新浪新闻页面抓取(JAVA-Jsoup)
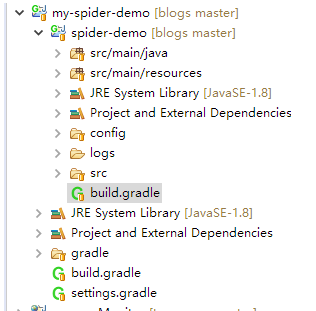
1、使用gradle建立工程:
工程格式如下:
include ':spider-demo' rootProject.name = 'my-spider-demo'
settings
def void forceVersion(details, group, version) {
if (details.requested.group == group) {
details.useVersion version
}
}
def void forceVersion(details, group, name, version) {
if (details.requested.group == group && details.requested.name == name) {
details.useVersion version
}
}
allprojects { p ->
group = 'com.my.spider'
version = '1.0.0'
apply plugin: 'java'
apply plugin: 'maven'
apply plugin: 'maven-publish'
[compileJava, compileTestJava]*.options*.encoding = 'UTF-8'
jar.doFirst {
manifest {
def manifestFile = "${projectDir}/META-INF/MANIFEST.MF"
if (new File(manifestFile).exists())
from (manifestFile)
attributes 'Implementation-Title':p.name
if (p.version.endsWith('-SNAPSHOT')) {
attributes 'Implementation-Version': p.version + '-' + p.ext.Timestamp
} else {
attributes 'Implementation-Version': p.version
}
attributes 'Implementation-BuildDateTime':new Date()
}
}
javadoc {
options {
encoding 'UTF-8'
charSet 'UTF-8'
author false
version true
links 'http://docs.oracle.com/javase/8/docs/api/index.html'
memberLevel = org.gradle.external.javadoc.JavadocMemberLevel.PRIVATE
}
}
if (p.name.endsWith('-api')){
task sourcesJar(type:Jar, dependsOn:classes) {
classifier = 'sources'
from sourceSets.main.allSource
}
task javadocJar(type:Jar, dependsOn:javadoc) {
classifier = 'javadoc'
from javadoc.destinationDir
}
}
publishing {
repositories {
maven {
credentials {
username "${repositoryUploadUsername}"
password "${repositoryUploadPassword}"
}
if (version.endsWith('-SNAPSHOT')) {
url "${repositoryUploadSnapshotUrl}"
} else {
url "${repositoryUploadReleaseUrl}"
}
}
}
publications {
mavenJava(MavenPublication) {
from components.java
// 只有*-api才会需要发布sources和javadoc
if (p.name.endsWith('-api')){
artifact sourcesJar {
classifier "sources"
}
artifact javadocJar {
classifier "javadoc"
}
}
}
}
}
if (System.env.uploadArchives) {
build.dependsOn publish
}
buildscript {
repositories {
maven {
name 'Maven Repository'
url "${repositoryMavenUrl}"
credentials {
username "${repositoryUsername}"
password "${repositoryPassword}"
}
}
}
dependencies {classpath 'org.springframework.boot:spring-boot-gradle-plugin:1.4.0.RELEASE' }
}
afterEvaluate {Project project ->
if (project.pluginManager.hasPlugin('java')) {
configurations.all {
resolutionStrategy.eachDependency {DependencyResolveDetails details ->
forceVersion details, 'org.springframework.boot', '1.4.1.RELEASE'
forceVersion details, 'org.slf4j', '1.7.21'
forceVersion details, 'org.springframework', '4.3.3.RELEASE'
}
exclude module:'slf4j-log4j12'
exclude module:'log4j'
}
dependencies {testCompile 'junit:junit:4.12' }
}
}
repositories {
maven {
name 'Maven Repository'
url "${repositoryMavenUrl}"
credentials {
username "${repositoryUsername}"
password "${repositoryPassword}"
}
}
ivy {
name 'Ivy Repository'
url "${repositoryIvyUrl}"
credentials {
username "${repositoryUsername}"
password "${repositoryPassword}"
}
layout "pattern", {
artifact '[organisation]/[module]/[revision]/[type]s/[artifact]-[revision].[ext]'
ivy '[organisation]/[module]/[revision]/[type]s/[artifact].[ext]'
m2compatible = true
}
}
}
// 时间戳:年月日时分
p.ext.Timestamp = new Date().format('yyyyMMddHHmm')
// Build Number
