机器学习公开课笔记(4):神经网络(Neural Network)——表示
动机(Motivation)
对于非线性分类问题,如果用多元线性回归进行分类,需要构造许多高次项,导致特征特多学习参数过多,从而复杂度太高。
神经网络(Neural Network)
一个简单的神经网络如下图所示,每一个圆圈表示一个神经元,每个神经元接收上一层神经元的输出作为其输入,同时其输出信号到下一层,其中每一层的第一个神经元称为bias unit,它是额外加入的其值为1,通常用+1表示,下图用虚线画出。
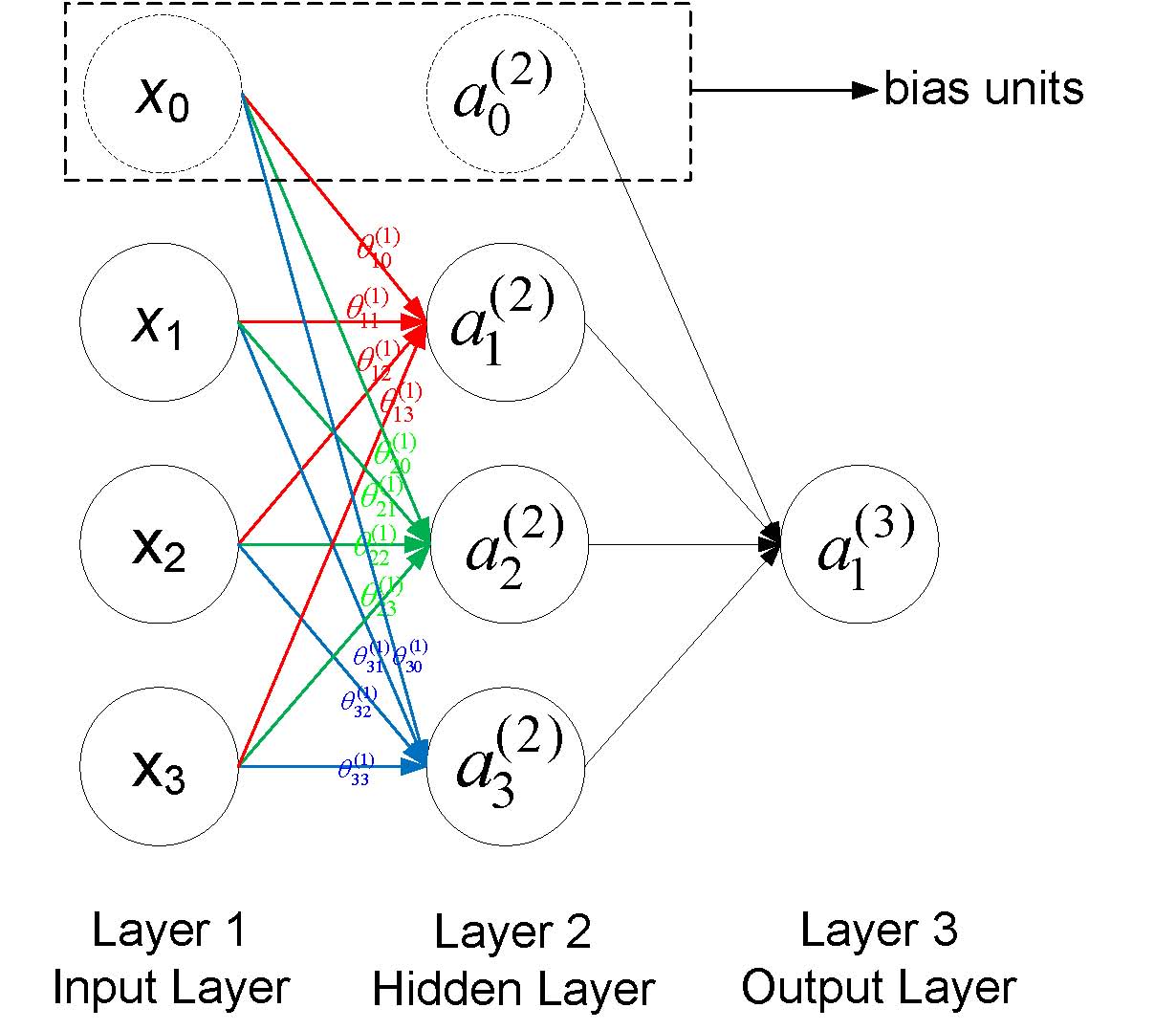
符号说明:
- $a_i^{(j)}$表示第j层网络的第i个神经元,例如下图$a_1^{(2)}$就表示第二层的第一个神经元
- $\theta^{(j)}$表示从第$j$层到第$j+1$层的权重矩阵,例如下图所有的$\theta^{(1)}$表示从第一层到第二层的权重矩阵
- $\theta^{(j)}_{uv}$表示从第j层的第v个神经元到第j+1层的第u个神经的权重,例如下图中$\theta^{(1)}_{23}$表示从第一层的第3个神经元到第二层的第2个神经元的权重,需要注意到的是下标uv是指v->u的权重而不是u->v,下图也给出了第一层到第二层的所有权重标注
- 一般地,如果第j层有$s_j$个神经元(不包括bias神经元),第j+1层有$s_{j+1}$个神经元(也不包括bias神经元),那么权重矩阵$\theta^{j}$的维度是$(s_{j+1}\times s_j+1)$
前向传播(Forward Propagration, FP)
后一层的神经元的值根据前一层神经元的值的改变而改变,以上图为例,第二层的神经元的更新方式为
$$a_1^{(2)} = g(\theta_{10}^{(1)}x_0 + \theta_{11}^{(1)}x_1 + \theta_{12}^{(1)}x_2 + \theta_{13}^{(1)}x_3)$$
$$a_2^{(2)} = g(\theta_{20}^{(1)}x_0 + \theta_{21}^{(1)}x_1 + \theta_{22}^{(1)}x_2 + \theta_{23}^{(1)}x_3)$$
$$a_3^{(2)} = g(\theta_{30}^{(1)}x_0 + \theta_{31}^{(1)}x_1 + \theta_{32}^{(1)}x_2 + \theta_{33}^{(1)}x_3)$$
$$a_4^{(2)} = g(\theta_{40}^{(1)}x_0 + \theta_{41}^{(1)}x_1 + \theta_{42}^{(1)}x_2 + \theta_{43}^{(1)}x_3)$$
其中g(z)为sigmoid函数,即$g(z)=\frac{1}{1+e^{-z}}$
1. 向量化实现(Vectorized Implementation)
如果我们以向量角度来看待上述的更新公式,定义
