sparkStreaming的transformation和action详解
- Transformations
- Window Operations
- Join Operations
- Output Operations
一、Transformations
|
1
|
val b = a.map(func) |
|
1
|
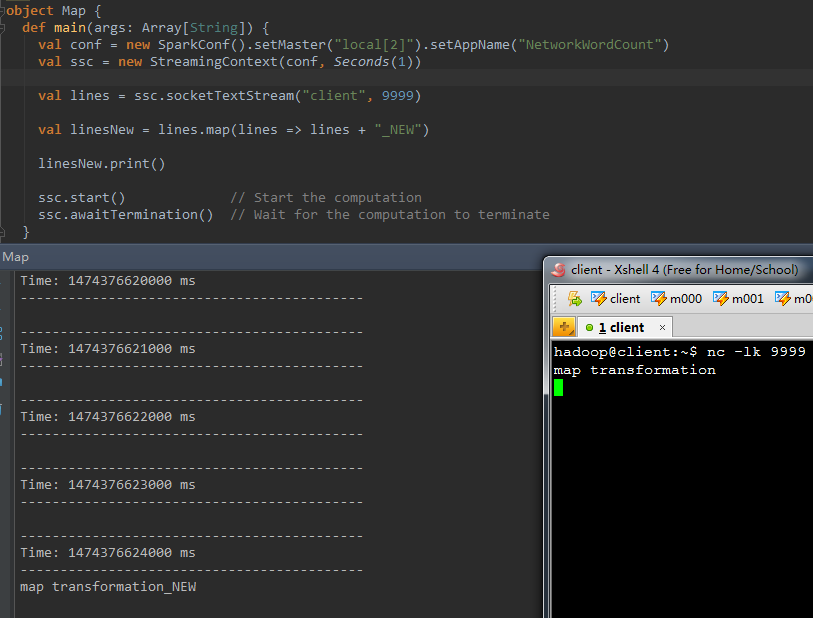
val linesNew = lines.map(lines => lines + "_NEW" ) |
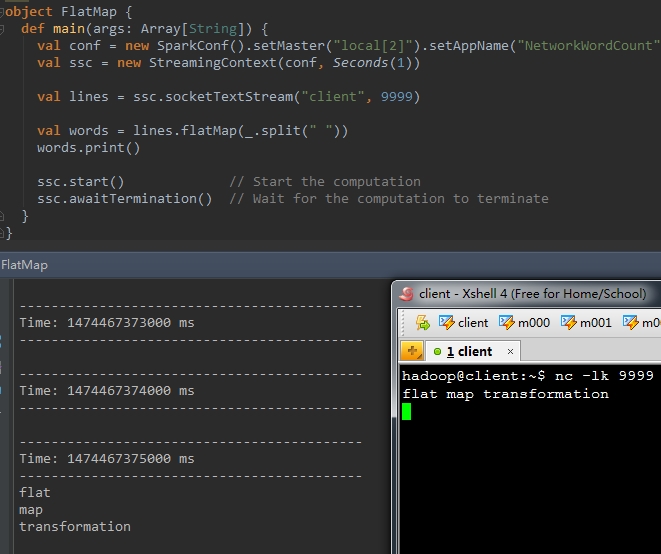
2、flatMap(func)
|
1
|
val b = a.flatMap(func) |
|
1
|
val words = lines.flatMap(_.split( " " )) |
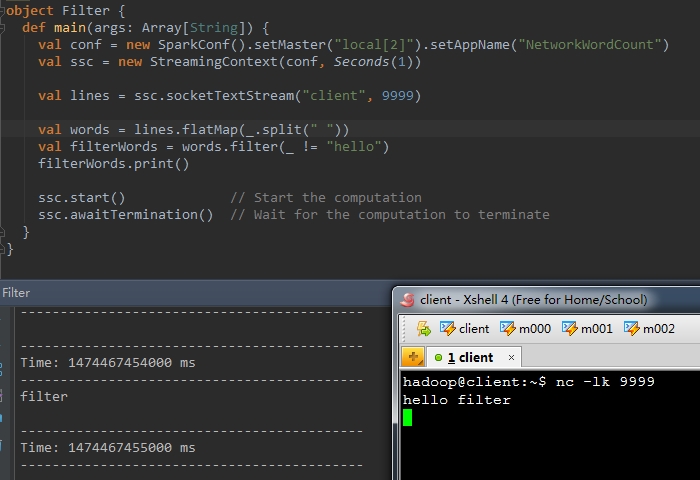
3、 filter(func)
|
1
|
