Scikit-Learn框架
1. Dataset
scikit-learn提供了一些标准数据集(datasets),比如用于分类学习的iris 和 digits 数据集,还有用于归约的boston house prices 数据集。
其使用方式非常简单如下所示:
|
$ python >>> from sklearn import datasets >>> iris = datasets.load_iris() >>> digits = datasets.load_digits() |
每个datasets对象(如iris或digits)都是一个类Dictionary,即是一个Map容器。同时datasets对象都有两个重要属性:
data属性是一个二维的矩阵,每行表示一个测试的样本(samples),每列表示样本的特征值(feature),如下所示:
|
from sklearn import datasets digits = datasets.load_digits() print(digits.data) |
|
输出: [[ 0. 0. 5. …, 0. 0. 0.] [ 0. 0. 0. …, 10. 0. 0.] [ 0. 0. 0. …, 16. 9. 0.] …, [ 0. 0. 1. …, 6. 0. 0.] [ 0. 0. 2. …, 12. 0. 0.] [ 0. 0. 10. …, 12. 1. 0.]] |
target是测试样本的真实标签,如下所示:
|
from sklearn import datasets digits = datasets.load_digits() print(digits.target) |
|
输出: [0 1 2 …, 8 9 8] |
ps:
iris 和 digits 数据集还有一些不同的属性,可以在datasets.load_XXX()函数源码中查看详细内容,如datasets.load_digits()函数内容如下:
|
Def load_digits(n_class=10, return_X_y=False): … return Bunch(data=flat_data, target=target, target_names=np.arange(10), images=images, DESCR=descr) |
- 说明load_digits方法,返回的是Bunch对象,其有data、target、target_names、images和DESCR成员属性。
2. Estimator
Estimator是scikit-learn实现的主要API,可以将其理解为模型(model),即是机器学习中的学习器(learner),通过estimator可以进行分类、回归和聚合等操作。
对于监督学习的任务可以分如下步骤进行:
c) 泛化性能度量:测量模型的泛化能力,即对其评分;
d) 模型进行预测:进行实际预测或应用。
2.1 模型选择
scikit-learn已经实现了非常多机器学习模型,用户只需根据接口参数要求直接创建即可。
如下所示获取一个支持向量机模型:
|
from sklearn import svm clf = svm.SVC(gamma=0.001, C=100.) |
2.2 训练模型
每个scikit-learn模型都提供一个fit(X, y)方法,用于训练模型,其中X参数是一个二维的矩阵,是指模型训练的数据集;y是一个一维数组,是指训练数据集的相应标签。如下所示的使用方式:
|
clf.fit(digits.data[:-1], digits.target[:-1]) |
- digits.data[:-1]:data是一个二维的数组,[:-1]表示传递第一维数组从开始到最后所有内容;
- digits.target[:-1]:target是一个一维数组,[:-1]b表示传递数组所有内容。
2.3 性能度量
每个scikit-learn模型都提供一个score()方法用于估计模型的性能,在训练完模型后,即可使用该方法进行估计性能。
如下所示的程序:
|
from __future__ import print_function from sklearn.datasets import load_iris from sklearn.cross_validation import train_test_split from sklearn.neighbors import KNeighborsClassifier iris = load_iris() X = iris.data y = iris.target #0.获取数据集,并将数据集分为训练数据和测试数据 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4) #1.获取模型 knn = KNeighborsClassifier(n_neighbors=5) #2.训练模型 knn.fit(X_train, y_train) #3.度量性能 print(knn.score(X_test, y_test)) |
|
输出: 0.973684210526 |
2.4 数据预
在训练完模型后,即可进行数据预测。每个scikit-learn模型都提供一个predict(X)方法,其功能是预测指定的数据。其中X是一个二维矩阵,即希望被预测的数据;同时该方法会返回一个一维的数组,每个元素对应矩阵X中每行的预测标签。
如下所示的完整程序:
|
from sklearn import datasets from sklearn import svm digits = datasets.load_digits() clf = svm.SVC(gamma=0.001, C=100.) clf.fit(digits.data[:-1], digits.target[:-1]) y=clf.predict(digits.data[-1:]) print(y) |
