源码详解系列(八) ------ 全面讲解HikariCP的使用和源码
简介
HikariCP 是用于创建和管理连接,利用“池”的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制、连接可靠性测试、连接泄露控制、缓存语句等功能,另外,和 druid 一样,HikariCP 也支持监控功能。
HikariCP 是目前最快的连接池,就连风靡一时的 BoneCP 也停止维护,主动让位给它,SpringBoot 也把它设置为默认连接池。
看过 HikariCP 源码的同学就会发现,相比其他连接池,它真的非常轻巧且简单,有许多值得我们学习的地方,尤其性能提升方面,本文也就针对这一方面重点分析。
本文将包含以下内容(因为篇幅较长,可根据需要选择阅读):
- HikariCP 的使用方法(入门案例、JDNI 使用、JMX 使用)
- HikariCP 的配置参数详解
- HikariCP 源码分析
其他连接池的内容也可以参考我的系列博客:
源码详解系列(四) ------ DBCP2的使用和分析(包括JNDI和JTA支持)
源码详解系列(五) ------ C3P0的使用和分析(包括JNDI)
源码详解系列(六) ------ 全面讲解druid的使用和源码
使用例子-入门
需求
使用 HikariCP 连接池获取连接对象,对用户数据进行简单的增删改查(sql 脚本项目中已提供)。
工程环境
JDK:1.8.0_231
maven:3.6.1
IDE:Spring Tool Suite 4.3.2.RELEASE
mysql-connector-java:8.0.15
mysql:5.7 .28
Hikari:2.6.1
主要步骤
编写 hikari.properties,设置数据库连接参数和连接池基本参数等;
通过
HikariConfig加载 hikari.properties 文件,并创建HikariDataSource对象;通过
HikariDataSource对象获得Connection对象;使用
Connection对象对用户表进行增删改查。
创建项目
项目类型Maven Project,打包方式war(其实jar也可以,之所以使用war是为了测试 JNDI)。
引入依赖
这里引入日志包,主要为了打印配置信息,不引入不会有影响的。
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- hikari -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>2.6.1</version>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
<!-- log -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.28</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
<type>jar</type>
</dependency>
编写hikari.properties
配置文件路径在resources目录下,因为是入门例子,这里仅给出数据库连接参数和连接池基本参数,后面会对所有配置参数进行详细说明。另外,数据库 sql 脚本也在该目录下。
#-------------基本属性--------------------------------
jdbcUrl=jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true
username=root
password=root
#JDBC驱动使用的Driver实现类类名
#默认为空。会根据jdbcUrl来解析
driverClassName=com.mysql.cj.jdbc.Driver
#-------------连接池大小相关参数--------------------------------
#最大连接池数量
#默认为10。可通过JMX动态修改
maximumPoolSize=10
#最小空闲连接数量
#默认与maximumPoolSize一致。可通过JMX动态修改
minimumIdle=0
获取连接池和获取连接
项目中编写了JDBCUtil来初始化连接池、获取连接、管理事务和释放资源等,具体参见项目源码。
路径:cn.zzs.hikari
HikariConfig config = new HikariConfig("/hikari.properties");
DataSource dataSource = new HikariDataSource(config);
编写测试类
这里以保存用户为例,路径在 test 目录下的cn.zzs.hikari。
@Test
public void save() throws SQLException {
// 创建sql
String sql = "insert into demo_user values(null,?,?,?,?,?)";
Connection connection = null;
PreparedStatement statement = null;
try {
// 获得连接
connection = JDBCUtils.getConnection();
// 开启事务设置非自动提交
connection.setAutoCommit(false);
// 获得Statement对象
statement = connection.prepareStatement(sql);
// 设置参数
statement.setString(1, "zzf003");
statement.setInt(2, 18);
statement.setDate(3, new Date(System.currentTimeMillis()));
statement.setDate(4, new Date(System.currentTimeMillis()));
statement.setBoolean(5, false);
// 执行
statement.executeUpdate();
// 提交事务
connection.commit();
} finally {
// 释放资源
JDBCUtils.release(connection, statement, null);
}
}
使用例子-通过JNDI获取数据源
需求
本文测试使用 JNDI 获取HikariDataSource对象,选择使用tomcat 9.0.21作容器。