val b = a.filter(func) |
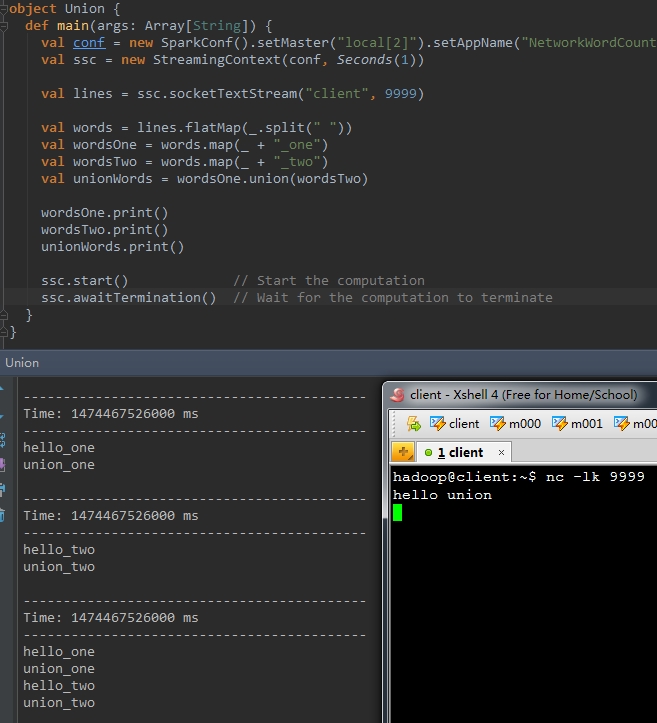
4、union(otherStream)
|
1
2
3
4
5
6
7
|
val wordsOne = words.map(_ + "_one" )val wordsTwo = words.map(_ + "_two" )val unionWords = wordsOne.union(wordsTwo)wordsOne.print()wordsTwo.print()unionWords.print() |
5、count()
|
1
|
val wordsCount = words.count() |
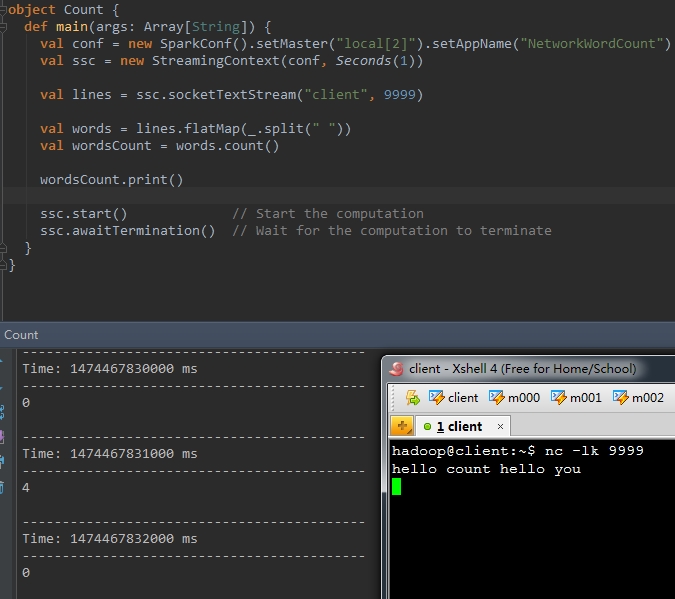
6、reduce(func)
|
1
|
val reduceWords = words.reduce(_ + "-" + _) |
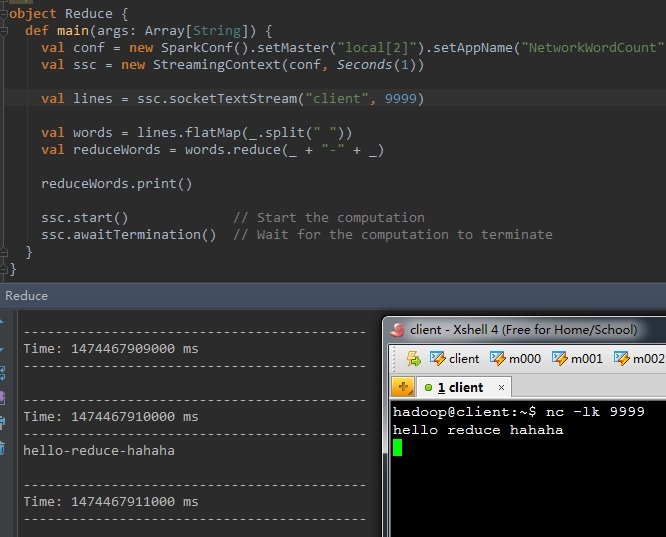
7、countByValue()
