python子域名收集器
今天心血来潮做了一个子域名收集器。过程是蛋疼啊!这里先感谢一下qpython群的咸鱼大佬,在换页的时候出了点毛病,讲到后面我们就知道了。
思路:

代码开始:
我们要用到的模块是
Requests
Bs4模块里的BeautifulSoup
Time模块
如果BeautifulSoup没有
安装方法:
LINUX:sudo pip install bs4
WINDOWS:pip install bs4
Import requests
From bs4 import BeautifulSoup
Import time
For i in range(48):
I=i*10#48*10=50我们爬50页
Heads={'User-Agent': 'Mozilla/5.0(Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
}#将自己伪装成浏览器
Url=”https://cn.bing.com/search?q=site%3adgjy.net&qs=n&sp=-1&pq=site%3adgjy.net&sc=2-11&sk=&cvid=C1A7FC61462345B1A71F431E60467C43&toHttps=1&redig=3FEC4F2BE86247E8AE3BB965A62CD454&pn=2&first={}&FORM=PERE”.format(i)#占位符会报错
#解析:q=你要搜索的东西 first=页数
First=1为第一页
First=10为第二页
以此类推
Html=request.urlopen(url,headers=heads)
soup=BeautifulSoup(html.content,'html.parser')
Job=soup.findAll(‘h2’)#列出h2标签
For i in job:
Time.sleep(3)#延迟3秒,防止被必应发现
Print(i.a.get(‘href’))
运行结果:
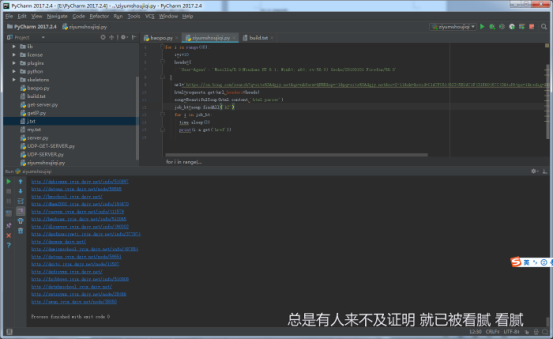
总结:
脚本代码:
import requests
from bs4 import BeautifulSoup
import time
for i in range(48):
i=i*10
heads={
'User-Agent': 'Mozilla/5.0(Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
}
url='https://cn.bing.com/search?q=site%3Adgjy.net&qs=n&form=QBRE&sp=-1&pq=site%3Adgjy.net&sc=2-11&sk=&cvid=C1A7FC61462345B1A71F431E60467C43&toHttps=1&redig=3FEC4F2BE86247E8AE3BB965A62CD454&pn=2&first={}&FROM=PERE'.format(i)
html=requests.get(url,headers=heads)
soup=BeautifulSoup(html.content,'html.parser')
job_bt=soup.findAll('h2')
for i in job_bt:
time.sleep(3)
print(i.a.get('href'))
python子域名收集器的更多相关文章
- bing搜索引擎子域名收集(Python脚本)
利用bing搜索引擎进行子域名收集,编写了一个简单的Python脚本,分享一下. #! /usr/bin/env python # _*_ coding:utf-8 _*_ import reques ...
- 子域名收集之DNS字典爆破工具fierce与dnsdict6的使用
子域名收集之DNS字典爆破工具fierce与dnsdict6的使用 一.fierce 0.介绍 该工具是一个域名扫描综合性工具.它可以快速获取指定域名的DNS服务器,并检查是否存在区域传输(Zone ...
- Python 爬虫练习(三) 利用百度进行子域名收集
不多介绍了,千篇一律的正则匹配..... import requests import re head = {'User-Agent': \ 'Mozilla/5.0 (Windows NT 6.3; ...
- PJzhang:经典子域名爆破工具subdomainsbrute
猫宁!!! 参考链接: https://www.waitalone.cn/subdomainsbrute.html https://www.secpulse.com/archives/5900.htm ...
