深入浅出数据结构C语言版(20)——快速排序
正如上一篇博文所说,今天我们来讨论一下所谓的“高级排序”——快速排序。首先声明,快速排序是一个典型而又“简单”的分治的递归算法。
递归的威力我们在介绍插入排序时相比已经见识过了:只要我前面的队伍是有序的,我就可以通过向前插队来完成“我的排序”,至于前面的队伍怎么有序……递归实现,我不管。
递归就是如此“简单”的想法:我不管需要的条件怎么来的,反正条件的实现交给“递归的小弟们”去做,只要有基准情形并且向着基准情形“递”去,就可以保证“归”回我一个需要的条件。
不过插入排序虽然体现出了递归的想法,却没有解释什么叫“分治”,其实分治就是分而治之的意思。如果要举个例子的话,恐怕汉诺塔是最为合适的,毕竟大家学习C语言递归时应该都接触过。
汉诺塔的递归解法用大白话来说就是:作为老和尚,我希望自己只用做一件事,就是把最底下的盘子移到C柱去,至于上面的盘子怎么移到B柱,交给小和尚A去做,而我把最底下的盘子移到C柱后,B柱的盘子们怎么移到C柱来,交给小和尚B去做。
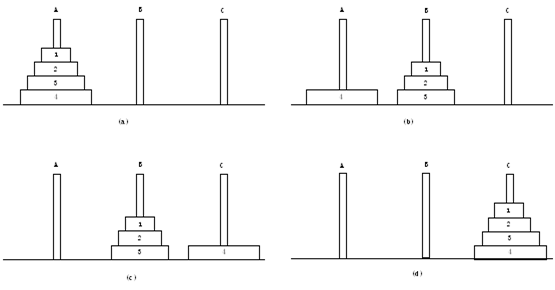
上述汉诺塔的解法就是一种“分治”:把上层盘子移到B柱的任务“分给”A去“治”,而把B柱的盘子们移到C柱的任务又“分给”B去“治”,我只要把底下的盘子移到C柱就行了。需要注意的是,分治不需要什么基准情形,其本质就是将一个大的任务分成两个或多个小的子任务,在子任务完成的情况下去更简单地解决大任务。一般来说分治总是与递归同时出现,即“分治之后递归完成”。
那么,快速排序又是怎样的一个分治、递归呢?我们就用大白话来说说快速排序的想法:
对于数组a,我随便选一个元素a[x]作为枢纽,所有小于枢纽的元素都“站左边去”,所有大于枢纽的元素都“站右边去”(分治),小于枢纽的元素们给我“自行”排好队,大于枢纽的元素们也给我“自行”排好队(递归)。(若小于a[x]的元素共有i个,则它们放在a[0]到a[i-1],而后将a[x]放在a[i]处,大于a[x]的放于a[i+1]到a[size-1]处,i如何确定暂时不管)
既然有递归,那么就必须有基准情形,那么快速排序的基准情形会是什么呢?显然是当数组被“递”得只有3个元素的时候,此时对该数组进行“分治”就会直接完成排序。
我们先来试着给出快速排序的伪代码,调用者调用方式为QuickSort(a,0,size-1):
void QuickSort(int *a, unsigned int left,unsigned int right)
{
//若a[left]到a[right]元素个数大于2,则继续分治、递归
if (left < right&&left != right - )
{
/*伪代码:随机选一个a[x],要求x>=left&&x<=right,作为枢纽*//*伪代码:将a[left]到a[right]中所有小于median的元素置于a[left]到a[i-1]处(i未知)*/
/*伪代码:将a[left]到a[right]中所有大于median的元素置于a[i+1]到a[right]处*/
/*伪代码:将a[x]放在a[i]处*/
QuickSort(a, left, i - );
QuickSort(a, i + , right);
}
//若a[left]到a[right]元素个数恰为2,则直接排序
else if (left == right - )
{
if(a[left]>a[right])
swap(&a[left], &a[right]);
}
//若left==right,则说明只有一个元素,已为“有序”
}
虽然快速排序的想法看似比较简单,但其实现还是有“坑”与“捷径”的,接下来我们就一步一步实现快速排序,看看都有什么“坑”与“捷径”。
回顾快速排序的想法和伪代码,可以看出其第一步就是“随便选一个a[x]”,这看似简单的第一步其实是一个“坑”,因为虽说是随便选,但“选一个a[x]”还是要写出具体代码来的,所以随便选一个枢纽的代码该如何写,就有了三种做法:
1.既然是随便选,那就直接选a[left]好了。
这个做法是最不可取的,原因非常简单,假设数组已经接近有序,那么选取a[left]作为枢纽就很容易导致分治变得“无效”,因为a[left]很可能就是最小的元素。
