sed修炼系列(三):sed高级应用之实现窗口滑动技术
sed系列文章:
sed修炼系列(一):花拳绣腿之入门篇
sed修炼系列(二):武功心法(info sed翻译+注解)
sed修炼系列(三):sed高级应用之实现窗口滑动技术
sed修炼系列(四):sed中的疑难杂症
1.什么是滑动窗口(slide window)技术
一图胜千言。
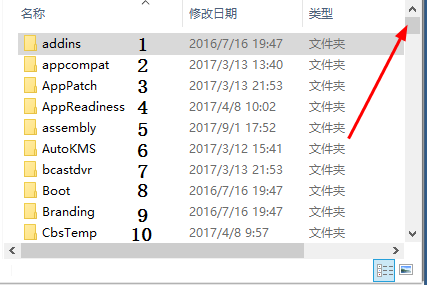
在上图中,资源管理器的高度固定为正好装下10行文件名,如果想要显示第11行,就要下拉滚动条一行的距离,使得11行正好能显示出来。但这时,最旧的第一行就会被踢出当前可视窗口。
滑动窗口的意思大致就是如此。维护一个窗口,当向窗口添加新数据时,旧的数据就被剔除出去,保证窗口的大小固定。当然,还有动态的大小不固定的窗口,此时根据其他规则来判断是否要剔除旧数据以及剔除哪些旧数据。
在sed的高级用法中,窗口滑动技术作用非常大,这也是"N"、"D"和"P"重要的原因。sed以模式空间为"主战场",以保持空间为"副战场"。所以sed要维护"窗口"只能通过模式空间,因为只有在模式空间中才能决定是否要踢掉旧数据以及踢掉哪些旧数据。但很多时候还会辅以保持空间,将每次操作完的窗口数据暂存到保持空间,并在下一个循环中将数据从保持空间拿回来维护一番。
下面是一些示例和窗口技术的用法说明。
2.实现窗口滑动
假如想要输出文件a.txt的前10行。这很简单。
sed '10q' a.txt
由于"q"命令在退出sed程序前会输出模式空间内容,所以第10行也会被输出,如果使用的是"Q"命令,则应该为:
sed 11Q a.txt
难题来了,想输出倒数10行要怎么实现,倒数15行?倒数20行?。再通用化一些,怎么能实现tail工具的倒数行查看功能呢。
2.1 通过"s"命令滑动窗口
由于sed是"一往无前,绝不回头"的流式处理器,任何一份输入流只要被读取过绝对不会再次被读取。
再者,sed采用行号计数器即时计数,每读取一行,计数器就加1。因此sed在读取到最后一行前,不知道后面还有多少行,也不知道什么时候才是最后一行。直到读取到输入流的最后一行,sed为该行打上"$"标记,表示这是最后一行。"$"只是一个标记符号,并非行号,行号只在计数器中记录,因此无法通过"$"来计算出倒数几行,例如"$-1"是错误的写法。这意味着,sed无法直接输出倒数的行。要输出倒数多少行,必须通过窗口来实现。
既然说到了行号,顺便提一提。行号的匹配过程比正则表达式的匹配效率要高的多,因为行号是记录在内存中的,只要比较下表达式中的行号值和计数器记录的值就可以了。而正则表达式匹配的时候要经过编译、匹配等工作,而且sed的正则表达式引擎匹配的效率并不如想象中的那么好,特别是使用了".*"结合了其他表达式的时候。因此,批量处理大量文件,特别是大文件时,能用行号尽量用行号。
回到正题。例如,要输出倒数10行,这个窗口就一直维持在10行的固定大小。当读取到最后一行时,可以通过"$"符号来判断这是否是最后一行,是的话就输出该窗口,否则不输出该窗口的数据。
通常,这样的问题会借助保持空间来临时存储窗口的数据,但此处仅依靠模式空间也能维持一个固定行数的窗口。如下:
#!/usr/bin/sed -nf
# 先读取8行,加上自动读取的一行共9行
N;N;N;N;N;N;N;N
# 判断是否是最后一行,如果不是则读取下一行并踢掉最前面的一行
:1
N
$!s/[^\n]*\n//;t1
# 读取到最后一行后,输出窗口中的内容
p
为了在模式空间中保持固定行数的窗口,只能让所有动作在一个sed循环内完成(因为SCRIPT循环结束时会清空模式空间),因此必须借助标签循环跳转。在上面的示例脚本中,首先读取了8行,加上自动读取的一行,模式空间中共9行,这正是我们需要维护的窗口。随后,使用一个循环判断标签,先读取一行,再判断该行是否是最后一行。如果不是,则剔除掉窗口中的第一行,这样窗口就一直维护在固定的9行大小。直到读取最后一行,这时替换命令失败。最后窗口中的10行内容被输出。