$a^{(1)}=x=\left[ \begin{matrix}x_0\\ x_1 \\ x_2 \\ x_3 \end{matrix} \right]$ $z^{(2)}=\left[ \begin{matrix}z_1^{(2)}\\ z_1^{(2)} \\ z_1^{(2)}\end{matrix} \right]$ $\theta^{(1)}=\left[\begin{matrix}\theta^{(1)}_{10}& \theta^{(1)}_{11}& \theta^{(1)}_{12}& \theta^{(1)}_{13}\\ \theta^{(1)}_{20}& \theta^{(1)}_{21}& \theta^{(1)}_{22}& \theta^{(1)}_{23}\\ \theta^{(1)}_{30}& \theta^{(1)}_{31}& \theta^{(1)}_{32} & \theta^{(1)}_{33}\end{matrix}\right]$
则更新公式可以简化为
$$z^{(2)}=\theta^{(1)}a^{(1)}$$
$$a^{(2)}=g(z^{(2)})$$
$$z^{(3)}=\theta^{(2)}a^{(2)}$$
$$a^{(3)}=g(z^{(3)})=h_\theta(x)$$
可以看到,我们由第一层的值,计算第二层的值;由第二层的值,计算第三层的值,得到预测的输出,计算的方式一层一层往前走的,这也是前向传播的名称由来。
2. 与Logistic回归的联系
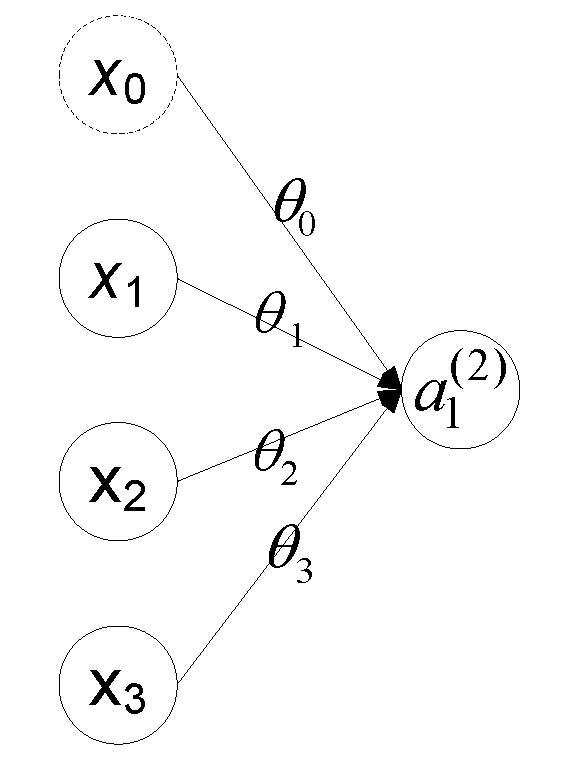
考虑上图没有隐藏层的神经网络,其中$x=\left[ \begin{matrix}x_0\\ x_1 \\ x_2 \\ x_3 \end{matrix} \right]$,$\theta=\left[ \begin{matrix}\theta_0& \theta_1& \theta_2 & \theta_3 \end{matrix} \right]$,则我们有$h_\theta(x)=a_1^{(2)}=g(z^{(1)})=g(\theta x)=g(x_0\theta_0+x_1\theta_1+x_2\theta_2+x_3\theta_3)$,可以看到这正是Logistic回归的假设函数!!!这种关系表明Logistic是回归是不含隐藏层的特殊神经网络,神经网络从某种程度上来说是对logistic回归的推广。
神经网络示例
对于如下图所示的线性不可分的分类问题,(0,0)(1,1)为一类(0,1)(1,0)为另一类,神经网络可以解决(见5)。首先需要一些简单的神经网络(1-4),其中图和真值表结合可以清楚的看出其功能,不再赘述。

1. 实现AND操作
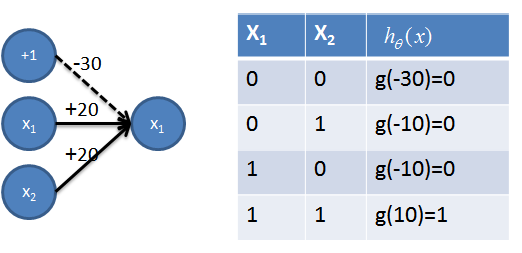
2. 实现OR操作

3. 实现非操作
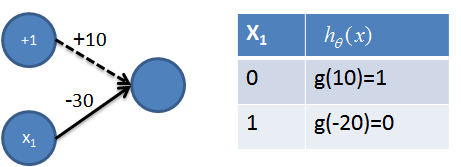
4. 实现NAND=((not x1) and (not x2))操作
