回首2018 | 分析型数据库AnalyticDB: 不忘初心 砥砺前行
题记
分析型数据库AnalyticDB(下文简称ADB),是阿里巴巴自主研发、唯一经过超大规模以及核心业务验证的PB级实时数据仓库。截止目前,现有外部支撑客户既包括传统的大中型企业和政府机构,也包括众多的互联网公司,覆盖外部十几个行业。同时,ADB在阿里内部承接着广告营销、商家数据服务、菜鸟物流、盒马新零售等众多核心业务的高并发低延时的分析处理。
2018年,我们新增了深圳和湾区研发中心迎来更多专业精兵强将的加入,也受到了众多业务场景挑战极大的客户鼎力支持,注定让这一年在发展史上将留下深深的印记。在过去的这一年,ADB在架构以及产品化演进上,迎来了飞速发展,谨以此文记录一起走过的2018年。
架构演进
一.接入层和SQL Parser
1.全面采用自研Parser组件-FastSQL
由于历史原因,ADB的各模块中曾有多个Parser组件,例如当时存储节点用的是Druid, 接入层SQL解析用的是Antlr Parser, 导致SQL兼容性难提升。对于一个上线多年、服务于内外众多数据业务的ADB来说,熟悉数据库的同学都知道,替换Parser难度之大,堪比飞行中换引擎。
经过半年多的努力,ADB完成了将上述几大Parser组件统一升级替换为FastSQL ( Base on Druid,经过开源社区8年的完善,语法支持已经非常完备)。升级为FastSQL后,在SQL兼容性大幅度提升、复杂场景解析速度提升30-100倍的同时, FastSQL还能无缝结合优化器,提供常量折叠、函数变换、表达式转换、函数类型推断、常量推断、语义去重等功能支持,方便优化器生成最优的执行计划。
2.实时写入性能提升10倍
在ADB v2.7.4版本开始,在SQL Parser上做了深度技术优化,大幅度提升了INSERT环节的性能,在实际生产环境中性能10倍性能提升,以云上4*C4为例,item表可以压测到15w TPS。
3.海量数据流式返回
在ADB v2.7以前的版本,计算框架返回的数据,需要在内存中堆积,等待全部执行完才返回到客户端。在并发大或者结果大时,可能有内存溢出的风险。从2.7版本开始,默认采用流式返回,数据实时返回客户端,能降低延时,极大的提升了大结果集返回的调用稳定性。
二. Query Optimizer