如果之前没有接触过 JNDI ,并不会影响下面例子的理解,其实可以理解为像 spring 的 bean 配置和获取。
引入依赖
本文在入门例子的基础上增加以下依赖,因为是 web 项目,所以打包方式为 war:
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet.jsp</groupId>
<artifactId>javax.servlet.jsp-api</artifactId>
<version>2.2.1</version>
<scope>provided</scope>
</dependency>
编写context.xml
在webapp文件下创建目录META-INF,并创建context.xml文件。这里面的每个 resource 节点都是我们配置的对象,类似于 spring 的 bean 节点。其中jdbc/hikariCP-test可以看成是这个 bean 的 id。
HikariCP 提供了HikariJNDIFactory来支持 JNDI 。
注意,这里获取的数据源对象是单例的,如果希望多例,可以设置singleton="false"。
<?xml version="1.0" encoding="UTF-8"?>
<Context>
<Resource
name="jdbc/hikariCP-test"
factory="com.zaxxer.hikari.HikariJNDIFactory"
auth="Container"
type="javax.sql.DataSource"
jdbcUrl="jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true"
username="root"
password="root"
driverClassName="com.mysql.cj.jdbc.Driver"
maximumPoolSize="10"
minimumIdle="0"
/>
</Context>
编写web.xml
在web-app节点下配置资源引用,每个resource-ref指向了我们配置好的对象。
<!-- JNDI数据源 -->
<resource-ref>
<res-ref-name>jdbc/hikariCP-test</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
编写jsp
因为需要在web环境中使用,如果直接建类写个main方法测试,会一直报错的,目前没找到好的办法。这里就简单地使用jsp来测试吧。
<body>
<%
String jndiName = "java:comp/env/jdbc/druid-test";
InitialContext ic = new InitialContext();
// 获取JNDI上的ComboPooledDataSource
DataSource ds = (DataSource) ic.lookup(jndiName);
JDBCUtils.setDataSource(ds);
// 创建sql
String sql = "select * from demo_user where deleted = false";
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
// 查询用户
try {
// 获得连接
connection = JDBCUtils.getConnection();
// 获得Statement对象
statement = connection.prepareStatement(sql);
// 执行
resultSet = statement.executeQuery();
// 遍历结果集
while(resultSet.next()) {
String name = resultSet.getString(2);
int age = resultSet.getInt(3);
System.err.println("用户名:" + name + ",年龄:" + age);
}
} catch(SQLException e) {
System.err.println("查询用户异常");
} finally {
// 释放资源
JDBCUtils.release(connection, statement, resultSet);
}
%>
</body>
测试结果
打包项目在tomcat9上运行,访问 http://localhost:8080/hikari-demo/testJNDI.jsp ,控制台打印如下内容:
用户名:zzs001,年龄:18
用户名:zzs002,年龄:18
用户名:zzs003,年龄:25
用户名:zzf001,年龄:26
用户名:zzf002,年龄:17
用户名:zzf003,年龄:18
使用例子-通过JMX管理连接池
需求
开启 HikariCP 的 JMX 功能,并使用 jconsole 查看。
修改hikari.properties
在例子一基础上增加如下配置。这要设置 registerMbeans 为 true,JMX 功能就会开启。
#-------------JMX--------------------------------
#是否允许通过JMX挂起和恢复连接池
#默认为false
allowPoolSuspension=false
#是否开启JMX
#默认false
registerMbeans=true
#数据源名,一般用于JMX。
#默认自动生成
poolName=zzs001
编写测试类
为了查看具体效果,这里让主线程进入睡眠,避免结束。
public static void main(String[] args) throws InterruptedException {
new HikariDataSourceTest().findAll();
Thread.sleep(60 * 60 * 1000);
}
使用jconsole查看
运行项目,打开 jconsole,选择我们的项目后点连接,在 MBean 选项卡可以看到我们的项目。通过 PoolConfig 可以动态修改配置(只有部分参数允许修改);通过 Pool 可以获取连接池的连接数(活跃、空闲和所有)、获取等待连接的线程数、挂起和恢复连接池、丢弃未使用连接等。
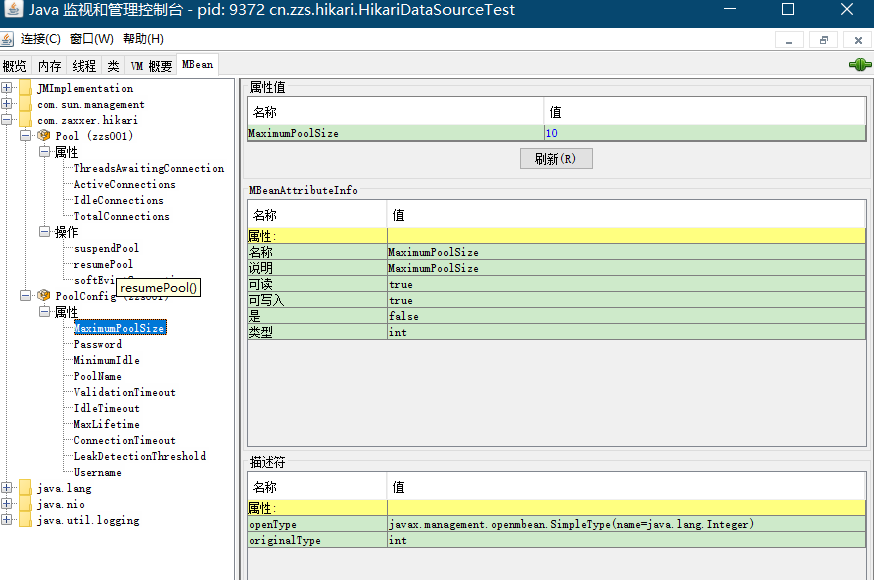
想了解更多 JMX 功能可以参考我的博客文章: 如何使用JMX来管理程序?