p.ext.BuildNumber = System.env.BUILD_NUMBER
if (p.ext.BuildNumber == null || "" == p.ext.BuildNumber) {
p.ext.BuildNumber = 'x'
}
}
task zipSources(type: Zip) {
description '压缩源代码'
project.ext.zipSourcesFile = project.name + '-' + project.version + '-' + project.ext.Timestamp + '.' + project.ext.BuildNumber + '-sources.zip'
archiveName = project.ext.zipSourcesFile
includeEmptyDirs = false
from project.projectDir
exclude '**/.*'
exclude 'build/*'
allprojects.each { p ->
exclude '**/' + p.name + '/bin/*'
exclude '**/' + p.name + '/build/*'
exclude '**/' + p.name + '/data/*'
exclude '**/' + p.name + '/work/*'
exclude '**/' + p.name + '/logs/*'
}
}
def CopySpec appCopySpec(Project prj, dstname = null) {
if (!dstname) { dstname = prj.name }
return copySpec{
// Fat jar
from (prj.buildDir.toString() + '/libs/' + prj.name + '-' + project.version + '.jar') {
into dstname
}
// Configs
from (prj.projectDir.toString() + '/config/examples') {
into dstname + '/config'
}
// Windows start script
from (prj.projectDir.toString() + '/' + prj.name + '.bat') {
into dstname
}
// Unix conf script
from (prj.projectDir.toString() + '/' + prj.name + '.conf') {
into dstname
rename prj.name, prj.name + '-' + project.version
}
}
}
task zipSetup(type: Zip, dependsOn: subprojects.build) {
description '制作安装包'
project.ext.zipSetupFile = project.name + '-' + project.version + '-' + project.ext.Timestamp + '.' + project.ext.BuildNumber + '-setup.zip'
archiveName = project.name + '-' + project.version + '-' + project.ext.Timestamp + '.' + project.ext.BuildNumber + '-setup.zip'
with appCopySpec(project(':spider-demo'))
}
import java.security.MessageDigest
def generateMD5(final file) {
MessageDigest digest = MessageDigest.getInstance("MD5")
file.withInputStream(){is->
byte[] buffer = new byte[8192]
int read = 0
while( (read = is.read(buffer)) > 0) {
digest.update(buffer, 0, read);
}
}
byte[] md5sum = digest.digest()
BigInteger bigInt = new BigInteger(1, md5sum)
return bigInt.toString(16)
}
task md5(dependsOn: [zipSetup, zipSources]) << {
String md5_setup = generateMD5(file("${projectDir}/build/distributions/" + project.ext.zipSetupFile));
String md5_sources = generateMD5(file("${projectDir}/build/distributions/" + project.ext.zipSourcesFile));
println project.ext.zipSetupFile + '=' + md5_setup
println project.ext.zipSourcesFile + '=' + md5_sources
def newFile = new File("${projectDir}/build/distributions/"
+ project.name + '-' + project.version + '-' + project.ext.Timestamp + '.' + project.ext.BuildNumber + '-md5.txt')
PrintWriter printWriter = newFile.newPrintWriter()
printWriter.println project.ext.zipSetupFile + '=' + md5_setup
printWriter.println project.ext.zipSourcesFile + '=' + md5_sources
printWriter.flush()
printWriter.close()
}
build.dependsOn subprojects.build, zipSetup, zipSources, md5
bulid.gradle
子过程相关依赖:
apply plugin: 'spring-boot'
apply plugin: 'application' distributions {
main {
contents {
from ("${projectDir}/config/examples") {
into "config"
}
}
}
} distTar.enabled = false springBoot {
executable = true
mainClass = 'com.my.spider.Application'
} dependencies {
compile 'org.springframework.boot:spring-boot-starter-web:1.4.0.RELEASE'
compile 'dom4j:dom4j:1.6.1'
compile 'commons-httpclient:commons-httpclient:3.1'
compileOnly 'com.h2database:h2:1.4.191'
compile 'javax.cache:cache-api:1.0.0'
