Storm(2015.08.12笔记)
2015.08.12Storm
一、Storm简介
Storm是Twitter开源的一个类似于Hadoop的实时数据处理框架。
Storm能实现高频数据和大规模数据的实时处理。
官网资料显示storm的一个节点在1秒钟能够处理100万个100字节的消息(IntelE5645@2.4Ghz的CPU,24GB的内存)
(storm +kafka+flume)
二、HADOOP与STORM比较
数据来源:HADOOP处理的是HDFS上TB级别的数据(历史数据),STORM是处理的是实时新增的某一笔数据(实时数据);
处理过程:HADOOP是分MAP阶段和REDUCE阶段,STORM是由用户定义处理流程,流程中可以包含多个步骤,每个步骤可以是数据源(SPOUT)或处理逻辑(BOLT);
是否结束:HADOOP最后是要结束的,STORM是没有结束状态,到最后一步时,就停在那,直到有新数据进入时再从头开始;
处理速度:HADOOP是以处理HDFS上大量数据为目的,处理速度慢,STORM是只要处理新增的某一笔数据即可,可以做到很快;
适用场景:HADOOP是在要处理批量数据时用的,不讲究时效性,STORM是要处理某一新增数据时用的,要讲时效性;

package storm;
import java.util.Map;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
/**
* 数据累加的操作,spout产生数据(在这里自己产生),bolt对数据累加求和
* @author Administrator
*
*/
public
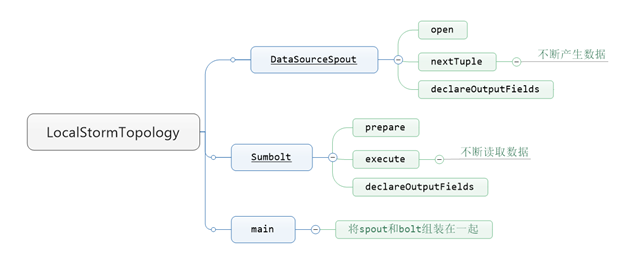
class LocalStormTopology {//都在一个类里面实现,需要写一个静态name类
public
static
class
DataSourceSpout
extends BaseRichSpout{//spout继承BaseRichSpout类,它有3个未实现的方法
private
Map
conf;//第一个未实现的方法。不知道会不会用上,先保存
private TopologyContext context;
private SpoutOutputCollector collector;
/**
* 本实例运行的是被调用一次,只能执行一次。
*/
public
void open(Map
conf, TopologyContext context,
SpoutOutputCollector collector) {//第一个未实现的方法,本实例运行时被调用一次,Map conf配置参数,可以获取topology的配置信息,TopologyContext理解为Topology的上下文,collector,发射器,将spout产生的数据发射出去
this.conf = conf;
this.context = context;
this.collector = collector;
}
/**
* 死循环的调用,心跳
*/
int
i=0;
public
void nextTuple() {//第二个未实现的方法,程序运行过程中不断被调用,调用此方法会不断产生数据
System.out.println("spout:"+i);//打印每次产生的数据
this.collector.emit(new Values(i++));//将产生的数据发射出去,发射需要emit这个方法,接受的是tuple,是list类型,tuple里面放的是列表的数据,里面是封装了列表;storm里面封装了一个values类,new Values相当于一个tuple,直接将i传进去,点进去,他继承了ArrayList,相当于创建了一个list,往list里面添加一个元素,每次都会发送数据,所以i++,每次递增加一
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* declarer方法的意思是声明输出的内容
*/
public
void declareOutputFields(OutputFieldsDeclarer declarer) {//第三个未实现的方法,spout只管发射数据,不指定目标,需要指定发射数据的的名称,bolt读取有标示的数据
declarer.declare(new Fields("num"));//declare方法接受参数fields,就new一个Fields,Fileds可接受一个可变参数(3个点)或者传一个list列表,需要指定一个字段名称,自定义为num。前面tuple封装了一个数据,这里对应也是一个字段,如果前面发射两个参数(i++,i+2),这里就指定2个字段('num''num'),bolt可通过num(num2)字段获取i++数据(i+2)。spout发射的数据与字段num做了关联
}
}
//写一个静态name类,也要实现3个未实现的方法
public
static
class
Sumbolt
extends BaseRichBolt{
private
Map
stormConf;
private TopologyContext context;
private OutputCollector collector;
public
void prepare(Map
stormConf, TopologyContext context,
OutputCollector collector) {//第一个未实现的方法
this.stormConf = stormConf;
this.context = context;
this.collector = collector;//只会用到这个
}
int
sum = 0;
public
void execute(Tuple input) {//这个方法,bolt也有个死循环,不断读取数据,每次获取的也是一个Tuple
//input.getInteger(0);//通过get方法Integer传递的是参数,获取的数据是列表的脚标,获取的是list的元素,不建议使用这种方式。
Integer value = input.getIntegerByField("num");//因为之前已经指定了num字段,所以通过num字段获取i++的值,使用declare方法指定的字段
sum+=value;//因为bolt需要对获取的字段的值累加求和
System.out.println("sum:"+sum);//直接将sum打印出来,打印每次累加求和的结果
//this.collector.emit(tuple);
}
public
void declareOutputFields(OutputFieldsDeclarer declarer) {
//因为这个bolt已经是最后一个bolt,bolt不需要往外发射数据,这里不需要定义字段
}
}
//需要topology。main函数将spout和bolt组装在一起
public
static
void main(String[] args) {
TopologyBuilder topologyBuilder = new TopologyBuilder();//先new TopologyBuilder,
topologyBuilder.setSpout("spout_id", new DataSourceSpout());//首先设置spout,id简单自定义为spout_id,后面需要具体指定spout类
topologyBuilder.setBolt("bolt_id", new Sumbolt()).shuffleGrouping("spout_id");//需要将spout和bolt连接起来,bolt接spout,在bolt调用一个方法shuffleGrouping(指定'spout_id')
LocalCluster localCluster = new LocalCluster();//组装后需要运行,在本地运行,造一个本地的轨道
localCluster.submitTopology("topology", new Config(), topologyBuilder.createTopology());//第一个是topology的名称,第二个是配置参数是map结构,storm提供了一个配置类,new Config(点进去,继承了HashMap),后面需要一个storm Topology,我们指定为topologyBuilder.createTopology()
}
}
Storm(2015.08.12笔记)的更多相关文章
- Zookepper(2015.08.16笔记)
2015.08.16zookepper Zookeeper 是 Google 的 Chubby一个开源的实现,是 Hadoop 的分布式协调服务(如同小区里面的供水.电的系统) 它包含一个简单的原 ...
