Java 数据类型在实际开发中应用
在前边的博文中,我已经介绍了Java核心的容器IO等,现在我来说一下java中的数据类型。在java中,一切东西皆为对象(这句话意思是java中绝大数情况都用对象),极少数不是对象的,也存在与之对应的对象(比如基本数据类型存在与之对应的包装类,数组有List对象可以代替)
Java中数据类型 主要有“基本数据类型”、“String”、“引用类型” (基本的引用类型不多做介绍,在下一篇博文中着重介绍“枚举”,也算是引用类型的一种)
一:基本数据类型
1.1基本数据类型的定义
byte、char、int、 float 、double、long...这些属于java的基本数据类型。具体用法可以参照 (Java基本数据类型总结 ) .在java看来,使用基本类型并不是面向对象的设计,于是提供一些专门的包装类。实际开发中,不需要我们考虑到底是用基本类型还是包装类(Java提供了自动装箱机制)。当然基本类型还是有必要学习一下的。
1.1.1按种类了解基本类型
基本类型可以分为三类,字符类型char,布尔类型boolean以及数值类型byte、short、int、long、float、double。JAVA中的数值类型不存在无符号的,它们的取值范围是固定的,不会随着机器硬件环境或者操作系统的改变而改变
Java决定了每种简单类型的大小,并不随着机器结构的变化而变化。这正是Java程序具有很强移植能力的原因之一。下表列出了Java中定义的简单类型、占用二进制位数及对应的封装器类。
|
简单类型 |
boolean |
byte |
char |
short |
Int |
long |
float |
double |
void |
|
二进制位数 |
1 |
8 |
16 |
16 |
32 |
64 |
32 |
64 |
-- |
|
封装器类 |
Boolean |
Byte |
Character |
Short |
Integer |
Long |
Float |
Double |
Void |
这张表可以简单的看一下,但不推荐花费太多时间(实际开发不需要,如果是应付考试还是需要记一下的)。因为 Java语言之所以流行就是希望程序员可以消耗更少的心力在语法上,从而省出更多的时间去整理具体的业务逻辑。在基本数据类型这一块,Java提供自动装箱机制,下面简单介绍一下自动装箱。
1.1.2Java中自动装箱
自动装箱就可以简单的理解为将基本数据类型封装为对象类型,来符合java的面向对象。比如你可以直接把一个int值复制给一个Integer对象
//声明一个Integer对象
Integer num = 10;
自动装箱的时候,存在一个细节点就是“对于值从–128到127之间的值,它们被装箱为Integer对象后,会存在内存中被重用,始终只存在一个对象”,测试如下
//在-128~127 之外的数
Integer num1 = 297; Integer num2 = 297;
System.out.println("num1==num2: "+(num1==num2));
// 在-128~127 之内的数
Integer num3 = 97; Integer num4 = 97;
System.out.println("num3==num4: "+(num3==num4));
//测试结果:num1==num2: false \n num3==num4: true
有时候,只能用包装类,不能用基本数据类型,比如集合内
具体的细节可以参考这几位仁兄的博客 (Java 自动装箱与拆箱(Autoboxing and unboxing),java 自动装箱与拆箱)
1.2 基本数据类型的保存位置
基本类型存储在栈中,处于效率考虑,基本类型保存在栈中。延伸一下,包装类保存在堆中(注意我之前说过的-127到128之间的包装类Integer)
1.3 堆栈的简单介绍(这个和基本数据类型没有太大关系相当于是扩展内容)
Java的堆是一个运行时数据区,不需要程序代码来显式的释放,由垃圾回收来负责即可。堆的优势是可以动态地分配内存 大小,生存期也不必事先告诉编译器(因为是在运行时动态分配内存的,Java的垃圾收集器会自动收走这些不再使用的数据)。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。栈中主要存放一些基本类型的变量数据(int, short, long, byte, float, double, boolean, char)和引用数据类型(这个和基本数据类型无关,不多做介绍)
1.3.1 数据共享简单介绍
//基本数据类型的共享和对象不一样,对象共享的本质上是引用,对象修改会影响另外一个变量,基本类型只是共享的值,当值修改时,实际上是让变量又重新指向了另一个地方