compile 'org.jboss.resteasy:resteasy-jaxrs:3.0.14.Final'
compile 'org.jboss.resteasy:resteasy-client:3.0.14.Final'
// Axis
compile 'axis:axis:1.4' compile 'org.jsoup:jsoup:1.10.1' compile 'com.alibaba:fastjson:1.2.21' }
bulid
2、代码编写:
入口:
package com.my.spider; import java.io.IOException; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.annotation.EnableScheduling; import com.my.spider.utils.CommonProperties; @SpringBootApplication
@EnableScheduling
@EnableAsync
public class Application { public static void main(String[] args) throws IOException {
String loc = CommonProperties.loadProperties2System(System.getProperty("spring.config.location"));
System.getProperties().setProperty("application.version", CommonProperties.getVersion(Application.class));
System.getProperties().setProperty("app.home", loc + "/..");
SpringApplication.run(Application.class, args);
} }
package com.my.spider.utils; import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Properties; import org.springframework.util.StringUtils; public final class CommonProperties { public static final String PPT_KEY_APP_HOME = "app.home"; public static final String DEFAULT_APP_HOME = "./"; public static final String getAppHome() {
return System.getProperty(DEFAULT_APP_HOME, DEFAULT_APP_HOME);
} public static String loadProperties2System(String location) throws IOException {
String configLocation = location;
File cnf;
if (!StringUtils.hasLength(configLocation)) {
configLocation = "./config";
cnf = new File(configLocation);
if (!cnf.exists() || !cnf.isDirectory()) {
configLocation = "../config";
cnf = new File(configLocation);
}
} else {
cnf = new File(configLocation);
}
for (File file : cnf.listFiles()) {
if (file.isFile() && file.getName().endsWith(".properties")) {
Properties ppt = new Properties();
try (FileInputStream fi = new FileInputStream(file)) {
ppt.load(fi);
System.getProperties().putAll(ppt);
}
}
}
return configLocation;
} public static String getVersion(Class<?> clazz) {
Package pkg = clazz.getPackage();
String ver = (pkg != null ? pkg.getImplementationVersion() : "undefined");
return (ver == null ? "undefined" : ver);
}
}
配置类:
package com.my.spider.config; import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableScheduling; @EnableScheduling
@Configuration
@ComponentScan(basePackages = {
"com.my.spider.rs",
"com.my.spider.schedule"
})
public class AppAutoConfiguration { }
META-INF下spring.factories文件:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.my.spider.config.AppAutoConfiguration
3、功能代码:
定时任务抽象类,提供三种定时任务的调用方法:
package com.my.spider.schedule; import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component; import com.fasterxml.jackson.databind.ObjectMapper; @Component
public abstract class ParentSchedule implements InitializingBean,DisposableBean{ public static Logger logger = LoggerFactory.getLogger(ParentSchedule.class); public final static ObjectMapper objectMapper = new ObjectMapper(); @Scheduled(
initialDelayString = "${agent.task.initialDelay:1000}", //
fixedDelayString = "${agent.task.fixedDelay:10000}")
public void dowork(){
execute();
}
//定时任务一
public abstract void execute(); @Scheduled(cron = "${agent.task.cron:0 0 10,14,16 * * ?}")
public void timeTask(){
executeTimeTask();
}
//定时任务三
public abstract void executeTimeTask(); //每天12点出发
@Scheduled(cron = "0 0 12 * * ?")