既然通过窗口能输出倒数10行,显然输出倒数第10行也是很简单的,只需将上面的"p"改成大写的"P"即可。
那要是想输出倒数15行、20行甚至是50行,也要这么写吗?先不说要写一大堆的"N"命令,仅仅窗口太大的问题就会导致效率极速下降。假如一个文件有1000行,要输出倒数20行,从第20几行开始每次做"$"匹配的时候都要从模式空间中的20多行搜索,这相当于处理了一个1000*20=20000行的文件。当然,行号匹配直接比较计数器的值,没有这种顾虑,但如果真的是正则表达式匹配,效率必然极速下降。
这时,保持空间就可以派上用场了。但需要注意的是,虽然使用保持空间可以简化处理逻辑,但因为两个buffer空间的数据交换过程都会对性能有一丝丝影响。所以一般来说,用一个buffer空间实现比借助两个buffer空间效率要高那么一点点,特别是大量处理大文件同时还要交换大量数据的时候,性能差距就比较明显。
2.2 借助保持空间暂存窗口
上面的例子的思路是读取一些初始行数填充窗口,在窗口快要达到目标大小时使用标签循环判断功能来维持固定大小的窗口滑动过程。
如果借助保持空间,可以将每次滑动后的窗口数据暂存起来,在读取了下一行时,将其追加回来再处理。
例如上面的例子借助保持空间实现,语句如下:
#!/usr/bin/sed -nf
H
10,${g;s/[^\n]*\n//;h}
$p
由于借助了保持空间,因此整个过程无需在一个sed循环内完成。上面的过程将通过sed循环的自动读取来填充窗口,并将其追加到保持空间。当填充到10行后,将其从保持空间拉回模式空间,并使用"s"命令滑动该窗口,滑动结束后再次将其放回保持空间。直到最后一行滑动结束后,输出最终窗口的内容。
注意,上面的数字是10,而不应该是11,这是"H"命令导致的结果,因为每次H执行时都会在保持空间尾部先追加一个"\n",即使最初保持空间为空时也会追加。这使得从读取第10行并执行了H后,保持空间将有共11行,其中第一行为空。
2.3 将窗口维护命令"s"替换成"D"
考虑"D"命令的特性:删除模式空间的第一行,并进入下一个SCRIPT循环。因此,除非模式空间已经没有内容了,否则"D"命令会一直SCRIPT循环直到模式空间中没有能被D命的地址匹配的内容。
为了方便说明"D",举个简单的例子:压缩连续空行。还有压缩相邻重复行,即去除重复行。
echo -e "1\n2\n\n3\n4\n\n\n5" | sed '$!N;/^\n$/!P;D'
echo -e "1\n2\n3\n3\n4\n4\n4\n4\n4\n5" | sed -r '$!N;/^(.*)\n\1$/!P;D'
这两个命令的思路都是以窗口为模型(我是这么认为的。自从有了窗口的概念,任何涉及"NDP"的命令我都将其认为是窗口,这样容易理解多了)。以"N"命令读入下一行到窗口中,如果窗口中的两行不重复,就输出第一行并执行"D"剔除第一行,于是滑动了窗口,并进入下一个SCRIPT循环。直到窗口中出现重复行,将一直循环滑动这大小为2行的窗口但不输出,直到不重复了才输出前面相邻重复行的最后一行。
由此也可以看出,其实即使是单行或双行的模式空间也都算是一个窗口,只不过这个窗口维护起来比较灵活。
以第二个去除重复行的命令来说,大致流程如下:其中d表示该行未被"P"输出且被"D"删除了,p表示被"P"输出后再被"D"删除。
1p
2p
3d
3p
4d
4d
4d
4d
4p
5p
回到正题。"D"命令其自身实现了一种特殊的条件式SCRIPT循环,而"s"命令要实现这样的循环只能通过标签判断的方式来实现,除非借助保持空间。正因为如此,"D"命令也能剔除窗口中的旧数据实现窗口滑动。