public static void main(String[] args) { int a = 5; int b = 5;//一定是先找栈里有没有5,有就让b也指向5 a = 6; //先找栈里有没有6,如果没有则新建6并让a指向
System.out.println(b); }
1.3.2 局部变量与成员变量保存位置简单介绍
对于成员变量和局部变量:成员变量就是方法外部,类的内部定义的变量;局部变量就是方法或语句块内部定义的变量。局部变量必须初始化。
- 形式参数是局部变量,局部变量的数据存在于栈内存中。栈内存中的局部变量随着方法的消失而消失。
- 成员变量存储在堆中的对象里面,由垃圾回收器负责回收
1.class BirthDate {
2. private int day; //day是成员变量
3. private int month;
4. private int year;
5. public BirthDate(int d, int m, int y) {
6. day = d; //d是局部变量
7. month = m;
8. year = y;
9. }
10. 省略get,set方法………
11.}
1.3.3 java中常量简单介绍
- 十六进制整型常量:以十六进制表示时,需以0x或0X开头,如0xaa,0X9f。
- 八进制整型常量:八进制必须以0开头,如0123,034。
- 长整型: 长整型必须以L作结尾,如9L,342L。
- 浮点数常量: 由于小数常量的默认类型是double型,所以float类型的后面一定要加f(F)。同样带小数的变量默认为double类型。 如:float f;f=1.3f;//必须声明f。
- 字符常量: 字符型常量需用两个单引号括起来(注意字符串常量是用两个双引号括起来)。Java中的字符占两个字节。
1.4 Java基本类型的“类型转换”
简单类型数据间的转换,有两种方式:自动转换和强制转换,通常发生在表达式中或方法的参数传递时。
1.4.1 自动转换:是JVM根据条件自动帮助我们转换,可以简单了解一下转换规则。
当一个较"小"数据与一个较"大"的数据一起运算时,系统将自动将"小"数据转换成"大"数据,再进行运算 。
这些类型由"小"到"大"分别为 (byte,short,char)--int--long--float—double,这里我们所说的"大"与"小",并不是指占用字节的多少,而是指表示值的范围的大小 。所以byte --char--short之间不可以自动转换
1.4.2 强制转换:
将"大"数据转换为"小"数据时,你必须使用强制类型转换。即你必须采用下面这种语句格式: int n=(int)3.14159/2;可以想象,这种转换肯定可能会导致溢出或精度的下降
- 表达式的数据类型自动提升 eg 所有的byte,short,char型的值将被提升为int型;
- 包装类和基本类型转换 :实际上Java存在一个自动装箱的机制,他可以自动转换。但是,我们可以用构造器转为包装类;用包装类对象的xxxValue()把包装类转为基本类型
- 其它类型间转为字符串:①调用类的串转换方法:X.toString(); ②自动转换:X+""; ③使用String的方法:String.volueOf(X);
- 字符串转为其它类型 ①先转换成相应的封装器实例,再调用对应的方法转换成其它类型 new Double("3.1").doubleValue().或者Double.valueOf("32.1").doubleValue()②静态parseXXX方法String s = "1";byte b = Byte.parseByte( s );
- Date类与其它数据类型的相互转换 :整型和Date类之间并不存在直接的对应关系,只是你可以使用int型为分别表示年、月、日、时、分、秒,这样就在两者之间建立了一个对应关系 。具体转换,可能用到format类
1.4.3 备注
只有boolean不参与数据类型的转换
二:String类型
在实际开发中 String使用非常广泛。于是Java设计者针对String做了非常多的优化来提高效率,这虽然提高了程序的效率,但是在一定程度上也会给我们开发提高了难度,于是在Thinking in Java中单独把String当作一个章节。下面我会从整体上总结一下String,一些具体的方法可以去查询API(Java API)
2.1 String创建方式
new是按照面向对象的标准语法,在内存使用上存在比较大的浪费。所以String对象的创建是不需要new的(这样可以提高效率,但是如果用new创建字符串也不会报错)
2.1.1在这里,延伸一下,java中创建对象的方式一共存在五种:
分别是 new 关键字、Class类的 newInstance 方法、Constructor类的 newInstance 方法、String对象的 clone方法、反序列化机制。但是String对象还有一种特殊的创建方式,就是通过使用 “ 或 ’ 包裹字符序列
public static void main(String[] args)
{
String s = "Hello World!";//实际上当""的时候java就创建了该对象
System.out.println(s);
}
下面的代码详细的对比了java的正常创建形式(“”)和 new的区别 (参照自 深入理解Java:String ),在这里,我推荐一下 String的原理与用法总结 。该博主图画的还是挺清晰的,一目了然
public static void main(String[] args) {
String s1 = "abc";
// ↑ 在字符串池创建了一个对象
String s2 = "abc";
// ↑ 字符串pool已经存在对象“abc”(共享),所以创建0个对象,累计创建一个对象
System.out.println("s1 == s2 : " + (s1 == s2));
// ↑ true 指向同一个对象,
System.out.println("s1.equals(s2) : " + (s1.equals(s2)));
String s3 = new String("abc");
// ↑ 创建了两个对象,一个存放在字符串池中,一个存在与堆区中;
// ↑ 还有一个对象引用s3存放在栈中
String s4 = new String("abc");
// ↑ 字符串池中已经存在“abc”对象,所以只在堆中创建了一个对象
System.out.println("s3 == s4 : " + (s3 == s4));
// ↑false s3和s4栈区的地址不同,指向堆区的不同地址
System.out.println("s3.equals(s4) : " + (s3.equals(s4)));
// ↑true s3和s4的值相同
System.out.println("s1 == s3 : "+(s1==s3));
//↑false 存放的地区多不同,一个栈区,一个堆区
System.out.println("s1.equals(s3) : "+(s1.equals(s3)));
//↑true 值相同
/**
* 情景三:
* 由于常量的值在编译的时候就被确定(优化)了。
* 在这里,"ab"和"cd"都是常量,因此变量str3的值在编译时就可以确定。
* 这行代码编译后的效果等同于: String str3 = "abcd";
*/
String str1 = "ab" + "cd"; //1个对象
String str11 = "abcd";
System.out.println("str1 = str11 : "+ (str1 == str11));
/**
* 情景四:
* 局部变量str2,str3存储的是存储两个拘留字符串对象(intern字符串对象)的地址
* 第三行代码原理(str2+str3):
* 运行期JVM首先会在堆中创建一个StringBuilder类,
* 同时用str2指向的拘留字符串对象完成初始化,
* 然后调用append方法完成对str3所指向的拘留字符串的合并,
* 接着调用StringBuilder的toString()方法在堆中创建一个String对象,
* 最后将刚生成的String对象的堆地址存放在局部变量str4中
* 而str5存储的是字符串池中"abcd"所对应的拘留字符串对象的地址。
* str4与str5地址当然不一样了
* 内存中实际上有五个字符串对象:
* 三个拘留字符串对象、一个String对象和一个StringBuilder对象。
*/
String str2 = "ab"; //1个对象
String str3 = "cd"; //1个对象
String str4 = str2+str3;
String str5 = "abcd";
System.out.println("str4 = str5 : " + (str4==str5)); // false
//↑------------------------------------------------------over
/**
* 情景五:
* JAVA编译器对string + 基本类型/常量 是当成常量表达式直接求值来优化的。
* 运行期的两个string相加,会产生新的对象的,存储在堆(heap)中
*/
String str6 = "b";
String str7 = "a" + str6;
