HDFS概述(3)————HDFS Federation
本指南概述了HDFS Federation功能以及如何配置和管理联合集群。
当前HDFS背景
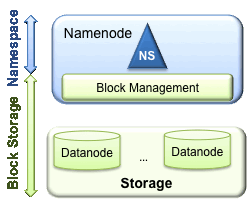
HDFS主要有两层:
1.Namespace
(1)包含目录,文件和块。
(2)它支持所有命名空间相关的文件系统操作,如创建,删除,修改和列出文件和目录。
2.Block Storage,分为两部分:
(1)块管理(在Namenode中执行)通过处理注册和周期性心脏跳动来提供Datanode集群成员资格。处理块报告并维护块的位置。支持块相关操作,如创建,删除,修改和获取块位置。管理复制块下的副本放置,块复制,并删除过度复制的块。
(2)存储 - 由Datanodes通过在本地文件系统上存储块并允许读/写访问来提供。
当前HDFS架构只允许整个集群中存在一个namespace,而该namespace被仅有的一个namenode管理。这个架构使得HDFS非常容易实现,但是,它(见上图)在具体实现过程中会出现一些模糊点,进而导致了很多局限性(下面将要详细说明),当然这些局限性只有在拥有大集群的公司,像baidu,腾讯等出现。
Multiple Namenodes/Namespaces
为了水平扩展名称服务,联合使用多个独立的Namenodes /命名空间。纳米诺斯联盟;Namenodes是独立的,不需要相互协调。Datanodes用作所有Namenodes的块的通用存储。每个Datanode注册到集群中的所有Namenodes。Datanodes发送周期性的心跳和块报告。他们还处理Namenodes的命令。
用户可以使用ViewFs创建个性化的命名空间视图。ViewFs类似于某些Unix / Linux系统中的客户端安装表。

Block Pool
块池是属于单个命名空间的一组块。Datanodes存储集群中所有块池的块。每个块池都是独立管理的。这允许命名空间为新块生成块ID,而不需要与其他命名空间协调。Namenode故障不会阻止Datanode在集群中提供其他的Namenode。
命名空间及其块池一起称为命名空间卷。这是一个独立的管理单位。当Namenode /命名空间被删除时,Datanodes的相应块池被删除。在集群升级期间,每个命名空间卷都将作为一个单元升级。
ClusterID
ClusterID标识符用于标识集群中的所有节点。格式化Namenode时,该标识符将被提供或自动生成。该ID应该用于格式化其他的Namenodes到集群。
主要优点
命名空间可伸缩性 - Federation会添加命名空间水平缩放。通过允许将更多的Namenodes添加到集群中,使用大量小文件的大型部署或部署可以从命名空间缩放中获益。
性能 - 文件系统吞吐量不受单个Namenode的限制。将更多的Namenodes添加到集群可以缩放文件系统的读/写吞吐量。
隔离 - 单个Namenode在多用户环境中不提供隔离。例如,实验应用程序可能会超载Namenode并减缓生产关键应用程序。通过使用多个Namenodes,可以将不同类别的应用程序和用户隔离到不同的命名空间。
Federation 配置
联合配置向后兼容,并允许现有的单个Namenode配置工作,无任何变化。新配置的设计使得集群中的所有节点具有相同的配置,而不需要根据集群中节点的类型部署不同的配置。
联盟添加了一个新的NameServiceID抽象。Namenode及其对应的辅助/备份/检查指针节点都属于NameServiceId。为了支持单个配置文件,Namenode和secondary / backup / checkpointer配置参数后缀为NameServiceID。
配置步骤
步骤1:将dfs.nameservices参数添加到配置中,并使用逗号分隔的NameServiceID进行配置。Datanodes将使用这个来确定集群中的Namenodes。
步骤2:对于每个Namenode和Secondary Namenode / BackupNode / Checkpointer,将以下配置参数添加到相应的NameServiceID到公共配置文件中:
| Daemon | Configuration Parameter |
|---|---|
| Namenode | dfs.namenode.rpc-address dfs.namenode.servicerpc-address dfs.namenode.http-address dfs.namenode.https-address dfs.namenode.keytab.file dfs.namenode.name.dir dfs.namenode.edits.dir dfs.namenode.checkpoint.dirdfs.namenode.checkpoint.edits.dir |
| Secondary Namenode | dfs.namenode.secondary.http-address dfs.secondary.namenode.keytab.file |
| BackupNode | dfs.namenode.backup.address dfs.secondary.namenode.keytab.file |
以下是两个Namenodes的示例配置:
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>nn-host1:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>nn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns1</name>
<value>snn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>nn-host2:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>nn-host2:http-port</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns2</name>
<value>snn-host2:http-port</value>
</property> .... Other common configuration ...