2018年,一方面云上云下业务全面从ADB上一代的LM引擎,迁移至羲和MPP引擎,另一方面越来越多的客户不希望走离线或者流计算清洗,实时数仓场景迸发,同时越来越多自动生成SQL的可视化工具开始对接ADB,对优化器团队提出了极高挑战。
为了应对这些挑战,在这一年里优化器团队从无到有,逐渐组建起来一支精练的国际化团队。在不断打造磨合过程中,ADB优化器这一年的斩获如下:
1.建立并完善RBO Plus优化器
不同于传统RBO优化器,在RBO Plus设计中实现了下列关键特性:
1). 引入代价模型和估算,利用ADB的高效存储接口,引入dynamic selectivity & cardinality估算优化join reorder, 使得ADB可以应对多达10+表join的复杂查询场景.
2). 针对MPP特别优化data shuffling,aggregation等执行计划,相对于LM引擎业务场景性能接近零回退。
3). 从功能和性能两个维度,对各种常见以及复杂关联子查询场景进行了深度优化,设计了一系列关联规则算法,在各种标准benchmark中相应的查询中,部分场景up to 20X提升。
4). 针对超短时延(ms)点查,设计了parameterized plan cache,将这些场景的优化时间成本降低10倍以上。
2.打造CBO优化器
面对越来越复杂的业务查询场景,RBO及RBO Plus有其相应的局限和挑战,CBO成为ADB优化器迈向通用商业优化器的关键,我们没有采用虽广泛使用但局限性也很多的Calcite优化器,而是着手打造自主可控的CBO优化器,提升ADB的核心竞争力:
1) 建立高效的统计信息收集体系,平衡准确性与收集代价,为CBO提供“基础信息设施”;
2) 构建Cascades架构的CBO框架,将其打造成可扩展的优化平台。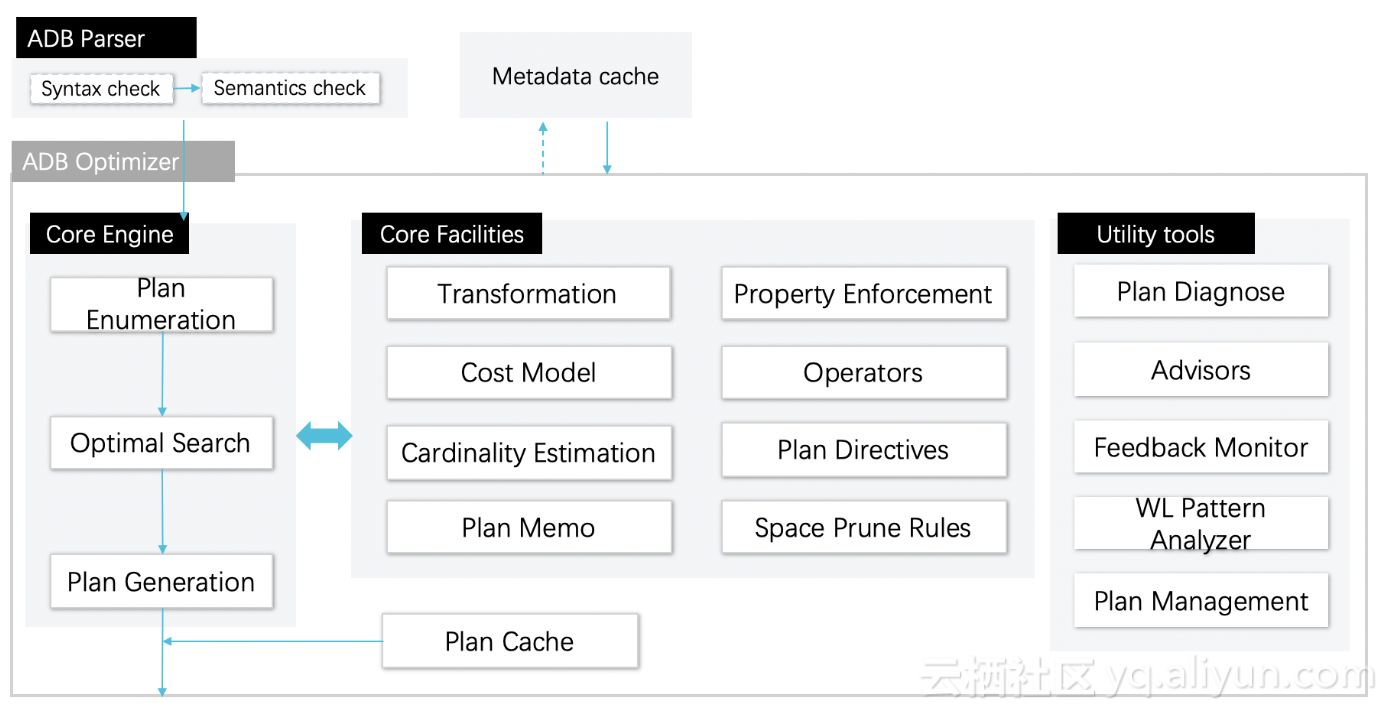
三. 羲和MPP引擎
这一年,ADB架构全面从上一代的LM引擎切换至羲和MPP引擎,羲和引擎一方面既要支撑完成切换,满足客户更灵活自由查询的重任,又要通过大幅度的性能优化来消除引擎切换带来的某些场景下的性能开销。
1.全Binary计算
基于Binary 的计算,省去Shuffle 的序列化和反序列化开销,并且与存储深度绑定,做到存储计算一体化,整个计算过程没有多余的序列化和反序列化开销。