使用"D"很多时候可以简化脚本的复杂性,但其绝对无法替代"s"命令的维护行为。因为D命令的循环范围固定为一整个SCRIPT循环(正如上面压缩重复行的示例,每次都回到SCRIPT的下一个循环从头开始),而"s"命令借助标签跳转可以实现在任意大小的范围内循环。因此,"D"命令实现窗口滑动时,在通用性上不及"s"命令。
仍然以输出倒数10行数据为例。借助"D"实现的语句如下:
#!/usr/bin/sed -nf
1h
2,10H
10g
$p
10,${N;D}
其中前3行只是为了填充一个10行的窗口放在模式空间中(填充窗口的方法实在很多,所以只要知道这3步是干啥的就行),从第11行开始这3行就没有任何作用了。重点在最后一行的10,${N;D},这是"NPD"的绝佳组合之一,通过"N;D"轻松地维持了一个固定大小的窗口:读一行删一行。直到最后一行被"N"读取,才被"$p"输出。之所以"$p"要放在"D"的上一行,是因为"D"总是会回到SCRIPT的顶端,所以它后面的命令是不会执行的。
2.4 真正的大招
呀,原来窗口这么好用?但是不要钻入了sed的牛角而蒙蔽了双眼。说实话,通过sed自身实现很多较为复杂的需求并不那么简单,费神又费力,反而结合其他文本处理工具来实现要简单的多的多。
就以上面的例子来说,输出倒数10行,结合shell变量简单的不得了。
total=`wc -l <filename`
sed -n $((total-9))',$p' filename
这样想输出任意哪些行号的行都可以简单至极。以上只是一个示例,结合其他可用的工具,同样能轻松地实现sed自身比较复杂的需求。因此,这是最终的"大招"。
另外,上面的示例中引号加的位置很奇怪,这是sed结合shell的难题。很多人可能都遇到过这个问题,在网上也没有很好的解释,因为这不是sed的问题,而是shell解析的特性。见sed修炼系列(四):sed中的疑难杂症。
2.5 维持窗口方法论
综合上面几个示例,维持窗口分为两种情况:
- 在模式空间中维持窗口大小。这分为两个过程:
- (1)填充窗口到指定行数;
- (2)滑动窗口。
- 借助保持空间暂存窗口。
- (1).不断填充保持空间的窗口;
- (2).在填充到指定大小后,将窗口拉回模式空间进行滑动;
- (3).滑动后将其覆盖回保持空间暂存下来。
- (4).继续读取并填充保持空间中的窗口,然后拉回模式空间,滑动后再暂存。
看上去,第一种情况比较容易些。确实如此,第一种情况不用多次考虑两个buffer之间的数据交换。并且,第一种情况的效率更高,因为在达到窗口大小之后,再也无需和保持空间交换数据。
3.最佳搭档:"N"、"P"和"D"命令
经过前面窗口滑动的示例,也能发现"N"和"D"是一个绝佳搭档,它俩配合能实现完美的窗口滑动,而且相比于借助保持空间暂存窗口的方法,它俩的逻辑非常清晰。
前面说了"N"和"D"的结合,加上"P"呢?单独的"N"和"P"结合没什么好说的,可能出现的情形太多了。
但"P"和"D"的结合却有一层固定的意义:根据匹配模式判断是否输出多行模式中的第一行,然后踢掉该行,并回到SCRIPT循环顶端。这很可能是在维护一个大小为两行的窗口。格式通常为:
[Address]P;D
再同时结合"N",作用就更明显了,维持一个窗口,并判断是否要输出该窗口的第一行,然后滑动窗口。格式通常为:
[Address1]N;[Address2]P;D
很多时候,Address是省略掉的。P命令前的Address完全是条件判断语句,判断是否要输出。N命令前的Address1如果存在,最大的可能是"$!",这表示当最后一行已被读取过(无论是sed循环自动读取的、n命令读取的还是N命令读取的),直接跳过该命令。如果不加"$!",则没有下一行可供读取时,将直接输出模式空间(除非指定了"-n")并退出sed程序。