String str67 = "ab";
System.out.println("str7 = str67 : "+ (str7 == str67));
//↑str6为变量,在运行期才会被解析。
final String str8 = "b";
String str9 = "a" + str8;
String str89 = "ab";
System.out.println("str9 = str89 : "+ (str9 == str89));
//↑str8为常量变量,编译期会被优化
}
2.1.2 简单的概括一下:
用“”创建对象的时候,String对象是放到常量池中,只会创建一个,每次都是先去找一下常量池有没有该字符串
用 new创建对象,会在队中创建一个对象,然后在栈内创建该对象应用,每次都是新创建
2.2 String类初始化后是不可变的(immutable)
String类初始化之后不可变,因为java设计者不希望我们方法传参是字符串的时候,方法内修改会影响外边的串,所以采取了一种传递拷贝的方式(也就是传值)
String ss = "this is the origen String";
TestString.showString(ss);
public static void showString(String s){
System.out.println(s);
}
2.2.1 Java中String不可变是怎么一回事
java中,一旦产生String对象,该对象就不会在发生变化。但是String另一方面的确提供了修改String的方法。这看起来很矛盾,实际上是我们没有仔细的了解那些修改的方法
比如replace(),如果可以看到源码,可以清楚的看到该方法实际上新产生一个字符串,替换操作是针对新的字符串。(下图参考自参考Java进阶01 String类,简单的表示replace()方法调用时
s的变化)
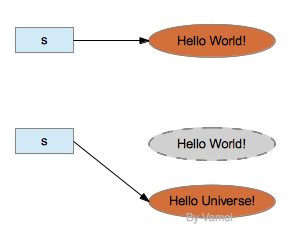
下边的代码 :我在原字符串的基础上添加了一句话,然后判断他们是否相同(如果是同一个对象修改,==输出结果应该是true)
String s1 = "我";
s1+="我想在加点东西";
system.out.println(s1 == s2)//输出结果是false
思考一下 "s1指向的对象中的字符串是什么"(我们潜意识的认为s1也会被修改,但是当s2 = "s2"时,实际上s2的引用已经被修改,它和s1没关系了)
String s1 = "s1";
String s2 = s1;
s2 = "s2";//s1指向的对象中的字符串是什么?
System.out.println(s1);//输出结果是s1
再重复一遍,无论是修改字符串的方法还是对字符串赋值,都和普通的对象不同。赋值是让字符串指向一个新的字符串,方法传参是copy一份值,传入进去。
再比如说:String str=”kv”+”ill”+” “+”ans”; 就是有4个字符串常量,首先”kv”和”ill”生成了”kvill”存在内存中,然后”kvill”又和” ” 生成 “kvill “存在内存中,最后又和生成了”kvill ans”;并把这个字符串的地址赋给了str
所以 + 会产生很多临时变量。下文中会说到StringBuilder 来避免这种情况。不过有一种特殊情况。 "ab"+"cd" 在JVM编译后和"abcd"一样
String str1 = "ab" + "cd"; //1个对象
String str11 = "abcd";
System.out.println("str1 = str11 : "+ (str1 == str11));
2.2.2 Java是怎样做到String的不可变的
在String源码中 ,使用private final char value[]来实现字符串的存储,就是因为final,才说String类型是不可变
/** The value is used for character storage. */
private final char value[];
2.3 String的保存位置
深入一点,我们了解一下String保存的位置(可以参考java+内存分配及变量存储位置的区别[转],java中的String类常量池详解)
String常量是保存在常量池中。JVM中的常量池在内存当中是以表的形式存在的, 对于String类型,有一张固定长度的CONSTANT_String_info表用来存储文字字符串值,注意:该表只存储文字字符串值,不存储符号引用。说到这里,对常量池中的字符串值的存储位置应该有一个比较明了的理解了。在程序执行的时候,常量池会储存在Method Area,而不是堆中。常量池中保存着很多String对象; 并且可以被共享使用,因此它提高了效率
