一个比较完善的httpWebRequest 封装,适合网络爬取及暴力破解
大家在模拟http请求的时候,对保持长连接及cookies,http头部信息等了解的不是那么深入。在各种网络请求过程中,发送N种问题。
可能问题如下:
1)登录成功后session保持
2)保证所有cookies回传到服务器
3)http头这么多,少一个,请求可能会失败
4)各种编码问题,gzip等压缩问题
为了解决这些问题,本人花了一天时间写了以下一个类,专门做http请求
using System;
using System.Collections.Generic;
using System.IO;
using System.IO.Compression;
using System.Linq;
using System.Net;
using System.Text;
using System.Threading.Tasks; namespace ScanWeb
{
//zetee
//不能Host、Connection、User-Agent、Referer、Range、Content-Type、Content-Length、Expect、Proxy-Connection、If-Modified-Since
//等header. 这些header都是通过属性来设置的 。
public class HttpRequestClient
{
static HashSet<String> UNCHANGEHEADS = new HashSet<string>();
static HttpRequestClient()
{
UNCHANGEHEADS.Add("Host");
UNCHANGEHEADS.Add("Connection");
UNCHANGEHEADS.Add("User-Agent");
UNCHANGEHEADS.Add("Referer");
UNCHANGEHEADS.Add("Range");
UNCHANGEHEADS.Add("Content-Type");
UNCHANGEHEADS.Add("Content-Length");
UNCHANGEHEADS.Add("Expect");
UNCHANGEHEADS.Add("Proxy-Connection");
UNCHANGEHEADS.Add("If-Modified-Since");
UNCHANGEHEADS.Add("Keep-alive");
UNCHANGEHEADS.Add("Accept"); ServicePointManager.DefaultConnectionLimit = ;//最大连接数 } /// <summary>
/// 默认的头
/// </summary>
public static string defaultHeaders = @"Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding:gzip, deflate, sdch
Accept-Language:zh-CN,zh;q=0.8
Cache-Control:no-cache
Connection:keep-alive
Pragma:no-cache
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"; /// <summary>
/// 是否跟踪cookies
/// </summary>
bool isTrackCookies = false;
/// <summary>
/// cookies 字典
/// </summary>
Dictionary<String, Cookie> cookieDic = new Dictionary<string, Cookie>(); /// <summary>
/// 平均相应时间
/// </summary>
long avgResponseMilliseconds = -; /// <summary>
/// 平均相应时间
/// </summary>
public long AvgResponseMilliseconds
{
get
{
return avgResponseMilliseconds;
} set
{
if (avgResponseMilliseconds != -)
{
avgResponseMilliseconds = value + avgResponseMilliseconds / ;
}
else
{
avgResponseMilliseconds = value;
} }
} public HttpRequestClient(bool isTrackCookies = false)
{
this.isTrackCookies = isTrackCookies;
}
/// <summary>
/// http请求
/// </summary>
/// <param name="url"></param>
/// <param name="method">POST,GET</param>
/// <param name="headers">http的头部,直接拷贝谷歌请求的头部即可</param>
/// <param name="content">content,每个key,value 都要UrlEncode才行</param>
/// <param name="contentEncode">content的编码</param>
/// <param name="proxyUrl">代理url</param>
/// <returns></returns>
public string http(string url, string method, string headers, string content, Encoding contentEncode, string proxyUrl)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Method = method;
if(method.Equals("GET",StringComparison.InvariantCultureIgnoreCase))
{
request.MaximumAutomaticRedirections = ;
request.AllowAutoRedirect = false;
} fillHeaders(request, headers);
fillProxy(request, proxyUrl); #region 添加Post 参数