2.内部池化
通过定长的内存切片完成池化,在计算过程中减少了连续内存扩容带来的消耗,同时通过池化完全自主管控内存,避免了在复杂SQL场景下的GC消耗。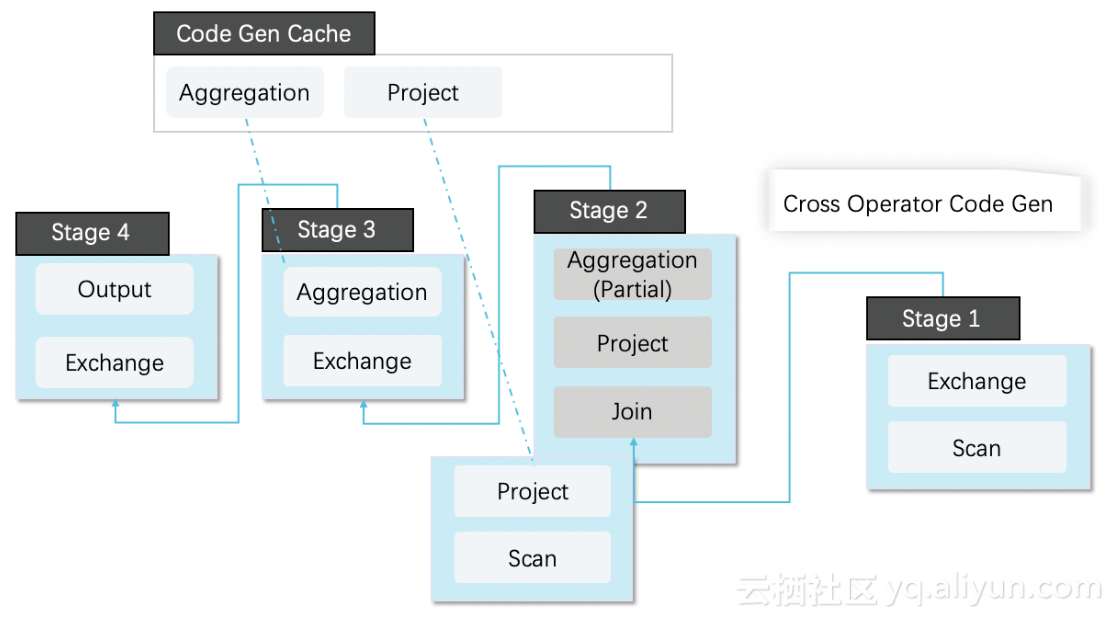
3.CodeGen深度优化
1). Cache使用,通过对算子,表达式的CodeGen常量抽取,缓存CodeGen生成的代码,在高并发场景下避免了每次都需要动态编译代码的开销,为支持高并发和QPS的业务打好了基础。
2). 通过算子融合减少算子之间物化的开销。
4.其它优化
1). 按列计算,通过列式计算与JVM团队合作引入JDK11支持新的SIMD指令集进行计算优化
2). 自动算法优化,根据数据分布,数据采样自动优化部分执行算法和内存;
3). 算子自适应的Spill,支持动态的内存分配和抢占,支持join,agg等算子落盘;
4). 引入新的序列化和反序列框架替换原有的JSON协议,引入新的Netty替换原有Jetty
5). 支持运行时统计信息收集,包括算子级,stage级,query级的内存、cpu cost统计,支持部分自动识别慢SQL。
四. 玄武存储引擎
为了满足业务高并发写入、低延时的查询,ADB做了读写分离架构设计。在历史的版本中,读写分析架构下有2个问题:1. 写入到可见是异步的, 部分场景有读写强一致性的诉求。2.增量数据写入较大的情况下,查询变慢。同样,今年存储引擎在增量数据的实时性和性能上也做出了重大突破。
1.支持读写强一致性
最新的ADB版本中,设计了一套完备的一致性读写分离架构,如下图所示: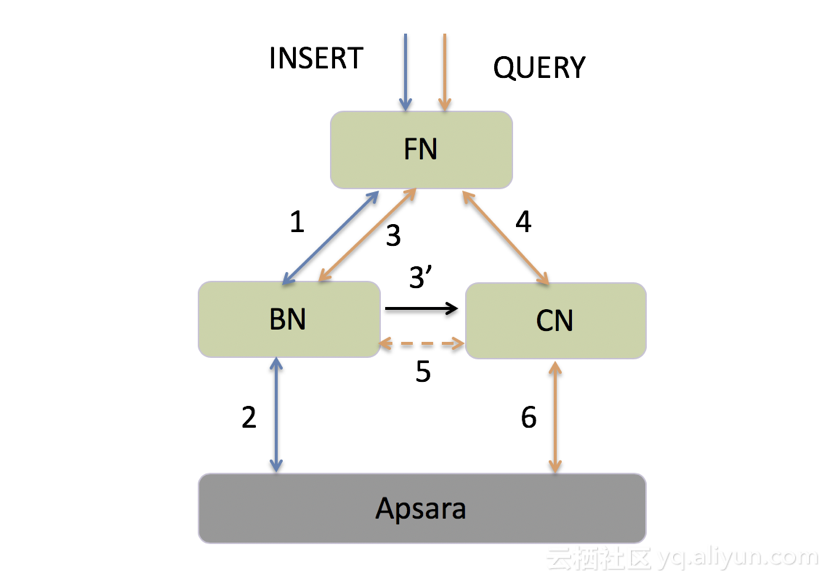
蓝色线代表写入链路,橙色线代表读取链路。以一次写入和读取为例,当用户新写入某表的数据后,立即发起查询,此时FN会收集该表在所有BN上的最新写入版本号(step 3),并将该版本号(标记为V1)信息随同查询请求一同发往对应的CN节点(step 4),CN比对该表在本地的消费版本(记为V2)和请求的版本号。
若V1>V2,CN消费到该最新写入数据(step 5)后提供查询;若V1
2.提升增量数据区的查询性能