|
输出: [8] |
- 最后输出的是一个数组,因为我们进行预测的数据只有一行,所以只输出一个元素。
3. Preprocessing
对于训练数据集和预测数据常需要先进行预处理,使得训练的模型泛化性能更高。其中本小结只简单介绍"特征缩放",更多功能可以参考[1]的预处理章节。
如下使用了preprocessing模块的scale()方法进行数据缩放:
|
from sklearn import preprocessing a = np.array([[10, 2.7, 3.6], [-100, 5, -2], [120, 20, 40]], dtype=np.float64) print(a) #比较在预处理前的数据 print(preprocessing.scale(a)) #比较在预处理后的数据 |
|
输出: [[ 10. 2.7 3.6] [-100. 5. -2. ] [ 120. 20. 40. ]] [[ 0. -0.85170713 -0.55138018] [-1.22474487 -0.55187146 -0.852133 ] [ 1.22474487 1.40357859 1.40351318]] |
4. Cross-validated
scikit-learn的交叉验证功能是通过model_selection模块实现,
4.1 split
通常在(监督)学习实验中,通常会将一部分数据独立出来作为测试集合。scikit-learn的model_selection模块有个辅助函数 train_test_split 可以快速地将数据划分为训练集合与测试结合。
如下将采样到一个训练集合同时保留 40% 的数据用于测试(评估):
|
from sklearn import datasets from sklearn.model_selection import train_test_split #0.获取数据集 iris = datasets.load_iris() print(iris.data.shape, iris.target.shape) #1.进行原始数据集的分离操作 X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=4) #2.分离后的数据集 print(X_train.shape, y_train.shape) print(X_test.shape, y_test.shape) |
|
输出: (150, 4) (150,) (112, 4) (112,) (38, 4) (38,) |
PS:
在model_selection中还有其它多种函数能用于数据集分离操作,可以具体参考[1]的Model selection模块。
4.2 score
Estimator对象已提供一个score函数能够度量模型的性能,但是该方法需要先训练模型,然后测量模型的性能。即将数据集分为两部分,一部分先训练模型;另一部分用于度量模型。
model_selection提供一种cross-validation(交叉验证)的方式来度量模型的性能,这种方式不需要用户手动分离数据集和训练模型。用户直接测量模型的泛化性能,该函数为:cross_val_score。
|
def cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs'): |
- estimator:为创建的模型;
- X:为数据集,为矩阵类型;
- y:为标签数,为向量类型;
- cv:为交叉验证的组数,每组都会产生一个评分结果,为整数类型;
- return:为每组验证的评分,为向量类型;
下面的例子演示了如何评估一个线性支持向量机在 iris 数据集上的精度,通过划分数据,可以连续5次评分:
|
from sklearn import datasets from sklearn import svm from sklearn.model_selection import cross_val_score iris = datasets.load_iris() clf = svm.SVC(kernel='linear', C=1) scores = cross_val_score(clf, iris.data, iris.target, cv=5) print(scores) |
|
输出: [ 0.96666667 1. 0.96666667 0.96666667 1. ] |
通过cross_val_score方法获取的是一个向量,用户可以对向量取平均分数和具有 95% 置信区间,如下所示的分数估计:
|
print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2)) |
|
输出: Accuracy: 0.98 (+/- 0.03) |
4.3 Learning curve
一个模型(Estimator)的泛化能力与它的训练数据集有很直接的关系,若训练数据集样本数少了则会出现"欠拟合"的模型,如图 11所示的第一个图;若训练数据集样本数多了则会出现"过拟合"的模型,如图 11所示的第三个图;如图 11所示的第二个图是数据集刚刚好的情况。
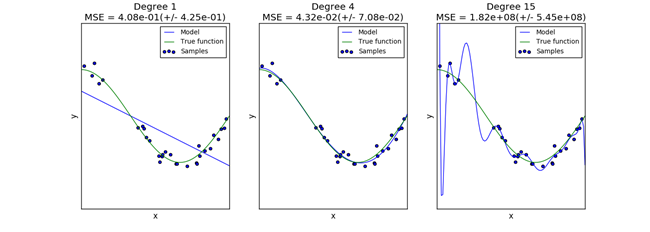
图 11
对于一维的特征向量可以图形化来描述过拟合和欠拟合的情况,若特征向量是多维的,则很难用图形化来评估数据集数量对模型的影响。
model_selection提供一个工具函数learning_curve来帮助用户了解数据集的样本数对模型泛化性能的影响,通过这个函数能够显示不同数量训练样本下模型的训练和验证分数。这里的训练分数是指进行训练模型的数据集来评估模型性能的分数;而验证分数是指在通过测试数据集对评估模型性能的分数。