|
1
|
val countByValueWords = words.countByValue() |
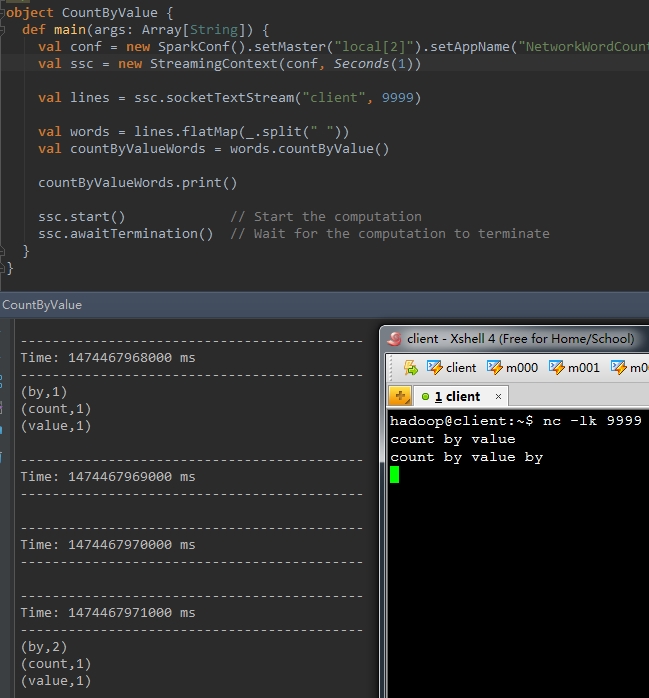
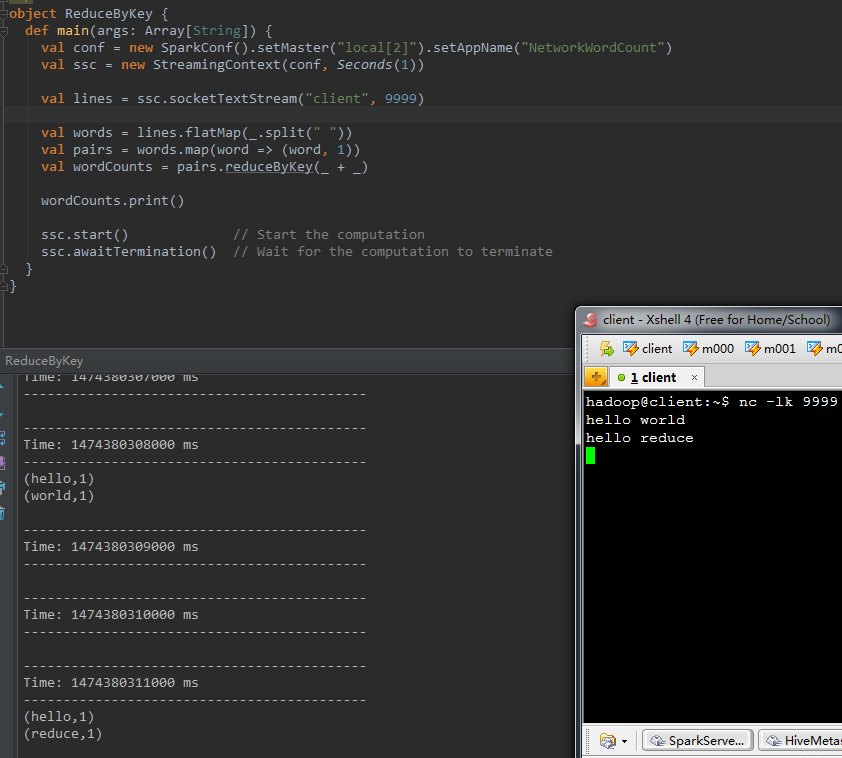
8、reduceByKey(func, [numTasks])
|
1
2
|
val pairs = words.map(word => (word , 1))val wordCounts = pairs.reduceByKey(_ + _) |
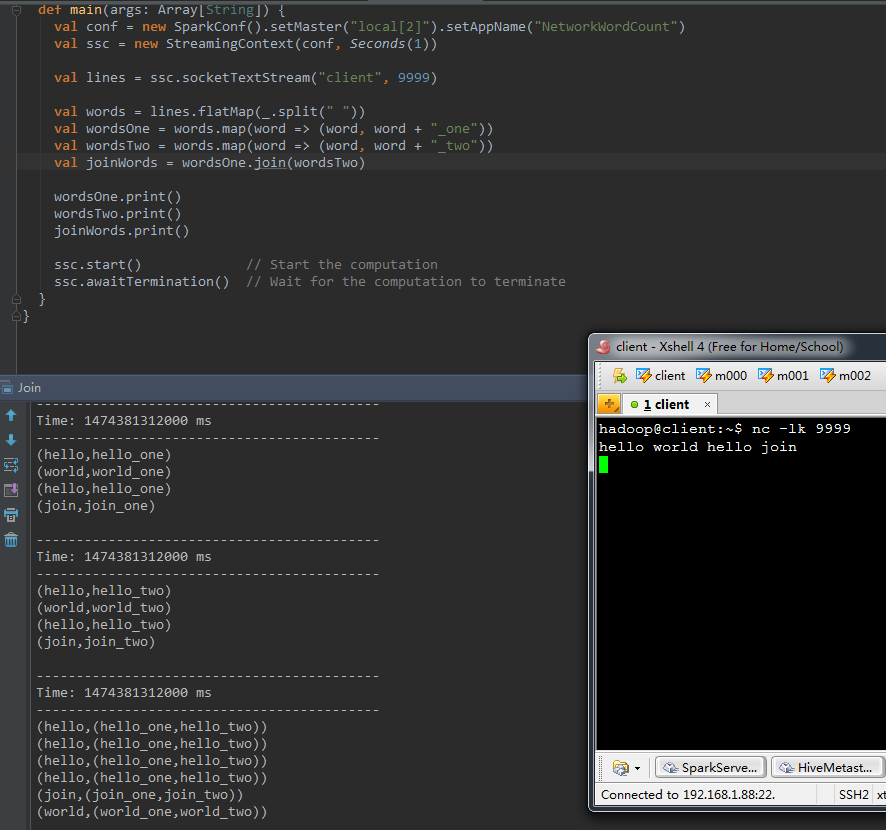
9、join(otherStream, [numTasks])
|
1
2
3
|
val wordsOne = words.map(word => (word , word + "_one" ))val wordsTwo = words.map(word => (word , word + "_two" ))val joinWords = wordsOne.join(wordsTwo) |