在 ADB 的存储节点对于突发的大批量实时写入,在增量数据区可能短时间内积累较多数据。如果查询发生在增量数据区,大量的table scan读取会拖慢整个数据分析性能。为此增量数据区引入 RocksDB 构建增量数据的索引,保证增量数据区的访问性能,通过LSM-Tree 的分层存储结果,提供良好的写入性能,及较好的查询能力。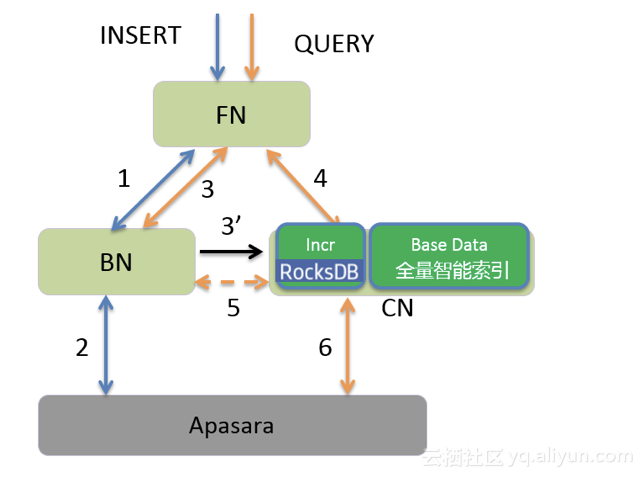
五. 分布式Meta服务
历史版本元数据稳定性挑战大,各模块各自访问元数据存在race condition,meta压力大,DDL体验差。今年我们重构了元数据模块,上线GMS服务提供元数据统一管理,同时提供分布式DDL能力,并通过分布式缓存降低meta库压力,提供高效元数据访问效率。
全局元数据服务发布
1). Global Meta Service (GMS)上线生产,提供分布式DDL和数据调度能力,同步建删表提升用户体验。
2). 表分区分配算法改进,为计算调度优化,支持多表组场景下的数据均匀分布
3). 数据更新(上线),数据重分布(Rebalance)稳定性大大提升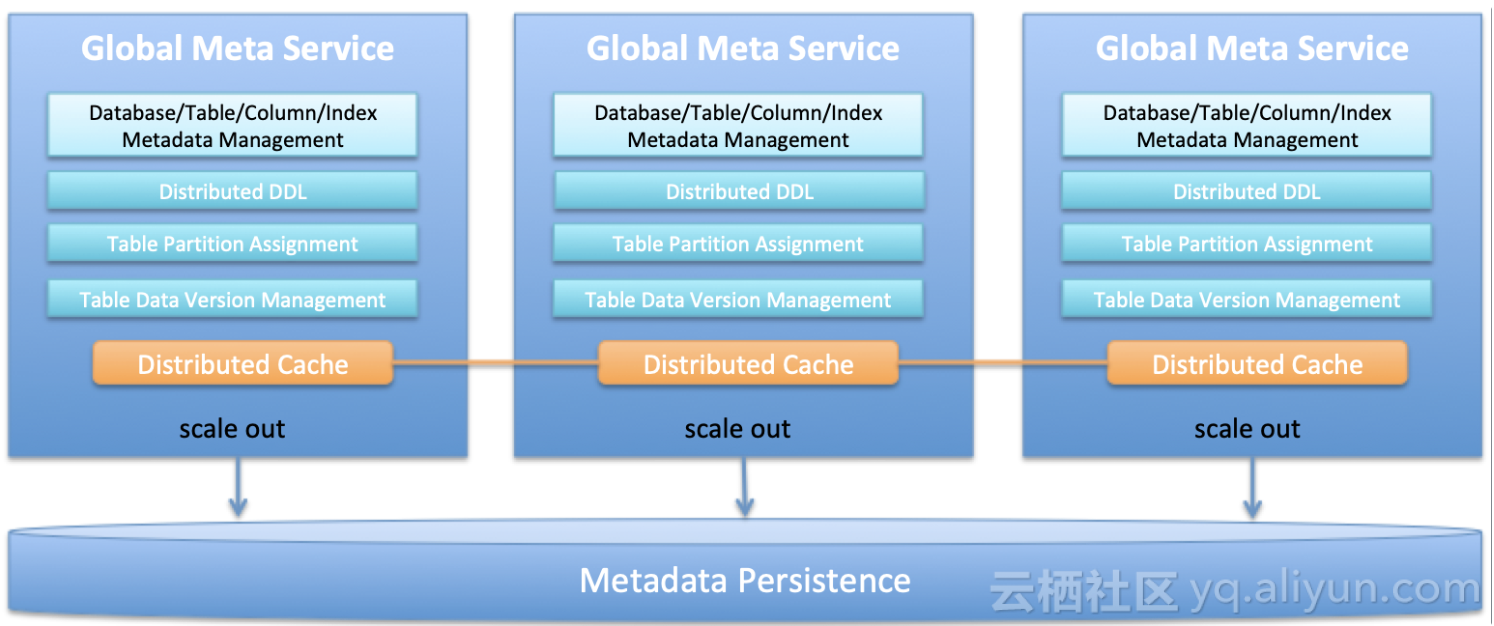
六. 硬件加速
GPU虽然已经广泛用于通用计算,但是通常是用于图形处理、机器学习和高性能计算等领域。如何将GPU的强大计算能力和ADB进行有机结合,并不是一个容易解决的问题。要想用好GPU,在GPU资源管理、代码生成、显存管理、数据管理、执行计划优化等方便,均有诸多挑战。
2018年,ADB引入了GPU作为计算加速引擎,原本依赖离线分析引擎、隔天才能完成的计算,现在只需要秒级延迟即可完成,成功将数据价值在线化,为客户带来了巨大的价值。
1.GPU资源管理
如何让去访问GPU资源是首先要解决的问题。 ADB通过jCUDA调用CUDA API,用于管理和配置GPU设备、GPU kernel的启动接口封装。该模块作为Java和GPU之间的桥梁,使得JVM可以很方便地调用GPU资源。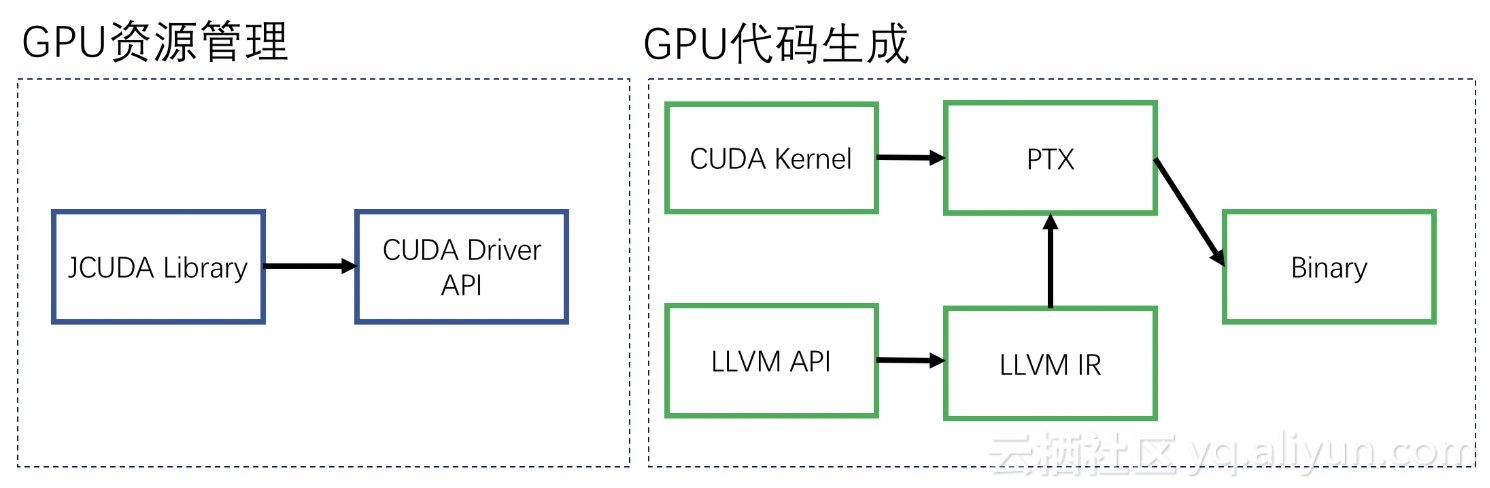
2.CodeGen
ADB的执行计划是为CPU做准备的,无法在GPU上执行。而且由于GPU架构的特殊性,GPU的编程模型也和CPU不同。为了解决这一问题,引入新的CodeGen模块。CodeGen先是借助LLVM API将物理计划编译成LLVM IR,IR经过优化以后通过转换成PTX代码。然后调用CUDA将PTX代码转换成本地可执行代码,并启动其中的GPU计算函数。
