Intel Core Microarchitecture Pipeline
Intel微处理器近20年从Pentium发展到Skylake,得益于制作工艺上的巨大发展,处理器的性能得到了非常大的增强,功能模块增多,不过其指令处理pipeline的主干部分算不上有特别大的变化,更多的是为了提高指令的处理速度添加一些模块以及各模块的增强与优化。
本文会以Intel Core微处理器架构为例去了解Intel微处理器pipeline的各个功能模块。
Core架构概览
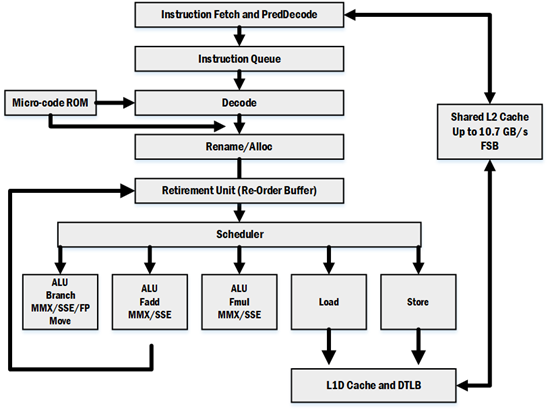
上图以指令的处理流程(pipeline)的方式对Core微处理器的架构进行了划分,指令通过各个功能模块最终实现指令的处理。需要注意的是,上图只是描画出pipeline的大致部分,本文也仅仅是对上图中的这些模块展开讨论,另外的某些模块或者细节会在以后的文章中讲述。
指令处理的pipeline如果按照指令的in-order/out-of-order的方式进行划分的话可以分成三部分:
- 指令的抓取以及解码是in-order的。指令流按照原本的顺序被抓取,然后送到解码器进行解码,这部分可以称为前端(Front-End)。
- 指令的执行是out-of-order的。指令在解码得到μops之后,会经过Renamer以及Reservation Station从而使μops支持out-of-order,然后经由Scheduler分发到各个Execution Unit执行。
- 指令的休止是in-order的。指令执行完成后,在Re-Order Buffer内对执行结果重新排序,使得执行结果顺序输出。
Front End
Instruction Fetch Unit
指令获取单元包含以下部件:instruction translation lookaside buffer(ITLB),instruction prefetcher,instruction cache,predecode unit。
其中ITLB用于存放虚拟地址向物理地址的转换表,目的是免去每次从内存查看页表的操作;instruction prefecher用于抓取接下来可能会执行的指令,instruction cache用于存储接下来要执行的指令;predecode unit用于指令的初步解码。
Instruction Cache and ITLB
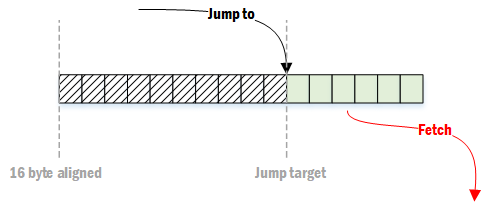
指令是以16字节对齐的方式取近CPU的,在读取指令时,会通过ITLB得到正确的物理地址,从内存中把指令读取到instruction cache以及instruction prefetch buffer。一旦将要执行的指令在cache中,则会把该16字节的指令发送到predecoder。一般来说,程序的指令平均长度为4字节,也就是说平均每一次可以抓取4条指令。
如果一段目标代码的开头不是16字节对齐的,则会导致fetch效率的下降
如果接下来的指令为跳转分支,则可能会造成解码效率的下降
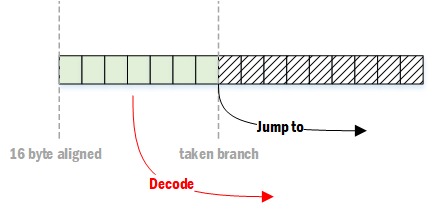
在一般的代码中,约每10条指令会出现一个分支,也就是说平均每3~4个时钟周期就会出现一次上述的情况。
不过,通常前端不会成为指令处理的瓶颈,因为pipeline的其他某些部分的效率无法达到每个时钟周期处理4条指令的程度,除非程序中有大量throughput非常高的指令,并且这些指令之间能很好地搭配出几条依赖链(如采用SSE2的音视频处理内核)。
Instruction PreDecode
指令预解码单元会接收到从instruction cache或者instruction prefetch buffer发出的16字节,并执行以下任务:
- 解码出指令的长度
- 解码出指令的所有前缀
- 为指令打上标记(如“是分支 / is branch”)