public void otherTask(){
executeOtherTask();
}
//定时任务三
public abstract void executeOtherTask();
}
package com.my.spider.utils; import java.util.HashMap;
import java.util.Map; import org.slf4j.Logger;
import org.slf4j.LoggerFactory; /**
* 页面抓取请求的公共类
* */
public class HttpHtmlUtils { public static Logger logger = LoggerFactory.getLogger(HttpHtmlUtils.class); public static Map<String, String> header = new HashMap<String, String>(); public static Map<String, String> header_a = new HashMap<String, String>(); static {
//设置请求头
header.put("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0");
header.put("Accept","text/javascript, text/html, application/xml, text/xml, */*");
header.put("Accept-Language","zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3");
header.put("Accept-Encoding","gzip, deflate");
header.put("X-Requested-With","XMLHttpRequest");
header.put("Content-Type","text/*, application/xml");
header.put("Connection","keep-alive"); header_a.put("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0");
header_a.put("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
header_a.put("Accept-Language","zh-CN,zh;q=0.8");
header_a.put("Accept-Encoding","gzip, deflate, sdch");
header_a.put("Content-Type","application/octet-stream");
header_a.put("Connection","keep-alive");
header_a.put("Upgrade-Insecure-Requests", "1");
} }
新浪滚动新闻抓取实现下载和分析:
package com.my.spider.schedule; import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set; import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils; import com.my.spider.utils.FileUtils;
import com.my.spider.utils.HttpHtmlUtils; @Component
public class SinaSchedule extends ParentSchedule { private static Logger logger = LoggerFactory.getLogger(SinaSchedule.class); public static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm"); public static SimpleDateFormat sdfYMD = new SimpleDateFormat("yyyy-MM-dd"); private static int downloadtimeout = 5000; public static Set<String> titleSet = new HashSet<String>(); @Value("${img.download.dir.prefix:D://testhtml}")
public String dirpath; @Override
public void afterPropertiesSet() throws Exception {
// TODO Auto-generated method stub } // 抓取文章列表
public static List<String> getArticleList(String url) { List<String> urlList = new ArrayList<String>();
logger.debug("获取文章信息url:{},开始时间={}", url, sdf.format(new Date())); try {
Connection connect = Jsoup.connect(url).headers(HttpHtmlUtils.header_a);
Document document;
document = connect.timeout(downloadtimeout).get();
Elements newsList = document.getElementsByClass("d_list_txt");
if (newsList != null && newsList.size() > 0) {
newsList = newsList.get(0).getElementsByTag("ul").get(0).getElementsByTag("li");
for (Element el : newsList) {
String elUrl = el.getElementsByTag("a").get(0).absUrl("href");
String urlName = el.getElementsByTag("a").get(0).text();
String time = el.getElementsByClass("c_time").get(0).text();
logger.debug("获取新闻:{},访问地址:{},时间:{}",urlName,elUrl,time);
//elUrl = el.getElementsByTag("a").get(0).attr("href");
urlList.add(elUrl);
}
}
logger.debug("获取文章列表信息:结束时间={}", sdf.format(new Date()));
return urlList;
} catch (IOException e) {
logger.error("访问文章列表失败:" + url + " 原因" + e.getMessage());
}
return null;
} // 抓取文章列表
public static Map<String, Object> getArticleInfo(String url) { logger.debug("获取文章信息url:{},开始时间={}", url, sdf.format(new Date()));
try {
Map<String, Object> map = new HashMap<String, Object>();
Connection connect = Jsoup.connect(url).headers(HttpHtmlUtils.header);
Document document;
document = connect.timeout(downloadtimeout).get();