CodeGen可以针对不同的处理器生成不同的代码,在GPU不可用时,也可以转至CPU进行执行。相对传统火山模型,ADB的CodeGen模块有效减少函数调用的开销、充分利用GPU的并发能力。另外Code Generator利用了算子融合,如group-by聚合、join再加聚合的融合,大大减少中间结果(特别是Join的连接结果)的拷贝和显存的占用。
3.显存管理
ADB开发了VRAM Manager用于管理各GPU的显存。有别于现在市面上其他GPU数据库系统使用GPU的方式,为了提升显存的利用率、提升并发能力,结合ADB多分区、多线程的特点,我们设计基于Slab的VRAM Manager来统一管理所有显存申请。
性能测试显示分配时间平均为1ms,明显快于GPU自带的显存分配接口的700ms,有利于提高系统整体并发度。
4.Plan优化
SQL从FN发送到CN,Task Manager先根据计算的数据量以及查询特征选择由CPU还是GPU处理,然后根据逻辑计划生成适合GPU执行的物理计划。GPU Engine收到物理计划后先对执行计划进行重写。如果计划符合融合特征,则启动复合算子融合,从而大量减少算子间临时数据的传输成本。
产品化能力升级
一. 易用性提升
1.全面切换羲和MPP引擎
从2.6.2版本开始,集团内和公有云全部默认MPP引擎,彻底告别上一代LM引擎的各种查询限制。MPP对SQL写法支持更加自由灵活,ADB客户迎来Full MPP时代。
2.SQL兼容性大幅度提升
接入层、存储层Parser模块全部升级为FastSQL后, 外加切换MPP成功,ADB v2.7以后的SQL兼容性较历史版本有了非常大提升。SQL其他优化还包括支持了流式后不再限制查询结果集返回、分页兼容MySQL等等。
3.自动扩缩容、升降配
6月份发布了重磅功能: 自动扩缩容+灵活升降配。除了扩缩基本能力外,客户还可以在规格之间切换。例如从10c4 切换至4c8, 可以从4c8切换至10c4,同时实时表还支持在高性能SSD实例和大存储SATA实例间来回切换。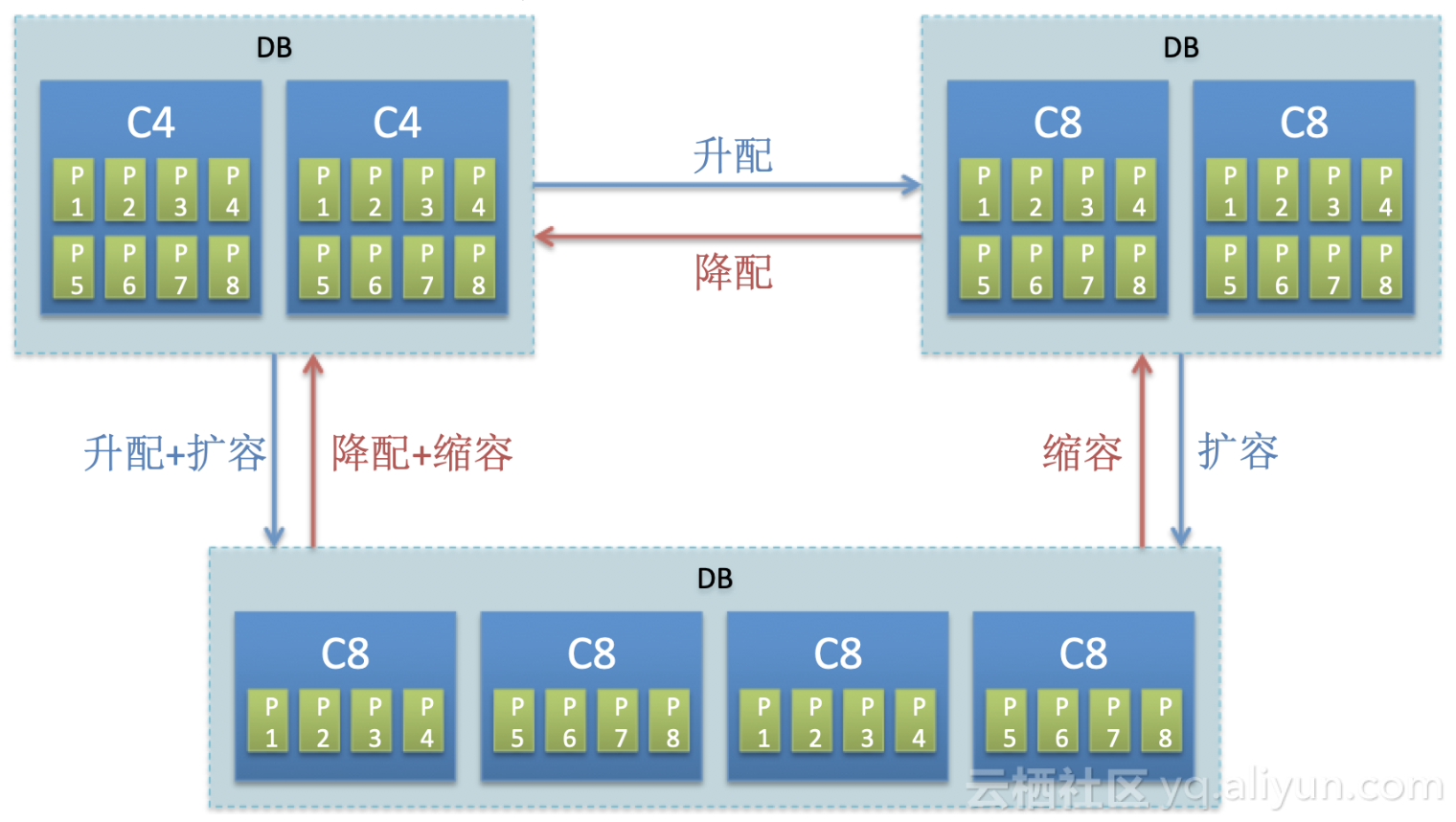
上线效果:配置切换做到读不中断,写入中断约1-2分钟,后续通过动态漂移分区,写入也能做到完全不停服。