是否在N前加"$!",对结果的影响很大。但想判断是否要加,难度还是挺大的,至少要对sed何时输出模式空间内容了如指掌。可以阅读sed修炼系列(一):花拳绣腿之入门篇。
最后,需要说的是"N"和奇偶数行的关系。"N"命令在无法读取下一行时将输出模式空间内容并退出sed,万一读到的最后一行是奇数行,又或是偶数行,会怎样影响结果呢?可能很多人(包括我自己)都琢磨过这个问题,也被这个问题困惑了很久而不得其解,这个问题甚至放进了info sed手册的Bug报告段中进行专门的解释。
其实根本不用考虑最后一行是奇数行还是偶数行,无论最后一行是奇数行还是偶数行,sed根本不管这个逻辑,它只记得最后一行是否被读取过,如果读取过,则在N命令处就退出sed。所以,真正需要考虑的是N命令前是否要加"$!",它决定了sed是在N处退出还是继续执行后面的命令。但有一种情况必须要考虑奇偶性,当"N"结合了其它读取行的操作(命令"n"或sed的自动读取)时,因为其余任意一个读取动作都会改变"N"读取的行的奇偶性。
例如,分别输出输入流的奇数行和偶数行。考虑以窗口模型实现的话,这是很简单的。
seq 1 10 | sed 'N;P;d' # 输出奇数行
seq 1 10 | sed '1!{N;P};d' # 输出偶数行
seq 1 10 | sed -n '1!{N;P;d}' # 输出偶数行,但需要考虑奇偶性
seq 1 10 | sed -n '1!{$!N;P;d}' # 输出偶数行,不需考虑奇偶性
前两个命令都很容易理解,第三个命令却需要考虑奇偶性。因为窗口是从第二行开始填充的,所以窗口数据被"d"删除前,其内第2行总是奇数行,例如"(2,3)"是一个窗口,"{4,5}"是一个窗口。当最后一行是奇数时,其必定是被"N"读取的,这不会影响结果。但如果最后一行是偶数,则此行必定是被sed自动读取的,使得sed在"N"命令处就结束了,其后的"P"就无法执行。这时,可以考虑在"N"前加上"$!",即第四条命令。
当然,更简单的方法如下:
seq 1 10 | sed 'n;d'
seq 1 10 | sed '1!n;d'
再例如,要删除文件的倒数第2行。如果知道窗口的概念,这一切都很容易:维持一个2行的窗口(N和D就够了),当发现最后一行被读取后,不输出其前一行即可。以下是实现语句:
sed 'N;$!P;D' filename
注意这里的"N"在处理最后一行时的作用,它输出了最后一行,且让sed程序结束,但这一行是自动输出的,而非"P"输出的,所以会受"-n"影响。如果改为"$!N",则最后一行被读取后,将直接连续执行两次"D",即同时删除了倒数2行。
sed修炼系列(三):sed高级应用之实现窗口滑动技术的更多相关文章
- sed修炼系列(一):花拳绣腿之入门篇
本文为花拳绣腿招式入门篇,主要目的是入门,为看懂sed修炼系列(二):武功心法做准备.虽然是入门篇,只介绍了基本工作机制以及一些选项和命令,但其中仍然包括了很多sed的工作机制细节.对比网上各sed相 ...
- sed修炼系列(四):sed中的疑难杂症
本文目录:1 sed中使用变量和变量替换的问题2 反向引用失效问题3 "-i"选项的文件保存问题4 贪婪匹配问题5 sed命令"a"和"N" ...
- sed修炼系列(二):sed武功心法(info sed翻译+注解)
sed系列文章: sed修炼系列(一):花拳绣腿之入门篇sed修炼系列(二):武功心法(info sed翻译+注解)sed修炼系列(三):sed高级应用之实现窗口滑动技术sed修炼系列(四):sed中 ...
- sed武功心法(info sed翻译+注解)
本文中的提到GNU扩展时,表示该功能是GNU为sed提供的(即GNU版本的sed才有该功能),一般此时都会说明:如果要写具有可移植性的脚本,应尽量避免在脚本中使用该选项. 本文中的正则表达式几乎和gr ...
