深入剖析SolrCloud(一)
作者:洞庭散人
出处:http://phinecos.cnblogs.com/
本博客遵从Creative Commons Attribution 3.0 License,若用于非商业目的,您可以自由转载,但请保留原作者信息和文章链接URL。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,是正在开发中的Solr4.0的核心组件之一,它的主要思想是使用Zookeeper作为集群的配置信息中心。它有几个特色功能:1)集中式的配置信息 2)自动容错 3)近实时搜索 4)查询时自动负载均衡

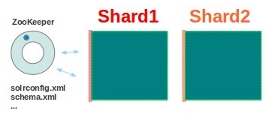
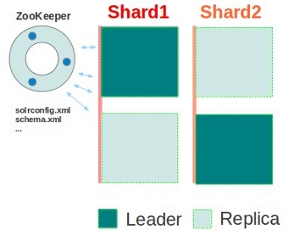
基本可以用上面这幅图来概述,这是一个拥有4个Solr节点的集群,索引分布在两个Shard里面,每个Shard包含两个Solr节点,一个是Leader节点,一个是Replica节点,此外集群中有一个负责维护集群状态信息的Overseer节点,它是一个总控制器。集群的所有状态信息都放在Zookeeper集群中统一维护。从图中还可以看到,任何一个节点都可以接收索引更新的请求,然后再将这个请求转发到文档所应该属于的那个Shard的Leader节点,Leader节点更新结束完成,最后将版本号和文档转发给同属于一个Shard的replicas节点。
下面我们来看一个简单的SolrCloud集群的配置过程。
首先去https://builds.apache.org/job/Solr-trunk/lastSuccessfulBuild/artifact/artifacts/下载Solr4.0的源码和二进制包,注意Solr4.0现在还在开发中,因此这里是Nightly
Build版本。
示例1,简单的包含2个Shard的集群
这个示例中,我们把一个collection的索引数据分布到两个shard上去,步骤如下:
为了弄2个solr服务器,我们拷贝一份example目录
然后启动第一个solr服务器,并初始化一个新的solr集群,
java -Dbootstrap_confdir=./solr/conf -Dcollection.configName=myconf -DzkRun -DnumShards=2 -jar start.jar
-DzkRun参数是启动一个嵌入式的Zookeeper服务器,它会作为solr服务器的一部分,-Dbootstrap_confdir参数是上传本地的配置文件上传到zookeeper中去,作为整个集群共用的配置文件,-DnumShards指定了集群的逻辑分组数目。
然后启动第二个solr服务器,并将其引向集群所在位置
java -Djetty.port=7574 -DzkHost=localhost:9983 -jar start.jar
-DzkHost=localhost:9983就是指明了Zookeeper集群所在位置
我们可以打开http://localhost:8983/solr/collection1/admin/zookeeper.jsp 或者http://localhost:8983/solr/#/cloud看看目前集群的状态,
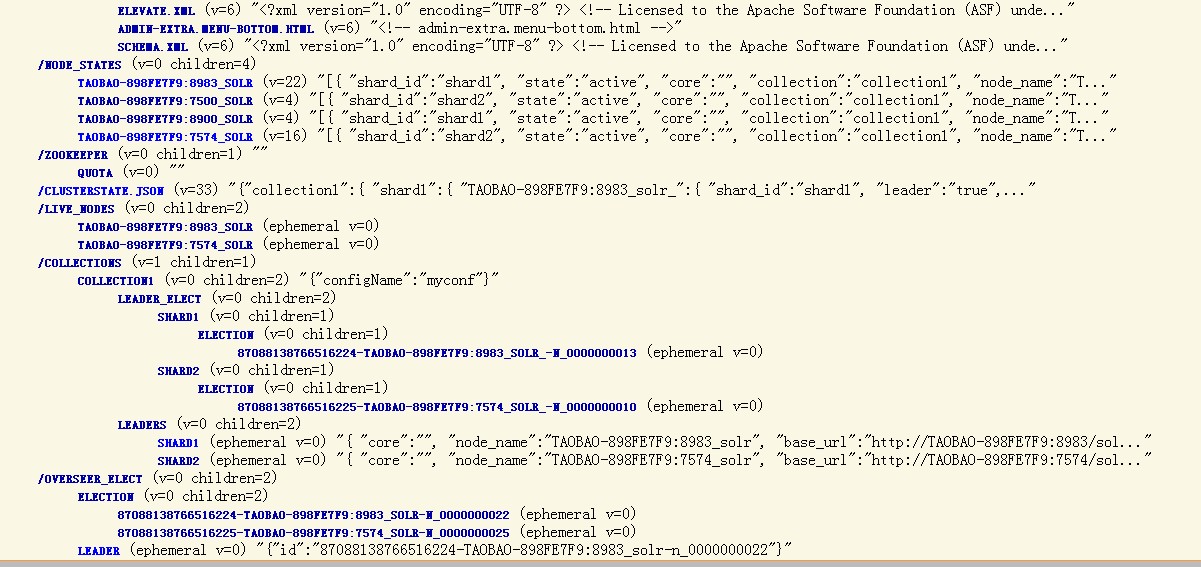