配置文件详解编写
相比其他连接池,HikariCP 的配置参数非常简单,其中有几个功能需要注意:HikariCP 强制开启借出测试和空闲测试,不开启回收测试,可选的只有泄露测试。
数据库连接参数
注意,这里在url后面拼接了多个参数用于避免乱码、时区报错问题。 补充下,如果不想加入时区的参数,可以在mysql命令窗口执行如下命令:set global time_zone='+8:00'。
#-------------基本属性--------------------------------
jdbcUrl=jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true
username=root
password=root
#JDBC驱动使用的Driver实现类类名
#默认为空。会根据jdbcUrl来解析
driverClassName=com.mysql.cj.jdbc.Driver
连接池数据基本参数
这两个参数都比较常用,建议根据具体项目调整。
#-------------连接池大小相关参数--------------------------------
#最大连接池数量
#默认为10。可通过JMX动态修改
maximumPoolSize=10
#最小空闲连接数量
#默认与maximumPoolSize一致。可通过JMX动态修改
minimumIdle=0
连接检查参数
针对连接失效的问题,HikariCP 强制开启借出测试和空闲测试,不开启回收测试,可选的只有泄露测试。
#-------------连接检测情况--------------------------------
#用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'
#如果驱动支持JDBC4,建议不设置,因为这时默认会调用Connection.isValid()方法来检测,该方式效率会更高
#默认为空
connectionTestQuery=select 1 from dual
#检测连接是否有效的超时时间,单位毫秒
#最小允许值250 ms
#默认5000 ms。可通过JMX动态修改
validationTimeout=5000
#连接保持空闲而不被驱逐的最小时间。单位毫秒。
#该配置只有再minimumIdle < maximumPoolSize才会生效,最小允许值为10000 ms。
#默认值10000*60 = 10分钟。可通过JMX动态修改
idleTimeout=600000
#连接对象允许“泄露”的最大时间。单位毫秒
#最小允许值为2000 ms。
#默认0,表示不开启泄露检测。可通过JMX动态修改
leakDetectionThreshold=0
#连接最大存活时间。单位毫秒
#最小允许值30000 ms
#默认30分钟。可通过JMX动态修改
maxLifetime=1800000
#获取连接时最大等待时间,单位毫秒
#获取时间超过该配置,将抛出异常。最小允许值250 ms
#默认30000 ms。可通过JMX动态修改
connectionTimeout=300000
#在启动连接池前获取连接的超时时间,单位毫秒
#>0时,会尝试获取连接。如果获取时间超过指定时长,不会开启连接池,并抛出异常
#=0时,会尝试获取并验证连接。如果获取成功但验证失败则不开启池,但是如果获取失败还是会开启池
#<0时,不管是否获取或校验成功都会开启池。
#默认为1
initializationFailTimeout=1
事务相关参数
建议保留默认就行。
#-------------事务相关的属性--------------------------------
#当连接返回池中时是否设置自动提交
#默认为true
autoCommit=true
#当连接从池中取出时是否设置为只读
#默认值false
readOnly=false
#连接池创建的连接的默认的TransactionIsolation状态
#可用值为下列之一:NONE,TRANSACTION_READ_UNCOMMITTED, TRANSACTION_READ_COMMITTED, TRANSACTION_REPEATABLE_READ, TRANSACTION_SERIALIZABLE
#默认值为空,由驱动决定
transactionIsolation=TRANSACTION_REPEATABLE_READ
#是否在事务中隔离内部查询。
#autoCommit为false时才生效
#默认false
isolateInternalQueries=false
JMX参数
建议不开启 allowPoolSuspension,对性能影响较大,后面源码分析会解释原因。
#-------------JMX--------------------------------
#是否允许通过JMX挂起和恢复连接池
#默认为false
allowPoolSuspension=false
#是否开启JMX
#默认false
registerMbeans=true
#数据源名,一般用于JMX。
#默认自动生成
poolName=zzs001
其他
注意,这里的 dataSourceJndiName 不是前面例子中的 jdbc/hikariCP-test,这个数据源是用来创建原生连接对象的,一般用不到。
#-------------其他--------------------------------
#数据库目录
#默认由驱动决定
catalog=github_demo
#由JDBC驱动提供的数据源类名
#不支持XA数据源。如果不设置,默认会采用DriverManager来获取连接对象
#注意,如果设置了driverClassName,则不允许再设置dataSourceClassName,否则会报错
#默认为空
#dataSourceClassName=
#JNDI配置的数据源名
#默认为空
#dataSourceJndiName=
#在每个连接获取后、放入池前,需要执行的初始化语句
#如果执行失败,该连接会被丢弃
#默认为空
#connectionInitSql=
#-------------以下参数仅支持通过IOC容器或代码配置的方式--------------------------------
#TODO
#默认为空
#metricRegistry
#TODO
#默认为空
#healthCheckRegistry
#用于Hikari包装的数据源实例
#默认为空
#dataSource
#用于创建线程的工厂
#默认为空
#threadFactory=
#用于执行定时任务的线程池
#默认为空
#scheduledExecutor=
源码分析
HikariCP 的源码轻巧且简单,读起来不会太吃力,所以,这次不会从头到尾地分析代码逻辑,更多地会分析一些设计巧妙的地方。
在阅读 HiakriCP 源码之前,需要掌握:CopyOnWriteArrayList、AtomicInteger、SynchronousQueue、Semaphore、AtomicIntegerFieldUpdater等工具。
注意:考虑篇幅和可读性,以下代码经过删减,仅保留所需部分 。
HikariCP为什么快?
