过程影响非常大。实际上,CheckPoint是对目录树的持久化操作,并不涉及BlocksMap数据结构,所以CheckPoint期间是可以让BlockReport请求直接通过,这样可以节省期间BlockReport排队等待带来的时间开销,HDFS-7097正是将锁粒度放小解决了CheckPoint过程不能处理BlockReport类型RPC请求的问题。
与HDFS-7097相对,另一种思路也值得借鉴,就是重启过程尽可能避免出现CheckPoint。触发CheckPoint有两种情况:时间周期或HDFS写操作事务数,分别通过参数dfs.namenode.checkpoint.period和dfs.namenode.checkpoint.txns控制,默认值分别是3600s和1,000,000,即默认情况下一个小时或者写操作的事务数超过1,000,000触发一次CheckPoint。为了避免在重启过程中频繁执行CheckPoint,可以适当调大dfs.namenode.checkpoint.txns,建议值10,000,000 ~ 20,000,000,带来的影响是EditLog文件累计的个数会稍有增加。从实践经验上看,对一个有亿级别元数据量的NameNode,回放一个EditLog文件(默认1,000,000写操作事务)时间在秒级,但是执行一次CheckPoint时间通常在分钟级别,综合权衡减少CheckPoint次数和增加EditLog文件数收益比较明显。
HDFS-6763 解决SBN每间隔1min全局计算和验证Quota值导致进程Hang住数秒的问题
Fix:2.8.0
ANN(ActiveNameNode)将HDFS写操作实时写入JN的EditLog文件,为同步数据,SBN默认间隔1min从JN拉取一次EditLog文件并进行回放,完成后执行全局Quota检查和计算,当Namespace规模变大后,全局计算和检查Quota会非常耗时,在此期间,整个SBN的Namenode进程会被Hang住,以至于包括DN心跳和BlockReport在内的所有RPC请求都不能及时处理。NameNode重启过程中这个问题影响突出。
实际上,SBN在EditLog Tailer阶段计算和检查Quota完全没有必要,HDFS-6763将这段处理逻辑后移到主从切换时进行,解决SBN进程间隔1min被Hang住的问题。
从优化效果上看,对一个拥有接近五亿元数据量,其中两亿数据块的NameNode,优化前数据块汇报阶段耗时~30min,其中触发超过20次由于计算和检查Quota导致进程Hang住~20s的情况,整个BlockReport阶段存在超过5min无效时间开销,优化后可到~25min。
HDFS-7980 简化首次BlockReport处理逻辑优化重启时间
Fix:2.7.1
NameNode加载完元数据后,所有DataNode尝试开始进行数据块汇报,如果汇报的数据块相关元数据还没有加载,先暂存消息队列,当NameNode完成加载相关元数据后,再处理该消息队列。对第一次块汇报的处理比较特别(NameNode重启后,所有DataNode的BlockReport都会被标记成首次数据块汇报),为提高处理速度,仅验证块是否损坏,之后判断块状态是否为FINALIZED,若是建立数据块与DataNode的映射关系,建立与目录树中文件的关联关系,其他信息一概暂不处理。对于非初次数据块汇报,处理逻辑要复杂很多,对报告的每个数据块,不仅检查是否损坏,是否为FINALIZED状态,还会检查是否无效,是否需要删除,是否为UC状态等等;验证通过后建立数据块与DataNode的映射关系,建立与目录树中文件的关联关系。
初次数据块汇报的处理逻辑独立出来,主要原因有两方面:
- 加快NameNode的启动时间;测试数据显示含~500M元数据的NameNode在处理800K个数据块的初次块汇报的处理时间比正常块汇报的处理时间可降低一个数量级;
启动过程中,不提供正常读写服务,所以只要确保正常数据(整个Namespace和所有FINALIZED状态Blocks)无误,无效和冗余数据处理完全可以延后到IBR(IncrementalBlockReport)或下次BR(BlockReport)。
