MapReduce初学习
Mapreduce概述:
MapReduce是一种分布式计算模型,主要用于搜索领域,解决海量数据的计算问题。MR是由两个阶段组成,Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,这两个函数的形参是key,value对,表示函数的输入信息。


举例:

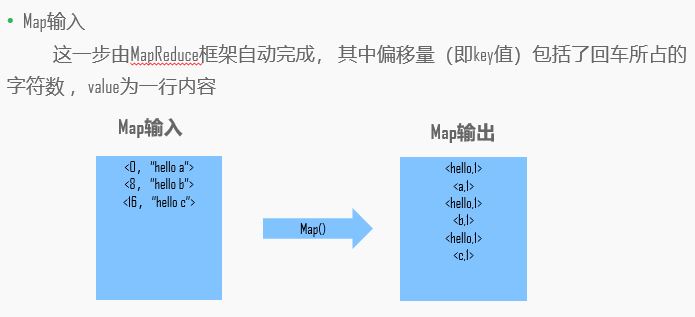
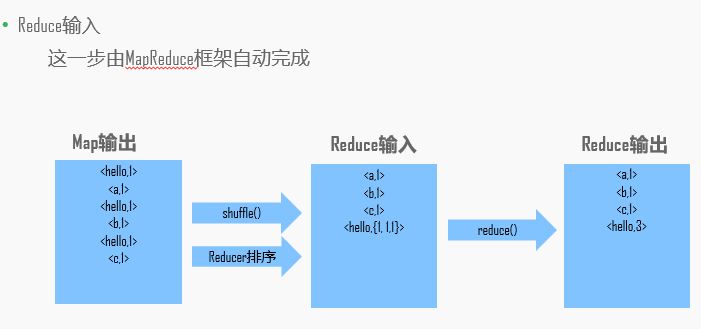
实战:
Linux下的data文件夹创建一个文本:
cd /home/data
touch words //创建文本words
gedit words //编辑words
words文本内容:
hello a
hello b
hello c
进行操作:
bin/hadoop fs -mkdir /words //创建words文件夹
bin/hdfs dfs -put /home/data/words /words //words文件上传到hdfs的words路径下
//如果hdfs路径内已经有words路径了,删除
bin/hdfs dfs -rm -r /words
接下来,我们来在Windows下的eclipse里编写mapreduce代码:
首先安装打开eclipse,创建一个maven项目:
pom.xml:添加依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.7.1</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
右键项目名,Build Path —— Configure Build Path,修改jdk版本
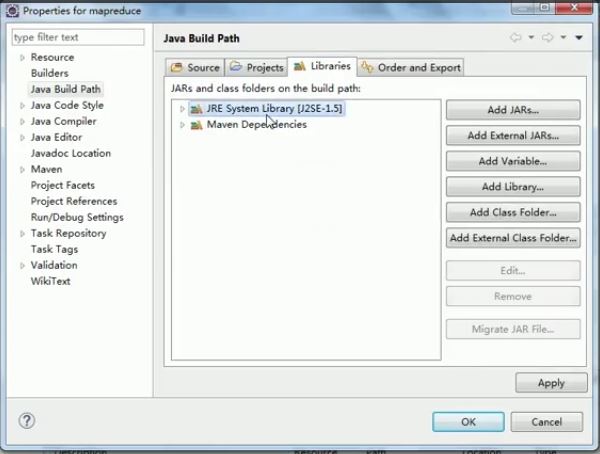
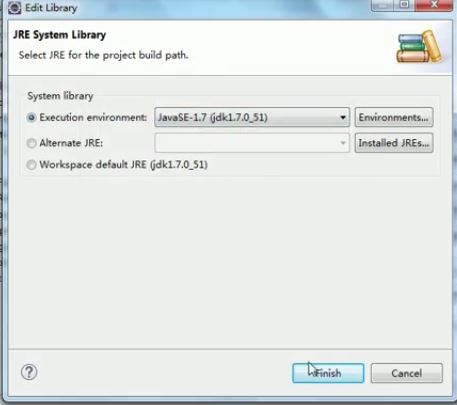
创建java 文件,开始编写mapper:
import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {//LongWritable相当于long,Text相当于String,IntWritable相当于int
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// 得到输入的每一行数据 hello a
String line = value.toString(); // 分割数据,通过空格来分割 hello,a
String[] words = line.split(" "); // 循环遍历并输出
// hello,1
// a,1
for (String word : words) {
context.write(new Text(word), new IntWritable(1));//每个值输出一次
} }
}
编写Reducer:
import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context content) throws IOException, InterruptedException {
Integer count = 0;
for (IntWritable value : values) {//迭代遍历
count += value.get();
}
content.write(key, new IntWritable(count));
}
}
编写Mapreduce:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountMapReduce {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration(); // 创建job对象
Job job = Job.getInstance(conf, "wordcount"); // 设置运行job的主类
job.setJarByClass(WordCountMapReduce.class); // 设置mapper类
job.setMapperClass(WordCountMapper.class);
// 设置reducer类
job.setReducerClass(WordCountReducer.class); // 设置map输出的key value
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); // 设置reducer输出的key value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); // 设置输入输入的路径
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop:9000/words"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop:9000/out")); // 提交job
boolean b = job.waitForCompletion(true); if(!b) {
System.err.println("This task has failed!!!");
} }
}
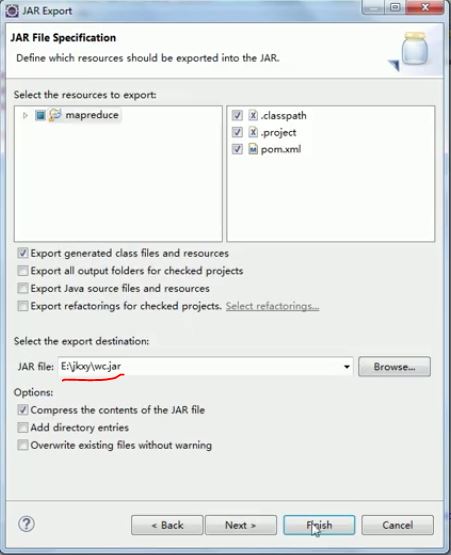
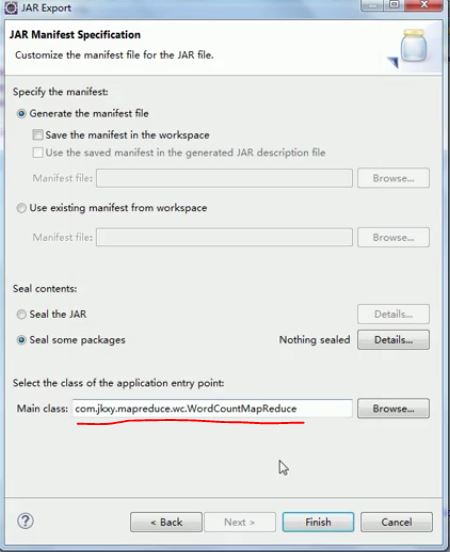
导出jar包:
第一种方式:
项目右键——Export