- 使用python处理子域名爆破工具subdomainsbrute结果txt
近期学习了一段时间python,结合自己的安全从业经验,越来越感觉到安全测试是一个体力活.如果没有良好的coding能力去自动化的话,无疑会把安全测试效率变得很低. 作为安全测试而言,第一步往往要通过 ...
- python 信息收集器和CMS识别脚本
前言: 信息收集是渗透测试重要的一部分 这次我总结了前几次写的经验,将其 进化了一下 正文: 信息收集脚本的功能: 1.端口扫描 2.子域名挖掘 3.DNS查询 4.whois查询 5.旁站查询 CM ...
- ★Kali信息收集~3.子域名系列
★3.1Netcraft :子域名查询 官网:http://searchdns.netcraft.com/ 输入要查询的域名,即可得知子域名 3.2Fierce :子域名查询 概述: fierce ...
- 【Python】子域名查询脚本
脚本学习,多写写就会啦,来一发个人编写的超级无敌low的子域名查询脚本 #coding:utf-8 import re import requests import urllib import url ...
- 子域名查询、DNS记录查询
目录 子域名信息查询 Layer子域名爆破机 subDomainBrute 利用google查询 HTTP证书查询 DNS记录查询脚本 IP转换为经纬度 利用网页获取对方经纬度信息 首先关于DNS域名 ...
随机推荐
- Flink升级到1.4版本遇到的坑
Flink 1.4没出来以前,一直使用Flink 1.3.2,感觉还算稳定,最近将运行环境升级到1.4,遇到了一些坑: 1.需要将可运行程序,基于1.4.0重新编译一次 2.对比了一下flink-co ...
- SQL Server 修改AlwaysOn共享网络位置
标签:MSSQL/故障转移 概述 很多人一开始搭建Alwayson的时候对于共享网络位置的选择不是很重视, 导致后面需要去修改这个路径.但是怎样修改这个路径呢?貌似没有给出具体的修改选项,但是还是有地 ...
- 关于博客中引用多媒体出现的bug说明
插件说明 Aplayer.Dplayer @DIYgod 大佬在gihub的开源项目,对此,表示非常之感谢!! Aplayer 支持放在页首 支持放在页尾 但是不支持直接放在文章中引用 解决方法: 1 ...
- 如何在markdown中插入表情
Markdown是很好用的呀,个人灰常的喜欢,也是灰常漂亮的,但是如何在写文章的时候插入表情呢,下面给出一部分代码
- Tableau Desktop 10.4.2 的安装和激活
在安装之前,首先我们要弄清楚Tableau是个什么鬼东西,我们为什么需要安装这款软件? Tableau将数据运算与美观的图表完美地嫁接在一起.它的程序很容易上手,各公司可以用它将大量数据拖放到数字&q ...
- Mysql 锁基础
本文同时发表在https://github.com/zhangyachen/zhangyachen.github.io/issues/53 lock与latch 在数据库中,lock与latch都可以 ...
- bzoj 3597: [Scoi2014]方伯伯运椰子
Description Input 第一行包含二个整数N,M 接下来M行代表M条边,表示这个交通网络 每行六个整数,表示Ui,Vi,Ai,Bi,Ci,Di 接下来一行包含一条边,表示连接起点的边 Ou ...
- 菜鸟之旅——初识.NET
入坑.Net 也已经两年多了,既然在微软.Net 体系下混,对.Net 体系也需要了解一下,当然这些知识也都是查阅资料都能够查到的,这里主要是对自己所学的整理,况且最近的学习有些闭门造车的味道,现在想 ...
- Matplotlib初体验
为一个客户做了关于每个差异otu在时间点上变化的折线图,使用python第一次做批量作图的程序,虽然是很简单的折线图,但是也是第一次使用matplotlib的纪念. ps:在第一个脚本上做了点小的改动 ...
- <转>LOG日志级别
Level Description Example emerg Emergencies - system is unusable 紧急 - 系统无法使用 Child cannot open lock ...