2.既然要随便选,那就选a[rand()%(right-left+1)]好了
这个做法可取,但是问题出在计算随机数上,计算随机数多少需要一点代价,而且计算随机数对于排序这件事并没有直接帮助。
3.三数中值法
很显然,这就是我们的主角了。相比于方法1,本方法要更加安全,而相比于方法2,本方法要更加廉价并且可以帮助到排序本身。那么三数中值法究竟是怎样的呢?其实就是:令center=(left+right)/2,然后选a[left]、a[center]、a[right]三者的中值作为枢纽。不过在选取中值的同时,我们也获取了这三者的大小信息,因此可以顺便将这三者“放好位置”,所以说相比于方法2,本方法对于排序要更有帮助一些。
三数中值法我们一般用一个单独的函数来实现(其返回值即枢纽的值):
int MedianOf3(int *a, unsigned int left, unsigned int right)
{
unsigned int center = (left + right) / ;//前两个if保证a[left]存储着三数最小值
//最后一个if保证a[center]为三数中值,a[right]为三数最大值
//三个if不仅选出了枢纽,同时将另外两元素的分治工作完成
if (a[left] > a[center])
swap(&a[left],&a[center]);
if (a[left] > a[right])
swap(&a[left],&a[right]);
if (a[center] > a[right])
swap(&a[center],&a[right]); //最后,将枢纽与a[right-1]交换,即“将枢纽放在a[right-1]处”
swap(&a[center],&a[right-]); return a[right-];
}
在三数中值法的代码中,最后我们将枢纽放在了a[right-1]处,这是为什么呢?接下来的讲解可以解释这个做法的原因。
实现了枢纽的选取后,接下来要实现的就是分治的“分”,在上述快速排序的想法中我们说过,我们将小于枢纽的元素们放在a[left]至a[i-1]处,枢纽放在a[i]处,大于枢纽的元素们放在a[i+1]至a[right]处。但是问题来了,怎么确定i的值呢?其实可以肯定的是,在开始分治(与枢纽的比较)前,i是绝对不可能知道的。只有所有元素都与枢纽比较完了才知道i到底是多少。
不过,既然肯定了必须比完才知道,那我们就“比完再知道”呗。具体想法就是:
1.先令枢纽与a[right-1]交换,即将枢纽暂且放在a[right-1]处(在三数中值代码中已经完成此步骤)
2.设变量l_pos从left+1开始递增,直观地说就是“让l_pos从数组左侧开始向右逐个扫描元素”(a[left]已经在三数中值时分治完毕,不需要再扫描)
若l_pos扫描到a[l_pos]>枢纽,则l_pos暂停扫描
3.设变量r_pos从right-2开始递减,直观地说就是“让r_pos从数组右侧开始向左逐个扫描元素”(a[right]已分治,a[right-1]为枢纽)
若r_pos扫描到a[r_pos]<枢纽,则r_pos暂停扫描
4.当l_pos与r_pos均停止时(若元素互异,必然存在此情况),若l_pos<r_pos(直观地说就是它们“尚未碰头”),则交换a[l_pos]与a[r_pos],然后l_pos继续向右扫描,r_pos继续向左扫描。若l_pos>r_pos,则它们“已经碰头”,此时应有l_pos=r_pos+1,即l_pos就在r_pos右边,于是我们彻底停止两者的扫描,并确定了i的值为此时的l_pos。
画图三张,以兹参考
图1,表示一种初始状态:

图2,表示当a[l_pos]>枢纽,a[r_pos]<枢纽,且尚未结束时
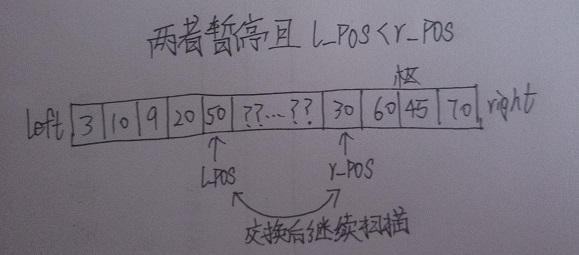
图3,表示结束情况

对应的分治部分代码就是这样:
//初始化l_pos与r_pos
unsigned int l_pos = left + , r_pos = right - ;
//根据三数中值法得出枢纽同时完成两个元素的分配