10、cogroup(otherStream, [numTasks])

11、transform(func)
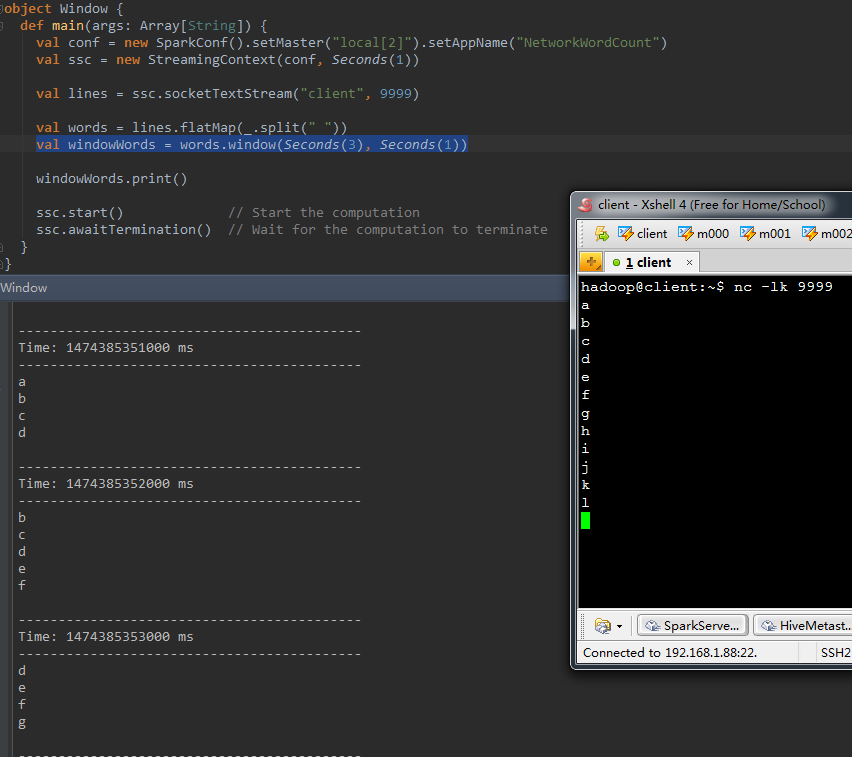
1、window(windowLength, slideInterval)
|
1
|
val windowWords = words.window(Seconds( 3 ), Seconds( 1)) |
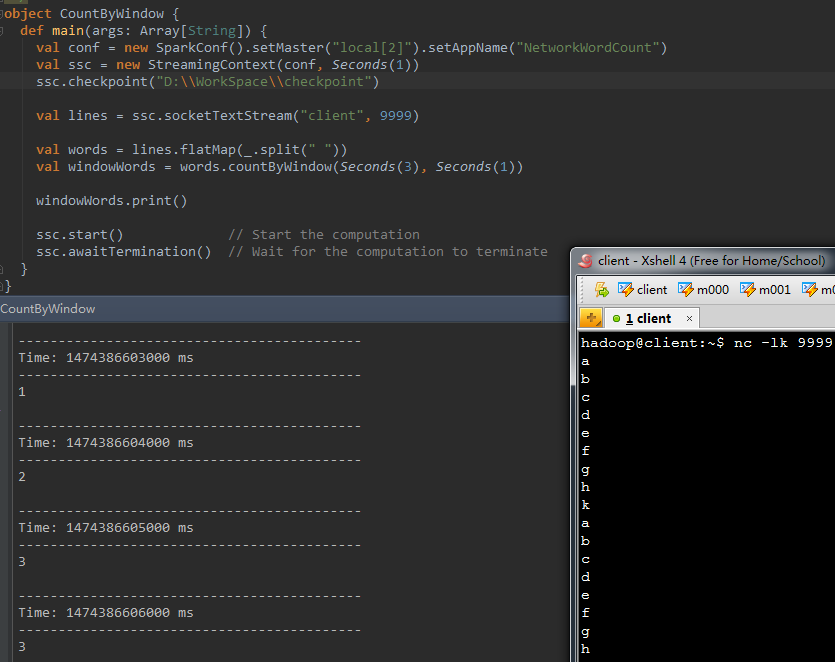
2、 countByWindow(windowLength,slideInterval)
|
1
|
val windowWords = words.countByWindow(Seconds( 3 ), Seconds( 1)) |
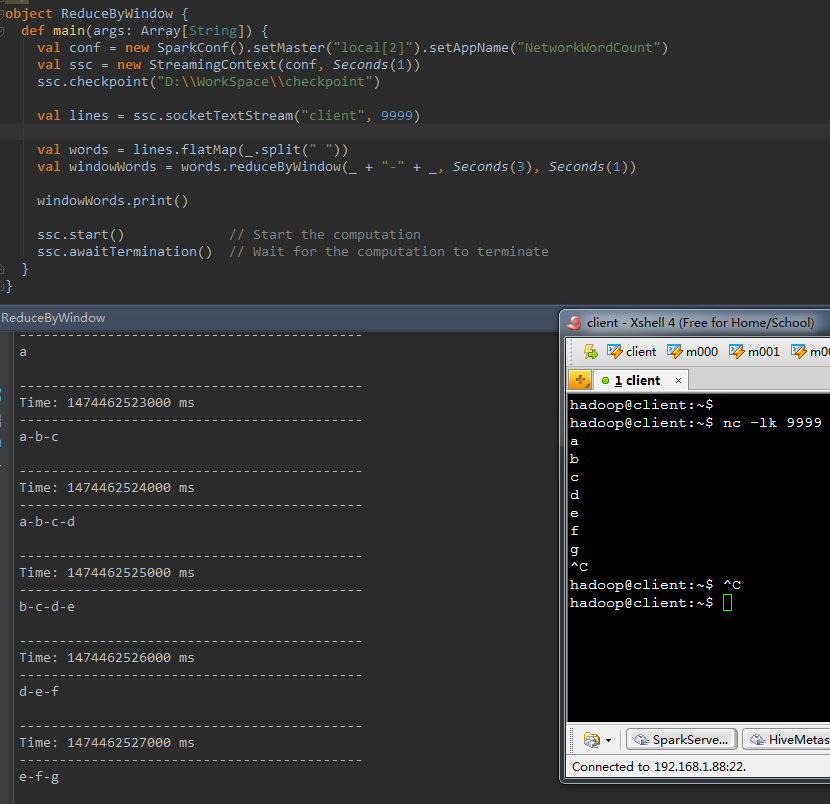
3、 reduceByWindow(func, windowLength,slideInterval)
