深入一致性哈希(Consistent Hashing)算法原理,并附100行代码实现
本文为实现分布式任务调度系统中用到的一些关键技术点分享——Consistent Hashing算法原理和Java实现,以及效果测试。
背景介绍
一致性Hashing在分布式系统中经常会被用到, 用于尽可能地降低节点变动带来的数据迁移开销。Consistent Hashing算法在1997年就在论文Consistenthashing and random trees中被提出。
先来简单理解下Hash是解决什么问题。假设一个分布式任务调度系统,执行任务的节点有n台机器,现有m个job在这n台机器上运行,这m个Job需要逐一映射到n个节点中一个,这时候可以选择一种简单的Hash算法来让m个Job可以均匀分布到n个节点中,比如 hash(Job)%n ,看上去很完美,但考虑如下两种情形:
- n个节点中有一个宕掉了,这时候节点数量变更为n-1,此时的映射公式变成 hash(Job)%(n-1)
- 由于Job数量增加,需要新增机器,此时的映射公式变成 hash(Job)%(n+1)
1、2两种情形可以看到,基本上所有的Job会被重新分配到跟节点变动前不同的节点上,意味着需要迁移几乎所有正在运行的Job,想想这样会给系统带来多大的复杂性和性能损耗。
另外还有一种情况,假设节点的硬件处理性能不完全一致,想让性能高的节点多被分配一些Job,这时候上述简单的Hash映射算法更是很难做到。
如何解决这种节点变动带来的大量数据迁移和数据不均匀分配问题呢?一致性哈希算法就很巧妙的解决了这些问题。
Consistent Hashing是一种Hashing算法,典型的特征是:在减少或者添加节点时,可以尽可能地保证已经存在Key映射关系不变,尽可能地减少Key的迁移。
Consistent Hashing算法原理,如何处理Job->Node映射过程
- 确定hashing值空间
给定值空间2^32,[0,2^32]是所有hash值的取值空间,形象地描述为如下一个环(ring):

2. 节点向值空间映射
将节点Node向这个值空间映射,取Node的Hash值,选取一个可以固定标识一个Node的属性值进行Hashing,假设以字符串形式输入,算法如下:
可以取Node标识的md5值,然后截取其中32位作为映射值。md5取值如下:
private byte[] md5(String value) {
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException(e.getMessage(), e);
}
md5.reset();
byte[] bytes;
try {
bytes = value.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e.getMessage(), e);
}
md5.update(bytes);
return md5.digest();
}

因为映射值只需要32位即可,所以可以利用以下方式计算最终值(number取0即可):
private long hash(byte[] digest, int number) {
return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[0 + number * 4] & 0xFF))
& 0xFFFFFFFFL;
}
把n个节点Node通过以上方式取得hash值,映射到环形值空间如下:
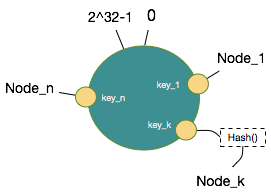
算法中,将以有序Map的形式在内存中缓存每个节点的Hash值对应的物理节点信息。缓存于这个内存变量中:private final TreeMap<Long, String> virtualNodes 。
3. 数据向值空间映射
数据Job取hash的方式跟节点Node的方式一模一样,可以使用上述md5->hash的方式同样将所有Job取得Hash映射到这个环中。
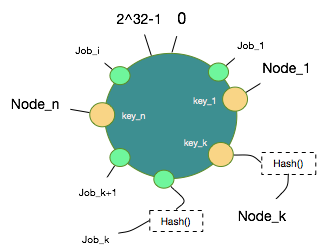
4. 数据和节点映射
当节点和数据都被映射到这个环上后,可以设定一个规则把哪些数据hash值放在哪些节点Node Hash值上了,规则就是,沿着顺时针方向,数据hash值向后找到第一个Node Hash值即认为该数据hash值对应的数据映射到该Node上。至此,这一个从数据到节点的映射关系就确定了。
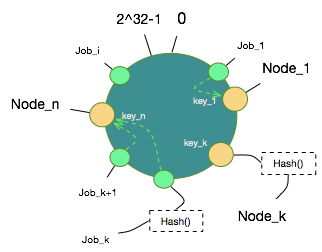
顺时针找下一个Node Hash值算法如下:
public String select(Trigger trigger) {
String key = trigger.toString();
byte[] digest = md5(key);
String node = sekectForKey(hash(digest, 0));
return node;
}
private String sekectForKey(long hash) {
String node;
Long key = hash;
if (!virtualNodes.containsKey(key)) {
SortedMap<Long, String> tailMap = virtualNodes.tailMap(key);
if (tailMap.isEmpty()) {
key = virtualNodes.firstKey();
} else {
key = tailMap.firstKey();
}
}
node = virtualNodes.get(key);
return node;
}
Trigger是对Job一次触发任务的抽象,这里可忽略关注,重写了toString方法返回一个标记一个Job的唯一标志,计算Hash值,从节点Hash值中按规则寻找。 虚拟节点后续介绍。