4.新版控制台和DMS上线
公有云新版的控制台展示的内容更加丰富,支持控制台打点,查看用户画像;增加了更多和用户交互的地方。用户管理,acl和子账号授权更加便捷等。DMS全新改版,体验大幅度提升,方便导入导出,支持SQL提示和SQL记忆功能。
5.发布面向用户侧的监控告警系统
为提升客户的自助化服务能力,用户侧的监控支持的指标有CPU使用量、查询和写入量、数据倾斜、Top Slow SQL等。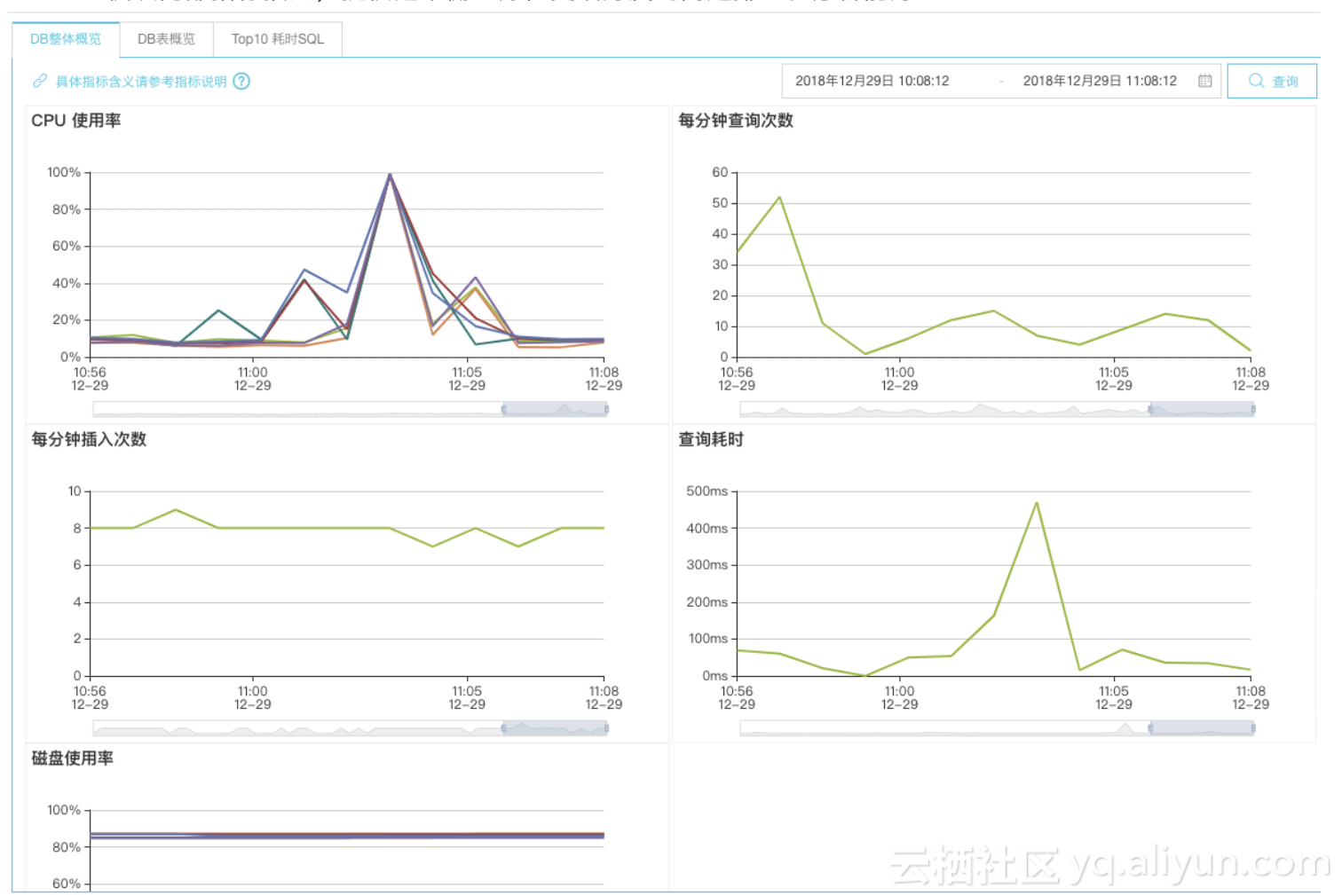
6.全网数据库监控大盘上线
这是全网数据库的眼睛,弹内云上数据库运行状况一览无遗。通过对数据库和系统层各种指标的埋点分析,时刻监控着数据库的运行状况,如下图所示(demo数据),同时支持将异常指标推送客户钉钉群,大幅度提升了运营值班效率。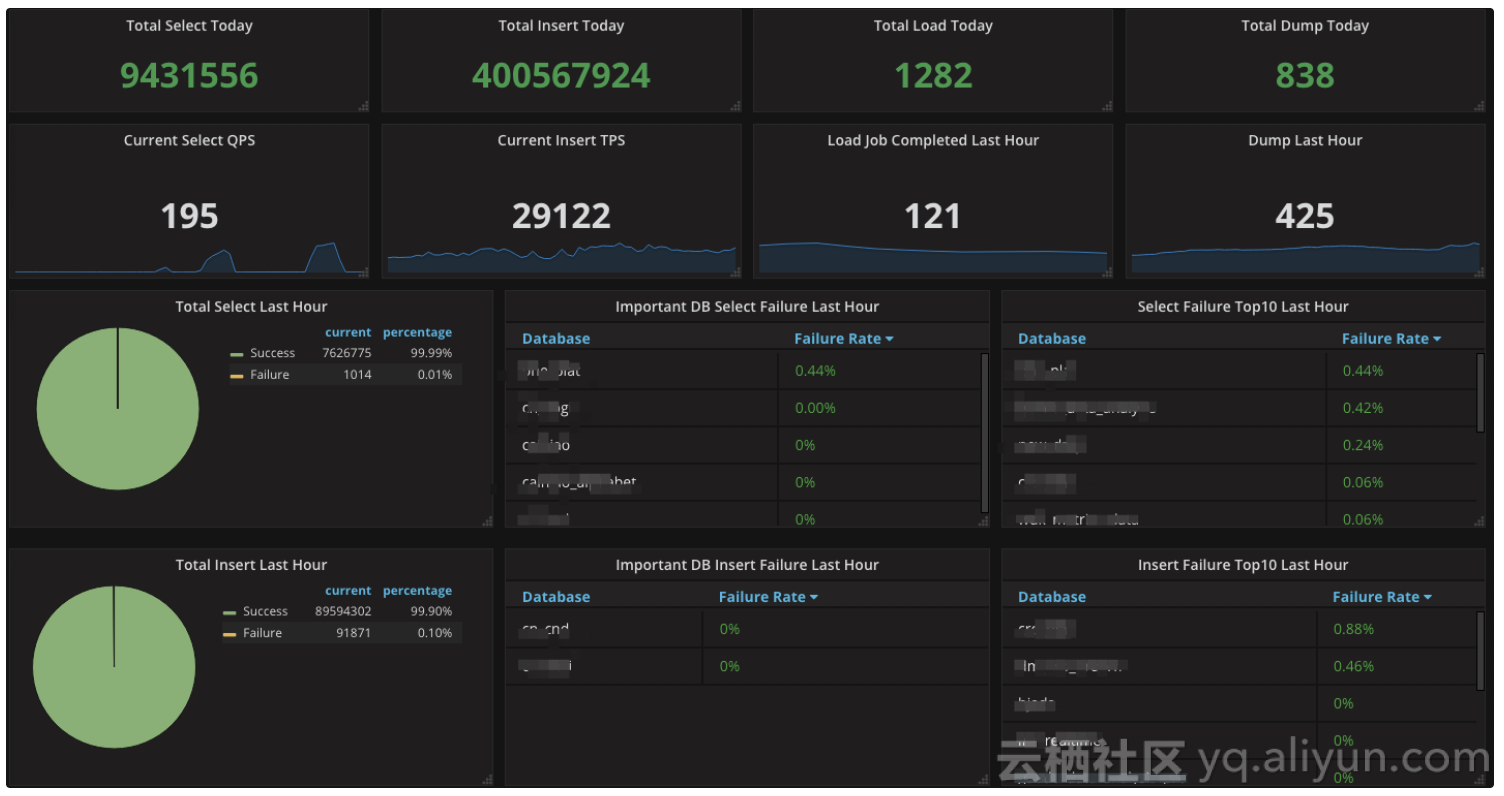
7.发布可用区
这一年公共云发布多可用区支持,彻底解决单个region卖空的问题,企业客户还可以有选择的利用可用区做服务容灾。
二. 发布新的核心功能
1.向量分析
今年9月正式发布向量分析能力,使得结构化与非结构化数据具备融合分析的能力。基于向量聚类规律的向量分区规则,按照聚类结果分区,让距离相近的向量就近存储。在某专有云项目里,支持1:10亿的人脸识别,QPS过万,延迟在100毫秒内,数据量达到数TB级别。
同时首次支撑银泰、盒马等新零售场景的人脸识别、算法推荐、与结构化数据实时融合分析,毫秒级打通线上线下会员体系,支撑实时数据化线下互动、营销。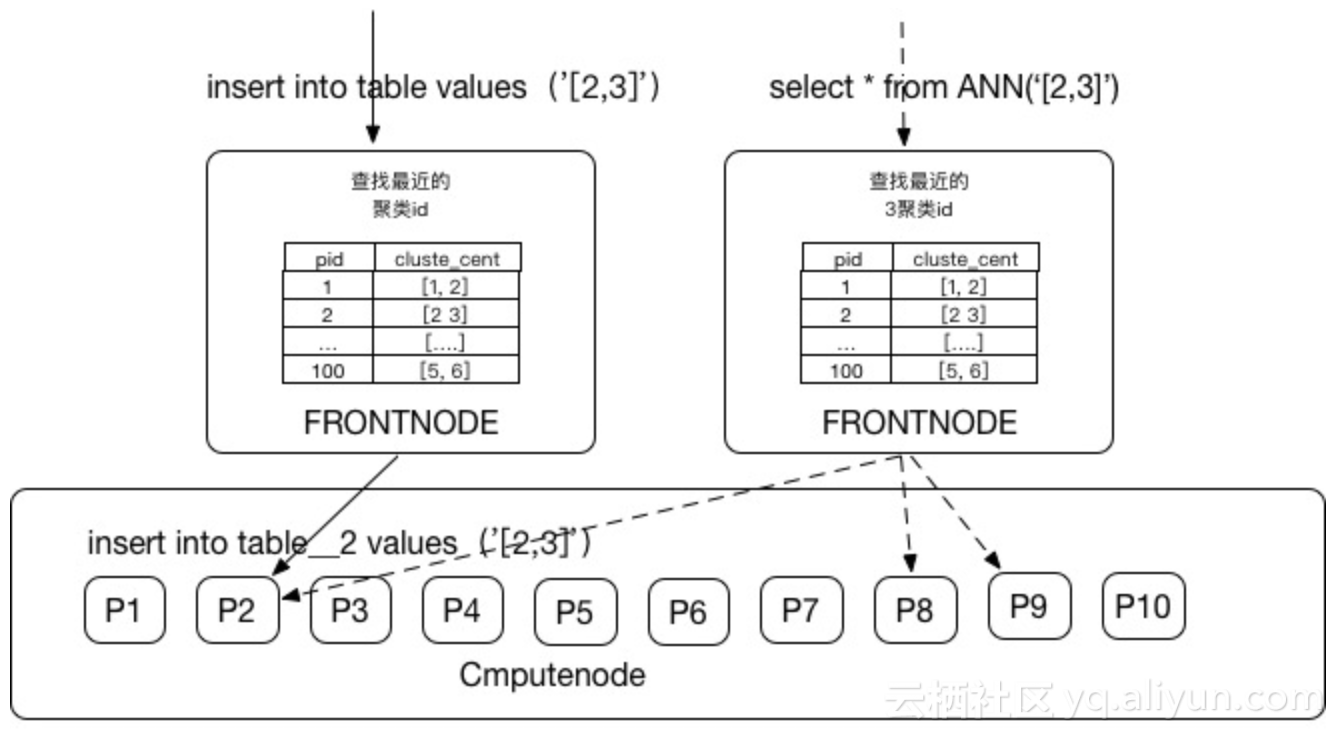
2.全文检索
ADB v2.7.4版本后,通过SQL语言提供全文检索功能,将常用的结构化数据分析操作,与灵活的非结构化数据分析操作统一,使用同一套SQL语言操作多种类型数据,降低了学习和开发成本。一方面提供结构化数据、非结构化文本的融合检索、多模分析能力,另一方面基于MPP+DAG技术提供了完善的分布式计算能力,同时内置了来自淘宝、天猫搜索的智能分词组件,分词效果更好,速度更快。
3.新数据类型 JSON & Decimal