|
1
|
val windowWords = words.reduceByWindow(_ + "-" + _, Seconds( 3) , Seconds( 1 )) |
4、 reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks])
|
1
|
val windowWords = pairs.reduceByKeyAndWindow((a:Int , b:Int) => (a + b) , Seconds(3 ) , Seconds( 1 )) |

5、 reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks])
|
1
|
val windowWords = pairs.reduceByKeyAndWindow((a: Int, b:Int ) => (a + b) , (a:Int, b: Int) => (a - b) , Seconds( 3 ), Seconds( 1 )) |

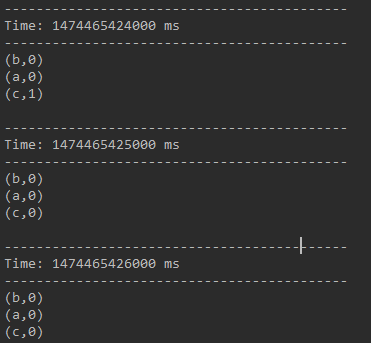
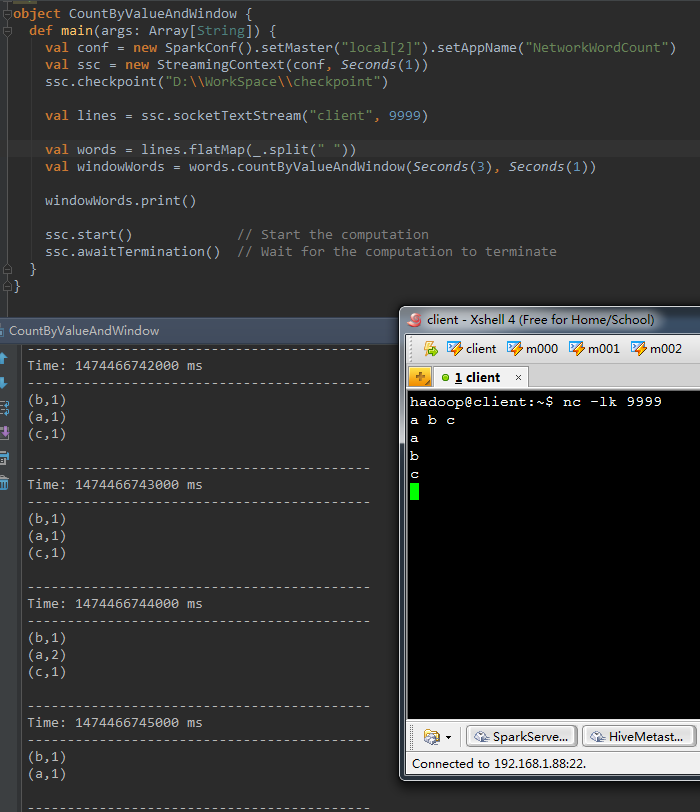
6、 countByValueAndWindow(windowLength,slideInterval, [numTasks])
|
1
|
val windowWords = words.countByValueAndWindow(Seconds( 3 ), Seconds( 1))[/align] |
1、DStream对象之间的Join
2、DStream和dataset之间的join
四、Output Operations
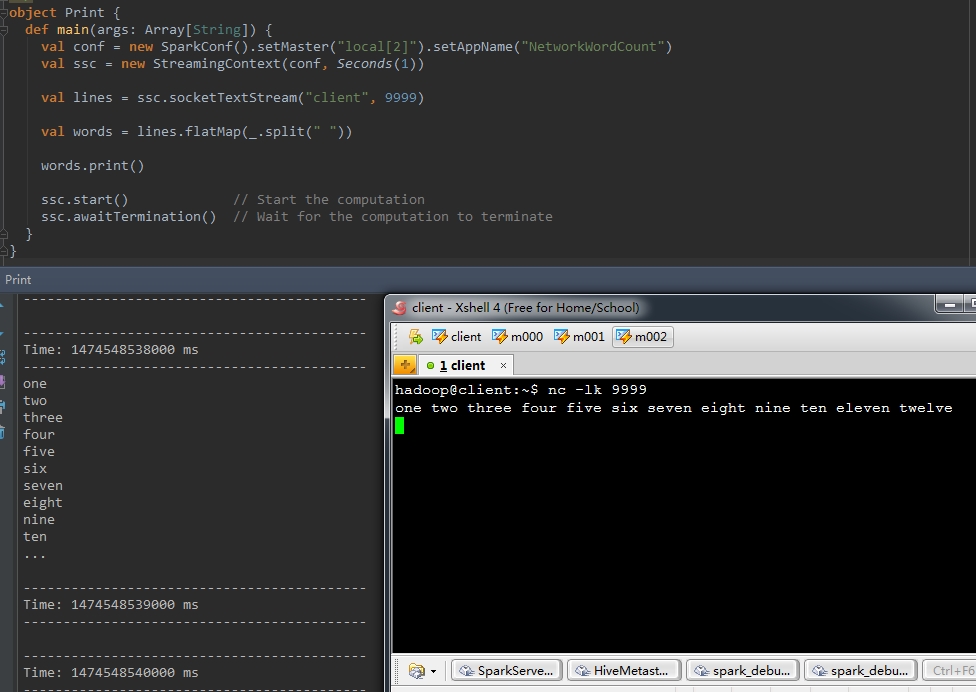
1、print()
|
1
2
|
val words = lines.flatMap(_.split(" "))words.print() |
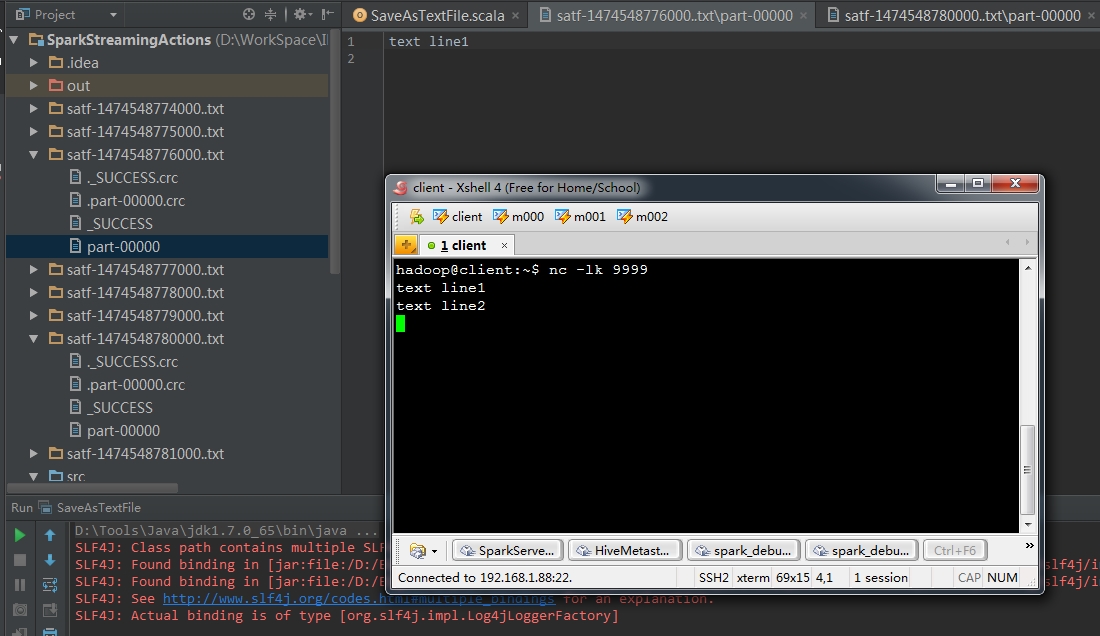