算法表现
接下来就可以见识下一致性哈希基于这样的数据结构是如何发挥前文提到的优势的。
1. 节点减少时,看需要迁移的节点情况
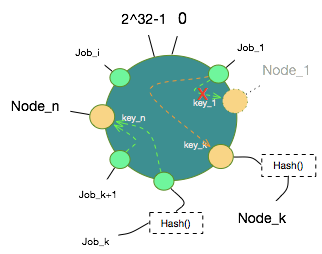
假设Node_1宕掉了,图中数据对象只有Job_1会被重新映射到Node_k,而其他Job_x扔保持原有映射关系不变。
2. 节点新增时
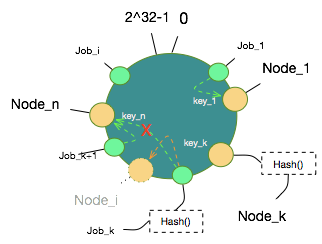
假设新增Node_i,图中数据对象只有Job_k会被重新映射到Node_i上,其他Job_x同样保持原有映射关系不变。
算法优化-虚拟节点
上述算法过程,会想到两个问题,第一,数据对象会不会分布不均匀,特别是新增节点或者减少节点时;第二,前文提到的如果想让部分节点多映射到一些数据对象,如何处理。虚拟节点这是解决这个问题。
将一个物理节点虚拟出一定数量的虚拟节点,分散到这个值空间上,需要尽可能地随机分散开。
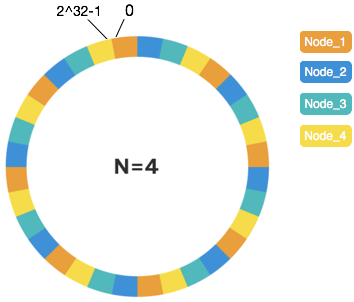
假设有4个物理节点Node,环上的每个色块代表一个虚拟节点涵盖的hash值区域,每种颜色代表一个物理节点。当物理节点较少时,虚拟节点数需要更高来确保更好的一致性表现。经测试,在物理节点为个位数时,虚拟节点可设置为160个,此时可带来较好的表现(后文会给出测试结果,160*n个总节点数情况下,如果发生一个节点变动,映射关系变化率基本为1/n,达到预期)。
具体做算法实现时,已知物理节点,虚拟节点数设置为160,可将这160*n的节点计算出Hash值,以Hash值为key,以物理节点标识为value,以有序Map的形式在内存中缓存,作为后续计算数据对象对应的物理节点时的查询数据。代码如下,virtualNodes中缓存着所有虚拟节点Hash值对应的物理节点信息。
public ConsistentHash(List<String> nodes) {
this.virtualNodes = new TreeMap<>();
this.identityHashCode = identityHashCode(nodes);
this.replicaNumber = 160;
for (String node : nodes) {
for (int i = 0; i < replicaNumber / 4; i++) {
byte[] digest = md5(node.toString() + i);
for (int h = 0; h < 4; h++) {
long m = hash(digest, h);
virtualNodes.put(m, node);
}
}
}
}
算法测试
以上详细介绍了一致性哈希(Consistent Hashing)的算法原理和实现过程,接下来给出一个测试结果:
以10个物理节点,160个虚拟节点,1000个数据对象做测试,10个物理节点时,这1000个数据对象映射结果如下:
减少一个节点前,path_7节点数据对象个数:113
减少一个节点前,path_0节点数据对象个数:84
减少一个节点前,path_6节点数据对象个数:97
减少一个节点前,path_8节点数据对象个数:122
减少一个节点前,path_3节点数据对象个数:102
减少一个节点前,path_2节点数据对象个数:99
减少一个节点前,path_4节点数据对象个数:98
减少一个节点前,path_9节点数据对象个数:102
减少一个节点前,path_1节点数据对象个数:99
减少一个节点前,path_5节点数据对象个数:84
减少一个物理节点path_9,此时9个物理节点,原有1000个数据对象映射情况如下:
减少一个节点后,path_7节点数据对象个数:132
减少一个节点后,path_6节点数据对象个数:107
减少一个节点后,path_0节点数据对象个数:117
减少一个节点后,path_8节点数据对象个数:134
减少一个节点后,path_3节点数据对象个数:104
减少一个节点后,path_4节点数据对象个数:104
减少一个节点后,path_2节点数据对象个数:115
减少一个节点后,path_5节点数据对象个数:89
减少一个节点后,path_1节点数据对象个数:98
先从数量上对比下每个物理节点上数据对象的个数变化:
减少一个节点后,path_7节点数据对象个数从113变为132
减少一个节点后,path_6节点数据对象个数从97变为107
减少一个节点后,path_0节点数据对象个数从84变为117
减少一个节点后,path_8节点数据对象个数从122变为134
减少一个节点后,path_3节点数据对象个数从102变为104
减少一个节点后,path_4节点数据对象个数从98变为104
减少一个节点后,path_2节点数据对象个数从99变为115
减少一个节点后,path_5节点数据对象个数从84变为89
减少一个节点后,path_1节点数据对象个数从99变为98
可以看到基本是均匀变化,现在逐个对比每个数据对象前后映射到的物理节点,发生变化的数据对象占比情况,统计如下:
数据对象迁移比率:0.9%
该结果基本体现出一致性哈希所能带来的最佳表现,尽可能地减少节点变动带来的数据迁移。
附Java完整代码
最后附上完整的算法代码,供大家参照。代码中数据对象是以Trigger抽象,可以调整成特定场景的,即可运行测试。
package com.cronx.core.common; import com.cronx.core.entity.Trigger; import java.io.UnsupportedEncodingException;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.Collections;