预解码单元每个时钟周期可以向instruction queue写入6条指令。预解码的后面获取的指令只能等待前面获取的指令解码完毕后才能开始解码。例如,某一次获取的16字节中含有7条指令,那么预解码单元会在第一个时钟周期写入6条指令,第二个时钟周期写入1条指令,而后续获取的指令会在第三个时钟周期进行解码,如此一来,前两个时钟周期平均解码的指令为3.5条。
另外,有两个前缀会导致解码变慢。这两个前缀会动态地改变指令的长度,被称为length changing prefixes(LCPs)。
- 66H Operand-Size Prefix 这个前缀会改变操作数的长度。比如在32位处理器中,默认操作数长度为32位,也就是说所用到的寄存器为EAX、EBX等(mov eax, 0xef)。如果使用了AX、BX等寄存器(mov ax, 0xef),此时操作数长度为16位,则会在指令前面添加前缀66H。
- 67H Address-Size Prefix 这个前缀会改变地址的位数。比如在32位处理器中,默认的地址为32位(mov eax, [edx]),如果某条指令希望用16位进行寻址的话(mov eax, [dx]),则会在指令前面添加前缀67H。
这两个前缀在IA-32系列之前的处理器上会导致predecode的延迟,不过在新系列的处理器上只有特定情况才会有副作用,比如说工作在保护模式的处理器,具体情况请自行查看资料。
Instruction Queue
Instruction Queue位于predecode unit与decoder之间,他最多可以存储18条指令,并且每个时钟周期可以向decoder发送5条指令,5条指令中只能包含1条macro-fusion指令。
Instruction Queue(IQ)最大的作用就是侦测并存储循环指令。IQ内提供了能存储小于18条指令的loop cache,如果loop stream detector(LSD)侦测到IQ内的指令为循环内的指令,则会把这些指令锁定下来,那么在循环期间就可以直接从IQ中获取指令到解码器,从而省去前面fetch以及predecode等工作。如此一来能很好地提高效率以及降低功耗。
总结来说LSD可以提供以下便利:
- 不会因为循环的跳转而影响效率。
- 不会因为循环的第一条指令不对齐而影响效率。
- 降低前端的功耗,因为在循环期间instruction cache,predecode unit等可以处于空闲状态。
不过如果想很好地利用这个功能的话就需要把循环内指令的大小控制在一定范围内。
※后续的处理器在decoder与execution unit之间添加了Instruction Decoder Queue,LSD也移动到了这个位置。
Instruction Decode
Core微处理器中包含了四个指令解码器。其中第一个解码器Decoder 0的功能最强,可以解码最高为4 μops的指令,其余的三个解码器只能解码单μop的指令。
尽管解码器存在上述分工,不过得益于某些改进策略(micro-fusion,macro-fusion,Stack Pointer Tracker),因此很多在execution unit时会被拆分成多个μops分别执行的指令在decoder阶段都会被当成单一的μop,如此一来那三个只能解码单μop的解码器就可以执行更多的解码任务,指令也没必要按照4-1-1-1的方式进行配置了。
Micro-code sequencer ROM (MSROM)
MSROM用于存储复杂指令的μops。对于那些大于4μops或者相当复杂(不常用)的指令,是无法通过decoder进行解码的,此时decoder会请求MSROM的协助,MSROM收到请求后会传输与指令对应的μops到Decode Pipeline/Decoded ICache上。
使用MSROM指令会导致解码时间出现较大的增加,因此应尽量避免使用MSROM指令。比如,对于PUSH与CALL指令来说,如果操作数为内存,则该指令的解码需要寻求MSROM的协助,但是如果操作数为寄存器,则可以由decoder直接解码。因此应当先把数据从内存mov进寄存器,再执行PUSH或CALL的操作。
| Instruction from MSROM | Recommendation Replacement Instructions |