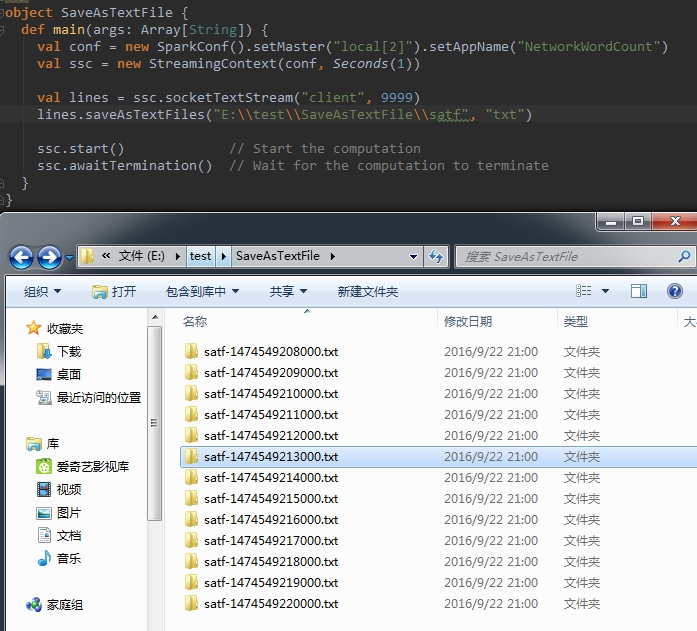
2、saveAsTextFiles(prefix, [suffix])
|
1
|
lines.saveAsTextFiles("satf", ".txt")[/align][align=left] |
3、saveAsObjectFiles(prefix, [suffix])
实验略过,可参考前面一个操作。
4、saveAsHadoopFiles(prefix, [suffix])
5、foreachRDD(func)
sparkStreaming的transformation和action详解的更多相关文章
- (七)Transformation和action详解-Java&Python版Spark
Transformation和action详解 视频教程: 1.优酷 2.YouTube 什么是算子 算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作. 算子分类: 具体: 1.Value ...