Element titleEl = document.getElementById("artibodyTitle");
String tilte = ""; if (titleEl != null) {
tilte = titleEl.text();
} Elements keywords = document.getElementsByClass("article-keywords");
String tag = "";
StringBuffer sb = new StringBuffer();
if (keywords != null ) {
for (Element t : keywords.get(0).getElementsByTag("a")) {
sb.append(t.text()).append(",");
}
if (!StringUtils.isEmpty(sb.toString())) {
tag = sb.deleteCharAt(sb.lastIndexOf(",")).toString();
}
} Element contentEle = document.getElementById("artibody");
String content = "";
String contentText = "";
if (contentEle != null) {
content = contentEle.html();
contentText = contentEle.text();
}
String description = "";
Elements descEle = document.getElementsByAttributeValue("name","description");
if (descEle != null && descEle.size() > 0) {
description = descEle.get(0).attr("content");
}
List<String> imgUrls = new ArrayList<>();
Elements imgs = contentEle.getElementsByTag("img");
if (imgs != null && imgs.size() > 0) {
for (Element img : imgs) {
String imgUrl = img.attr("src");
if (!StringUtils.isEmpty(imgUrl)) {
imgUrls.add(imgUrl);
}
}
}
map.put("imgs", imgUrls);
map.put("description", description);
map.put("content", content);
map.put("contentText", contentText);
map.put("tag", tag);
map.put("title", tilte);
logger.debug("获取文章信息:结束时间={}", sdf.format(new Date())); return map;
} catch (IOException e) {
logger.error("访问文章页失败:" + url + " 原因" + e.getMessage());
}
return null;
} @Override
public void destroy() throws Exception {
// TODO Auto-generated method stub } public static void main(String[] args) {
List<String> url = new ArrayList<>();
url.addAll(getArticleList("http://roll.news.sina.com.cn/s/channel.php?ch=01#col=89&spec=&type=&ch=0"
+ "1&k=&offset_page=0&offset_num=0&num=60&asc=&page=1"));
titleSet.addAll(url);
logger.debug("此次共获取到{}个",titleSet.size()); for (String urlStr : titleSet) {
try {
/*
String htmlFile = FileUtils.downloadYunFile(urlStr, "D://testhtml//sina//"+sdfYMD.format(new Date()));
Document document = Jsoup.parse(new File(htmlFile), "utf8");
document.getElementsByTag("tilte");
*/
//下载保存
FileUtils.downloadYunFile(urlStr, "D://testhtml//sina//"+sdfYMD.format(new Date())); getArticleInfo(urlStr); } catch (Throwable e) { } }
} @Override
public void execute() { } @Override
public void executeTimeTask() {
// TODO Auto-generated method stub } @Override
public void executeOtherTask() {
// TODO Auto-generated method stub } }
下载html文件代码:
package com.my.spider.utils; import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import java.util.Arrays; import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.HttpEntity;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpMethod;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.http.client.ClientHttpRequestFactory;
import org.springframework.http.client.HttpComponentsClientHttpRequestFactory;
import org.springframework.util.StreamUtils;
import org.springframework.web.client.RestTemplate;
import org.springframework.web.util.UriComponentsBuilder; import com.fasterxml.jackson.databind.ObjectMapper; public class FileUtils { private static final Logger logger = LoggerFactory.getLogger(FileUtils.class); private static ObjectMapper _objectMapper = new ObjectMapper(); private static int downloadTimeout = 5000; public static void main(String[] args) throws Throwable {
String filePath = "/temp/temp/test.mpg";
String dirPrex = "/temp&Z:\\\\";
String[] paths = dirPrex.split("&");
System.out.println(paths[1] + filePath.substring(paths[0].length() + 1).replace("/", "\\"));
