搭建高可用的flink JobManager HA
JobManager协调每个flink应用的部署,它负责执行定时任务和资源管理。
每一个Flink集群都有一个jobManager, 如果jobManager出现问题之后,将不能提交新的任务和运行新任务失败,这样会造成单点失败,所以需要构建高可用的JobMangager。
类似zookeeper一样,构建好了高可用的jobManager之后,如果其中一个出现问题之后,其他可用的jobManager将会接管任务,变为leader。不会造成flink的任务执行失败。可以在单机版和集群版构建jobManager。
下面开始构建一个单机版flink的JobManger高可用HA版。
首先需要设置SSH免密登录,因为启动的时候程序会通过远程登录访问并且启动程序。
执行命令,就可以免密登录自己的机器了。如果不进行免密登录的话,那么启动的hadoop的时候会报 "start port 22 connection refused"。
ssh-keygen -t rsa ssh-copy-id -i ~/.ssh/id_rsa.pub huangqingshi@localhost
接下来在官网上下载hadoop的binary文件,然后开始解压,我下载的版本为hadoop-3.1.3版本。安装Hadoop的目的是用hadoop存储flink的JobManager高可用的元数据信息。
我安装的是hadoop的单机版,可以构建hadoop集群版。接下来进行hadoop的配置。
配置etc/hadoop/coresite.xml,指定namenode的hdfs协议文件系统的通信地址及临时文件目录。
<configuration>
<property>
<!--指定namenode的hdfs协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<property>
<!--指定hadoop集群存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop/tmp</value>
</property>
</configuration>
配置etc/hadoop/hdfs-site.xml, 设置元数据的存放位置,数据块的存放位置,DFS监听端口。
<configuration>
<property>
<!--namenode 节点数据(即元数据)的存放位置,可以指定多个目录实现容错,多个目录用逗号分隔-->
<name>dfs.namenode.name.dir</name>
<value>/tmp/hadoop/namenode/data</value>
</property>
<property>
<!--datanode 节点数据(即数据块)的存放位置-->
<name>dfs.datanode.data.dir</name>
<value>/tmp/hadoop/datanode/data</value>