if (contentEncode == null)
{
contentEncode = Encoding.UTF8;
}
if (!string.IsNullOrWhiteSpace(content))
{
byte[] data = contentEncode.GetBytes(content);
request.ContentLength = data.Length;
using (Stream reqStream = request.GetRequestStream())
{
reqStream.Write(data, , data.Length);
reqStream.Close();
}
}
#endregion HttpWebResponse response = null;
System.Diagnostics.Stopwatch sw = new System.Diagnostics.Stopwatch();
try
{
sw.Start();
response = (HttpWebResponse)request.GetResponse();
sw.Stop();
AvgResponseMilliseconds = sw.ElapsedMilliseconds;
CookieCollection cc = new CookieCollection();
string cookieString = response.Headers[HttpResponseHeader.SetCookie];
if (!string.IsNullOrWhiteSpace(cookieString))
{
var spilit = cookieString.Split(';');
foreach (string item in spilit)
{
var kv = item.Split('=');
if (kv.Length == )
cc.Add(new Cookie(kv[].Trim(), kv[].Trim()));
}
}
trackCookies(cc);
}
catch (Exception ex)
{
sw.Stop();
AvgResponseMilliseconds = sw.ElapsedMilliseconds;
return "";
} string result = getResponseBody(response);
return result;
} /// <summary>
/// post 请求
/// </summary>
/// <param name="url"></param>
/// <param name="headers"></param>
/// <param name="content"></param>
/// <param name="contentEncode"></param>
/// <param name="proxyUrl"></param>
/// <returns></returns>
public string httpPost(string url, string headers, string content, Encoding contentEncode, string proxyUrl = null)
{
return http(url, "POST", headers, content, contentEncode, proxyUrl);
} /// <summary>
/// get 请求
/// </summary>
/// <param name="url"></param>
/// <param name="headers"></param>
/// <param name="content"></param>
/// <param name="proxyUrl"></param>
/// <returns></returns>
public string httpGet(string url, string headers, string content=null, string proxyUrl=null)
{
return http(url, "GET", headers, null, null, proxyUrl);
} /// <summary>
/// 填充代理
/// </summary>
/// <param name="proxyUri"></param>
private void fillProxy(HttpWebRequest request, string proxyUri)
{
if (!string.IsNullOrWhiteSpace(proxyUri))
{
WebProxy proxy = new WebProxy();
proxy.Address = new Uri(proxyUri);
request.Proxy = proxy;
}
} /// <summary>
/// 跟踪cookies
/// </summary>
/// <param name="cookies"></param>
private void trackCookies(CookieCollection cookies)
{
if (!isTrackCookies) return;
if (cookies == null) return;
foreach (Cookie c in cookies)
{
if (cookieDic.ContainsKey(c.Name))
{
cookieDic[c.Name] = c;
}
else
{
cookieDic.Add(c.Name, c);
}
} } /// <summary>
/// 格式cookies
/// </summary>
/// <param name="cookies"></param>
private string getCookieStr()
{
StringBuilder sb = new StringBuilder();
foreach (KeyValuePair<string, Cookie> item in cookieDic)
{
if (!item.Value.Expired)
{
if (sb.Length == )
{
sb.Append(item.Key).Append("=").Append(item.Value.Value);
}
else
{
sb.Append("; ").Append(item.Key).Append(" = ").Append(item.Value.Value);