} // 文件复制
public static void copy(String src, String dest) throws IOException { System.out.println("正在拷贝【" + src + "】到【" + dest + "】\n");
File destFile = new File(dest);
if (!destFile.exists()) {
String dir = dest.substring(0, dest.lastIndexOf(File.separator));
File dirF = new File(dir);
if (!dirF.exists() || !dirF.isDirectory()) {
dirF.mkdirs();
}
destFile.createNewFile();
}
FileInputStream in = new FileInputStream(src);
FileOutputStream out = new FileOutputStream(dest);
byte[] buffer = new byte[40960];
while (in.read(buffer) != -1) {
out.write(buffer);
out.flush();
}
in.close();
out.close();
} // 下载云文件
public static String downloadYunFile(String url, String dir) throws Throwable { String fileName = getFileName(url); String filePath = dir + File.separator + fileName; try (CloseableHttpClient httpclient = HttpClients.createDefault()) {
HttpGet httpget = new HttpGet(url);
httpget.setConfig(RequestConfig.custom() //
.setConnectionRequestTimeout(downloadTimeout) //
.setConnectTimeout(downloadTimeout) //
.setSocketTimeout(downloadTimeout) //
.build());
try (CloseableHttpResponse response = httpclient.execute(httpget)) {
org.apache.http.HttpEntity entity = response.getEntity();
File desc = new File(filePath);
File folder = desc.getParentFile();
folder.mkdirs();
try (InputStream is = entity.getContent(); //
OutputStream os = new FileOutputStream(desc)) {
StreamUtils.copy(is, os);
}
} catch (Throwable e) {
throw new Throwable("文件下载失败......", e);
}
}
return filePath;
} public static String getFileName(String fileFullPath) {
fileFullPath = fileFullPath.replace("/", "\\");
return fileFullPath.substring(fileFullPath.lastIndexOf("\\") + 1, fileFullPath.length());
} // 请求例子
public void getToken(String url, String data) throws Throwable { RestTemplate restTemplate = new RestTemplate();
ClientHttpRequestFactory clientFactory = new HttpComponentsClientHttpRequestFactory();
restTemplate.setRequestFactory(clientFactory); HttpHeaders requestHeaders = new HttpHeaders();
requestHeaders.setAccept(Arrays.asList(MediaType.APPLICATION_JSON_UTF8));
requestHeaders.setContentType(MediaType.APPLICATION_JSON_UTF8);
logger.debug("获取token的URL:" + url); URI uri = UriComponentsBuilder.fromUriString(url).build().encode().toUri(); logger.debug("请求数据:{}", _objectMapper.writeValueAsString(data)); HttpEntity<String> requestEntity = new HttpEntity<String>(data, requestHeaders); ResponseEntity<String> response = restTemplate.exchange(uri, HttpMethod.POST, requestEntity, String.class);
String resp = response.getBody();
logger.debug("请求返回值数据:{}", _objectMapper.writeValueAsString(resp));
} }
4、总结:
Jsoup对于这种页面抓取很好用!也可能因为这是实现了一个最简单的页面抓取过程!
追加一个下载音频的代码:
package com.my.spider.service; import java.net.HttpURLConnection;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Map; import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service; import com.alibaba.fastjson.JSONObject;
import com.my.spider.model.AudioInfo;
import com.my.spider.utils.FileUtils;
import com.my.spider.utils.HttpHtmlUtils;
import com.my.spider.utils.HttpURLConnectionFactory; @Service
public class XmlyAudioService { public static final Logger logger = LoggerFactory.getLogger(XmlyAudioService.class);
static String url = "http://www.ximalaya.com/dq/comic/";
static String requetUrl = "http://www.ximalaya.com/tracks/"; public static void main(String[] args) {
List<String> audioUrlList = new ArrayList<String>();
int count = getCount(url);
if(count > 1) {
audioUrlList.addAll(getAudioList(1,url));
for (int i = 2; i <= count; i++) {
url = url +i+"/";