| CALL m16/m32/m64 | Load + CALL reg |
| PUSH m16/m32/m64 | Store + RSP update |
| (I)MUL r/m16 (Result DX:AX) | Use (I)MUL r16, r/m16 extended precision not required, or (I)MUL r32, r/m32 |
| (I)MUL r/m32 (Result EDX:EAX) | Use (I)MUL r32/m32 if extended precision not required, or (I)MUL r64, r/m64 |
| (I)MUL r/m64 (Result RDX:RAX) | Use (I)MUL r64, r/m64 if extended precision not required |
其他如DIV,CPUID,AESDEC等指令也是MSROM指令,MSROM指令一般都会有较高的latency以及1/throughput,具体哪条指令为MSROM指令以及相关数据还请查看Intel 64 and IA-32 Architectures Optimization Reference Manual。
The Out-of-Order Engine
散序引擎(Out-of-Order Engine)能大大提高指令的执行效率。散序引擎通过侦测各指令间的依赖关系,使得指令形成各不相干的依赖链,那么某条依赖链上的指令就能在其它依赖链等待资源时进入execution unit执行,实现了对处理器的充分利用。正是这种基于资源的处理方式使得指令打破了其原本的处理顺序,故称为Out-of-Order。散序引擎包含三个主要部分。
Renamer/Allocator
指令在前端经过解码后会得到μops队列,Renamer/Allocator对队列中的μop执行以下操作:
- 把μops相关的逻辑寄存器重命名为物理寄存器,用Register alias table(RAT)维护逻辑寄存器与物理寄存器之间的映射关系。
- 为μops开辟资源,如load或store所需的临时buffer。
- 把μops与合适的端口进行绑定。
其中寄存器重命名与Out-of-Order尤为相关。如果发现μops对整个寄存器的写入操作,Renamer会为逻辑寄存器映射到新的物理寄存器,如此一来就切断了依赖链,为Out-of-Order execution打下了基础。
Scheduler (Reservations station)
Scheduler(RS)的目的是把μops分配到相应的execution port。为了实现这个目的,RS必须具备识别μop是否ready的能力。当μop的所有的源(source)都就位时则表明该μop为ready,可以让RS调度到execution unit执行。RS会根据Issue Port的可用情况以及已就绪μops的优先级来对μop进行调度。
RS会为每个进入其中的μop开辟一项,用于存储正在等待资源的μop,Core微处理器中的RS可以容纳32项μops。
在scheduler之前的μops的顺序都是in-order的,经过scheduler之后μops变为了out-of-order。
Retirement (Reorder buffer)
Reorder buffer(ROB)主要用于记录μops的状态以及存储EU执行完成后返回的结果,然后按照in-order的顺序把执行结果写回寄存器,使得在用户层看来指令在以in-order的顺序执行,in-order写回的这一步被称为retirement。Core微处理器一共可以容纳96项μops。
Out-of-Order Engine在Sandy Bridge微处理器后进行了大幅度的改变,相关细节请查看Re-Order Buffer。
Execution Units
在RS的指令就绪后,RS会通过issue port(IP)把指令调度到相应的EU执行,Core微处理器一共有6个IP,也就是说一次性最多可以发出6个μops。在执行完成指令后,除了少数指令之外(如store),一般都需要把执行结果写回寄存器(或者说ROB),经由writeback port(WP)进行写回,Core微处理器一共有4个WP。