import java.util.List;
import java.util.SortedMap;
import java.util.TreeMap; /**
* Created by echov on 2018/1/9.
*/
public class ConsistentHash { private final TreeMap<Long, String> virtualNodes; private final int replicaNumber; private final int identityHashCode; private static ConsistentHash consistentHash; public ConsistentHash(List<String> nodes) {
this.virtualNodes = new TreeMap<>();
this.identityHashCode = identityHashCode(nodes);
this.replicaNumber = 160;
for (String node : nodes) {
for (int i = 0; i < replicaNumber / 4; i++) {
byte[] digest = md5(node.toString() + i);
for (int h = 0; h < 4; h++) {
long m = hash(digest, h);
virtualNodes.put(m, node);
}
}
}
} private static int identityHashCode(List<String> nodes){
Collections.sort(nodes);
StringBuilder sb = new StringBuilder();
for (String s: nodes
) {
sb.append(s);
}
return sb.toString().hashCode();
} public static String select(Trigger trigger, List<String> nodes) {
int _identityHashCode = identityHashCode(nodes);
if (consistentHash == null || consistentHash.identityHashCode != _identityHashCode) {
synchronized (ConsistentHash.class) {
if (consistentHash == null || consistentHash.identityHashCode != _identityHashCode) {
consistentHash = new ConsistentHash(nodes);
}
}
}
return consistentHash.select(trigger);
} public String select(Trigger trigger) {
String key = trigger.toString();
byte[] digest = md5(key);
String node = sekectForKey(hash(digest, 0));
return node;
} private String sekectForKey(long hash) {
String node;
Long key = hash;
if (!virtualNodes.containsKey(key)) {
SortedMap<Long, String> tailMap = virtualNodes.tailMap(key);
if (tailMap.isEmpty()) {
key = virtualNodes.firstKey();
} else {
key = tailMap.firstKey();
}
}
node = virtualNodes.get(key);
return node;
} private long hash(byte[] digest, int number) {
return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[0 + number * 4] & 0xFF))
& 0xFFFFFFFFL;
} private byte[] md5(String value) {
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException(e.getMessage(), e);
}
md5.reset();
byte[] bytes;
try {
bytes = value.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e.getMessage(), e);
}
md5.update(bytes);
return md5.digest();
} }
深入一致性哈希(Consistent Hashing)算法原理,并附100行代码实现的更多相关文章
- 一致性哈希(consistent hashing)算法
文章同步发表在博主的网站朗度云,传输门:http://www.wolfbe.com/detail/201608/341.html 1.背景 我们都知道memcached服务器是不提供分布 ...
- 用于KV集群的一致性哈希Consistent Hashing机制
KV集群的请求分发 假定N为后台服务节点数,当前台携带关键字key发起请求时,我们通常将key进行hash后采用模运算 hash(key)%N 来将请求分发到不同的节点上, 后台节点的增删会引起几乎所 ...