audioUrlList.addAll(getAudioList(i,url));
url = url.replace(i+"/", "");
}
}
List<String> audioList = new ArrayList<String>();
//解析
if(audioUrlList.size() > 0) {
for (String url : audioUrlList) {
audioList.addAll(listAudio(url));
}
}
System.out.println(audioUrlList.size() + "==" + audioList.size());
List<AudioInfo> audioInfos = new ArrayList<>();
//下载
for (String sound_id : audioList) {
requetUrl = requetUrl + sound_id+".json";
System.out.println(requetUrl);
audioInfos.add(downloadList(requetUrl));
requetUrl = requetUrl.replace(sound_id+".json", "");
}
} //获取音频页详情
public static List<String> getAudioList(int num,String url){
List<String> list = new ArrayList<>();
try {
Connection connect = Jsoup.connect(url).headers(HttpHtmlUtils.header_a);
Document document = connect.timeout(5000).get();
FileUtils.str2File(document.toString(), "G:\\xmly\\html\\comic" + num + ".html");
Element el = document.getElementById("explore_album_detail_entry");
Elements els = el.getElementsByClass("albumface");
for (Element element : els) {
list.add(element.absUrl("href"));
}
} catch (Throwable e) {
logger.error("获取{}网页信息失败,{}",url,e.getMessage(),e);
}
return list;
} public static List<String> listAudio(String url){
List<String> list = new ArrayList<>();
try {
Connection connect = Jsoup.connect(url).headers(HttpHtmlUtils.header_a);
Document document = connect.timeout(5000).get();
FileUtils.str2File(document.toString(), "G:\\xmly\\html\\comic_"+System.currentTimeMillis()+".html");
Elements els = document.getElementsByClass("personal_body");
if(els!=null && els.size() > 0) {
String sound_ids = els.get(0).attr("sound_ids");
list.addAll(Arrays.asList(sound_ids.split(",")));
}
} catch (Throwable e) {
logger.error("获取{}网页信息失败,{}",url,e.getMessage(),e);
}
return list;
} //
@SuppressWarnings("unchecked")
public static AudioInfo downloadList(String url){
AudioInfo audioInfo = new AudioInfo();
try { HttpURLConnection conn = HttpURLConnectionFactory.getConn(url);
conn.setRequestProperty("Content-Type", "*/*; charset=utf-8");
String audioJson = HttpURLConnectionFactory.sendGet(conn);
Map<String,Object> map = (Map<String, Object>) JSONObject.parse(audioJson);
audioInfo.setId(map.get("id").toString());
audioInfo.setName(map.get("title").toString());
audioInfo.setUrl(map.get("play_path").toString());
try {
FileUtils.downloadRenameFile(audioInfo.getUrl(), "G:\\xmly", audioInfo.getName()+".mp3");
} catch (Throwable e) {
logger.error("{}下载失败,id={}",audioInfo.getName(),audioInfo.getId());;
} } catch (Throwable e) {
logger.error(e.getMessage(),e);
}
return audioInfo;
} //获取总页数页数
public static int getCount(String url) {
try {
Connection connect = Jsoup.connect(url).headers(HttpHtmlUtils.header_a);
Document document = connect.timeout(5000).get();
Elements els = document.getElementsByClass("pagingBar_page");
if(els.size() < 2) {
return 1;
}
Element pageCout = els.get(els.size()-2);
return Integer.valueOf(pageCout.text());
} catch (Throwable e) {
e.printStackTrace();
}
return 0;
} }
xmly.java
新浪新闻页面抓取(JAVA-Jsoup)的更多相关文章
- Python爬虫:新浪新闻详情页的数据抓取(函数版)
上一篇文章<Python爬虫:抓取新浪新闻数据>详细解说了如何抓取新浪新闻详情页的相关数据,但代码的构建不利于后续扩展,每次抓取新的详情页时都需要重新写一遍,因此,我们需要将其整理成函数, ...
- Python_网络爬虫(新浪新闻抓取)
爬取前的准备: BeautifulSoup的导入:pip install BeautifulSoup4 requests的导入:pip install requests 下载jupyter noteb ...
- selenium+BeautifulSoup+phantomjs爬取新浪新闻
一 下载phantomjs,把phantomjs.exe的文件路径加到环境变量中,也可以phantomjs.exe拷贝到一个已存在的环境变量路径中,比如我用的anaconda,我把phantomjs. ...
- python3爬虫-爬取新浪新闻首页所有新闻标题
准备工作:安装requests和BeautifulSoup4.打开cmd,输入如下命令 pip install requests pip install BeautifulSoup4 打开我们要爬取的 ...