这本来是非常合理和正常的设计逻辑,但是实现时NameNode在判断是否为首次数据块块汇报的逻辑一直存在问题,导致这段非常好的改进点逻辑实际上长期并未真正执行到,直到HDFS-7980在Hadoop-2.7.1修复该问题。HDFS-7980的优化效果非常明显,测试显示,对含80K Blocks的BlockReport RPC请求的处理时间从~500ms可优化到~100ms,从重启期整个BlockReport阶段看,在超过600M元数据,其中300M数据块的NameNode显示该阶段从~50min优化到~25min。
HDFS-7503 解决重启前大删除操作会造成重启后锁内写日志降低处理能力
Fix:2.7.0
若NameNode重启前产生过大删除操作,当NameNode加载完FSImage并回放了所有EditLog构建起最新目录树结构后,在处理DataNode的BlockReport时,会发现有大量Block不属于任何文件,Hadoop-2.7.0版本前,对于这类情况的输出日志逻辑在全局锁内,由于存在大量IO操作的耗时,会严重拉长处理BlockReport的处理时间,影响NameNode重启时间。HDFS-7503的解决办法非常简单,把日志输出逻辑移出全局锁外。线上效果上看对同类场景优化比较明显,不过如果重启前不触发大的删除操作影响不大。
防止热备节点SBN(StandbyNameNode)/冷备节点SNN(SecondaryNameNode)长时间未正常运行堆积大量Editlog拖慢NameNode重启时间
选择HA热备方案SBN(StandbyNameNode)还是冷备方案SNN(SecondaryNameNode)架构,执行CheckPoint的逻辑几乎一致,如图6所示。如果SBN/SNN服务长时间未正常运行,CheckPoint不能按照预期执行,这样会积压大量EditLog。积压的EditLog文件越多,重启NameNode需要加载EditLog时间越长。所以尽可能避免出现SNN/SBN长时间未正常服务的状态。

图6 CheckPoint流程
在一个有500M元数据的NameNode上测试加载一个200K次HDFS事务操作的EditLog文件耗时~5s,按照默认2min的EditLog滚动周期,如果一周时间SBN/SNN未能正常工作,则会累积~5K个EditLog文件,此后一旦发生NameNode重启,仅加载EditLog文件的时间就需要~7h,也就是整个集群存在超过7h不可用风险,所以切记要保证SBN/SNN不能长时间故障。
HDFS-6425 HDFS-6772 NameNode重启后DataNode快速退出blockContentsStale状态防止PostponedMisreplicatedBlocks过大影响对其他RPC请求的处理能力
当集群中大量数据块的实际存储副本个数超过副本数时(跨机房架构下这种情况比较常见),NameNode重启后会迅速填充到PostponedMisreplicatedBlocks,直到相关数据块所在的所有DataNode汇报完成且退出Stale状态后才能被清理。如果PostponedMisreplicatedBlocks数据量较大,每次全遍历需要消耗大量时间,且整个过程也要持有全局锁,严重影响处理BlockReport的性能,HDFS-6425和HDFS-6772分别将可能在BlockReport逻辑内部遍历非常大的数据结构PostponedMisreplicatedBlocks优化到异步执行,并在NameNode重启后让DataNode快速退出blockContentsStale状态避免PostponedMisreplicatedBlocks过大入手优化重启效率。
降低BlockReport时数据规模
NameNode处理BlockReport的效率低主要原因还是每次BlockReport所带的Block规模过大造成,所以可以通过调整Block数量阈值,将一次BlockReport分成多盘分别汇报,以提高NameNode对BlockReport的处理效率。可参考的参数为:dfs.blockreport.split.threshold,默认值1,000,000,即当DataNode本地的Block个数超过1,000,000时才会分盘进行汇报,建议将该参数适当调小,具体数值可结合NameNode的处理BlockReport时间及集群中所有DataNode管理的Block量分布确定。