- 调用sed命令的三种方式
调用sed命令的三种方式 调用sed有三种方式,一种为Shell命令行方式,另外两种是将sed命令写入脚本文件,然后执行该脚本文件. 三种方式的命令格式归纳如下: 一.在Shell命令行输入命令调用s ...
- Sed&awk笔记之sed篇
http://blog.csdn.net/a81895898/article/details/8482387 Sed是什么 <sed and awk>一书中(1.2 A Stream Ed ...
- Sed&awk笔记之sed篇(转)
Sed是什么 <sed and awk>一书中(1.2 A Stream Editor)是这样解释的: Sed is a "non-interactive" strea ...
- Android高效率编码-第三方SDK详解系列(三)——JPush推送牵扯出来的江湖恩怨,XMPP实现推送,自定义客户端推送
Android高效率编码-第三方SDK详解系列(三)--JPush推送牵扯出来的江湖恩怨,XMPP实现推送,自定义客户端推送 很久没有更新第三方SDK这个系列了,所以更新一下这几天工作中使用到的推送, ...
- linux磁盘管理系列三:LVM的使用
磁盘管理系列 linux磁盘管理系列一:磁盘配额管理 http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_linux_040_quota.html l ...
随机推荐
- 微信小程序框架探究和解析
何为框架 你对微信小程序的技术框架了解多少? 对wepy 框架进行一系列的深入了解 微信小程序框架解析和探究 小程序组件化框架WePY 在性能调优上做出的探究 开发者培训班上海专场PPT分享:小程序框 ...
- 数据结构随笔-php实现栈
栈(Stack)满足后进先出(LIFO)的原则: 下面利用php实现栈的相关操作: 本实例栈的基本操作: 入栈(push):向栈内压入一个元素,栈顶指针指向栈顶元素 出栈(pop): 从栈顶去除元素, ...
- Java的三种代理模式简述
本文着重讲述三种代理模式在java代码中如何写出,为保证文章的针对性,暂且不讨论底层实现原理,具体的原理将在下一篇博文中讲述. 代理模式是什么 代理模式是一种设计模式,简单说即是在不改变源码的情况下, ...
- Given n pairs of parentheses, write a function to generate all combinations of well-formed parentheses. For example, given n = 3, a solution set is: "((()))", "(()())", "(())()", "()(())", "()()()"
思路:采用递归的思想,当左括号数大于右括号数时可以加左或者右括号,否则只能加左括号,当左括号数达到n时,剩下全部.不过,每一个方法的调用都会产生一个栈帧,每执行一个方法就会出现压栈操作,所以采用递归的 ...
- Javascript闭包与作用域this
闭包与this的一般用法 关于js函数与闭包的文章想必大家都是在熟悉不过的了,作为js核心亦即最强大的功能之一,每次回过头翻出来看一看,都会有不一样的收获与理解,经典的含义无非如此而已. 1.闭包 1 ...
- 【head first python】2.共享你的代码 函数模块
#coding:utf-8 #注释代码! #添加两个注释,一个描述模块,一个描述函数 '''这是nester.py模块,提供了一个名为print_lol()的函数, 这个函数的作用是打印列表,其中可能 ...
- Oracle的安装问题
1. 安装时提示:unable to create directory: /u01/oracle/oradata 这个是由于以oracle用户进行安装时,之前没有创建/u01/这个目录,要知道orac ...
- 两点补充——CSS3新属性以及弹性布局
CSS3 新属性 一.[ CSS3新增属性前缀 ] 1.-webkit-:chrome/safari 2.-moz-:火狐 3.-mo-:IE 4.-o-: Opera 欧朋 二 .[CSS 长度单位 ...
- “selection does not contain a main type”解决方法
在运行java程序时,出现了错误“selection does not contain a main type”. 是因为.java文件不在项目的src路径内,也就是说源代码未被eclipse编译,字 ...
- 运维之Linux基础(二)
运维之Linux基础(二) 1. file 命令基期用法 2. 文件系统 Linux的文件系统结构是树状结构,所有的文件都在/root跟目录下 /boot:系统启动相关的文件, 如:内核.initrd ...