}
}
}
return sb.ToString(); } /// <summary>
/// 填充头
/// </summary>
/// <param name="request"></param>
/// <param name="headers"></param>
private void fillHeaders(HttpWebRequest request, string headers, bool isPrint = false)
{
if (request == null) return;
if (string.IsNullOrWhiteSpace(headers)) return;
string[] hsplit = headers.Split(new String[] { "\r\n" }, StringSplitOptions.RemoveEmptyEntries);
foreach (string item in hsplit)
{
string[] kv = item.Split(':');
string key = kv[].Trim();
string value = string.Join(":", kv.Skip()).Trim();
if (!UNCHANGEHEADS.Contains(key))
{
request.Headers.Add(key, value);
}
else
{
#region 设置http头
switch (key)
{ case "Accept":
{
request.Accept = value;
break;
}
case "Host":
{
request.Host = value;
break;
}
case "Connection":
{
if (value == "keep-alive")
{
request.KeepAlive = true;
}
else
{
request.KeepAlive = false;//just test
}
break;
}
case "Content-Type":
{
request.ContentType = value;
break;
} case "User-Agent":
{
request.UserAgent = value;
break;
}
case "Referer":
{
request.Referer = value;
break;
} case "Content-Length":
{
request.ContentLength = Convert.ToInt64(value);
break;
}
case "Expect":
{
request.Expect = value;
break;
}
case "If-Modified-Since":
{
request.IfModifiedSince = Convert.ToDateTime(value);
break;
}
default:
break;
}
#endregion
}
}
CookieCollection cc = new CookieCollection();
string cookieString = request.Headers[HttpRequestHeader.Cookie];
if (!string.IsNullOrWhiteSpace(cookieString))
{
var spilit = cookieString.Split(';');
foreach (string item in spilit)
{
var kv = item.Split('=');
if (kv.Length == )
cc.Add(new Cookie(kv[].Trim(), kv[].Trim()));
}
}
trackCookies(cc);
if (!isTrackCookies)
{
request.Headers[HttpRequestHeader.Cookie] = "";
}
else
{
request.Headers[HttpRequestHeader.Cookie] = getCookieStr();
} #region 打印头
if (isPrint)
{
for (int i = ; i < request.Headers.AllKeys.Length; i++)
{
string key = request.Headers.AllKeys[i];
System.Console.WriteLine(key + ":" + request.Headers[key]);
}
}
#endregion } /// <summary>
/// 打印ResponseHeaders
/// </summary>
/// <param name="response"></param>
private void printResponseHeaders(HttpWebResponse response)
{
#region 打印头
if (response == null) return;
for (int i = ; i < response.Headers.AllKeys.Length; i++)
{
string key = response.Headers.AllKeys[i];
System.Console.WriteLine(key + ":" + response.Headers[key]);
}
#endregion
} /// <summary>
/// 返回body内容
/// </summary>
/// <param name="response"></param>
/// <returns></returns>
private string getResponseBody(HttpWebResponse response)
{
Encoding defaultEncode = Encoding.UTF8;
string contentType = response.ContentType;
if (contentType != null)
{
if (contentType.ToLower().Contains("gb2312"))
{
defaultEncode = Encoding.GetEncoding("gb2312");
}
else if (contentType.ToLower().Contains("gbk"))
{
defaultEncode = Encoding.GetEncoding("gbk");