- 门户级UGC系统的技术进化路线——新浪新闻评论系统的架构演进和经验总结(转)
add by zhj:先收藏了 摘要:评论系统是所有门户网站的核心标准服务组件之一.本文作者曾负责新浪网评论系统多年,这套系统不仅服务于门户新闻业务,还包括调查.投票等产品,经历了从单机到多机再到集群 ...
- 小爬新浪新闻AFCCL
1.任务目标: 爬取新浪新闻AFCCL的文章:文章标题.时间.来源.内容.评论数等信息. 2.目标网页: http://sports.sina.com.cn/z/AFCCL/ 3.网页分析 4.源代码 ...
- 今天写了一个简单的新浪新闻RSS操作类库
今天,有位群友问我如何获新浪新闻列表相关问题,我想,用正则表达式网页中取显然既复杂又不一定准确,现在许多大型网站都有RSS集合,所以我就跟他说用RSS应该好办一些. 一年前我写过一个RSS阅读器,不过 ...
- C# 页面抓取获取快递信息
通过页面抓取信息可以获得很多我们想要的信息,比如现在常会用到的快递查询,主要抓取的网站为http://www.kuaidi100.com/ 通过IE的网络分析我们可以得到下面信息 通过对这个网站的分析 ...
- Lance老师UI系列教程第八课->新浪新闻SlidingMenu界面的实现
UI系列教程第八课:Lance老师UI系列教程第八课->新浪新闻SlidingMenu界面的实现 今天蓝老师要讲的是关于新浪新闻侧滑界面的实现.先看看原图: 如图所示,这种侧滑效果以另一种方式替 ...
随机推荐
- Struts配置详解
一.Stuts的元素 1 web.xml 任何一个web应用程序都是基于请求响应模式进行构建的,所以无论采用哪种MVC框架,都离不开web.xml文件的配置.换句话说,web.xml并不是Struts ...
- 配置java项目的intellij idea的运行环境
才疏学浅,只懂一点点前端的皮毛东西,对于项目运行环境的配置一无所知,今天简单记录一下! 前提:装好了jdk.maven.intellij idea. 1. file菜单->Open...打开从S ...
- PHP成长之路之PHP连接MySql数据库(一)
PHP(外文名:PHP: Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用开源脚本语言.语法吸收了C语言.Java和Perl的特点,利于学习,使用广泛,主要适用于W ...
- 【ANT】时间戳
属性 说明 举例 DSTAMP 设置为当前日期,默认格式:yyyymmdd 20170309 TSTAMP 设置为当前时间,默认格式:hhmm 2007 TODAY 设置为当前日期,带完整的月份 Ma ...
- JavaScript闭包基本概念
闭包的概念 维基百科中是这么解释闭包的: 计算机科学中,闭包(也称为词法闭包或函数闭包)是指一个函数或函数的引用,与一个引用环境绑定在一起.这个函数环境是一个存储该函数每个非局部变量(也叫自由变量)的 ...
- 关于spring mybateis 定义resultType="java.util.HashMap"
关于spring mybateis 定义resultType="java.util.HashMap" List<HashMap<String, Object>& ...
- C/C++调用Golang 二
C/C++调用Golang 二 <C/C++调用Golang 一>简单介绍了C/C++调用Golang的方法步骤,只涉及一个简单的函数调用.本文总结具体项目中的使用场景,将介绍三种较复杂的 ...
- MHA高可用架构与Atlas读写分离
1.1 MHA简介 1.1.1 MHA软件介绍 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton ...
- 【http转https】其之一:腾讯云 DV SSL证书申请实验
文:铁乐猫 2016年1月 前言 大概2017年12月28日左右公司提出以后需要将公司网站由http提升到https级别,以便谷歌和火狐浏览器将之认定为安全网站. 主要是出于客户.用户那边用火狐或谷歌 ...
- 阿里云 redis 通过rinetd 进行端口透传
https://help.aliyun.com/document_detail/43850.html?spm=5176.7738718.2.3.yW2eyQ 目前云数据库 Redis 版需要通过 EC ...