结合源码分析以及参考资料,相比 DBCP 和 C3P0 等连接池,HikariCP 快主要有以下几个原因:
- 通过代码设计和优化大幅减少线程间的锁竞争。这一点主要通过
ConcurrentBag来实现,下文会展开。 - 引入了更多 JDK 的特性,尤其是 concurrent 包的工具。DBCP 和 C3P0 出现时间较早,基于早期的 JDK 进行开发,也就很难享受到后面更新带来的福利;
- 使用 javassist 直接修改 class 文件生成动态代理,精简了很多不必要的字节码,提高代理方法运行速度。相比 JDK 和 cglib 的动态代理,通过 javassist 直接修改 class 文件生成的代理类在运行上会更快一些(这是网上找到的说法,但是目前 JDK 和 cglib 已经经过了多次优化,在代理类的运行速度上应该不会差一个数量级,我抽空再测试下吧)。HikariCP 涉及 javassist 的代码在
JavassistProxyFactory类中,相关内容请自行查阅; - 重视代码细节对性能的影响。下文到的 fastPathPool 就是一个例子,仔细琢磨 HikariCP 的代码就会发现许多类似的细节优化,除此之外还有 FastList 等自定义集合类;
接下来,本文将在分析源码的过程中对以上几点展开讨论。
HikariCP的架构
在分析具体代码之前,这里先介绍下 HikariCP 的整体架构,和 DBCP2 的有点类似(可见 HikariCP 与 DBCP2 性能差异并不是由于架构设计)。
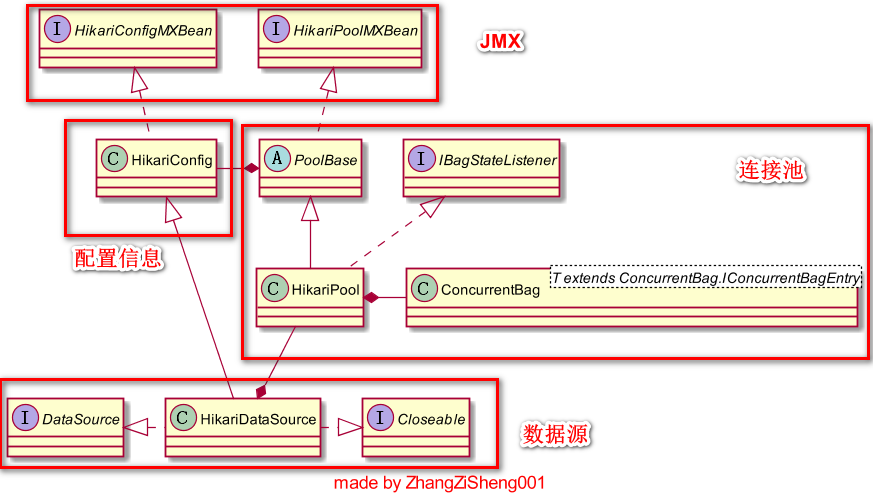
我们和 HikariCP 打交道,一般通过以下几个入口:
通过 JMX 调用
HikariConfigMXBean来动态修改配置(只有部分参数允许修改,在配置详解里有注明);通过 JMX 调用
HikariPoolMXBean来获取连接池的连接数(活跃、空闲和所有)、获取等待连接的线程数、挂起和恢复连接池、丢弃未使用连接等;使用
HikariConfig加载配置文件,或手动配置HikariConfig的参数,一般它会作为入参来构造HikariDataSource对象;使用
HikariDataSource获取和丢弃连接对象,另外,因为继承了HikariConfig,我们也可以通过HikariDataSource来配置参数,但这种方式不支持配置文件。
为什么HikariDataSource持有HikariPool的两个引用
在图中可以看到,HikariDataSource持有了HikariPool的引用,看过源码的同学可能会问,为什么属性里会有两个HikariPool,如下:
public class HikariDataSource extends HikariConfig implements DataSource, Closeable
{
private final HikariPool fastPathPool;
private volatile HikariPool pool;
}
这里补充说明下,其实这里的两个HikariPool的不同取值代表了不同的配置方式:
配置方式一:当通过有参构造new HikariDataSource(HikariConfig configuration)来创建HikariDataSource时,fastPathPool 和 pool 是非空且相同的;
配置方式二:当通过无参构造new HikariDataSource()来创建HikariDataSource并手动配置时,fastPathPool 为空,pool 不为空(在第一次 getConnectionI() 时初始化),如下;
public Connection getConnection() throws SQLException
{
if (isClosed()) {
throw new SQLException("HikariDataSource " + this + " has been closed.");
}
if (fastPathPool != null) {
return fastPathPool.getConnection();
}
// 第二种配置方式会在第一次 getConnectionI() 时初始化pool
HikariPool result = pool;
if (result == null) {
synchronized (this) {
result = pool;
if (result == null) {
validate();
LOGGER.info("{} - Starting...", getPoolName());
try {
pool = result = new HikariPool(this);
}
catch (PoolInitializationException pie) {
if (pie.getCause() instanceof SQLException) {
throw (SQLException) pie.getCause();
}
else {
throw pie;
}
}
LOGGER.info("{} - Start completed.", getPoolName());
}
}
}
return result.getConnection();
}
针对以上两种配置方式,其实使用一个 pool 就可以完成,那为什么会有两个?我们比较下这两种方式的区别:
private final T t1;
private volatile T t2;
public void method01(){
if (t1 != null) {
// do something
}
}
public void method02(){
T result = t2;
if (result != null) {
// do something
}
}
上面的两个方法中,执行的代码几乎一样,但是 method02 在性能上会比 method01 稍差。当然,主要问题不是出在 method02 多定义了一个变量,而在于 t2 的 volatile 性质,正因为 t2 被 volatile 修饰,为了实现数据一致性会出现不必要的开销,所以 method02 在性能上会比 method01 稍差。pool 和 fastPathPool 的问题也是同理,所以,第二种配置方式不建议使用。
通过上面的问题就会发现,HiakriCP 在追求性能方面非常重视细节,怪不得能够成为最快的连接池!