}
else if (contentType.ToLower().Contains("zh-cn"))
{
defaultEncode = Encoding.GetEncoding("zh-cn");
}
} string responseBody = string.Empty;
if (response.ContentEncoding.ToLower().Contains("gzip"))
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream))
{
responseBody = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, defaultEncode))
{
responseBody = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())
{
using (StreamReader reader = new StreamReader(stream, defaultEncode))
{
responseBody = reader.ReadToEnd();
}
}
}
return responseBody;
} public static string UrlEncode(string item, Encoding code)
{
return System.Web.HttpUtility.UrlEncode(item.Trim('\t').Trim(), Encoding.GetEncoding("gb2312"));
} public static string UrlEncodeByGB2312(string item)
{
return UrlEncode(item, Encoding.GetEncoding("gb2312"));
} public static string UrlEncodeByUTF8(string item)
{
return UrlEncode(item, Encoding.GetEncoding("utf-8"));
} public static string HtmlDecode(string item)
{
return WebUtility.HtmlDecode(item.Trim('\t').Trim());
} }
}
完整的封装类
使用方式:
1)打开谷歌浏览器,或者F12
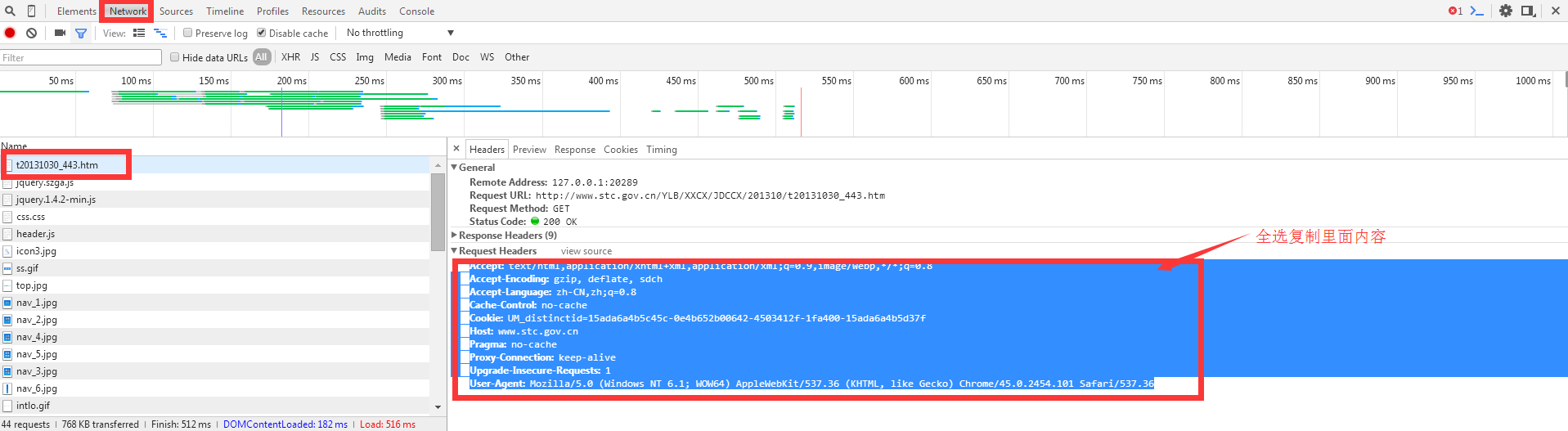
复制Request Headers 里面的所有内容,然后执行代码:
string heads = @"Accept:text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.8
Cache-Control:no-cache
Content-Length:251
Content-Type:application/x-www-form-urlencoded; charset=UTF-8
Cookie:JSESSIONID=B1716F5DAC2F78D1E592F5421D859CFA; Hm_lvt_f44f38cf69626ed8bcfe92d72ed55922=1498099203; Hm_lpvt_f44f38cf69626ed8bcfe92d72ed55922=1498099203; cache_cars=152%7C152%7CBDL212%7C111111%7C111111%2C152%7C152%7CBy769x%7C111111%7C111111%2C152%7C152%7Cd12881%7C111111%7C111111
Host:www.xxxxxxxx.com
Origin:http://www.xxxxxxxx.com
Pragma:no-cache
Proxy-Connection:keep-alive
Referer:http://www.cheshouye.com/api/weizhang/
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36
X-Requested-With:XMLHttpRequest"; string url = "http://www.xxxxxxxxxxxx.com/api/weizhang/open_task?callback=jQuery1910816327";
HttpRequestClient s = new HttpRequestClient(true);
string content = "chepai_no=b21451&chejia_no=111111&engine_no=111111&city_id=152&car_province_id=12&input_cost=0&vcode=%7B%22cookie_str%22%3A%22%22%2C%22verify_code%22%3A%22%22%2C%22vcode_para%22%3A%7B%22vcode_key%22%3A%22%22%7D%7D&td_key=qja5rbl2d97n&car_type=02&uid=0";
string response= s.httpPost(url, heads, content, Encoding.UTF8);
就这样,你会惊喜的发现,卧槽!反回来的值和谷歌上显示值一个样子,
只要域名没变化,HttpRequestClient 对象就不要去改变, 多线程请使用ThreadLocal<HttpRequestClient >
配合我很久之前写的多线类 QueueThreadBase 让你起飞.
你想暴力破解网站登录密码吗?基本思路如下:
1)强大的用户名+密码字典
2)多线程Http+代理(代理可以不用,如果服务器做了ip限制,那么代理就非常有用了,最好是透明的http代理,并且有规则剔除慢的代理)
3)验证码破解.(只要验证码不复杂,在某宝就能买的dll 可用,1000块钱上下)
4)慢慢等......看奇迹发生,(我已经做好了一个,各位程序员我屁股已经翘好,等你一脚)
一个比较完善的httpWebRequest 封装,适合网络爬取及暴力破解的更多相关文章
- 使用Node.js实现简单的网络爬取
由于最近要实现一个爬取H5游戏的代理服务器,隧看到这么一篇不错的文章(http://blog.miguelgrinberg.com/post/easy-web-scraping-with-nodejs ...