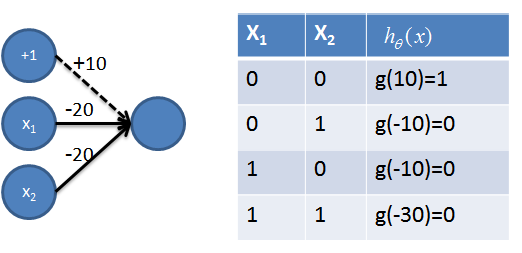
5. 组合实现NXOR=NOT(x1 XOR x2) 操作
该神经网络用到了之前的AND操作(用红色表示)、NAND操作(用青色表示)和OR操作(用橙色表示),从真值表可以看出,该神经网络成功地将(0, 0)(1,1)分为一类,(1,0)(0,1)分为一类,很好解决了线性不可分的问题。

神经网络的代价函数(含正则项)
$$J(\Theta) = -\frac{1}{m}\left[\sum\limits_{i=1}^{m}\sum\limits_{k=1}^{K}y^{(i)}_{k}log(h_\theta(x^{(i)}))_k + (1-y^{(i)}_k)log(1-(h_\theta(x^{(i)}))_k)\right] + \frac{\lambda}{2m}\sum_{l=1}^{L-1}\sum\limits_{i=1}^{s_l}\sum\limits_{j=1}^{s_{l+1}}(\Theta_{ji}^{(l)})^2$$
符号说明:
- $m$ — 训练example的数量
- $K$ — 最后一层(输出层)的神经元的个数,也等于分类数(分$K$类,$K\geq 3$)
- $y_k^{(i)}$ — 第$i$个训练exmaple的输出(长度为$K$个向量)的第$k$个分量值
- $(h_\theta(x^{(i)}))_k$ — 对第$i$个example用神经网络预测的输出(长度为$K$的向量)的第$k$个分量值
- $L$ — 神经网络总共的层数(包括输入层和输出层)
- $\Theta^{(l)}$ — 第$l$层到第$l+1$层的权重矩阵
- $s_l$ — 第$l$层神经元的个数, 注意$i$从1开始计数,bias神经元的权重不算在正则项内
- $s_{l+1}$ — 第$l+1$ 层神经元的个数
参考文献
[1] Andrew Ng Coursera 公开课第四周
[2] Neural Networks. https://www.doc.ic.ac.uk/~nd/surprise_96/journal/vol4/cs11/report.html
[3] The nature of code. http://natureofcode.com/book/chapter-10-neural-networks/
[4] A Basic Introduction To Neural Networks. http://pages.cs.wisc.edu/~bolo/shipyard/neural/local.html
机器学习公开课笔记(4):神经网络(Neural Network)——表示的更多相关文章
- 机器学习公开课笔记(5):神经网络(Neural Network)——学习
这一章可能是Andrew Ng讲得最不清楚的一章,为什么这么说呢?这一章主要讲后向传播(Backpropagration, BP)算法,Ng花了一大半的时间在讲如何计算误差项$\delta$,如何计算 ...