HikariPool--管理连接的池塘
HikariPool 是一个非常重要的类,它负责管理连接,涉及到比较多的代码逻辑。这里先简单介绍下这个类,对下文代码的具体分析会有所帮助。
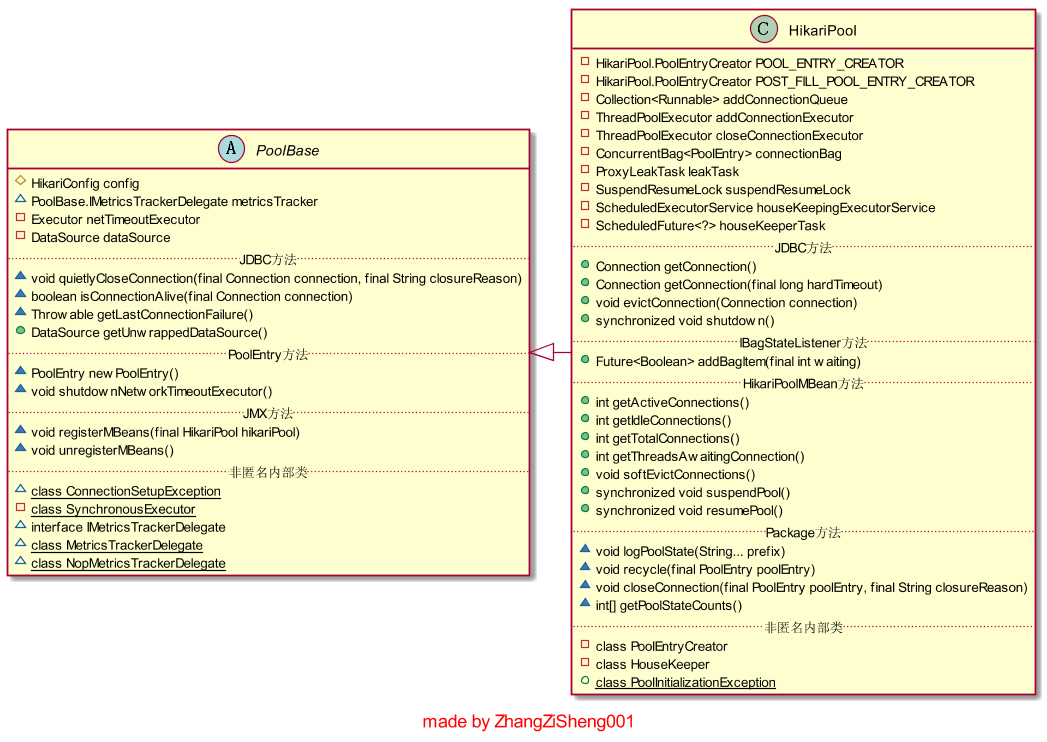
HikariPool 的几个属性说明如下:
| 属性类型和属性名 | 说明 |
|---|---|
| HikariConfig config | 配置信息。 |
| PoolBase.IMetricsTrackerDelegate metricsTracker | 指标记录器包装类。HikariCP支持Metrics监控,但需要额外引入jar包,本文不会涉及这一部分内容 |
| Executor netTimeoutExecutor | 用于执行设置连接超时时间的任务。如果是mysql驱动,实现为PoolBase.SynchronousExecutor,如果是其他驱动,实现为ThreadPoolExecutor,为什么mysql不同,原因见: https://bugs.mysql.com/bug.php?id=75615 |
| DataSource dataSource | 用于获取原生连接对象的数据源。一般我们不指定的话,使用的是DriverDataSource |
| HikariPool.PoolEntryCreator POOL_ENTRY_CREATOR | 创建新连接的任务,Callable实现类。一般调用一次创建一个连接 |
| HikariPool.PoolEntryCreator POST_FILL_POOL_ENTRY_CREATOR | 创建新连接的任务,Callable实现类。一般调用一次创建一个连接,与前者区别在于它创建最后一个连接,会打印日志 |
| Collection<![CDATA[]> addConnectionQueue | 等待执行PoolEntryCreator任务的队列 |
| ThreadPoolExecutor addConnectionExecutor | 执行PoolEntryCreator任务的线程池。以addConnectionQueue作为等待队列,只开启一个线程执行任务。 |
| ThreadPoolExecutor closeConnectionExecutor | 执行关闭原生连接的线程池。只开启一个线程执行任务。 |
| ConcurrentBag<![CDATA[]> connectionBag | 存放连接对象的包。用于borrow、requite、add和remove对象。 |
| ProxyLeakTask leakTask | 报告连接丢弃的任务,Runnable实现类。 |
| SuspendResumeLock suspendResumeLock | 基于Semaphore包装的锁。如果设置了isAllowPoolSuspension则会生效,默认MAX_PERMITS = 10000 |
| ScheduledExecutorService houseKeepingExecutorService | 用于执行HouseKeeper(连接检测任务和维持连接池大小)和ProxyLeakTask的任务。只开启一个线程执行任务。 |
| ScheduledFuture<?> houseKeeperTask | houseKeepingExecutorService执行HouseKeeper(检测空闲连接任务)返回的结果,通过它可以结束HouseKeeper任务。 |
为了更清晰地理解上面几个字段的含义,我简单画了个图,不是很严谨,将就看下吧。在这个图中,PoolEntry 封装了 Connection 对象,在图中把它看成是连接对象会更好理解一些。我们可以看到ConcurrentBag 是整个 HikariPool 的核心,其他对象都围绕着它进行操作,后面会单独讲解这个类。客户端线程可以调用它的 borrow、requite 和 remove 方法,houseKeepingExecutorService 线程可以调用它的 remove 方法,只有 addConnectionExecutor 可以进行 add 操作。
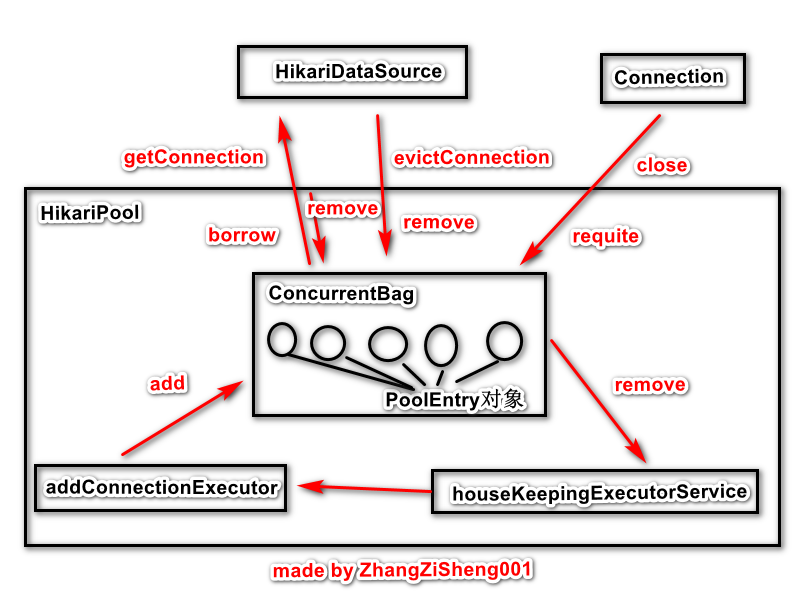
borrow 和 requite 对于 ConcurrentBag 而言是只读的操作,addConnectionExecutor 只开启一个线程执行任务,所以 add 操作是单线程的,唯一存在锁竞争的就是 remove 方法。接下来会具体讲解 ConcurrentBag。
ConcurrentBag--更少的锁冲突
在 HikariCP 中ConcurrentBag用于存放PoolEntry对象(封装了Connection对象,IConcurrentBagEntry实现类),本质上可以将它就是一个资源池。

下面简单介绍下几个字段的作用:
| 属性 | 描述 |
|---|---|
| CopyOnWriteArrayList<![CDATA[]> sharedList | 存放着状态为使用中、未使用和保留三种状态的PoolEntry对象。注意,CopyOnWriteArrayList是一个线程安全的集合,在每次写操作时都会采用复制数组的方式来增删元素,读和写使用的是不同的数组,避免了锁竞争。 |
| ThreadLocal<List<![CDATA[]>> threadList | 存放着当前线程返还的PoolEntry对象。如果当前线程再次借用资源,会先从这个列表中获取。注意,这个列表的元素可以被其他线程“偷走”。 |
| SynchronousQueue<![CDATA[]> handoffQueue | 这是一个无容量的阻塞队列,每个插入操作需要阻塞等待删除操作,而删除操作不需要等待,如果没有元素插入,会返回null,如果设置了超时时间则需要等待。 |
| AtomicInteger waiters | 当前等待获取元素的线程数 |
| IBagStateListener listener | 添加元素的监听器,由HikariPool实现,在该实现中,如果waiting - addConnectionQueue.size() >= 0,则会让addConnectionExecutor执行PoolEntryCreator任务 |
| boolean weakThreadLocals | 元素是否使用弱引用。可以通过系统属性com.zaxxer.hikari.useWeakReferences进行设置 |
这几个字段在ConcurrentBag中如何使用呢,我们来看看borrow的方法:
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// 1. 首先从threadList获取对象
// 获取绑定在当前线程的List<Object>对象,注意这个集合的实现一般为FastList,这是HikariCP自己实现的,后面会讲到
final List<Object> list = threadList.get();
// 遍历结合
for (int i = list.size() - 1; i >= 0; i--) {
// 获取当前元素,并将它从集合中删除
final Object entry = list.remove(i);
// 如果设置了weakThreadLocals,则存放的是WeakReference对象,否则为我们一开始设置的PoolEntry对象
@SuppressWarnings("unchecked")
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry;