重启完成后对比检查数据块上报情况
前面提到NameNode汇总DataNode上报的数据块量达到预设比例(dfs.namenode.safemode.threshold-pct)后就会退出Safemode,一般情况下,当NameNode退出Safemode后,我们认为已经具备提供正常服务的条件。但是对规模较大的集群,按照这种默认策略及时执行主从切换后,容易出现短时间丢块的问题。考虑在200M数据块的集群,默认配置项dfs.namenode.safemode.threshold-pct=0.999,也就是当NameNode收集到200M*0.999=199.8M数据块后即可退出Safemode,此时实际上还有200K数据块没有上报,如果强行执行主从切换,会出现大量的丢块问题,直到数据块汇报完成。应对的办法比较简单,尝试调大dfs.namenode.safemode.threshold-pct到1,这样只有所有数据块上报后才会退出Safemode。但是这种办法一样不能保证万无一失,如果启动过程中有DataNode汇报完数据块后进程挂掉,同样存在短时间丢失数据的问题,因为NameNode汇总上报数据块时并不检查副本数,所以更稳妥的解决办法是利用主从NameNode的JMX数据对比所有DataNode当前汇报数据块量的差异,当差异都较小后再执行主从切换可以保证不发生上述问题。
其他
除了优化NameNode重启时间,实际运维中还会遇到需要滚动重启集群所有节点或者一次性重启整集群的情况,不恰当的重启方式也会严重影响服务的恢复时间,所以合理控制重启的节奏或选择合适的重启方式尤为关键,HDFS集群启动方式分析一文对集群重启方式进行了详细的阐述,这里就不再展开。
经过多次优化调整,从线上NameNode历次的重启时间监控指标上看,收益非常明显,图7截取了其中几次NameNode重启时元数据量及重启时间开销对比,图中直观显示在500M元数据量级下,重启时间从~4000s优化到~2000s。

图7 NameNode重启时间对比
这里罗列了一小部分实践过程中可以有效优化重启NameNode时间或者重启全集群的点,其中包括了社区成熟Patch和相关参数优化,虽然实现逻辑都很小,但是实践收益非常明显。当然除了上述提到,NameNode重启还有很多可以优化的地方,比如优化FSImage格式,并行加载等等,社区也在持续关注和优化,部分讨论的思路也值得关注、借鉴和参考。
四、总结
NameNode重启甚至全集群重启在整个Hadoop集群的生命周期内是比较频繁的运维操作,优化重启时间可以极大提升运维效率,避免可能存在的风险。本文通过分析NameNode启动流程,并结合实践过程简单罗列了几个供参考的有效优化点,借此希望能给实践过程提供可优化的方向和思路。
五、参考文献
作者简介
小桥,美团点评技术工程部数据平台研发工程师。2012年北京航空航天大学毕业,2015年初加入美团点评,关注Hadoop生态存储方向,致力于为美团点评提供稳定、高效、易用的离线数据存储服务。
回答“思考题”、发现文章有错误、对内容有疑问,都可以来微信公众号(美团点评技术团队)后台给我们留言。我们每周会挑选出一位“优秀回答者”,赠送一份精美的小礼品。快来扫码关注我们吧!

HDFS NameNode重启优化的更多相关文章
- HDFS NameNode 设计实现解析
接前文 分布式存储-HDFS 架构解析,我们总体分析了 HDFS 架构的主要构成组件包括:NameNode.DataNode 和 Client.本文首先进一步解析 HDFS NameNode 的设计和 ...
- 后端分布式系列:分布式存储-HDFS NameNode 设计实现解析
接前文 分布式存储-HDFS 架构解析,我们总体分析了 HDFS 架构的主要构成组件包括:NameNode.DataNode 和 Client.本文首先进一步解析 HDFS NameNode 的设计和 ...
- Hadoop:HDFS NameNode内存全景
原文转自:https://tech.meituan.com/namenode.html 感谢原作者 一.概述 从整个HDFS系统架构上看,NameNode是其中最重要.最复杂也是最容易出现问题的地方, ...