- Andrew Ng机器学习公开课笔记 -- 支持向量机
网易公开课,第6,7,8课 notes,http://cs229.stanford.edu/notes/cs229-notes3.pdf SVM-支持向量机算法概述, 这篇讲的挺好,可以参考 先继 ...
- Andrew Ng机器学习公开课笔记 -- 学习理论
网易公开课,第9,10课 notes,http://cs229.stanford.edu/notes/cs229-notes4.pdf 这章要讨论的问题是,如何去评价和选择学习算法 Bias/va ...
- 机器学习公开课笔记(8):k-means聚类和PCA降维
K-Means算法 非监督式学习对一组无标签的数据试图发现其内在的结构,主要用途包括: 市场划分(Market Segmentation) 社交网络分析(Social Network Analysis ...
- Andrew Ng机器学习公开课笔记–Principal Components Analysis (PCA)
网易公开课,第14, 15课 notes,10 之前谈到的factor analysis,用EM算法找到潜在的因子变量,以达到降维的目的 这里介绍的是另外一种降维的方法,Principal Compo ...
- Andrew Ng机器学习公开课笔记 – Factor Analysis
网易公开课,第13,14课 notes,9 本质上因子分析是一种降维算法 参考,http://www.douban.com/note/225942377/,浅谈主成分分析和因子分析 把大量的原始变量, ...
- Andrew Ng机器学习公开课笔记 -- Regularization and Model Selection
网易公开课,第10,11课 notes,http://cs229.stanford.edu/notes/cs229-notes5.pdf Model Selection 首先需要解决的问题是,模型 ...
- 机器学习公开课笔记(3):Logistic回归
Logistic 回归 通常是二元分类器(也可以用于多元分类),例如以下的分类问题 Email: spam / not spam Tumor: Malignant / benign 假设 (Hypot ...
- Andrew Ng机器学习公开课笔记–Reinforcement Learning and Control
网易公开课,第16课 notes,12 前面的supervised learning,对于一个指定的x可以明确告诉你,正确的y是什么 但某些sequential decision making问题,比 ...
随机推荐
- 小白学习mysql之函数
## 导语 曾经我以为,学会了select.update.insert和delete之后,我就学会了数据库~,要不是到公司看到SQL里充满了密密麻麻的的各种函数,我差点就信了~,当初的自己是多么的天真 ...
- Linux 常用工具贴
1. nmon for Linux 用于监控Linux CPU.IO.网络等,可以生产excel格式的报表 http://nmon.sourceforge.net/pmwiki.php?n=Sit ...
- 约瑟夫环的java解决
总共3中解决方法,1.数学推导,2.使用ArrayList递归解决,3.使用首位相连的LinkedList解决 import java.util.ArrayList; /** * 约瑟夫环问题 * 需 ...
- ThinkPHP之验证码的使用
ThinkPHP中已经提供了验证码的生成以及验证的功能.下面介绍如何使用验证码.编程的时候还是采用MVC的方式 View层 <!DOCTYPE html> <html> < ...
- 第二十四课:jQuery.event.remove,dispatch的源码解读
本课还是来讲解一下jQuery是如何实现它的事件系统的.这一课我们先来讲一下jQuery.event.remove的源码解读. remove方法的目的是,根据用户传参,找到事件队列,从里面把匹配的ha ...
- 每天一个linux命令(21):tar命令
通过SSH访问服务器,难免会要用到压缩,解压缩,打包,解包等,这时候tar命令就是是必不可少的一个功能强大的工具.linux中最流行的tar是麻雀虽小,五脏俱全,功能强大. tar 命令可以为linu ...
- chromiun 学习《一》
众所周知,Chrome是建立在开源的Chromium项目上的. 而且不得不说,学习并分析开源项目的代码对一个程序员的提高确实蛮大的.这篇博文我会记录一下学习过程中我遇到的一些问题,并分享学习中我所参考 ...
- Python 之我见
读音 Python(KK 英语发音:/ˈpaɪθən/) 序言 其实早前就已经接触了python这个功能强大的脚本语言,但是那时只是基于兴趣而学习,目的性并不是很强,所以学习的并不是很深入.最近由于闲 ...
- springMVC实现防止重复提交
参考文档:http://my.oschina.net/mushui/blog/143397
- POJ 3273 Monthly Expense
传送门 Time Limit: 2000MS Memory Limit: 65536K Description Farmer John is an astounding accounting wiza ...