int median = MedianOf3(a, left, right); //l_pos与r_pos不断向中间扫描
while ()
{
while (a[l_pos] < median)
l_pos++;
while (a[r_pos] > median)
r_pos++;
//l_pos与r_pos均暂停扫描的两种情况
if (l_pos < r_pos)
swap(&a[l_pos], &a[r_pos]);
else
break;
}
//最后记得将枢纽交换至正确位置
swap(&a[l_pos], &a[right - ]);
解决了选取枢纽与分治,快速排序就算是完成了,从之前所给的快速排序伪代码就可以看出这一点,伪代码中没有解决的就是这两个地方:
void QuickSort(int *a, unsigned int left,unsigned int right)
{
if (left < right&&left != right - )
{
//选枢纽:
//随机选一个a[x],要求x>=left&&x<=right,作为枢纽median //分治:
//将a[left]到a[right]中所有小于median的元素置于a[left]到a[i-1]处
//将a[left]到a[right]中所有大于median的元素置于a[i+1]到a[right]处
//将a[x]放在a[i]处 //递归
QuickSort(a, left, i - );
QuickSort(a, i + , right);
}
else if (left == right - )
{
if(a[left]>a[right])
swap(&a[left], &a[right]);
}
}
将伪代码中未完成部分填上,就有了如下快速排序:
void QuickSort(int *a, unsigned int left, unsigned int right)
{
//若a[left]到a[right]元素个数大于2,则继续分治、递归
if (left < right&&left != right - )
{
/*——————选枢纽——————*/
int median = MedianOf3(a, left, right);//根据三数中值法得出枢纽同时完成两个元素的分配 /*——————分治——————*/
unsigned int l_pos = left + , r_pos = right - ;//初始化l_pos与r_pos
//l_pos与r_pos不断向中间扫描
while ()
{
while (a[l_pos] < median)
l_pos++;
while (a[r_pos] > median)
r_pos++;
//l_pos与r_pos均暂停扫描的两种情况
if (l_pos < r_pos)
swap(&a[l_pos], &a[r_pos]);
else
break;
}
//最后记得将枢纽交换至正确位置
swap(&a[l_pos], &a[right - ]); /*——————递归——————*/
QuickSort(a, left, l_pos - );
QuickSort(a, l_pos + , right);
}
//若a[left]到a[right]元素个数恰为2,则直接排序
else if (left == right - )
{
if (a[left]>a[right])
swap(&a[left], &a[right]);
}
//若left==right,则说明只有一个元素,已为“有序”
}
但是请注意!上述代码是有问题的,这是不容易察觉的第二个坑!坑在何处呢?让我们揪出上述代码的一部分:
while ()
{
while (a[l_pos] < median)
l_pos++;
while (a[r_pos] > median)
r_pos++;
//l_pos与r_pos均暂停扫描的两种情况
if (l_pos < r_pos)
swap(&a[l_pos], &a[r_pos]);
else
break;
}
如果数组的元素一定互异,那么这一部分代码没有问题,但是如果数组元素存在相同,那么这部分代码就可能出现问题。