- Consistent Hashing算法-搜索/负载均衡
在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin).哈希算法(HASH).最少连接算法(Least Connection).响应速度算法(Respons ...
- Consistent Hashing算法
前几天看了一下Memcached,看到Memcached的分布式算法时,知道了一种Consistent Hashing的哈希算法,上网搜了一下,大致了解了一下这个算法,做下记录. 数据均衡分布技术在分 ...
- Nginx的负载均衡 - 一致性哈希 (Consistent Hash)
Nginx版本:1.9.1 我的博客:http://blog.csdn.net/zhangskd 算法介绍 当后端是缓存服务器时,经常使用一致性哈希算法来进行负载均衡. 使用一致性哈希的好处在于,增减 ...
- 经典傅里叶算法小集合 附完整c代码
前面写过关于傅里叶算法的应用例子. <基于傅里叶变换的音频重采样算法 (附完整c代码)> 当然也就是举个例子,主要是学习傅里叶变换. 这个重采样思路还有点瑕疵, 稍微改一下,就可以支持多通 ...
- Java架构师方案—多数据源开发详解及原理(二)(附完整项目代码)
1. mybatis下数据源开发工作 2. 数据源与DAO的关系原理模型 3. 为什么要配置SqlSessionTemplate类的bean 4. 多数据源应用测试 1. mybatis下数据源开发工 ...
- java 一致性哈希类实例 算法
package com.hash; import java.util.Collection; import java.util.SortedMap; import java.util.TreeMap; ...
- _00013 一致性哈希算法 Consistent Hashing 新的讨论,并出现相应的解决
笔者博文:妳那伊抹微笑 博客地址:http://blog.csdn.net/u012185296 个性签名:世界上最遥远的距离不是天涯,也不是海角,而是我站在妳的面前.妳却感觉不到我的存在 技术方向: ...
随机推荐
- 前端构建之gulp与常用插件(转载)
原博主:幻天芒 原文地址:http://www.cnblogs.com/humin/p/4337442.html gulp是什么? http://gulpjs.com/ 相信你会明白的! 与著名的构建 ...
- geoserver安装部署步骤
方式一:直接在geoserver官网下载zip源代码解压包,直接部署在tomcat里面运行geoserver: 方式二:下载安装包方式 以GeoServer2.8.5版本为准,安装之前必须要保证你机子 ...
- 一道叉姐的AC自动机鬼题
题面描述丢失了... 给n个串模板串,然后再给你m个串,对于这m个串的每个串,问在[L,R]的模板串中,在多少个串中出现过; 这题的正解是对于后m个串建AC自动机,然后离线,在fail树上树链求并. ...
- SQL数据库语句
on xxx --主文件 ( name=‘xxxx’, fliename='里面写文件放的路径\xxxx.mdf', size=xxMB, filegrowth=xxMB, maxsize=xxMB ...
- java获取properties配置文件值
package me.ilt.Blog.util; import java.io.File; import java.io.FileInputStream; import java.io.IOExce ...
- java应用的jar包多合一
之前开发的java程序由于依赖比较多的jar包,启动命令为" java -classpath .:lib/*.jar 主类名",这种启动方式需要指定类路径.入口类名称,并存在jar ...
- python爬虫爬取人人车(二手车)、利用padas、matplotlib生成图表,将信息打成csv格式
该程序主要为了抓取人人车卖车信息,包括车系.车型号.购车日期.卖车价格.行驶路程.首付价格等等信息.话不多说直接代码. 入库之后将Mongodb里的信息导出成Excel语句 mongoexport - ...
- 程序猿的日常——Java中的集合列表
列表对于日常开发来说实在是太常见了,以至于很多开发者习惯性的用到数组,就来一个ArrayList,根本不做过多的思考.其实列表里面还是有很多玩法的,有时候玩不好,搞出来bug还得定位半天.所以这里就再 ...
- Python学习_10__python2到python3
同样作为动态语言,python的面相对像和ruby有很多类似的地方,这里还是推荐<Ruby元编程>一书来参考学习python的面向对象.然而python并不是纯面向对象设计,所以很多rub ...
- Android View的事件冲突
上一篇博客讨论了一下view中的事件分发,既然存在事件分发的过程,那么也就可能存在着冲突.常见的由以下三种形式的冲突.(外面叫做OuterViewGroup,包裹在里面的叫做InnerViewGrou ...