在2.7版本,正式发布JSON数据类型,完整的支持了包括Object、NULL、Array在内的所有JSON类型的检索分析,为业务提供了 Schema less的极大灵活性,同时也提供了快速的检索性能。为了更好方便金融客户,同样在2.7版本里,ADB正式发布Decimal数据类型,向传统数据库的数据类型兼容性上又迈出了重要的一步。
三. 生态建设
1.数据接入
客户数据往往有多种多样,存储在各种地方。为了追求更低成本、更高效率的数据接入能力,打造实时数仓的能力,ADB今年在数据接入上做了诸多的完善。
1). Copy From OSS & MaxCompute 开发完成,元旦后上线。
2). ADB Uploader发布,方便本地文件快速导入。
3). ADB发布Logstash插件,方便日志数据format后直接写入ADB,中间无需经过MQ或者HUB。
4). ADB Client SDK发布并开源,客户端写入编程逻辑简化,聚合写入性能大幅度提升。
5). Batch表导入稳定性大大提升,同时完成MaxCompute SDK升级和OpenMR切换。
6). Connector Service上线,提供统一数据源接入层
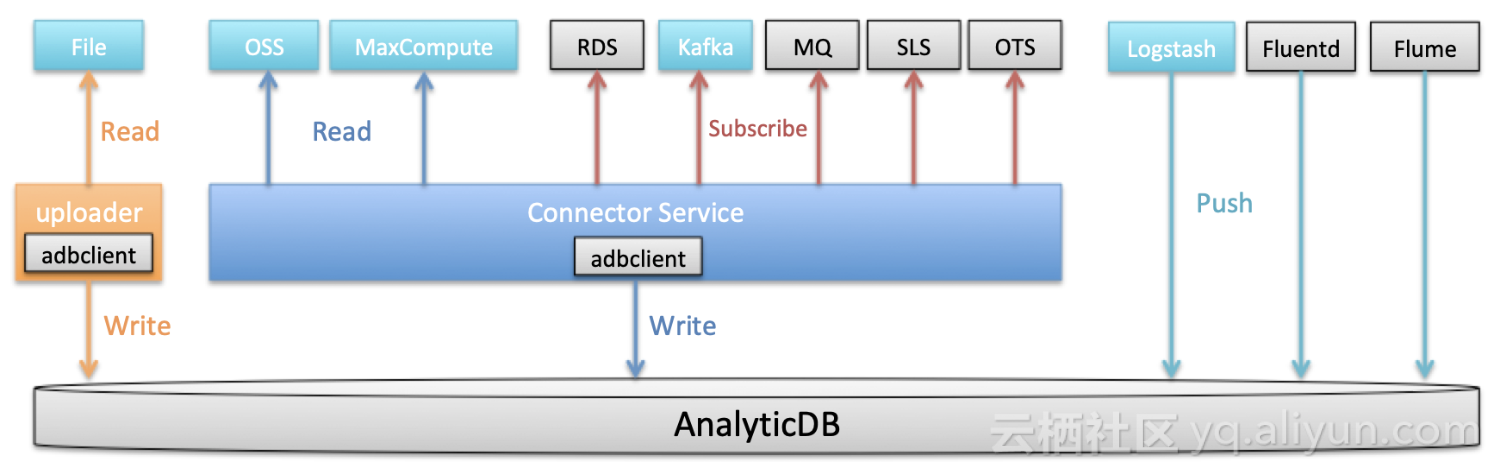
接下来ADB计划基于现有框架接入更多数据源(图中灰色部分)
2.行业云接入
完成金融云、物流云、聚石塔三大行业云接入,使得金融、物流、电商中小企业也能享受到低成本的实时数据分析能力,提升企业精细化数据运营的水平。
望未来
2018年,对AnalyticDB来说注定是非同凡响的一年,在架构演进、稳定性、生态建设以及兼容性上均取得了长足的进步。这一年我们成功入选全球权威IT咨询机构Forrester发布"The Forrester Wave™: CloudData Warehouse,Q4 2018"研究报告的Contenders象限,以及Gartner发布的分析型数据管理平台报告 (Magic Quadrant forData Management Solutions for Analytics),开始进入全球分析市场。
展望未来,我们接下来将继续在分析性能、稳定性、以及产品化(易用性、数据通道、任务管理、可视化等周边生态建设) 上继续做广、做深!ADB旨在帮客户将整个数据分析和价值化从传统的离线分析带到下一代的在线实时分析模式。谢谢一路陪我们成长的客户!感恩,感谢!