假设l_pos暂停了扫描,原因是a[l_pos]==median,而且r_pos也暂停了扫描并且也是因为a[r_pos]==median,那么单纯交换a[l_pos]与a[r_pos]只会使循环陷入死循环,因为两个子循环的判断条件将永远为false,从而l_pos与r_pos一直不变。
那么该如何解决这个问题呢?最直接的办法就是增加新的判断,判断a[l_pos]与a[r_pos]是否都与median相等,如果是则不交换两者,改为令l_pos++和r_pos--。
但是实际上我们存在一个解决此问题的捷径,这个捷径的思路解说起来稍显麻烦:既然问题是出在交换后l_pos与r_pos不会变化(递增与递减),那就在子循环处改为先变化再比较不就好了:
while ()
{
while (a[++l_pos] < median)
/*Do nothing*/;
while (a[--r_pos] > median)
/*Do nothing*/;
if (l_pos < r_pos)
swap(&a[l_pos], &a[r_pos]);
else
break;
}
同时,因为l_pos与r_pos都变成了“先变化再比较”,所以两者的初始值也要改变为:
unsigned int l_pos = left, r_pos = right - ;
于是,完整的快速排序就实现好了,代码如下:
void QSort(int *a, unsigned int left, unsigned int right)
{
if (left < right&&left != right - )
{
unsigned int l_pos = left, r_pos = right - ;
int median = MedianOf3(a, left, right);
int temp;
while ()
{
while (a[++l_pos] < median);
while (a[--r_pos] > median);
if (l_pos < r_pos)
{
temp = a[l_pos];
a[l_pos] = a[r_pos];
a[r_pos] = temp;
}
else
break;
}
temp = a[l_pos];
a[l_pos] = a[right - ];
a[right - ] = temp;
QSort(a, left, l_pos - );
QSort(a, l_pos + , right);
}
else if (left == right - && a[left] > a[right])
{
int temp = a[left];
a[left] = a[right];
a[right] = temp;
}
}
为了方便调用者,我们可以实现一个简单的“接口”:
void QuickSort(int *a, unsigned int size)
{
return QSort(a, , size - );
}
对于快速排序,还要注意的一点是当数组的大小N很小时,快速排序是不如插入排序的,并且需要注意的是由于快速排序的递归,必然会出现“小数组”。因此实际实现快速排序时往往选择对小数组执行一个插入排序。即:
void QSort(int *a, unsigned int left, unsigned int right)
{
if (left < right-N)
{
//此部分代码略
}
else
{
InsertionSort(a,right-left+);
}
}
至此,快速排序实现完毕。
接下来我们试着分析一下快速排序的时间复杂度。这一部分我们将分为两个小部分:快速排序的最坏情况,快速排序的最好情况。
首先,为了方便分析,我们假设快速排序的枢纽选择是完全随机的。对于大小为N的数组,快速排序耗时设为T(N),则T(1)=1。于是,T(N)=T(i)+T(N-i-1)+c*N,其中i为小于枢纽的元素个数,c为未知常数,c*N代表分治阶段耗费的线性时间。
那么,快速排序的最坏情况就是每一次选取的枢纽都是最小的元素,此时i=0,上述公式变为:
T(N)=T(N-1)+c*N,递推此公式可得