什么是常量池
常量池指的是在编译期被确定,并被保存在已编译的.class文件中的一些数据。
除了包含代码中所定义的各种基本类型(如int、long等等)和对象型(如String及数组)的常量值(final)还包含一些以文本形式出现的符号引用。
2.4主要的方法
- s.length() 返回s字符串长度
- s.charAt(2) 返回s字符串中下标为2的字符
- s.substring(0, 4) 返回s字符串中下标0到4的子字符串
- s.indexOf("Hello") 返回子字符串"Hello"的下标
- s.startsWith(" ") 判断s是否以空格开始
- s.endsWith("oo") 判断s是否以"oo"结束
- s.equals("Good World!") 判断s是否等于"Good World!" ==只能判断字符串是否保存在同一位置。需要使用equals()判断字符串的内容是否相同。
- s.compareTo("Hello Nerd!") 比较s字符串与"Hello Nerd!"在词典中的顺序, 返回一个整数,如果<0,说明s在"Hello Nerd!"之前 如果>0,说明s在"Hello Nerd!"之后 如果==0,说明s与"Hello Nerd!"相等。
- s.trim() 去掉s前后的空格字符串,并返回新的字符串
- s.toUpperCase() 将s转换为大写字母,并返回新的字符串
- s.toLowerCase() 将s转换为小写,并返回新的字符串
- s.replace("World", "Universe") 将"World"替换为"Universe",并返回新的字符串
2.5:简单概括总结String中的细节点
总体来说,如果你还是对String感到困惑,不如把握住一点就是“ 创建时间” 如果编译期就知道是啥,会丢到常量池.
单独使用""引号创建的字符串都是常量,编译期就已经确定存储到String Pool中;
使用new String("")创建的对象会存储到heap中,是运行期新创建的;
使用只包含常量的字符串连接符如"aa" + "aa"创建的也是常量,编译期就能确定,已经确定存储到String Pool中;
使用包含变量的字符串连接符如"aa" + s1创建的对象是运行期才创建的,存储在heap中;
intern(): String实例调用该方法可以让JVM检查常量池,如果没有实例的value属性对应的字符串序列,就将本实例放入常量池,如果有则返回常量池中相对应的实例的引用而不是当前实例的引用
2.6 StringBuilder 和StringBuffer 和 +
首先StringBuilder 和StringBuffer区别是 StringBuffer线程安全(存在一堆synchronized)
其次,我们推荐用StringBuilder 而不是+ ,虽然+号在jvm中本质也是建StringBuilder,但是每s = s+"1";都会引入一个StringBuilder对象
String [] aaa = {"1","2","3"};
for (String s : aaa) {
s+="1";//每循环一次,都会产生一个StringBuilder对象
}
另外:StringBuilder允许我们在声明的时候指定大小,避免我们多次分配缓存
三:Java引用类型
Java有 5种引用类型(对象类型):类 接口 数组 枚举 标注。
new 的对象会放到java堆中,然后把引用放到栈内,这里不多加叙述
Java 数据类型在实际开发中应用的更多相关文章
- Java数据类型在实际开发中的应用一
在前边的博文中,我已经介绍了Java核心的容器IO等,现在我来说一下java中的数据类型.在java中,一切东西皆为对象(这句话意思是java中绝大数情况都用对象),极少数不是对象的,也存在与之对应的 ...
- Java数据类型在实际开发中的应用二枚举类型
在实际编程中,往往存在着这样的"数据集",它们的数值在程序中是稳定的,而且"数据集"中的元素是有限的.在JDK1.5之前,人们用接口来描述这一种数据类型. 1. ...
- Java 数据类型在实际开发中应用二枚举
在实际编程中,往往存在着这样的"数据集",它们的数值在程序中是稳定的,而且"数据集"中的元素是有限的.在JDK1.5之前,人们用接口来描述这一种数据类型. 1. ...
- Java 反射在实际开发中的应用
运行时类型识别(RTTI, Run-Time Type Information)是Java中非常有用的机制,在java中,有两种RTTI的方式,一种是传统的,即假设在编译时已经知道了所有的类型:还有一 ...