</property>
<property>
<!--手动设置DFS监听端口-->
<name>dfs.http.address</name>
<value>127.0.0.1:</value>
</property>
</configuration>
配置etc/hadoop/yarn-site.xml,配置NodeManager上运行的附属服务以及resourceManager主机名。
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<!--配置NodeManger上运行的附属服务。需要配置成mapreduce_shuffle后才可以在Yarn上运行MapReduce程序-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--resourcemanager 的主机名-->
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
配置etc/hadoop/mapred-site.xml,指定mapreduce作业运行在yarn上。
<property>
<!--指定mapreduce作业运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
需要执行nameNode的format操作,不执行直接启动会报“NameNode is not formatted.”。
bin/hdfs namenode -format
接下来启动hadoop,如果成功的话,可以访问如下URL:
http://localhost:8088/ 查看构成cluster的节点
http://localhost:8042/node 查看node的相关信息。

以上说明hadoop单机版搭建完成。
接下来需要下载一个flink的hadoop插件,要不然flink启动的时候会报错的。
把下载的插件放到flink文件的lib文件夹中。
配置一下flink文件夹的conf/flink-conf.yaml。指定HA高可用模式为zookeeper,元数据存储路径用于恢复master,zookeeper用于flink的 checkpoint 以及 leader 选举。最后一条为zookeeper单机或集群的地址。
high-availability: zookeeper
high-availability.storageDir: hdfs://127.0.0.1:9000/flink/ha
high-availability.zookeeper.quorum: localhost:2181
其他的采用默认配置,比如JobManager的最大堆内存为1G,每一个TaskManager提供一个task slot,执行串行的任务。
接下来配置flink的 conf/masters 用于启动两个主节点JobManager。