T(N-1)=T(N-2)+c*(N-1)
T(N-2)=T(N-3)+c*(N-2)
……
T(2)=T(1)+c*2
将上述公式左侧与右侧均全部相加,得:
T(N)+T(N-1)+T(N-2)+……+T(2) = T(N-1)+T(N-2)+……T(2)+T(1)+c*(2+3+4+5+……+N)
化简可得:
T(N)=T(1)+c*(2+3+4+……+N)=1+c*(2+3+4+……+N)=O(N2)
也就是我们在上一篇博文提到的,快速排序最坏情况为O(N2)
不难看出,选择枢纽时不论是完全随机还是三数中值,快速排序都不容易出现这样的最坏情况。
接下来我们看看快速排序的最好情况。快速排序的最好情况显然就是每次枢纽都选择了整个剩余数组的中间值,为了简化推导,我们假定递归时将枢纽本身也带进去,并且N为2的幂。从而
T(N)=2*T(N/2)+c*N
两边同时除以N,得:
T(N)/N=T(N/2)/(N/2)+c,递推此公式可得:
T(N/2)/(N/2)=T(N/4)/(N/4)+c
T(N/4)/(N/4)=T(N/8)/T(N/8)+c
……
T(2)/2=T(1)/1+c
将上述公式左侧与右侧均全部相加, 得:
T(N)/N+T(N/2)/(N/2)+……+T(2)/2=T(N/2)/(N/2)+……T(1)/1+c*logN
化简,得:
T(N)/N=T(1)/1+c*logN,即T(N)=N*c*logN=O(N*logN)。所以快速排序的最好情况就是O(N*logN)。
快速排序的平均情况分析的公式繁杂,且化简需要高深的数学,此处只给出基本思路:既然枢纽是随机的,那么小于枢纽的元素个数i就也是随机位于[0,N-1],那么i的平均值就应该是(0+1+2+……+(N-1))/N,同理大于枢纽的元素个数平均值为(0+1+2+……+(N-1))/N,基于这两点,T(N)=2*(0+1+2+……+(N-1))/N+c*N,依据此公式进行递推、相加、化简,可以得出平均时间为O(N*logN)
对于快速排序的分析并不是只有本文所提,比如在l_pos于r_pos扫描的过程中,我们为什么选择在a[l_pos]或a[r_pos]等于median时停下,而不是继续扫描呢?这是有原因的,简述就是:防止极端情况下l_pos及r_pos越界,同时使分得的两个子数组大小更加平衡。但是更多的分析本文就不做介绍了,时间有限╮(╯_╰)╭
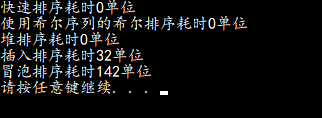
最后,对于大小为20万的随机整数数组,我们提过的“主流”排序算法的简单比较结果如下(仅供参考):
深入浅出数据结构C语言版(20)——快速排序的更多相关文章
- 深入浅出数据结构C语言版(5)——链表的操作
上一次我们从什么是表一直讲到了链表该怎么实现的想法上:http://www.cnblogs.com/mm93/p/6574912.html 而这一次我们就要实现所说的承诺,即实现链表应有的操作(至于游 ...
- 深入浅出数据结构C语言版(1)——什么是数据结构及算法
在很多数据结构相关的书籍,尤其是中文书籍中,常常把数据结构与算法"混合"起来讲,导致很多人初学时对于"数据结构"这个词的意思把握不准,从而降低了学习兴趣和学习信 ...
- 深入浅出数据结构C语言版(8)——后缀表达式、栈与四则运算计算器
在深入浅出数据结构(7)的末尾,我们提到了栈可以用于实现计算器,并且我们给出了存储表达式的数据结构(结构体及该结构体组成的数组),如下: //SIZE用于多个场合,如栈的大小.表达式数组的大小 #de ...
- 深入浅出数据结构C语言版(14)——散列表
我们知道,由于二叉树的特性(完美情况下每次比较可以排除一半数据),对其进行查找算是比较快的了,时间复杂度为O(logN).但是,是否存在支持时间复杂度为常数级别的查找的数据结构呢?答案是存在,那就是散 ...
- 深入浅出数据结构C语言版(19)——堆排序
在介绍优先队列的博文中,我们提到了数据结构二叉堆,并且说明了二叉堆的一个特殊用途--排序,同时给出了其时间复杂度O(N*logN).这个时间界是目前我们看到最好的(使用Sedgewick序列的希尔排序 ...