</configuration>
格式化Namenodes
步骤1:使用以下命令格式化Namenode:
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
选择一个唯一的cluster_id,它不会与您的环境中的其他集群冲突。如果未提供cluster_id,则会自动生成唯一的。
步骤2:使用以下命令格式化附加的Namenodes:
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format -clusterId <cluster_id>
请注意,步骤2中的cluster_id必须与步骤1中的cluster_id相同。如果它们不同,则附加的Namenodes不会是联合集群的一部分。
从旧版本升级并配置Federation
较旧的版本只支持一个Namenode。将集群升级到较新版本以启用联合在升级期间,您可以提供如下的ClusterID:
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start namenode -upgrade -clusterId <cluster_ID>
如果未提供cluster_id,则会自动生成。
将新的Namenode添加到现有的HDFS集群
执行以下步骤:
将dfs.nameservices添加到配置中。
使用NameServiceID后缀更新配置。配置键名称已更改后版本0.20。您必须使用新的配置参数名才能使用联合。
将新的Namenode相关配置添加到配置文件。将配置文件传播到集群中的所有节点。启动新的Namenode和Secondary / Backup。通过对集群中的所有Datanode运行以下命令,刷新Datanodes以获取新添加的Namenode:
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsadmin -refreshNamenodes <datanode_host_name>:<datanode_rpc_port>
管理集群
启动和停止集群
要启动集群,请运行以下命令:
[hdfs]$ $HADOOP_HOME/sbin/start-dfs.sh
要停止集群,请运行以下命令:
[hdfs]$ $HADOOP_HOME/sbin/stop-dfs.sh
这些命令可以从HDFS配置可用的任何节点运行。该命令使用配置来确定集群中的Namenode,然后在这些节点上启动Namenode进程。Datanodes在工作文件中指定的节点上启动。该脚本可以用作构建自己的脚本来启动和停止集群的参考。
平衡器
平衡器已被更改为使用多个Namenodes。可以使用以下命令运行Balancer:
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start balancer [-policy <policy>]
policy参数可以是以下任一项:datanode - 这是默认策略。这样可以平衡Datanode级别的存储空间。这与以前版本的平衡策略相似。块池 - 这将平衡块池池级别的存储空间,并在Datanode级别进行平衡。请注意,Balancer仅平衡数据,不平衡命名空间。有关完整的命令用法,请参阅平衡器。
退役
退役类似于以前的版本。需要分解的节点将添加到所有Namenodes的排除文件中。每个Namenode取消其Block Pool。当所有Namenodes完成退役Datanode时,Datanode被视为已退役。
步骤1:要将排除文件分发到所有的Namenodes,请使用以下命令:
[hdfs]$ $HADOOP_HOME/sbin/distribute-exclude.sh <exclude_file>
步骤2:刷新所有的Namenodes以接收新的排除文件:
[hdfs]$ $HADOOP_HOME/sbin/refresh-namenodes.sh
上述命令使用HDFS配置来确定集群中配置的Namenodes,并刷新它们以接收新的排除文件。
群集Web控制台
与Namenode状态网页类似,当使用联合时,可以使用群集Web控制台来监视http:// <any_nn_host:port> /dfsclusterhealth.jsp中的联合群集。群集中的任何Namenode都可用于访问此网页。
群集Web控制台提供以下信息:一个集群摘要,显示了整个集群的文件数,块数,总配置存储容量以及可用和已用存储。包含Namenode列表和一个摘要,其中包含每个Namenode的文件数,块数,缺失块数,实时数和死区数据节点数。它还提供访问每个Namenode的Web UI的链接。Datanodes的退役状态。
http://dongxicheng.org/mapreduce/hdfs-federation-introduction/
HDFS概述(3)————HDFS Federation的更多相关文章
- HDFS概述(5)————HDFS HA
HA With QJM 目标 本指南概述了HDFS高可用性(HA)功能以及如何使用Quorum Journal Manager(QJM)功能配置和管理HA HDFS集群. 本文档假设读者对HDFS集群 ...