如图 11所示是一个SVM模型在不同数据集样本数下,训练分数和交叉验证分数的学习曲线,通过两者分数的差异可以评估模型的拟合程度:
- 若出现Training分数和Cross-validation分数都一样低,那说明模型为欠拟合情况;
- 若出现Training分数高,而Cross-validation分数低,则说明模型出现了过拟合情况;
- 而Training分数低,而Cross-validation分数高的情况是不可能出现的情况;
- 只有Training分数和Cross-validation分数一样高才说明模型是拟合适中。
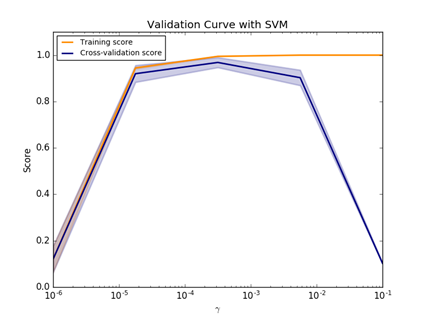
图 12
我们使用learning_curve函数的目标是获取使得Training分数和Cross-validation分数一样高的数据样本数。其中learning_curve函数声明头如下所示:
|
def learning_curve(estimator, X, y, groups=None, train_sizes=np.linspace(0.1, 1.0, 5), cv=None, scoring=None, exploit_incremental_learning=False, n_jobs=1, pre_dispatch="all", verbose=0): |
- estimator:为评估的模型;
- X:为数据集,为矩阵类型;
- y:为标签数,为向量类型;
- train_sizes:训练数据集的大小,为向量类型,每个元素表示进行训练的数据样本数;若元素为浮点类型,则训练数是整个样本集的比例;若元素为整数类型,则训练数就是所指定的固定数量。
- cv:为交叉验证的组数,每组都会产生一个评分结果,为整数类型;
- return:会一个元祖,该元祖有三个元素:
- train_sizes_abs:为每组训练的样本数,其为一个向量类型;
- train_scores:为每组训练数据集的评分,为矩阵类型;
- test_scores:为交叉验证的测试评分,也为矩阵类型。
如下的使用示例:
|
from sklearn.model_selection import learning_curve from sklearn.svm import SVC from sklearn.datasets import load_iris iris = load_iris() X = iris.data y = iris.target train_sizes, train_scores, valid_scores = learning_curve(SVC(kernel='linear'), X, y, train_sizes=[0.40, 0.80, 1], cv=5) print(train_sizes) print(train_scores) print(valid_scores) |
|
输出: [ 48 96 120] [[ 1. 1. 1. 1. 1. ] [ 0.98958333 0.97916667 0.97916667 1. 0.97916667] [ 0.975 0.975 0.99166667 0.98333333 0.98333333]] [[ 0.66666667 0.66666667 0.66666667 0.66666667 0.66666667] [ 0.96666667 1. 0.93333333 0.9 1. ] [ 0.96666667 1. 0.96666667 0.96666667 1. ]] |
PS
scikit-learn的model_selection模块还提供另一个评估函数:Validation curve,该函数功能与learning_curve功能类似,不过Validation_curve函数支持调节不同模型的参数来验证性能。
5. Persistence
scikit-learn提供模型持久化功能,即能够将训练好的模型保存起来,后续可以直接获取模型不需要重复训练,从而节约预测的时间。
Python提供了一个模块 pickle,能够实现模型持久化功能。其使用方式如下所示:
|
from sklearn import svm from sklearn import datasets clf = svm.SVC() iris = datasets.load_iris() X, y = iris.data, iris.target clf.fit(X, y) import pickle s = pickle.dumps(clf) clf2 = pickle.loads(s) y_predit = clf2.predict(X[0:1]) print(y_predit) #预测标签 print(y[0]) #真实标签 |
|
输出: [0] 0 |
在特殊情况下,可以使用joblib代替pickle模块,特别是在大数据集下效率更高,但只有pickle将模型保存到磁盘中,而不是保存为字符串形式,如下所示的使用:
|
from sklearn.externals import joblib joblib.dump(clf, 'filename.pkl') clf = joblib.load('filename.pkl') |
6. 参考文献
[2].scikit-learn中文版网站;
Scikit-Learn框架的更多相关文章
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
- Linear Regression with Scikit Learn
Before you read This is a demo or practice about how to use Simple-Linear-Regression in scikit-lear ...