- 深入浅出数据结构C语言版(4)——表与链表
在我们谈论本文具体内容之前,我们首先要说明一些事情.在现实生活中我们所说的"表"往往是二维的,比如课程表,就有行和列,成绩表也是有行和列.但是在数据结构,或者说我们本文讨论的范围内 ...
- 深入浅出数据结构C语言版(3)——递归简论
相信学习过C语言的读者都已经接触过递归(不论是谭浩强的C程序设计还是C Primer Plus都有递归程序),本文就是对递归的基本原则进行简要介绍.首先,我们写一个基本的递归函数作为例子: int ...
- 深入浅出数据结构C语言版(2)——简要讨论算法的时间复杂度
所谓算法的"时间复杂度",你可以将其理解为算法"要花费的时间量".比如说,让你用抹布(看成算法吧--)将家里完完全全打扫一遍大概要5个小时,那么你用抹布打扫家里 ...
- 深入浅出数据结构C语言版(6)——游标数组及其实现
在前两次博文中,我们由表讲到数组,然后又由数组的缺陷提出了指针式链表(即http://www.cnblogs.com/mm93/p/6576765.html中讲解的带有next指针的链表).但是指针式 ...
随机推荐
- node中package.json全方面解析
Name 必须字段. 小提示: 不要在name中包含js, node字样: 这个名字最终会是URL的一部分,命令行的参数,目录名,所以不能以点号或下划线开头: 这个名字可能在require()方法中被 ...
- Java入门(4)——常见的String方法
考虑到API当中的解释,新手可能有点看不懂(我刚开始就是不太看得懂).最好的学习方法当然是是自己一个一个去试一遍,然后就可以加深印象. 然后, 这是我当初学习的时候用自己的大白话做的笔记.现在查阅的话 ...
- Spring详解(一)------概述
本系列教程我们将对 Spring 进行详解的介绍,相信你在看完后一定能够有所收获. 1.什么是 Spring ? Spring是一个开源框架,Spring是于2003 年兴起的一个轻量级的Java 开 ...
- vue.js拓展篇(8):测试开发与调试
内容 第15章:测试开发与调试 任何实际项目的开发,除了功能性代码的完成,规范的开发流程和严谨的测试都是不可或缺的.合理使用工具将事半功倍. 1.ESLint ESLint是Lint语法检查工具,避免 ...
- vue.js基础知识篇(5):过渡、Method和Vue实例方法
第8章:过渡 1.CSS过渡 2.JavaScript过渡 3.渐进过渡 第9章:method Vue.js的事件一般通过v-on指令配置在HTML中,虽然也可以在js的代码中使用原生的addEven ...
- 安装lvs过程
linux我是最小化安装的mini,安装完成后搭建本地yum,首先安装Development Tools开发工具组 1)在各服务器上修改主机名: [root@LVS1 ~]# hostname LVS ...
- ScrollView嵌套ListView只显示一行
错误描述 ScrollView嵌套ListView中导致ListView高度计算不正确,只显示一行. 解决方法 重写ListView的onMeasure方法,代码如下. @Override publi ...
- 设置Linux环境变量的方法与区别(Ubuntu)
设置 Linux 环境变量可以通过 export 实现,也可以通过修改几个文件来实现,有必要弄清楚这两种方法以及这几个文件的区别. 通过文件设置 Linux 环境变量 首先是设置全局环境变量, ...
- 使用DOM解析XML文件,、读取xml文件、保存xml、增加节点、修改节点属性、删除节点
使用的xml文件 <?xml version="1.0" encoding="GB2312" ?> <PhoneInfo> <Br ...
- 【C#多线程编程实战笔记】二、 线程同步
使用Mutex类-互斥锁 owned为true,互斥锁的初始状态就是被主线程所获取,否则处于未获取状态 name为定义的互斥锁名称,在整个操作系统只有一个命名未CSharpThreadingCookb ...