localhost:8081
localhost:8082
配置flink的 conf/slaver 用于配置三个从节点TaskManager。
localhost
localhost
localhost
进入zookeeper路径并且启动zookeeper
bin/zkServer.sh start
进入flink路径并启动flink。
bin/start-cluster.sh conf/flink-conf.yaml
启动截图说明启动了两个节点的HA集群。

执行jps,两个JobManager节点和三个TaskManager节点:

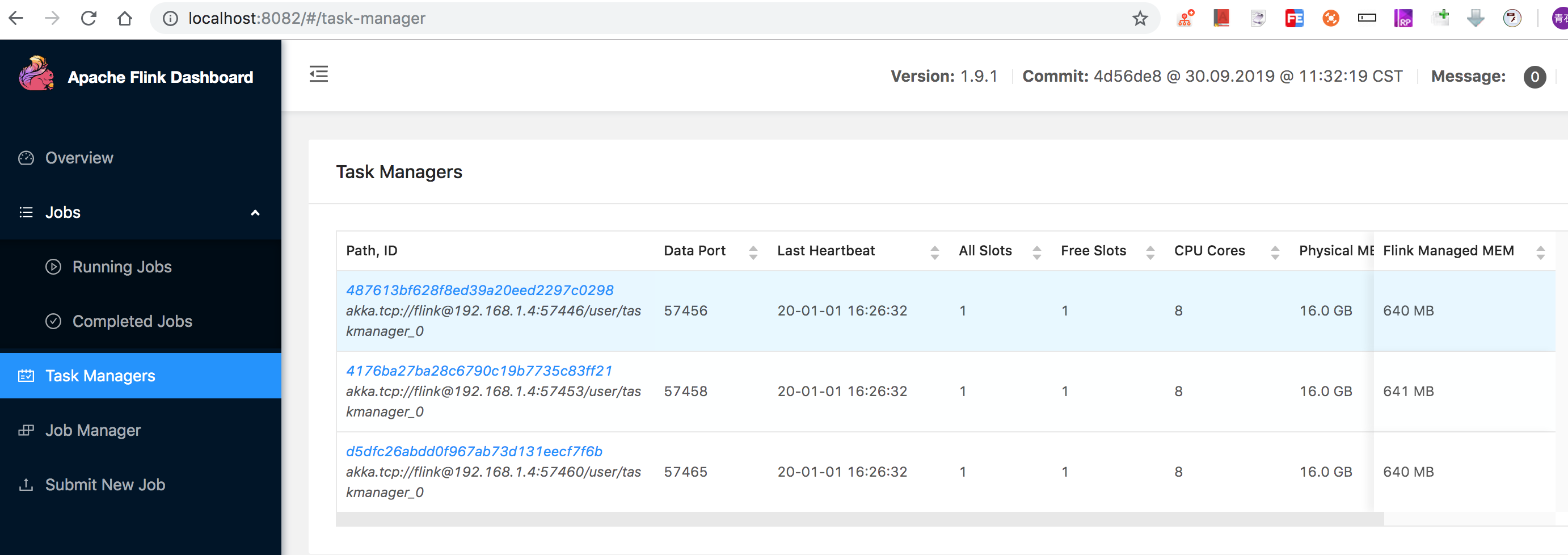
浏览器访问 http://localhost:8081 和 http://localhost:8082,查看里边的日志,搜索granted leadership的说明是主JobManager,如下图。8082端口说明为主JobMaster

一个JobManager, 里边有三个TaskManager,两个JobManager共享这三个TaskManager:
接下来我们来验证一下集群的HA功能,我们已经知道8082为主JobManager,然后我们找到它的PID,使用如下命令:
ps -ef | grep StandaloneSession
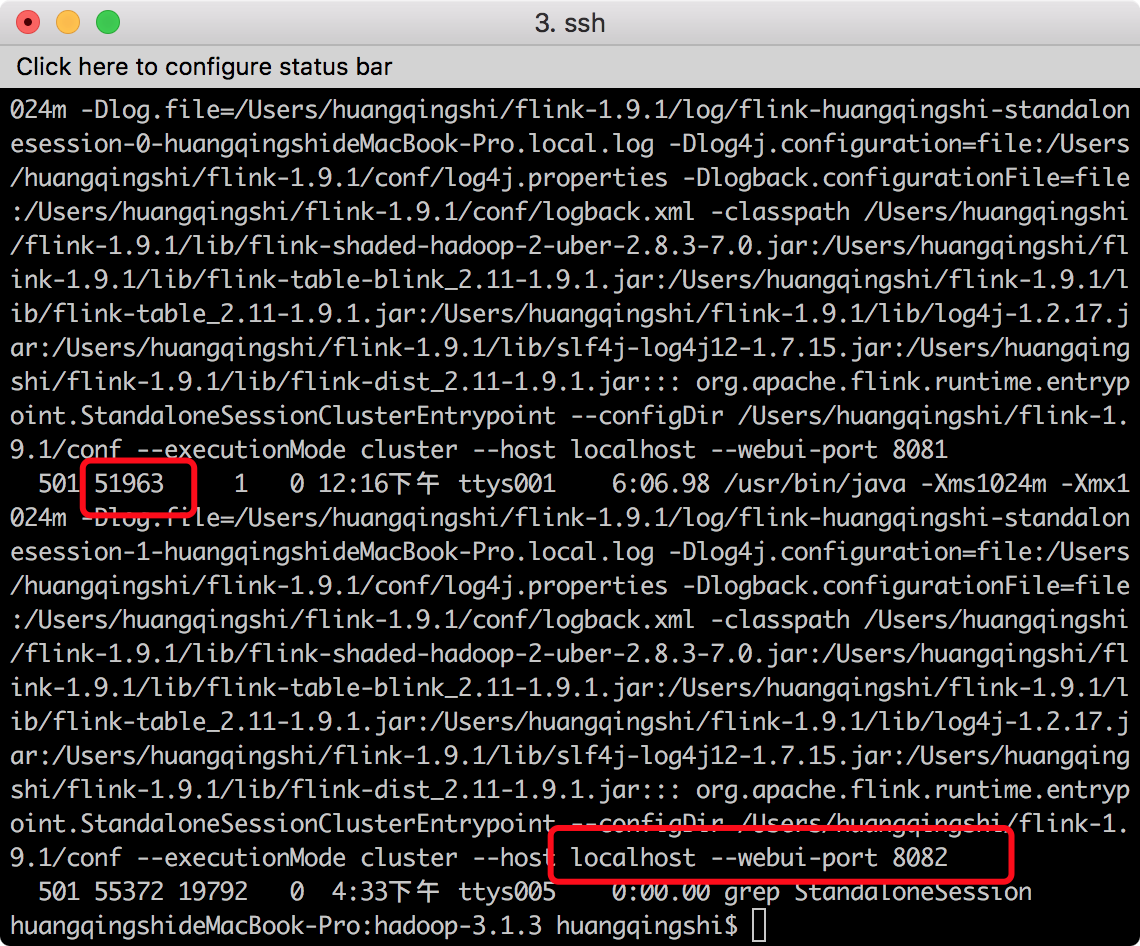
我们将其kill掉,执行命令kill -9 51963,此时在访问localhost:8082 就不能访问了。localhost:8081 还可以访问,还可以提供服务。接下来咱们重新 启动flink的JobManager 8082 端口。
bin/jobmanager.sh start localhost
此时8081已经成为leader了,继续提供高可用的HA了。

好了,到此就算搭建完成了。
搭建高可用的flink JobManager HA的更多相关文章
- Nginx+Keepalived(双机热备)搭建高可用负载均衡环境(HA)
原文:https://my.oschina.net/xshuai/blog/917097 摘要: Nginx+Keepalived搭建高可用负载均衡环境(HA) http://blog.csdn.ne ...
- Nginx+Keepalived(双机热备)搭建高可用负载均衡环境(HA)-转帖篇
原文:https://my.oschina.net/xshuai/blog/917097 摘要: Nginx+Keepalived搭建高可用负载均衡环境(HA) http://blog.csdn.ne ...
- 通过LVS+Keepalived搭建高可用的负载均衡集群系统
1. 安装LVS软件 (1)安装前准备操作系统:统一采用Centos6.5版本,地址规划如下: 服务器名 IP地址 网关 虚拟设备名 虚拟ip Director Server 192.168 ...