第二种方式:(把所有jar包都导入进去,包括依赖的jar包)先运行(报错不用管)


打开虚拟机,终端启动hadoop(hadoop目录下sbin/start-all.sh)
把刚刚导出的jar包放入/home/jars中,
//运行jar包
bin/yarn jar /home/jars/wc.jar
运行进程可以打开hadoop:8088查看
运行完成后打开hadoop:50070,上方Utilities——第一个,查看hdfs中目录是否有out
//查看out中数据
bin/hdfs dfs -ls /out
bin/hdfs dfs -cat /out/part-r-
可以看到结果
a
b
c
hello
在Windows下连接hadoop:
在第一个链接里面有个源码的文件包,里面有两个工具,hadoopbin包和hadoop-eclipse-plugin-2.7.0.jar。
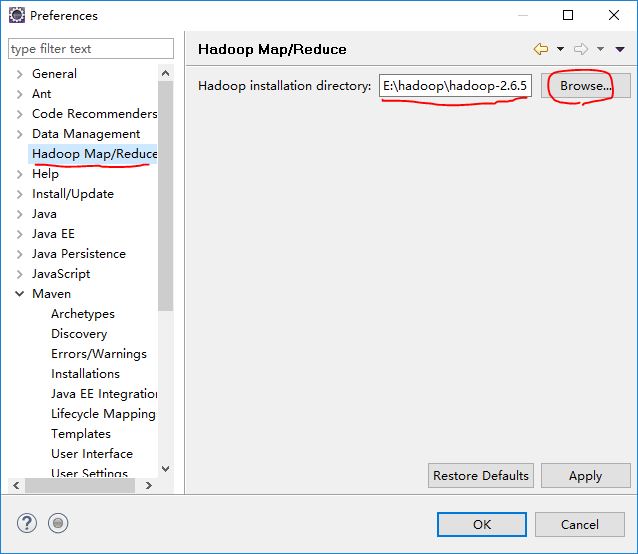
先将hadoop包打开,放在一个目录下,然后进行环境配置:

path里添加:

将hadoop-eclipse-plugin-2.7.0.jar放入eclipse安装目录下的plugins目录下,将hadoopbin包中的文件放在hadoop安装目录的bin目录下,全部替换。
把hadoopbin包中的hadoop.dll文件放在 C:\Windows\System32 中
打开eclipse(如果此时eclipse是打开状态,请重启):如果此时左侧的DFS Locations没有出现,说明插件有问题,请换一个插件
确定
上方Window -> Show View -> Other -> Map/Reduce Tools :

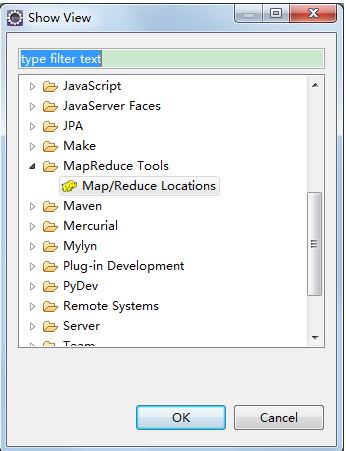
下方会出现:点击右方小象:

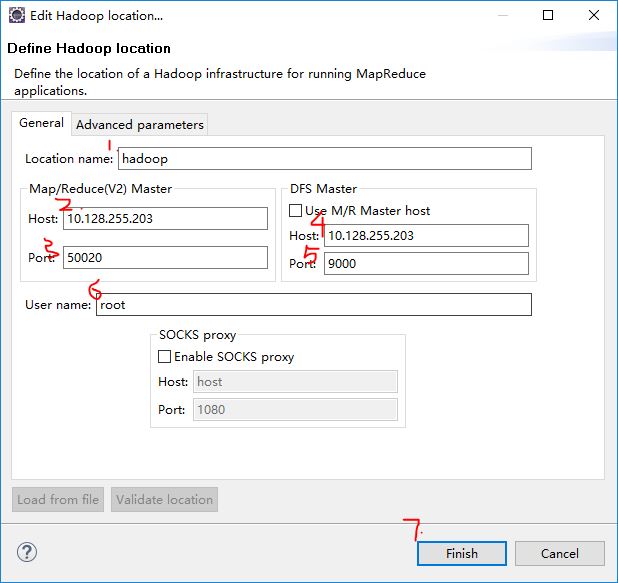
(1)添加你想起的location名字,我这里起名hadoop
(2)(3)应该和mapred-site.xml里的一致,如果没有,默认IP地址,port为50020;
(4)(5)和core-site.xml一致
(6)Linux下使用的用户名
如果出现:说明成功了
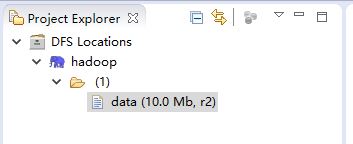
如果没成功,可能是插件版本或者插件本身问题(我被这个插件折腾了几个星期),试着换插件。
PS1.输入输出中的hadoop对应的IP地址,如果不直接写IP地址的话,可以在Windows下添加映射:
打开C:\Windows\System32\drivers\etc 下的hosts文件,末尾添加:
hadoop 10.128.255.203
注意一下,如果虚拟机的ip地址换了的话,不要忘记更换此处的映射;如果虚拟机的hosts文件也添加了映射,也不要忘记更换。
PS2.如果怀疑是端口连不上,可以使用telnet:
打开控制面板:

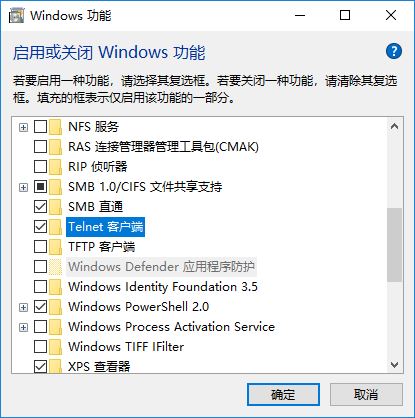
安装完成后打开命令行:

出现

说明端口连接成功。
MapReduce初学习的更多相关文章
- clisp, scheme 和 clojure 初学习
clisp, scheme和clojure 初学习 1 clojure "clojure绝对会成为你的编程工具箱里的终极武器" "其他语言可能只是工具,但 Clojure ...
- 第2节 mapreduce深入学习:14、mapreduce数据压缩-使用snappy进行压缩
第2节 mapreduce深入学习:14.mapreduce数据压缩-使用snappy进行压缩 文件压缩有两大好处,节约磁盘空间,加速数据在网络和磁盘上的传输. 方式一:在代码中进行设置压缩 代码: ...
- 第2节 mapreduce深入学习:8、手机流量汇总求和
第2节 mapreduce深入学习:8.手机流量汇总求和 例子:MapReduce综合练习之上网流量统计. 数据格式参见资料夹 需求一:统计求和 统计每个手机号的上行流量总和,下行流量总和,上行总流量 ...
- 第2节 mapreduce深入学习:7、MapReduce的规约过程combiner
第2节 mapreduce深入学习:7.MapReduce的规约过程combiner 每一个 map 都可能会产生大量的本地输出,Combiner 的作用就是对 map 端的输出先做一次合并,以减少在 ...
- 第2节 mapreduce深入学习:6、MapReduce当中的计数器
第2节 mapreduce深入学习:6. MapReduce当中的计数器 计数器是收集作业统计信息的有效手段之一,用于质量控制或应用级统计.计数器还可辅助诊断系统故障.如果需要将日志信息传输到map ...
- 第2节 mapreduce深入学习:4, 5
第2节 mapreduce深入学习:4.mapreduce的序列化以及自定义排序 序列化(Serialization)是指把结构化对象转化为字节流. 反序列化(Deserialization)是序列化 ...
- 第2节 mapreduce深入学习:2、3
第2节 mapreduce深入学习:2.MapReduce的分区:3.分区案例的补充完成运行实现 在MapReduce中,通过我们指定分区,会将同一个分区的数据发送到同一个reduce当中进行处理,例 ...
- c# window服务-初学习
window服务-初学习 一.工具: VS2015+NET Framework4.5. 二.操作: 1.新建windows服务的项目: 2.修改windows服务相关内容: 3.预览windows服务 ...
- Python初学习:简单的练习题
Python初学习 一些见到那的练习题: 初级难度 设计一重量转换器,输入以g为单位的数字后,返回换算结果以Kg为单位的结果 中级难度 设计一个求直角三角形斜边长的函数,(以两个直角边为参数,求最长边 ...
随机推荐
- CTP多点触摸协议【转】
转自:http://blog.chinaunix.net/uid-26403844-id-5063920.html linux kernel 2.6.30开始对多点触摸支持,最近高通要求所有CTP器件 ...
- Mybatis三剑客
1.Mybatis-generator 自动化生成数据库交互代码->dao+pojo+xml 2.Mybatis-plugin dao文件和xml自动跳转,验证正确性,在xml中只能提示等功能 ...
- Java坦克大战 (五) 之产生敌方坦克和爆炸效果
本文来自:小易博客专栏.转载请注明出处:http://blog.csdn.net/oldinaction 在此小易将坦克大战这个项目分为几个版本,以此对J2SE的知识进行回顾和总结,希望这样也能给刚学 ...
- MySQL 一般模糊查询的几种用法
1.%:表示零个或多个字符.在某些情况下需要中文查询,一般用两个%来查询,即%%: select * from user where name like %五%; -->表示:查询user表中的 ...
- centos6.5 卸载adobeflash
# rpm -e flash-plugin # rpm -qa | grep ^flash-plugin
- 关于 hibernate 中 hashCode爆栈的探讨
今天在 hibernate 的一对多映射测试 merge 方法时,出现了以下的异常: 我们可以看到,这里的错误有非常明显的重复性,很显然是做了间接递归,并且递归的调用是 hashMap 中的hashC ...
- 对于scanf和cin的输入输出速度的验证
本文为https://www.byvoid.com/zhs/blog/fast-readfile的验证性文章 --------------------------------------------- ...
- Xamarin XAML语言教程构建ControlTemplate控件模板 (二)
Xamarin XAML语言教程构建ControlTemplate控件模板 (二) (2)打开MainPage.xaml文件,编写代码,将构建的控件模板应用于ContentView中.代码如下: &l ...
- Eclipse 教程 | 菜鸟教程
http://www.runoob.com/eclipse/eclipse-charset.html
- 【线性基】【贪心】【独立环】bzoj2115 [Wc2011] Xor
网上到处都是题解,自己画个图也很好理解.虽然环的个数很多,但是都可以通过独立环之间异或出来,不用管. 独立环求法:生成树之后,每次向图里添加非树边(u,v),则这个独立环的异或和为sum[u]^sum ...