- Spark技术在京东智能供应链预测的应用——按照业务进行划分,然后利用scikit learn进行单机训练并预测
3.3 Spark在预测核心层的应用 我们使用Spark SQL和Spark RDD相结合的方式来编写程序,对于一般的数据处理,我们使用Spark的方式与其他无异,但是对于模型训练.预测这些需要调用算 ...
- 如何使用scikit—learn处理文本数据
答案在这里:http://www.tuicool.com/articles/U3uiiu http://scikit-learn.org/stable/modules/feature_extracti ...
- Query意图分析:记一次完整的机器学习过程(scikit learn library学习笔记)
所谓学习问题,是指观察由n个样本组成的集合,并根据这些数据来预测未知数据的性质. 学习任务(一个二分类问题): 区分一个普通的互联网检索Query是否具有某个垂直领域的意图.假设现在有一个O2O领域的 ...
随机推荐
- es6的一些个人总结
es6的一些知识点 前言:es6(ECMAscript2015)标准 let.const.var的一些区别 let.const 块级作用域.全局作用域.函数作用域 var 全局作用域.函数作用域 变量 ...
- Spring MVC 文件下载时候 发现IE不支持
@RequestMapping("download") public ResponseEntity<byte[]> download(Long fileKey) thr ...
- Android系统--输入系统(十四)Dispatcher线程情景分析_dispatch前处理
Android系统--输入系统(十四)Dispatcher线程情景分析_dispatch前处理 1. 回顾 我们知道Android输入系统是Reader线程通过驱动程序得到上报的输入事件,还要经过处理 ...
- java 图片质量压缩
/** * 图片质量压缩 * @param file 要压缩的图片文件 * @param input 文件输入流 * @param quality 压缩质量(0-1) * @author ouyang ...
- oracle 小测
01)oracle10i,oracle11g,oracle12c,其它i,g,c什么意思? i(Internet)互联网 g(grid)网格 c(cloud) 云02)sqlplus是什么意思? 是o ...
- MongoDB 系列(一) C# 简易入门封装
之前写过一篇关于MongoDB的封装 发现太过繁琐 于是打算从新写一篇简易版 1:关于MongoDB的安装请自行百度,进行权限认证的时候有一个小坑,3.0之后授权认证方式默认的SCRAM-SHA-1模 ...
- (转)log4j(四)——如何控制不同风格的日志信息的输出?
一:测试环境与log4j(一)——为什么要使用log4j?一样,这里不再重述 1 老规矩,先来个栗子,然后再聊聊感受 import org.apache.log4j.*; //by godtrue p ...
- Spring mybatis源码篇章-SqlSessionFactoryBean
前言:通过实例结合源码的方式解读,其中涉及到的文件来自于博主的Github毕设项目SchoolActivity_WxServer,引用的jar包为mybatis-spring-1.3.0.jar Sp ...
- Python学习记录----IDE安装
摘要: 安装eric5 一 确定python版本 安装的最新版本:python3.3 下载连接:http://www.python.org/getit/ 二 确定pyqt版本 安装的最新版本:PyQt ...
- IEnumerable & IEnumerator
IEnumerable 只有一个方法:IEnumerator GetEnumerator(). INumerable 是集合应该实现的一个接口,这样,就能用 foreach 来遍历这个集合. IEnu ...