- keepalived工作原理和配置说明 腾讯云VPC内通过keepalived搭建高可用主备集群
keepalived工作原理和配置说明 腾讯云VPC内通过keepalived搭建高可用主备集群 内网路由都用mac地址 一个mac地址绑定多个ip一个网卡只能一个mac地址,而且mac地址无法改,但 ...
- 搭建高可用mongodb集群(四)—— 分片(经典)
转自:http://www.lanceyan.com/tech/arch/mongodb_shard1.html 按照上一节中<搭建高可用mongodb集群(三)-- 深入副本集>搭建后还 ...
- [转]搭建高可用mongodb集群(四)—— 分片
按照上一节中<搭建高可用mongodb集群(三)—— 深入副本集>搭建后还有两个问题没有解决: 从节点每个上面的数据都是对数据库全量拷贝,从节点压力会不会过大? 数据压力大到机器支撑不了的 ...
- [转]搭建高可用mongodb集群(二)—— 副本集
在上一篇文章<搭建高可用MongoDB集群(一)——配置MongoDB> 提到了几个问题还没有解决. 主节点挂了能否自动切换连接?目前需要手工切换. 主节点的读写压力过大如何解决? 从节点 ...
- 搭建高可用mongodb集群(四)—— 分片
按照上一节中<搭建高可用mongodb集群(三)—— 深入副本集>搭建后还有两个问题没有解决: 从节点每个上面的数据都是对数据库全量拷贝,从节点压力会不会过大? 数据压力大到机器支撑不了的 ...
- 搭建高可用mongodb集群(三)—— 深入副本集内部机制
在上一篇文章<搭建高可用mongodb集群(二)—— 副本集> 介绍了副本集的配置,这篇文章深入研究一下副本集的内部机制.还是带着副本集的问题来看吧! 副本集故障转移,主节点是如何选举的? ...
随机推荐
- 随机数专题 Day08
package com.sxt.arraytest2; import java.util.Arrays; /* * 随机数专题 * Math类的random()方法 * m~n的随机数 * 公式:(i ...
- 4818 Largest Empty Circle on a Segment (几何+二分)
ACM-ICPC Live Archive 挺水的一道题,直接二分圆的半径即可.1y~ 类似于以前半平面交求核的做法,假设半径已经知道,我们只需要求出线段周围哪些位置是不能放置圆心的即可.这样就转换为 ...
- 异常处理之try catch finally
package com.sxt.wrapper.test2; /* 0418 * 异常处理 * 采用异常处理的好处:保证程序发生异常后可以继续执行 * e.printStaceTrace:打印堆栈信息 ...
- Hbase数据模型物理视图
- saltStack 配置管理(也就是替换文件)
目录 /srv/salt/base下面新建一个文件dns.sls /opt/resolv.conf_bak: #这个是文件替换的位置,也就说替换到远程文件的/opt/resolv.conf_ ...
- Android 使用ViewPager结合PhotoView开源组件实现网络图片在线浏览功能
在实际的开发中,我们市场会遇到这样的情况:点击某图片,浏览某列表(某列表详情)中的所有图片数据,当然,这些图片是可以放大和缩小的,比如我们看下百度贴吧的浏览大图的效果: 链接 这种功能,在一些app ...
- BERT-Pytorch demo初探
https://zhuanlan.zhihu.com/p/50773178 概述 本文基于 pytorch-pretrained-BERT(huggingface)版本的复现,探究如下几个问题: py ...
- 2018-11-19-Roslyn-NameSyntax-的-ToString-和-ToFullString-的区别
title author date CreateTime categories Roslyn NameSyntax 的 ToString 和 ToFullString 的区别 lindexi 2018 ...
- linux包之nmap之ncat命令
[root@ka1che225 ~]# which nc/usr/bin/nc[root@ka1che225 ~]# which ncat/usr/bin/ncat[root@ka1che225 ~] ...
- php三目运算计算三个数最大值最小值
文章地址:https://www.cnblogs.com/sandraryan/ $x = 10; $y = 45; $z = 3; //求出三个数字中最大值最小值 //先比较x y,如果x> ...