// 采用CAS方式将获取的对象状态由未使用改为使用中,如果失败说明其他线程正在使用它,这里可知,threadList上的元素可以被其他线程“偷走”。
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
// 2.如果还没获取到,会从sharedList中获取对象
// 等待获取连接的线程数+1
final int waiting = waiters.incrementAndGet();
try {
// 遍历sharedList
for (T bagEntry : sharedList) {
// 采用CAS方式将获取的对象状态由未使用改为使用中,如果当前元素正在使用,则无法修改成功,进入下一循环
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
// 通知监听器添加包元素。如果waiting - addConnectionQueue.size() >= 0,则会让addConnectionExecutor执行PoolEntryCreator任务
if (waiting > 1) {
listener.addBagItem(waiting - 1);
}
return bagEntry;
}
}
// 通知监听器添加包元素。
listener.addBagItem(waiting);
// 3.如果还没获取到,会从轮训进入handoffQueue队列获取连接对象
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
// 从handoffQueue队列中获取并删除元素。这是一个无容量的阻塞队列,插入操作需要阻塞等待删除操作,而删除操作不需要等待,如果没有元素插入,会返回null,如果设置了超时时间则需要等待
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
// 这里会出现三种情况,
// 1.超时,返回null
// 2.获取到元素,但状态为正在使用,继续执行
// 3.获取到元素,元素状态未未使用,修改未使用并返回
if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
// 计算剩余超时时间
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
// 超时返回null
return null;
}
finally {
// 等待获取连接的线程数-1
waiters.decrementAndGet();
}
}
在以上方法中,唯一可能出现线程切换到就是handoffQueue.poll(timeout, NANOSECONDS),除此之外,我们没有看到任何的 synchronized 和 lock。之所以可以做到这样主要由于以下几点:
- 元素状态的引入,以及使用CAS方法修改状态。在
ConcurrentBag中,使用使用中、未使用、删除和保留等表示元素的状态,而不是使用不同的集合来维护不同状态的元素。元素状态这一概念的引入非常关键,为后面的几点提供了基础。ConcurrentBag的方法中多处调用 CAS 方法来判断和修改元素状态,这一过程不需要加锁。 - threadList 的使用。当前线程归还的元素会被绑定到
ThreadLocal,该线程再次获取元素时,在该元素未被偷走的前提下可直接获取到,不需要去 sharedList 遍历获取; - 采用
CopyOnWriteArrayList来存放元素。在CopyOnWriteArrayList中,读和写使用的是不同的数组,避免了两者的锁竞争,至于多个线程写入,则会加ReentrantLock锁。 - sharedList 的读写控制。borrow 和 requite 对 sharedList 来说都是不加锁的,缺点就是会牺牲一致性。用户线程无法进行增加元素的操作,只有 addConnectionExecutor 可以,而 addConnectionExecutor 只会开启一个线程执行任务,所以 add 操作不会存在锁竞争。至于 remove 是唯一会造成锁竞争的方法,这一点我认为也可以参照 addConnectionExecutor 来处理,在加入任务队列前把
PoolEntry的状态标记为删除中。
其实,我们会发现,ConcurrentBag在减少锁冲突的问题上,除了设计改进,还使用了比较多的 JDK 特性。
如何加载配置
在HikariCP 中,HikariConfig用于加载配置,具体的代码并不复杂,但相比其他项目,它的加载要更加简洁一些。我们直接从PropertyElf.setTargetFromProperties(Object, Properties)方法开始看,如下:
// 这个方法就是将properties的参数设置到HikariConfig中
public static void setTargetFromProperties(final Object target, final Properties properties)
{
if (target == null || properties == null) {
return;
}
// 在这里会利用反射获取
List<Method> methods = Arrays.asList(target.getClass().getMethods());
// 遍历
properties.forEach((key, value) -> {
// 如果是dataSource.*的参数,直接加入到dataSourceProperties属性
if (target instanceof HikariConfig && key.toString().startsWith("dataSource.")) {
((HikariConfig) target).addDataSourceProperty(key.toString().substring("dataSource.".length()), value);
}
else {
// 如果不是,则通过set方法设置
setProperty(target, key.toString(), value, methods);
}
});
}
进入到PropertyElf.setProperty(Object, String, Object, List<Method>)方法:
private static void setProperty(final Object target, final String propName, final Object propValue, final List<Method> methods)
{
// 拼接参数的setter方法名
String methodName = "set" + propName.substring(0, 1).toUpperCase(Locale.ENGLISH) + propName.substring(1);
// 获取对应的Method 对象
Method writeMethod = methods.stream().filter(m -> m.getName().equals(methodName) && m.getParameterCount() == 1).findFirst().orElse(null);
// 如果不存在,按另一套规则拼接参数的setter方法名
if (writeMethod == null) {
String methodName2 = "set" + propName.toUpperCase(Locale.ENGLISH);