- HDFS NameNode内存详解
前言 <HDFS NameNode内存全景>中,我们从NameNode内部数据结构的视角,对它的内存全景及几个关键数据结构进行了简单解读,并结合实际场景介绍了NameNode可能遇到的问题 ...
- HDFS NameNode内存全景
一.概述 从整个HDFS系统架构上看,NameNode是其中最重要.最复杂也是最容易出现问题的地方,而且一旦NameNode出现故障,整个Hadoop集群就将处于不可服务的状态,同时随着数据规模和集群 ...
- HDFS集群优化篇
HDFS集群优化篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.操作系统级别优化 1>.优化文件系统(推荐使用EXT4和XFS文件系统,相比较而言,更推荐后者,因为XF ...
- Hadoop HDFS NameNode工作机制
Secondary namenode 首先,我们假设如果存储在Namenode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中 ...
- HDFS NameNode HA 部署文档
简介: HDFS High Availability Using the Quorum Journal Manager Hadoop 2.x 中,HDFS 组件有三个角色:NameNode.DataN ...
- Hadoop(五)—— HDFS NameNode、DataNode工作机制
一.NN与2NN工作机制 NameNode(NN) 1.当HDFS启动时,会加载日志(edits)和镜像文件(fsImage)到内存中. 2-4.当元数据的增删改查请求进来时,NameNode会先将操 ...
随机推荐
- 将 Sidecar 容器带入新的阶段
作者 | 徐迪.张晓宇 导读:本文根据徐迪和张晓宇在 KubeCon NA 2019 大会分享整理.分享将会从以下几个方面进行切入:首先会简单介绍一下什么是 Sidecar 容器:其次,会分享几个阿里 ...
- 【一起学源码-微服务】Nexflix Eureka 源码十一:EurekaServer自我保护机制竟然有这么多Bug?
前言 前情回顾 上一讲主要讲了服务下线,已经注册中心自动感知宕机的服务. 其实上一讲已经包含了很多EurekaServer自我保护的代码,其中还发现了1.7.x(1.9.x)包含的一些bug,但这些问 ...
- linux tomcat安装
一.下载tomcat包 下载tomcat包并上传至服务器中 解压文件: tar -zxvf apache-tomcat-8.5.47.tar.gz 为了后期程序的便于管理,我们还需要将Tomcat复制 ...
- 超详细Node安装教程
今天周末休息,我制定了我的2020年度规划,其中包含编写50篇养成写博文的习惯.算下来平均每周一篇,感觉也不是很难,但我的写作能力不是很好,争取一次比一次好!希望自己能够坚持下去.2020为自己而活, ...
- background,position,绝对定位中位置属性的定位规则,cursor
backgorund背景 background-color:red; 背景颜色 background-image:url(路径);背景图片 background-repeat:no-repeat;不重 ...
- vue项目准备工作
1.写文档: 产品说明.工作日志.接口说明文档.数据库说明文档.项目架构说明文档等···· 例如:后台管理系统:商品的管理.店铺的管理.店铺类别管理.管理员的管理.用户管理等····· 前端渲染 ...
- (三)Django模板语言
一.字典,列表,类在template模板中的使用 在视图函数中,即views.py中进行传值操作,可通过render方法,进行传值 from django.shortcuts import rende ...
- cannot open git-upload-pack,cannot open git-receive-pack,Can't connect to any URI错误解决方法eclipse
cannot open git-upload-pack,cannot open git-receive-pack,Can't connect to any URI错误解决方法eclipse 解决ecl ...
- css部分概念
1.层叠 规则之间属性相同,值不同的时候就会发生声明冲突,这个时候层叠就会起作用了,层叠会将我们声明的不同的值进行保留,相同的值进行比较,选权重值更高的一个来运行.具体情境如下:假设我们定义了一个di ...
- 【转】在Eclipse下搭建Android开发环境教程
本文将全程演示Android开发环境的搭建过程,无需配置环境变量.所有软件都是写该文章时最新版本,希望大家喜欢. 一 相关下载 三 Eclipse配置 (1)Java JDK下载 1 安装andr ...