现在,我们可以试试索引一些文档,
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar ipod_video.xml
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar monitor.xml
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar mem.xml
最后,来试试分布式搜索吧:
http://localhost:8983/solr/collection1/select?q
Zookeeper维护的集群状态数据是存放在solr/zoo_data目录下的。
现在我们来剖析下这样一个简单的集群构建的基本流程:
先从第一台solr服务器说起:
1) 它首先启动一个嵌入式的Zookeeper服务器,作为集群状态信息的管理者,
2) 将自己这个节点注册到/node_states/目录下
3) 同时将自己注册到/live_nodes/目录下
4)创建/overseer_elect/leader,为后续Overseer节点的选举做准备,新建一个Overseer,
5) 更新/clusterstate.json目录下json格式的集群状态信息
6) 本机从Zookeeper中更新集群状态信息,维持与Zookeeper上的集群信息一致
7)上传本地配置文件到Zookeeper中,供集群中其他solr节点使用
8) 启动本地的Solr服务器,
9) Solr启动完成后,Overseer会得知shard中有第一个节点进来,更新shard状态信息,并将本机所在节点设置为shard1的leader节点,并向整个集群发布最新的集群状态信息。
10)本机从Zookeeper中再次更新集群状态信息,第一台solr服务器启动完毕。
然后来看第二台solr服务器的启动过程:
1) 本机连接到集群所在的Zookeeper,
2) 将自己这个节点注册到/node_states/目录下
3) 同时将自己注册到/live_nodes/目录下
4) 本机从Zookeeper中更新集群状态信息,维持与Zookeeper上的集群信息一致
5) 从集群中保存的配置文件加载Solr所需要的配置信息
6) 启动本地solr服务器,
7) solr启动完成后,将本节点注册为集群中的shard,并将本机设置为shard2的Leader节点,
8) 本机从Zookeeper中再次更新集群状态信息,第二台solr服务器启动完毕。
示例2,包含2个shard的集群,每个shard中有replica节点
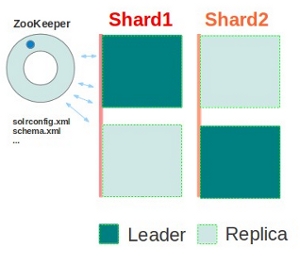
如图所示,集群包含2个shard,每个shard中有两个solr节点,一个是leader,一个是replica节点,
cp -r example2 example2B
cd exampleB
java -Djetty.port=8900 -DzkHost=localhost:9983 -jar start.jar
cd example2B
java -Djetty.port=7500 -DzkHost=localhost:9983 -jar start.jar
我们可以打开http://localhost:8983/solr/collection1/admin/zookeeper.jsp 看看包含4个节点的集群的状态,