下面的表为Core微处理器(06-0FH)以及Enhanced Core微处理器(06-17H)的port及其目的端的EU的功能以及Latency、Throughout。
| Executable Operation | Latency, Throughput | Comment1 | |
| Signature=06_0FH | Signature=06_17H | ||
| Interger ALU Interger SIMD ALU FP/SIMD/SSE2 Move and Logic |
1, 1 1, 1 1, 1 |
1, 1 1, 1 1, 1 |
Includes 64-bit mode integer MUL; Issue port 0; Writeback Port 0; |
| Single-precision(SP) FP MUL Double-precision FP MUL |
4, 1 5, 1 |
4, 1 5, 1 |
Issue port 0;Writeback port 0 |
| FP MUL (x87) FP Shuffle DIV/SQRT |
5, 2 1, 1 -, -8 |
5, 2 1, 1 -, -8 |
Issue port 0;Writeback port 0 FP shuffle does not handle QW shuffle |
| Integer ALU Integer SIMD ALU FP/SIMD/SSE2 Move and Logic |
1, 1 1, 1 1, 1 |
1, 1 1, 1 1, 1 |
Excludes 64-bit mode integer MUL; Issue port 1;Writeback port 1; |
| FP ADD QW Shuffle |
3, 1 1, 12 |
3, 1 1, 13 |
Issue port 1; Writeback port 1; |
| Integer loads FP loads |
3, 1 4, 1 |
3, 1 4, 1 |
Issue port 2; Writeback port 2; |
| Store address4 | 3, 1 | 3, 1 | Issue port 3; |
| Store data5 | Issue port 4; | ||
| Integer ALU Integer SIMD ALU FP/SIMD/SSE2 Move and Logic |
1, 1 1, 1 1, 1 |
1, 1 1, 1 1, 1 |
Issue port 5; Writeback port 5 |
| QW shuffles 128-bit Shuffle/Pack/Unpack |
1, 12 2-4, 2-46 |
1, 13 1-3, 17 |
Issue port 5; Writeback port 5 |
NOTES:
- 如果向同一个port调度不同latency的操作,有可能会导致writeback bus冲突,因而影响性能。例如向port 1:clock 0发出的操作的latency为2,clock 1发出的操作的latency为1,那么在clock 2时两者都需要writeback port 1进行写回,此时必然会导致其中的一个操作延迟写回。
- 当Core执行128-bit shuffle操作时会有较长的latency并降低throughput。
- Enhanced Core独立出来了128-bit shuffle操作,在port 5,并且提升了执行速度。
- 为store的写回做准备,相关的地址操作。
- 为store的写回做准备,相关的数据操作,数据写回内存与cache、memory相关,其中涉及到一些处理逻辑,后面分析。
- Core中的128-bit Shuffle/Pack/Unpack等操作用的都是QW shuffle单元。