- Redis(2015.08.03笔记一)
一.redis简介 Redis是一种面向"键/值"对数据类型的内存数据库,可以满足我们对海量数据的读写需求. redis的键只能是字符串 redis的值支持多种数据类型: 1:字符 ...
- 2015年12月28日 Java基础系列(六)流
2015年12月28日 Java基础系列(六)流2015年12月28日 Java基础系列(六)流2015年12月28日 Java基础系列(六)流
- 2015年12月13日 spring初级知识讲解(四)面向切面的Spring
2015年12月13日 具体内容待补充...
- 【C++】命令行Hangman #2015年12月15日 00:20:27
增加了可以在构造Hangman对象时通过传入参数设定“最大猜测次数”的功能.少量修改.# 2015年12月15日 00:20:22 https://github.com/shalliestera/ha ...
- 我的Python成长之路---第一天---Python基础(作业2:三级菜单)---2015年12月26日(雾霾)
作业二:三级菜单 三级菜单 可一次进入各个子菜单 思路: 这个题看似不难,难点在于三层循环的嵌套,我的思路就是通过flag的真假来控制每一层的循环的,简单来说就是就是通过给每一层循环一个单独的布尔变量 ...
- 我的Python成长之路---第一天---Python基础(作业1:登录验证)---2015年12月26日(雾霾)
作业一:编写登录接口 输入用户名密码 认证成功系那是欢迎信息 输错三次后锁定 思路: 1.参考模型,这个作业我参考了linux的登录认证流程以及结合网上银行支付宝等锁定规则 1)认证流程参考的是Lin ...
- 我的Python成长之路---第一天---Python基础(1)---2015年12月26日(雾霾)
2015年12月26日是个特别的日子,我的Python成之路迈出第一步.见到了心目中的Python大神(Alex),也认识到了新的志向相投的伙伴,非常开心. 尽管之前看过一些Python的视频.书,算 ...
- 新手C#SQLServer在程序里实现语句的学习2018.08.12
从C#中连接到SQL Server数据库,再通过C#编程实现SQL数据库的增删改查. ado.net提供了丰富的数据库操作,这些操作可以分为三个步骤: 第一,使用SqlConnection对象连接数据 ...
随机推荐
- CXF_Spring_Rest
一.接口类 <PRE class=java name="code">@Path("/rest_HelloWorld") public interfa ...
- 微端游戏启动器LAUNCHER的制作之MFC版一(序和进程通信)
额...刚开始信誓旦旦说要写launcher制作的博客,还没写完就被抛到脑后了真是没毅力.最近把之前写的wpf的launcher改成了mfc版,遇到很多问题,写了三个星期才写完,好好记录一下吧.我也想 ...
- iOS开发tips-UITableView、UICollectionView行高/尺寸自适应
UITableView 我们都知道UITableView从iOS 8开始实现行高的自适应相对比较简单,首先必须设置estimatedRowHeight给出预估高度,设置rowHeight为UITabl ...
- 浅谈 MVC中的ViewData、ViewBag和TempData
ViewBag和TempData的区别 ViewData ViewBag 它是Key/Value字典集合 它是dynamic类型对像 从Asp.net MVC 1 就有了 ASP.NET MVC3 才 ...
- runtime ---- iOS
1.runtime是什么?runtime是一套底层的C语言的API(包括C语言数据类型,C语言函数) 实际上平时我们写的OC代码底层都是基于runtime,实际上也就是最后都转成了runtime代码 ...
- Python2和Python3中除法操作/的不同
X/Y 在3.0版本之前的Python中 >>>1/2 0 即一个整数(无小数部分的数)被另外一个整数除,计算结果的小数部分被截除了,只留下了整数部分 有时候,这个功能比较有用,譬如 ...
- PHP中的 !== 与 !=
'==' 比较两边的值是否相等,会自动转换类型: '===' 则会严格比较类型是否相同,如果类型不相同,直接返回false. 例如:'123' === 123 // => false '!=' ...
- ABP入门系列(11)——编写单元测试
ABP入门系列目录--学习Abp框架之实操演练 源码路径:Github-LearningMpaAbp 1. 前言 In computer programming, unit testing is a ...
- [转]支持向量机SVM总结
首先,对于支持向量机(SVM)的简单总结: 1. Maximum Margin Classifier 2. Lagrange Duality 3. Support Vector 4. Kernel 5 ...
- linux 下rabbitmq 安装
准备工作: erlang环境 otp_src_19.0.tar.gz rabbitmq abbitmq-server-generic-unix-3.6.5.tar.xz # yum -y ins ...