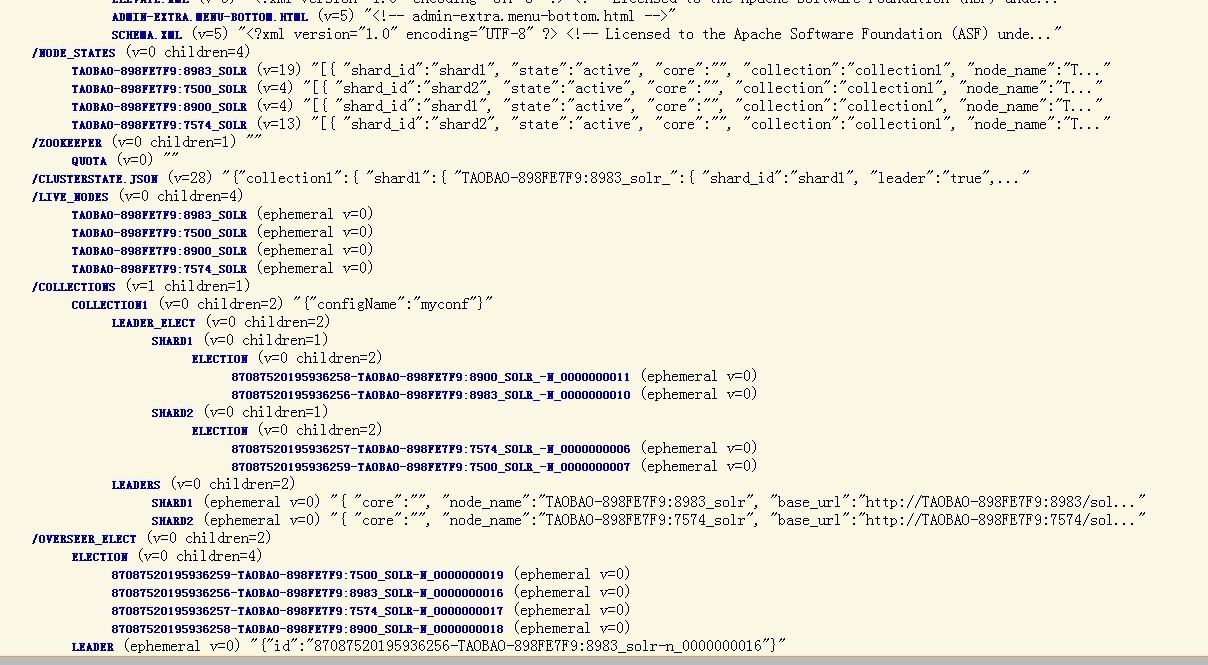
这个集群现在就具备容错性了,你可以试着干掉一个Solr服务器,然后再发送查询请求。背后的实质是集群的ov erseer会监测各个shard的leader节点,如果leader节点挂了,则会启动自动的容错机制,会从同一个shard中的其他replica节点集中重新选举出一个leader节点,甚至如果overseer节点自己也挂了,同样会自动在其他节点上启用新的overseer节点,这样就确保了集群的高可用性。
示例3 包含2个shard的集群,带shard备份和zookeeper集群机制
上一个示例中存在的问题是:尽管solr服务器可以容忍挂掉,但集群中只有一个zookeeper服务器来维护集群的状态信息,单点的存在即是不稳定的根源。如果这个zookeeper服务器挂了,那么分布式查询还是可以工作的,因为每个solr服务器都会在内存中维护最近一次由zookeeper维护的集群状态信息,但新的节点无法加入集群,集群的状态变化也不可知了。因此,为了解决这个问题,需要对Zookeeper服务器也设置一个集群,让其也具备高可用性和容错性。
有两种方式可选,一种是提供一个外部独立的Zookeeper集群,另一种是每个solr服务器都启动一个内嵌的Zookeeper服务器,再将这些Zookeeper服务器组成一个集群。 我们这里用后一种做示例:

java -Dbootstrap_confdir=./solr/conf -Dcollection.configName=myconf -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -DnumShards=2 -jar start.jar
cd example2
java -Djetty.port=7574 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
cd exampleB
java -Djetty.port=8900 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
cd example2B
java -Djetty.port=7500 -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
我们可以打开http://localhost:8983/solr/collection1/admin/zookeeper.jsp 看看包含4个节点的集群的状态,可以发现其实和上一个没有任何区别。
后续的文章将从实现层面对SolrCloud这个分布式搜索解决方案进行进一步的深入剖析。
深入剖析SolrCloud(一)的更多相关文章
- 深入剖析SolrCloud(二)
作者:洞庭散人 出处:http://phinecos.cnblogs.com/ 本博客遵从Creative Commons Attribution 3.0 License,若用于非商业目的,您可以自由 ...
- 深入剖析SolrCloud(三)
作者:洞庭散人 出处:http://phinecos.cnblogs.com/ 本博客遵从Creative Commons Attribution 3.0 License,若用于非商业目的,您可以自由 ...