writeMethod = methods.stream().filter(m -> m.getName().equals(methodName2) && m.getParameterCount() == 1).findFirst().orElse(null);
}
// 如果该参数setter方法不存在,则抛出异常,从这里可以看出,HikariCP 中不能存在配错参数名的情况
if (writeMethod == null) {
LOGGER.error("Property {} does not exist on target {}", propName, target.getClass());
throw new RuntimeException(String.format("Property %s does not exist on target %s", propName, target.getClass()));
}
// 接下来就是调用setter方法来配置具体参数了。
try {
Class<?> paramClass = writeMethod.getParameterTypes()[0];
if (paramClass == int.class) {
writeMethod.invoke(target, Integer.parseInt(propValue.toString()));
}
else if (paramClass == long.class) {
writeMethod.invoke(target, Long.parseLong(propValue.toString()));
}
else if (paramClass == boolean.class || paramClass == Boolean.class) {
writeMethod.invoke(target, Boolean.parseBoolean(propValue.toString()));
}
else if (paramClass == String.class) {
writeMethod.invoke(target, propValue.toString());
}
else {
writeMethod.invoke(target, propValue);
}
}
catch (Exception e) {
LOGGER.error("Failed to set property {} on target {}", propName, target.getClass(), e);
throw new RuntimeException(e);
}
}
我们会发现,相比其他项目(尤其是 druid),HikariCP 加载配置的过程非常简洁,不需要按照参数名一个个地加载,这样后期会更好维护。当然,这种方式我们也可以运用到实际项目中。
获取一个连接对象的过程
现在简单介绍下获取连接对象的过程,我们进入到HikariPool.getConnection(long)方法:
public Connection getConnection(final long hardTimeout) throws SQLException
{ // 如果我们设置了allowPoolSuspension为true,则这个锁会生效
// 它采用Semaphore实现,MAX_PERMITS = 10000,正常情况不会用完,除非你挂起了连接池(通过JMX等方式),这时10000个permits会一次被消耗完
suspendResumeLock.acquire();
// 获取开始时间
final long startTime = currentTime();
try {
// 剩余超时时间
long timeout = hardTimeout;
PoolEntry poolEntry = null;
try {
// 循环获取,除非获取到了连接或者超时
do {
// 从ConcurrentBag中借出一个元素
poolEntry = connectionBag.borrow(timeout, MILLISECONDS);
// 前面说过,只有超时情况才会返回空,这时会跳出循环并抛出异常
if (poolEntry == null) {
break;
}
final long now = currentTime();
// 如果元素被标记为丢弃或者空闲时间过长且连接无效则会丢弃该元素,并关闭连接
if (poolEntry.isMarkedEvicted() || (elapsedMillis(poolEntry.lastAccessed, now) > ALIVE_BYPASS_WINDOW_MS && !isConnectionAlive(poolEntry.connection))) {
closeConnection(poolEntry, "(connection is evicted or dead)"); // Throw away the dead connection (passed max age or failed alive test)
// 计算剩余超时时间
timeout = hardTimeout - elapsedMillis(startTime);
}
else {
// 这一步用于支持metrics监控,本文不涉及
metricsTracker.recordBorrowStats(poolEntry, startTime);
// 创建Connection代理类,该代理类就是使用Javassist生成的
return poolEntry.createProxyConnection(leakTask.schedule(poolEntry), now);
}
} while (timeout > 0L);
// 不涉及
metricsTracker.recordBorrowTimeoutStats(startTime);
}
catch (InterruptedException e) {
// 获取连接过程如果中断,则回收连接并抛出异常
if (poolEntry != null) {
poolEntry.recycle(startTime);
}
Thread.currentThread().interrupt();
throw new SQLException(poolName + " - Interrupted during connection acquisition", e);
}
}
finally {
// 释放一个permit
suspendResumeLock.release();
}
// 抛出超时异常
throw createTimeoutException(startTime);
}
以上就是获取连接对象的过程,没有太复杂的逻辑。这里需要注意,使用 HikariCP 最好不要开启 allowPoolSuspension ,否则每次连接都会有获取和释放 permit 的过程。另外,HikariCP 默认 testOnBorrow,有点难以理解。
以上,HikariCP 的使用例子和源码分析基本讲完,后续有空再做补充。
参考资料
微信公众号【工匠小猪猪的技术世界】的追光者系列文章
本文为原创文章,转载请附上原文出处链接: https://www.cnblogs.com/ZhangZiSheng001/p/12329937.html
源码详解系列(八) ------ 全面讲解HikariCP的使用和源码的更多相关文章
- 源码详解系列(七) ------ 全面讲解logback的使用和源码
什么是logback logback 用于日志记录,可以将日志输出到控制台.文件.数据库和邮件等,相比其它所有的日志系统,logback 更快并且更小,包含了许多独特并且有用的特性. logback ...