- [转]Java 反射在实际开发中的应用
一:Java类加载和初始化 1.1 类加载器(类加载的工具) 1.2 Java使用一个类所需的准备工作 二:Java中RTTI 2.1 :为什么要用到运行时类型信息(就是RTTI) 2.2 :RTT ...
- Java 泛型在实际开发中的应用
java泛型是对Java语言的类型系统的一种扩展,泛型的本质就是将所操作的数据类型参数化.下面我会由浅入深地介绍Java的泛型. 一:泛型出现的背景 在java代码里,你会经常发现类似下边的代码: p ...
- Android学习探索之Java 8 在Android 开发中的应用
前言: Java 8推出已经将近2年多了,引入很多革命性变化,加入了函数式编程的特征,使基于行为的编程成为可能,同时减化了各种设计模式的实现方式,是Java有史以来最重要的更新.但是Android上, ...
- Java IO在实际开发中的应用
IO是java绕不过去的槛,在开发中io无处不在, 正如同 世界上本没有路,java io写多了,也就知道了大体是什么意思,在读完thinking in java 感觉就更清晰了,结合具体的业务场景, ...
- Java和.NET在开发中的不同盘点
我是用VS2008和VS2010开发.NET程序,通过MyEclipse8.5开发JAVA程序,下面从IDE.语言.插件的不同点来做下简单的说明.但由于经验知识还有限,本篇文章只能从比较表面的以及自己 ...
随机推荐
- Js判断是否是直接进入本页面的
今天带来一个Js的小示例,用来判断当前页面的链接来路.很多人应该可以用到,这个虽然非常简单,但是用到的地方却还是挺多的 首先新建一个index.html,代码如下 <!DOCTYPE html& ...
- 侯捷STL学习(一)
开始跟着<STL源码剖析>的作者侯捷真人视频,学习STL,了解STL背后的真实故事! 视频链接:侯捷STL 还有很大其他视频需要的留言 第一节:STL版本和重要资源 STL和标准库的区别 ...
- R + ggplot2 Graph Catalog(转)
Joanna Zhao’s and Jenny Bryan’s R graph catalog is meant to be a complement to the physical book,Cre ...
- 打开Eclipse弹出“No java virtual machine was found..."的解决方法
今天准备用Eclipse抓取Android应用崩溃log,打开Eclipse时发现运行不了有以下弹框 A Java Runtime Environment(JRE) or Java Developme ...
- 02-C#(基础)基本的定义和说明
C#程序或DLL的源码是一组类型的声明 类:类型是一种模板,可以把类型想象成一个用来创建数据结构的模板.模板本身并不是数据结构,但它详细说明了该模板构造的对象的特征. 命名空间:它是一种把相关的类型声 ...
- ATmega8仿真——外部中断的学习
前面我们学习了ATmega8的I/O口作为通用数字输入/输出口来用时对LED数码管控制和扫描按键的应用: 但ATmega8多数的I/O口都是复用口,除了作为通用数字I/O使用,还有其第二功能,这里我们 ...
- Js实现京东无延迟菜单效果(demo)
一个端午节,外面人山人海,又那么热,我认为宅在家里看看慕课网,充实自己来的实际... 这是一个js实现京东无延迟菜单效果,感觉很好,分享给大家... 1.开发基本的菜单结构 2.开发普通的二级菜单效果 ...
- NFS文件共享
NFS文件共享 简介 NFS即网络文件系统(network file system),监听在TCP 2049端口. 服务器需要记住客户端的ip地址以及相应的端口信息,这些信息可以委托给RPC(remo ...
- Python抓取成都房价信息
Python里scrapy爬虫 scrapy爬虫,正好最近成都房价涨的厉害,于是想着去网上抓抓成都最近的房价情况,顺便了解一下,毕竟咱是成都人,得看看这成都的房子我以后买的起不~ 话不多说,进入正题: ...
- 官方 React 快速上手脚手架 create-react-app
此文简单讲解了官方 React 快速上手脚手架的安装与介绍. 1. React 快速上手脚手架 create-react-app 为了快速地进行构建使用 React 的项目,FaceBook 官方发布 ...