- 深入剖析SolrCloud(四)
作者:洞庭散人 出处:http://phinecos.cnblogs.com/ 本博客遵从Creative Commons Attribution 3.0 License,若用于非商业目的,您可以自由 ...
- 探索C#之6.0语法糖剖析
阅读目录: 自动属性默认初始化 自动只读属性默认初始化 表达式为主体的函数 表达式为主体的属性(赋值) 静态类导入 Null条件运算符 字符串格式化 索引初始化 异常过滤器when catch和fin ...
- jQuery之Deferred源码剖析
一.前言 大约在夏季,我们谈过ES6的Promise(详见here),其实在ES6前jQuery早就有了Promise,也就是我们所知道的Deferred对象,宗旨当然也和ES6的Promise一样, ...
- [C#] 剖析 AssemblyInfo.cs - 了解常用的特性 Attribute
剖析 AssemblyInfo.cs - 了解常用的特性 Attribute [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5944391.html 序 ...
- Membership三步曲之进阶篇 - 深入剖析Provider Model
Membership 三步曲之进阶篇 - 深入剖析Provider Model 本文的目标是让每一个人都知道Provider Model 是什么,并且能灵活的在自己的项目中使用它. Membershi ...
- 《AngularJS深度剖析与最佳实践》简介
由于年末将至,前阵子一直忙于工作的事务,不得已暂停了微信订阅号的更新,我将会在后续的时间里尽快的继续为大家推送更多的博文.毕竟一个人的力量微薄,精力有限,希望大家能理解,仍然能一如既往的关注和支持sh ...
- 探索c#之Async、Await剖析
阅读目录: 基本介绍 基本原理剖析 内部实现剖析 重点注意的地方 总结 基本介绍 Async.Await是net4.x新增的异步编程方式,其目的是为了简化异步程序编写,和之前APM方式简单对比如下. ...
随机推荐
- 使用sessionStorage实现页面间传值与传对象
问题描述:业务从A页面跳转到B页面,需要由A页面向B页面传入一个对象.B页面解析对象中的值,然后根据这些值做具体的业务逻辑. 一般的传值方法如下: A页面跳转到B页面时: b.html?xxx=xxx ...
- Android OpenCSV
OpenCSV https://sourceforge.net/projects/opencsv/ 使用参考 http://stackoverflow.com/questions/16672074/i ...
- Mongodb 的劣势
MongoDB中的数据存放具有相当的随意性,不具有MySQL在开始就定义好了.对运维人员来说,他们可能不清楚数据库内部数据的数据格式,这也会数据库的运维带来了麻烦. 1. 事务关系支持薄弱.这也是所有 ...
- js mouseover/out 要用mouseenter/leave 代替
js中 onmouseover/out 在进入离开绑定事件的子元素时,都会触发一次,因此项目中药尽量少用 可以使用onmouseenter/leave代替,它们在绑定事件上只会触发一次,不会重复触发
- 【django】Bootstrap 安装和使用
官网 下载:推荐下载源码包 安装Bower:使用Bower安装并管理 Bootstrap 的Less.CSS.JavaScript和字体文件(通过npm安装bower) npm install -g ...
- HDU - 6395:Sequence (分块+矩阵)
题面太丑了,就不复制了. 题意:F1=A: F2=B: Fn=D*Fn-1+C*Fn-2+P/i:求Fn. 思路:根据P/i的值划分区间,每个区间矩阵求. 带常数的矩阵: #include<bi ...
- CENTOS7配置静态IP后无法ping通外部网络的问题
我今天想谈论的并不是如何配置静态IP,这样的话题已经有好多高手再谈. 我想谈的是为什么,我按照他们的教程无论如何也要发生各种问题,没办法连接外网的问题. 先给大家看我的最终版配置方案:我只修改了一个文 ...
- python3之scrapy安装使用
需要安装的包 pip install scrapy selenium 可能需要卸载重装的模块 lxml cryptography cffi pypiwin32 pip uninstall xx ...
- Spring 循环依赖
循环依赖就是循环引用,就是两个或多个Bean相互之间的持有对方,比如CircleA引用CircleB,CircleB引用CircleC,CircleC引用CircleA,则它们最终反映为一个环.此处不 ...
- 四、 kafka consumer 配置
consumer配置 #指明当前消费进程所属的消费组,一个partition只能被同一个消费组的一个消费者消费(同一个组的consumer不会重复消费同一个消息) group.id #针对一个part ...