- Enhanced Core中128-bit Shuffle/Pack/Unpack等操作有独立的128-bit单元。
- DIV/SQRT等操作的latency与throughput是数据相关的。通俗地说就是,简单的DIV/SQRT的latency会较短,复杂的DIV/SQRT的latency则较长。
Advanced Memory Access
Intel处理器一般都含有多级data cache。Core微处理器就含有两级data cache,其中每个核心内部的为L1 data cache、两个核心共用外部的L2 cache。
一个核心内部包含的数据访问相关部分有:
- L1 data cache,也被称为data cache unit(DCU),它可以同时处理多个cache misses以及stores/loads;能维护cache coherency(cache一致性)。cache line为64-byte。
- Data translation lookaside buffer(DTLB),即缓存在核心内的虚拟物理地址转换表。Core的实现分为分两层:DTLB0、DTLB1。DTBL0用于loads,DTLB1用于stores以及作为DTBL0的loads misses候补。
- Page miss handler(PMH),当所请求虚拟地址转换的页表不在TLB时,会由PMH进行处理。
- Memory ordering buffer(MOB),由load buffer与store buffer组成,用于支持loads与stores的out of order处理、预测(speculative)处理。
Load Buffer and Store Buffer
Core微处理器的load unit以及store unit一个时钟周期可以从DCU中读取或者写入最多128-bit。DCU以及EU之间有load buffer与store buffer,用于暂存load与store指令访问的数据。
- load指令在Allocator期间,会被分配一个load buffer,在load EU执行期间把数据从DCU读入load buffer,然后通过writeback port把数据写回ROB,在retirement时会把数据从ROB写入register。
- store指令在Allocator期间,会被分配一个store buffer,在store EU执行期间把目标内存地址以及数据写入store buffer,在retirement后会把数据写入DCU。
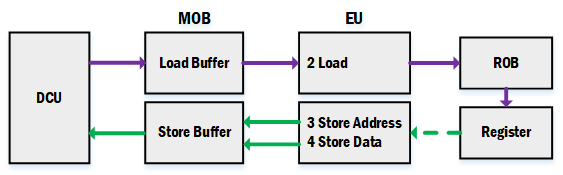
内存数据的存储相比其它普通的指令来说,运行时间受到更多因素的影响,如cache miss、总线忙、数据不对齐等,而加入load buffer以及store buffer能有效降低读写内存时受到的负面影响,把数据留在离EU更近的地方,使得对内存数据的处理显得更为本地化,即对EU来说,所要处理的数据都更容易获取,割离前后端(读写内存)的影响(in-flight)。
Out of Order
微处理器中相关的内存读写操作是out of order的,不过out of order的内存操作需要遵循以下规则:
- 对于老的微处理器来说(如P6),在一个store的地址没搞清楚之前,它后面的loads都不能提到该store之前,等到地址确定后才能做出抉择。不过新系列的处理器可以通过预测来决定load是否可以提前,请参考下面的Memory Disambiguation。
- 如果访问的是同一个地址,load不能提到位于它前面的store之前。
- 对于老的微处理器来说(如P6),stores之间的顺序不能调换,比较新的微处理器似乎可以?
如下图所示:
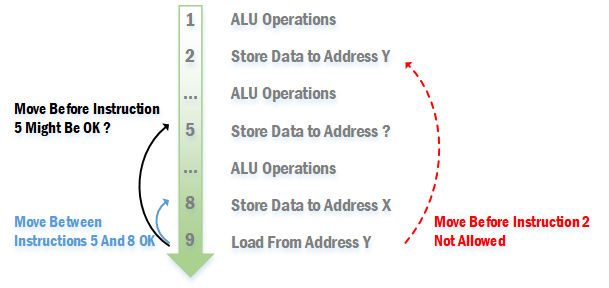
Speculate
由于指令的执行分为fetch、decode、execution、retirement等多个阶段,不同的微处理器细分开来可以有十多到二十多级的pipeline。执行到分支(Branch)的时候,按理来说是需要等条件的最终执行结果出来才能知道接下来走那个分支,不过如此一来,在等待执行结果的途中pipeline中的各部分器件会处于空闲状态,导致资源浪费以及指令执行效率不高。