- Spring MVC 学习总结(三)——请求处理方法Action详解
Spring MVC中每个控制器中可以定义多个请求处理方法,我们把这种请求处理方法简称为Action,每个请求处理方法可以有多个不同的参数,以及一个多种类型的返回结果. 一.Action参数类型 如果 ...
- Struts2学习笔记(三)——Action详解
Action是用于处理请求操作的,它是由StrutsPrepareAndExceuteFilter分发过来的. 1.Action的创建方式 1) POJO类(PlainOldJavaObjects简单 ...
- Struts2 配置Action详解
Struts2的核心功能是action,对于开发人员来说,使用Struts2主要就是编写action,action类通常都要实现com.opensymphony.xwork2.Action接口,并实 ...
- vuex 源码分析(五) action 详解
action类似于mutation,不同的是Action提交的是mutation,而不是直接变更状态,而且action里可以包含任意异步操作,每个mutation的参数1是一个对象,可以包含如下六个属 ...
- Odoo中的五种Action详解
转载请注明原文地址:https://www.cnblogs.com/ygj0930/p/10826232.html Odoo中的五种action都是继承自ir.actions.actions模型实现的 ...
- Struts 2 配置Action详解_java - JAVA
文章来源:嗨学网 敏而好学论坛www.piaodoo.com 欢迎大家相互学习 实现了Action处理类之后,就可以在struts.xml中配置该Action,从而让Struts 2框架知道哪个Act ...
- 转载 Struts2的配置 struts.xml Action详解
在学习struts的时候,我们一定要掌握struts2的工作原理.只有当我们明确了在struts2框架的内部架构的实现过程,在配置整个struts 的框架时,可以很好的进行逻辑上的配置.接下来我就先简 ...
- Action详解
简介 Action 是用于处理请求操作的,它是由 StrutsPrepareAndExecuteFilter 分发过来的. 在 Struts2 框架中,Action 是框架的核心类,被称为业务逻辑控制 ...
随机推荐
- C++——代码风格
google代码风格 1.使用安全的分配器(allocator),如scoped_ptr,scoped_array 2.测试用的,其他的不能用: 2.1 友元 2.2 C++异常 2.3 RTTI 3 ...
- CSS实现背景图片固定
body { background-image:url('bg.jpg'); background-repeat: no-repeat; background-attachment: fixed; / ...
- Flink 配置文件详解
前面文章我们已经知道 Flink 是什么东西了,安装好 Flink 后,我们再来看下安装路径下的配置文件吧. 安装目录下主要有 flink-conf.yaml 配置.日志的配置文件.zk 配置.Fli ...
- Guava Spiltter类
Splitter 提供了各种方法来处理分割操作字符串,对象等. 类声明 以下是com.google.common.base.Splitter类的声明: @GwtCompatible(emulated= ...
- C++公有继承、私有继承以及友元
公有继承: 基类的成员在派生类中维持原来的访问权限,基类的publice成员为派生类的public成员,基类的protected成员为派生类的protected成员,基类的private成员在派生类的 ...
- 深入理解JAVA虚拟机原理之垃圾回收器机制(一)
更多Android高级架构进阶视频学习请点击:https://space.bilibili.com/474380680 对于程序计数器.虚拟机栈.本地方法栈这三个部分而言,其生命周期与相关线程有关,随 ...
- 大道浮屠诀---NBU7.7.3_oracle11G单机-单机(异机恢复WINDOWS2008平台)
现有环境说明: 一台WINDOWS2008R2:安装有NBU7.7.3,作为服务端 一台WINDOWS2008R2:安装有oracle11.2.0.3,作为数据库服务器 现假设数据库意外崩溃,需要进行 ...
- LCA的 Trajan 算法
参考博客 参考博客 根据博客的模拟,就可以知道做法和思想. 现在就是实现他. 例题 :hdu 2586 题意:m 个询问,x 到 y 的距离,我们的思想就是求出:x到根的距离+y到根的距离- ...
- python之保留有限的历史记录(collections.deque)
1.deque(maxlen=N)创建一个固定长度的队列,当有新的记录加入而队列已经满时,会自动移除老的记录. from collections import deque q = deque(maxl ...
- 关于windows和linux系统更换JDK版本后,修改环境变量也无法生效的原因和解决办法
今天遇到了一个问题: 我linux系统之前安装JDK12,今天将其改成了JDK1.8,并修改了环境变量,但是通过java -version命令显示的依旧是JDK12的版本. 这是因为,当使用安装版本的 ...