- HDFS概述
HDFS概述 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS产出背景及定义 1>.HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配 ...
- [HDFS Manual] CH6 HDFS Federation
HDFS Federation HDFS Federation 1 Background 2.多个namenode/namespace 2.1 关键好处 3 联合配置 3.1 配置 3.2 格式化na ...
- HDFS概述(一)
HDFS概述(一) 1. HDFS产出的背景及定义 1.1 HDFS产生的背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需 ...
- HDFS概述和Shell操作
大数据技术之Hadoop(HDFS) 第一章 HDFS概述 HDFS组成架构 HDFS文件块大小 第二章 HDFS的Shell操作(开发重点) 1.基本语法 bin/hadoop fs 具体命令 ...
- Hadoop(5)-HDFS概述
HDFS产生背景 HDFS优缺点 HDFS组成架构 HDFS文件块大小
- [HDFS Manual] CH3 HDFS Commands Guide
HDFS Commands Guide HDFS Commands Guide 3.1概述 3.2 用户命令 3.2.1 classpath 3.2.2 dfs 3.2.3 envvars 3.2.4 ...
- [HDFS Manual] CH2 HDFS Users Guide
2 HDFS Users Guide 2 HDFS Users Guide 2.1目的 2.2.概述 2.3.先决条件 2.4. Web Interface 2.5. Shell Command 2. ...
- 大数据之路week07--day01(HDFS学习,Java代码操作HDFS,将HDFS文件内容存入到Mysql)
一.HDFS概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 ...
随机推荐
- Thinkjs学习2—数据库的配置
以github登录认证为例,说明如何通过mvc三部分的配合,实现这个功能. 要实现的功能:首页判断用户是否登录,如果没有登录,显示登录界面,用户点击按钮进入github登录验证,并保存用户的信息,登录 ...
- Ext.grid.EditorGridPanel点击单元格添加菜单栏
1.定义菜单栏需要的全局变量 var khbm; var type; 2.新建一个菜单栏 var smenu = new Ext.menu.Menu({ id:"sMenu", i ...
- jmeter后置处理器 JSON Extractor取多个变量值
1.需要获取响应数据的请求右键添加-后置处理器-JSON Extractor 2.如果要获取json响应数据多个值时,设置的Variable names (后续引用变量值的变量名设置)与JSON Pa ...
- MyBatis框架——关系映射(一对多、多对多、多对一查询)
关系映射 一.映射(多)对一.(一)对一的关联关系 1).使用列的别名 ①.若不关联数据表,则可以得到关联对象的id属性 ②.若还希望得到关联对象的其它属性.则必须关联其它的数据表 1.创建表: 员工 ...
- jvm系列 (四) ---强、软、弱、虚引用
java引用 目录 jvm系列(一):jvm内存区域与溢出 jvm系列(二):垃圾收集器与内存分配策略 jvm系列(三):锁的优化 我的博客目录 为什么将引用分为不同的强度 因为我们需要实现这样一种情 ...
- localStorage sessionStorage 和cookie等前端存储方式总结
localStorage sessionStorage 和cookie localStorage localStorage是本地存储的,除非清空本地数据 localStorage不会自动把数据发给服务 ...
- maven 添加memcached.jar配置方法
针对Java项目添加 memcahced 在mvnrepository 找了半天也没找到memcached.jar的配置xml, 由于目前Javamemcached client没有官方的maven ...
- 使用sql语句复制一张表
如何使用sql语句复制一张表? 方法一:第一步:先建一张新表,新表的结构与老表相等. create table newbiao like chengjibiao(老表名); 第二步:将老表中的值复制到 ...
- 分而治之(Work Breakdown Structure, WBS)
不知道大家有没有和我一样的情况,就是想写一篇博客,不知道从何写起,如何组织语言,如何安排这篇博客的要交待的事情的前因后果:如果在写作过程中被打断,又不知道如何重新拾起键盘,从哪里写起."就如 ...
- 201521123104 《Java程序设计》 第12周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多流与文件相关内容. 2. 书面作业 将Student对象(属性:int id, String name,int age,doubl ...