解决方法就是微处理器会预测接下来会走哪个分支,微处理器把该分支的指令获取并处理。不过由于该分支只是预测分支,实际并不一定会走该分支,因此分支内的指令不应该执行retirement步骤,直到确定了会走该分支。如果实际上不走预测分支,则需要把预测分支清空,重新执行另一分支。
Load的retirement是把数据从ROB写入register,而Store的retirement是把数据从store buffer写入DCU。预测分支内的Load与Store就不会执行这些步骤,直到确定会走该预测分支。
Memory Disambiguation
前面在讨论Out of Order的内存访问时,说到在老的微处理器中,如果指令Store的地址未知时,位于其后的Load指令必须等到计算出该Store的地址后才能判断Load是否能提前,不过新的处理器采用了Memory Disambiguation(MD)技术,使得可以在不知道Store地址的情况下决定是否提前执行Load。
我们先来看看Load提前会得到怎么样的好处
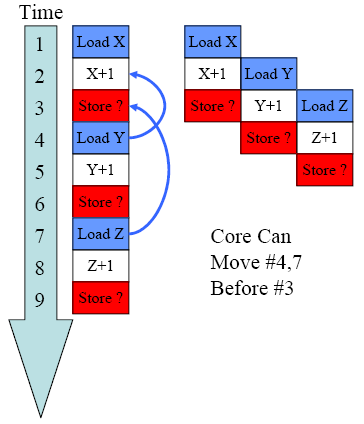
在采用Memory Disambiguation前,上面的指令需要9个时钟周期才能完成,而采用了该技术之后仅需5个时钟周期即可完成,Load提前执行使得位于其后的指令也能提前执行,进而充分利用了各个不同功能的EU。据统计,在一般的工作站中,Load占全部指令的10~25%,Store占比30~45%,可以想象采用MD技术后,指令的执行效率会有相当的提升。
那么在MD中,Load提前到一个未知地址的Store之前执行的以依据是什么?微处理器主要根据过去执行指令来进行预测,准确率达到90%以上。不过由于是预测,因此不一定准确,也就如上述speculate的讨论一样不能执行retirement步骤,直到算出Store的地址。
Store Forwarding
如果在一个store后紧跟着对同一地址的load,那么load就能直接从store中获取所需的数据,而不用再次去到内存中获取,这种技术被称为Store Forwarding(ST)。ST需要满足以下几个条件:
- store必须为相同地址的load之前的最后一个store。
- store所存储的数据必须等于或大于load所读取的数据。
- load的数据不能超越cache line边界(Core之后的微处理器去除了这个限制)。
- load的数据不能超越8字节的边界(Core之后的微处理器去除了这个限制),除非是16字节的读取。
- load的地址必须跟store的地址一样(Nehalem之后的微处理器去除了这个限制),除非是以下的情况:
- 64 bit的store可以forward它任意一半32 bit。
- 128 bit的store可以foward它任意一半的64 bit。
- 128 bit的store可以foward它任意四分之一的32 bit。
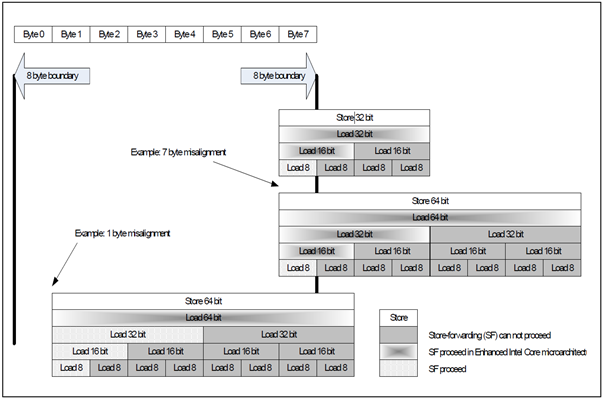
总体来说,随着微处理器的更新,限制越来越少,不过具体还请查看相关资料。
Data Prefetch to L1 caches
Core微处理器提供了两个预取数据的硬件(hardware prefetcher),用于预先获取数据进L1 data cache (DCU):
- Data cache unit (DCU) prefetcher - 也就是常说的流预取器(stream prefetcher),一旦发现当前获取的某个数据的地址是不久前获取的某个数据地址的递增,就会触发该prefetcher,处理器会认为我们在访问一段连续的数据,因此会自动把其递增地址上的下一个cache line获取进入cache。
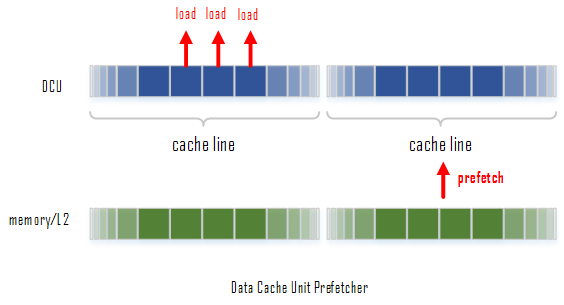