- 源码详解系列(六) ------ 全面讲解druid的使用和源码
简介 druid是用于创建和管理连接,利用"池"的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制.连接可靠性测试.连接泄露控制.缓存语句等功能,另外,druid还扩展 ...
- Mybatis源码详解系列(四)--你不知道的Mybatis用法和细节
简介 这是 Mybatis 系列博客的第四篇,我本来打算详细讲解 mybatis 的配置.映射器.动态 sql 等,但Mybatis官方中文文档对这部分内容的介绍已经足够详细了,有需要的可以直接参考. ...
- Java源码详解系列(十)--全面分析mybatis的使用、源码和代码生成器(总计5篇博客)
简介 Mybatis 是一个持久层框架,它对 JDBC 进行了高级封装,使我们的代码中不会出现任何的 JDBC 代码,另外,它还通过 xml 或注解的方式将 sql 从 DAO/Repository ...
- Java源码详解系列(十二)--Eureka的使用和源码
eureka 是由 Netflix 团队开发的针对中间层服务的负载均衡器,在微服务项目中被广泛使用.相比 SLB.ALB 等负载均衡器,eureka 的服务注册是无状态的,扩展起来非常方便. 在这个系 ...
- 源码详解系列(五) ------ C3P0的使用和分析(包括JNDI)
简介 c3p0是用于创建和管理连接,利用"池"的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制.连接可靠性测试.连接泄露控制.缓存语句等功能.目前,hibernate ...
- 套用GGTalk做项目的经验总结——GGTalk源码详解系列(一)
坦白讲,我们公司其实没啥技术实力,之所以还能不断接到各种项目,全凭我们老板神通广大!要知道他每次的饭局上可都是些什么人物! 但是项目接下一大把,就凭咱哥儿几个的水平,想要独立自主.保质保量保期地一个个 ...
- Mybatis源码详解系列(三)--从Mapper接口开始看Mybatis的执行逻辑
简介 Mybatis 是一个持久层框架,它对 JDBC 进行了高级封装,使我们的代码中不会出现任何的 JDBC 代码,另外,它还通过 xml 或注解的方式将 sql 从 DAO/Repository ...
- Java源码详解系列(十一)--Spring的使用和源码
Spring 是一个一站式的 Java 框架,致力于提高我们项目开发的效率.通过 Spring,我们可以避免编写大量额外代码,更专注于我们的核心逻辑.目前,Spring 已经成为最受欢迎的 Java ...
随机推荐
- BitSet 的使用
BitSet 的简单介绍 BitSet,即位图,是位操作的对象,值只有 0 或 1(即 false 或 true). Java 的 BitSet 内部维护着一个 long 数组,默认初始化时数组的长度 ...
- ES 服务器 索引、类型仓库基类 BaseESStorage
/******************************************************* * * 作者:朱皖苏 * 创建日期:20180508 * 说明:此文件只包含一个类,具 ...
- 图解kubernetes调度器预选设计实现学习
Scheduler中在进行node选举的时候会首先进行一轮预选流程,即从当前集群中选择一批node节点,本文主要分析k8s在预选流程上一些优秀的筛选设计思想,欢迎大佬们指正 1. 基础设计 1.1 预 ...
- 构造分组背包(CF)
Ivan is a student at Berland State University (BSU). There are n days in Berland week, and each of t ...
- RSA 的加密 解密
RSA加密解密类: package me.hao0.trace.order; import java.io.BufferedReader; import java.io.BufferedWriter; ...
- SpringCloud组件和概念介绍(一)
一:什么是微服务(Microservice) 微服务英文名称Microservice,Microservice架构模式就是将整个Web应用组织为一系列小的Web服务.这些小的Web服务可以独立地编译及 ...
- 鉴于崔庆才大大的对于 beautifulsoup 的再理解
源地址看 soups = BeautifulSoup(html) soup = BeautifulSoup(open('index.html')) print soup.prettify() Tag通 ...
- EFK教程(5) - ES集群开启用户认证
基于ES内置及自定义用户实现kibana和filebeat的认证 作者:"发颠的小狼",欢迎转载 目录 ▪ 用途 ▪ 关闭服务 ▪ elasticsearch-修改elastics ...
- Hystrix 监控数据聚合 Turbine【Finchley 版】
原文地址:https://windmt.com/2018/04/17/spring-cloud-6-turbine/ 上一篇我们介绍了使用 Hystrix Dashboard 来展示 Hystrix ...
- 最短路径-Dijkstra+Floyd+Spfa
Dijkstra算法: Dijkstra(迪杰斯特拉)算法是典型的单源最短路径算法,用于计算一个节点到其他所有节点的最短路径.主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止.Dijkstra ...