回首2018 | 分析型数据库AnalyticDB: 不忘初心 砥砺前行的更多相关文章
- 阿里下一代云分析型数据库AnalyticDB入选Forrester云化数仓象限
前言 近期, 全球权威IT咨询机构Forrester发布"The Forrester Wave: CloudData Warehouse Q4 2018"研究报告,阿里巴巴分析型数 ...
- 阿里巴巴下一代云分析型数据库AnalyticDB入选Forrester Wave™ 云数仓评估报告 解读
前言近期, 全球权威IT咨询机构Forrester发布"The Forrester WaveTM: CloudData Warehouse Q4 2018"研究报告,阿里巴巴分析型 ...
- AnalyticDB - 分析型数据库
https://yq.aliyun.com/teams/31?spm=5176.7937365.1120968.ee1.78505692UL9DhG 分析型数据库(AnalyticDB)是一种高并发低 ...
- 什么是分析型数据库PostgreSQL版
分析型数据库PostgreSQL版(原HybridDB for PostgreSQL)为您提供简单.快速.经济高效的 PB 级云端数据仓库解决方案.分析型数据库PostgreSQL版 兼容 Green ...
- 悠星网络基于阿里云分析型数据库PostgreSQL版的数据实践
说到“大数据”,当下这个词很火,各行各业涉及到数据的,目前都在提大数据,提数据仓库,数据挖掘或者机器学习,但同时另外一个热门的名词也很火,那就是“云”.越来越多的企业都在搭建属于自己的云平台,也有一些 ...
- amazon redshift 分析型数据库特点——本质还是列存储
Amazon Redshift 是一种快速且完全托管的 PB 级数据仓库,使您可以使用现有的商业智能工具经济高效地轻松分析您的所有数据.从最低 0.25 USD 每小时 (不承担任何义务) 直到每年每 ...
- 更强大的实时数仓构建能力!分析型数据库PostgreSQL 6.0新特性解读
阿里云 AnalyticDB for PostgreSQL 为采用MPP架构的分布式集群数据库,完备支持SQL 2003,部分兼容Oracle语法,支持PL/SQL存储过程,触发器,支持标准数据库事务 ...
- (转)操作型数据库的春天:MongoDB 1.5亿美元融资背后的故事
大部分融资都要耗时数月,但非关系式数据库MongoDB仅用3周时间就完成了1.5亿美元的融资.为什么这个进程会这么快,MongoDB CEO Max Schireson在接受采访时说,这是因为投资者看 ...
- runtime实现对象存储型数据库——LHDB
前言 最近在GitHub上看了一份关于基于runtime封装的对象存储型数据库的开源代码,觉得非常值得分享记录一下,在IOS中对数据库的操作一般通过CoreData和SQLite,CoreData 虽 ...
随机推荐
- Unity NGUI 粒子的排序
Unity NGUI系统中是没有对粒子进行排序的,如: 怎么解决这个问题呢? 思路是把粒子的渲染层级,相对于UI组件的层级进行一个偏移. 解决后的效果如下: 代码如下: using System.Co ...
- 2019 IEEEXtreme 13.0 Impact Factor 影响因子
Impact Factor 题目大意 顾名思义,求影响因子.有 n 行 json 数据,第一行为期刊信息,后面为出版商出版的文章信息. 输入输出 点击查看详细 输入: 6 {"publi ...
- Python-docx库的使用
from docx import Document from docx.shared import Inches document = Document() document.add_heading( ...
- JDBC_入门及注入问题
.JDBC基本概念: java database Connectivity java数据库连接,java语言操作数据库 本质: 官方定义的一套操作所有关系型数据库的规则,即接口. 各个数据库厂商实现这 ...
- Ajax.BeginForm 在 Chrome下的问题
项目背景:MVC4 代码: @using (Ajax.BeginForm("Index", "GoingMeter", new AjaxOptions { On ...
- Apache2.2+tomcat7 负载均衡配置
思路及步骤:第一步配置tomcat,第二步配置apache 服务器,第三步添加项目到tomcat中并测试 第一步配置tomcat 1,打开 第一个tomcat,conf文件夹下的server.xml ...
- 《人月神话》读书笔记 PB16110698 第七周(~4.19)
每逢读书笔记上交作业时刻,班级blog页面上总能看到<人月神话>相关的读书笔记,本次软工课邓老师推荐的第一篇读书笔记也是写的<人月神话>,算是对它“耳濡目染”了.本周,我终于抽 ...
- ExecutorService线程池submit的使用
有关线程池ExecutorService,只谈submit的使用 可创建的类型如下: private static ExecutorService pool = Executors.newFixedT ...
- 关于SQL server2017无法连接远程服务器的问题
安装了SQL server2017,能连接上本地数据库,但是连接远程数据库则老报错,什么实例错误之类的,百度找了也是什么打开sql server 服务,什么修改端口1433,什么TCP协议之类的,全部 ...
- 关于DB9一些信号的缩写
https://www.cnblogs.com/CCJVL/archive/2010/02/04/1663565.html 场景:PCB板子与PC通过RS232连接,以下信号的方向相对于PCB板子而言 ...