- Instruction pointer (IP)-based strided prefetcher - 该prefetcher会跟踪load指令,如果发现load指令的地址之间存在相同的间隔,那么该prefetcher就会被触发,去预取下一个间隔所在的地址的数据。这种预取可以是前向也可以是后向的,并且间隔的大小最大可以到达2KB。
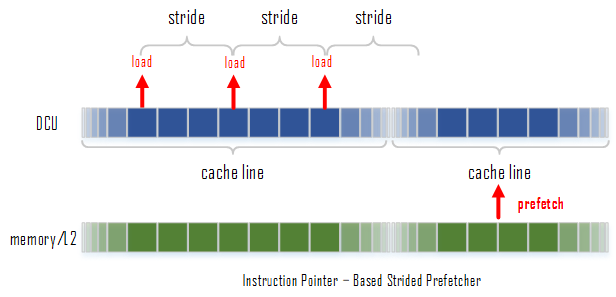
数据的预取还需要满足以下几个条件:
- load的数据是从writeback类型的内存(内存访问的一种cache类型,writeback简单地说就是load与store都要经过cache)中获取的。
- 要预取的数据在一页(page boundary of 4KB)之内。
- pipeline在处理过程中不会进行限制与锁定。
- 在load的过程中没有太多的cache miss。
- 总线不是太忙。
- 没有连续的流写回操作(continuous stream of stores)。
Data Prefetch to L2 caches
L2 cache上的数据预取由Data prefetch logic(DPL)进行管理。L2要从内存预获取什么数据,依据的是DCU过去从L2访问过什么数据。DPL维护了两个独立的队列,用于存储DCU访问的数据的地址:一条队列是用于存储upstreams,即递增的地址,有12项;另一条队列用于存储downstreams,即递减的地址,有4项。每一项用于跟踪一页(4KB)的地址访问情况。
DPL会监控DCU对于连续递增序列(incremental sequences,known as streams)的读取情况。一旦DPL侦测到DCU在访问的数据是流,则会预读取下一条cache line。如DCU向L2要求访问cache line A以及A+1,那么DPL会认为DCU接下来需要访问A+2,那么就会去预取cache line A+2,如果DCU访问了A+2,那么DPL就会预取A+3。递减序列同理。
上面描述的是DPL的基础功能。DPL在Pentium M微处理器首次引入,在Core微处理器时已经有相当强大的功能,如:能判断何时跳过某些不需要的cache lines;每次处理两个预读;预取的cache line可以比load的数据领先8个cache line;可以根据总线的繁忙程度动态调整等。
Reference:
Intel 64 and IA-32 Architectures Software Developer's Manual
Intel® 64 and IA-32 Architectures Optimization Reference Manual
Agner Fog - The microarchitecture of Intel, AMD and VIA CPUs
Operand size prefix in 16-bit mode
David Kanter - The Memory Aliasing Problem
David Kanter - Memory Disambiguation, the Solution
Intel Core Microarchitecture Pipeline的更多相关文章
- Intel CPU Microarchitecture
http://en.wikipedia.org/wiki/Intel_Tick_Tock Atom Roadmap[16] Fabrication process Microarchitectur ...
- Intel Core i7的整体操作
Intel Core i7的整体操作(我们也称呼为Nehalem,他的项目代码名) 主要分成2个部分-指令控制单元Instruction Control Unit(ICU),负责从存储器读出指令序列, ...
- 学习笔记:GLSL Core Tutorial – Pipeline (OpenGL 3.2 – OpenGL 4.2)
GLSL Core Tutorial – Pipeline (OpenGL 3.2 – OpenGL 4.2) GLSL 是一种管道,一种图形化的流水线 1.GLSL 的具体工作流程: 简化流程如下: ...