- pyhton 网络爬取软考题库保存text
#-*-coding:utf-8-*-#参考文档#https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#find-al ...
- seo-mask -- 为单页应用创建一个适合蜘蛛爬取的seo网站
seo-mask seo-mask是利用搜索引擎蜘蛛的爬取原理(蜘蛛只会爬取网页的内容,并不会关心解析网页里的css和js),制作一套专门针对seo的镜像网站,鄙人称它为针对seo的mask,让蜘蛛看 ...
- B站真的是一个神奇的地方,初次用Python爬取弹幕。
"网上冲浪""886""GG""沙发"--如果你用过这些,那你可能是7080后: "杯具"" ...
- Python3爬虫(1)_使用Urllib进行网络爬取
网络爬虫 又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫 ...
- python Requests库网络爬取IP地址归属地的自动查询
#IP地址查询全代码import requestsurl = "http://m.ip138.com/ip.asp?ip="try: r = requests.get(url + ...
- Python Requests库网络爬取全代码
#爬取京东商品全代码 import requestsurl = "http://item.jd.com/2967929.html"try: r = requests.get(url ...
- 用WebCollector制作一个爬取《知乎》并进行问题精准抽取的爬虫(JAVA)
简单介绍: WebCollector是一个无须配置.便于二次开发的JAVA爬虫框架(内核),它提供精简的的API.仅仅需少量代码就可以实现一个功能强大的爬虫. 怎样将WebCollector导入项目请 ...
- 基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
原文地址http://blog.csdn.net/qy20115549/article/details/52203722 本文为原创博客,仅供技术学习使用.未经允许,禁止将其复制下来上传到百度文库等平 ...
随机推荐
- hdu2389二分图之Hopcroft Karp算法
You're giving a party in the garden of your villa by the sea. The party is a huge success, and every ...
- poj1269计算几何直线和直线的关系
We all know that a pair of distinct points on a plane defines a line and that a pair of lines on a p ...
- Bash 的若干基本问题
Bash 的若干基本问题 这里介绍一些bash启动前.后的问题,以及一些使用bash需要注意的基本问题. 1.Bash的介绍 Bash是一种Shell程序,它是一般的Linux系统中的 ...
- 在SCIKIT中做PCA 逆运算 -- 新旧特征转换
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- Java中实现String.padLeft和String.padRight
因为习惯了C#中的padLeft和padRight,接触Java后突然失去这两个功能,觉得别扭,就试着实现了这两个方法. Java中String.format()中带有字符串对齐功能如下: Syste ...
- OC中Foundation框架之NSArray、NSMutableArray
NSArray概述 NSArray是OC中的数组类 NSArray特点 )只能存放任意OC对象,并且是有顺序的 )不能存放非OC对象,比如int/float/double/char/enum/stru ...
- ActiveXObject函数详解(转自http://eyesinthesky.iteye.com/blog/1560033)
什么是 ActiveX 控件? ActiveX 控件广泛用于 Internet.它们可以通过提供视频.动画内容等来增加浏览的乐趣.不过,这些程序可能出问题或者向您提供不需要的内容.在某些情况下,这些程 ...
- Linux的环境变量设置和查看
一.Linux的变量种类 按变量的生存周期来划分,Linux变量可分为两类: 1.永久的:需要修改配置文件,变量永久生效. 2.临时的:使用export命令声明即可,变量在关闭shell时失效. 二. ...
- 初识数据库连接池开源框架Druid
Druid是阿里巴巴的一个数据库连接池开源框架,准确来说它不仅仅包括数据库连接池这么简单,它还提供强大的监控和扩展功能.本文仅仅是在不采用Spring框架对Druid的窥探,采用目前最新版本druid ...
- Ubuntu怎样进行自由截图操作
全屏截图 1. 很简单,键盘上右上角都有一个 Print Screen按键,敲一下,全屏截图操作完成. 自由截图 1. 此种方式很简单,打开系统设置->键盘,进入shortcuts选项 2. 点 ...