- Intel® Core™ i5-5300U Processor
3M Cache, up to 2.90 GHz Specifications Ordering and Compliance Essentials Product Collection 5t ...
- Intel processor brand names-Xeon,Core,Pentium,Celeron----Xeon
http://en.wikipedia.org/wiki/Comparison_of_Intel_processors Processor Series Nomenclature Code Name ...
- CPU Stepping
http://baike.baidu.com/view/16839.htm?fr=ala0_1_1 步进 编辑 步进(Stepping)是CPU的一个重要参数,也叫分级鉴别产品数据转换规范,“步进 ...
- Intel processor brand names-Xeon,Core,Pentium,Celeron----Pentium
http://en.wikipedia.org/wiki/Pentium Pentium From Wikipedia, the free encyclopedia This article ...
- Intel processor brand names-Xeon,Core,Pentium,Celeron----Celeron
http://en.wikipedia.org/wiki/Celeron Celeron From Wikipedia, the free encyclopedia Celeron Produ ...
- Intel CPUs
http://en.wikipedia.org/wiki/Intel_cpus List of Intel Atom microprocessors List of Intel Xeon microp ...
随机推荐
- mpls vpn剩余笔记
将IP地址映射为简单的具有固定长度的标签 用于快速数据包交换 20 3 1 8 在整个转发过程中,交换节点仅根据标记进行转发 标签交换路径(LSP) 多协议标签交换MPLS最初是为了提高转发速度而提出 ...
- 第一次作业-----四则运算题目生成(基于java)
1.题目要求 1.除了整数以外,还要支持真分数的四则运算,真分数的运算,例如:1/6 + 1/8 = 7/24. 2.运算符为 +, −, ×, ÷. 3.并且要求能处理用户的输入,并判断对错,打分统 ...
- 201521123072《java程序设计》第七周总结
201521123072<java程序设计>第七周总结 标签: java 1. 本周学习总结 2. 书面作业 ArrayList代码分析 1.1 解释ArrayList的contains源 ...
- 201521123110 《JAVA程序设计》第3周学习总结
1.本章学习总结 ` ` 2.书面作业 1.代码阅读 public class Test1 { private int i = 1;//这行不能修改 private static int j = 2; ...
- java课程设计--WeTalk(201521123076)
在线群聊系统 1,团队课程设计博客链接 http://www.cnblogs.com/slickghost/p/7018105.html 个人负责模块或任务说明 负责模块:总体设计及主要聊天功能实现 ...
- 25个最基本的JavaScript面试问题及答案
1.使用 typeof bar === "object" 来确定 bar 是否是对象的潜在陷阱是什么?如何避免这个陷阱? 尽管 typeof bar === "objec ...
- mysql数据库-中文乱码问题解决方案
来自:http://www.2cto.com/database/201108/101151.html MySQL会出现中文乱码的原因不外乎下列几点: .server本身设定问题,例如还停留在latin ...
- Android 字体修改,所有的细节都在这里 | 开篇
版权声明: 本账号发布文章均来自公众号,承香墨影(cxmyDev),版权归承香墨影所有. 每周会统一更新到这里,如果喜欢,可关注公众号获取最新文章. 未经允许,不得转载. 序 在 Android 下使 ...
- 与 Hadoop 对比,如何看待 Spark 技术?
主要是先看MapReduce模型有什么问题? 第一:需要写很多底层的代码不够高效,第二:所有的事情必须要转化成两个操作Map/Reduce,这本身就很奇怪,也不能解决所有的情况. 其实Spark出现就 ...
- 记录兼容IE8中发现的一些问题
1.new Date().getYear(); chrome下:获取的是1900年之后的年份,如2017年获取的是117 IE8下:获取的是公元年份,如2017获取的是2017 解决方案:使用new ...