python3爬虫爬取煎蛋网妹纸图片(上篇)
其实之前实现过这个功能,是使用selenium模拟浏览器页面点击来完成的,但是效率实际上相对来说较低。本次以解密参数来完成爬取的过程。
首先打开煎蛋网http://jandan.net/ooxx,查看网页源代码。我们搜索其中一张图片的编号,比如3869006,看下在源代码中是否能找到图片链接

从上面的HTML结构中找到这个标号对应的一些属性,没有直接的图片链接地址,只有一个src=//img.jandan.net/blank.gif,这很明显不是个真实的链接地址,因为每一个图片编号都有这个值。我们注意到后面还有一个onload=‘jandan_load_img(this)’,可以大胆猜测真实地址有关,传入了一个this参数,也就是调用它的对象。然后后面还有一个img-hash,后面文本一长串的字符,按命名来看应该是图片的hash值,这个目前不知道什么用,先留意下就好,继续往后走,我们去看jandan_load_img()这个函数。
打开chrome F12开发者工具,刷新网页,查看NetWork选项卡中的js,可以在左侧列表项里找到一个包含jandan_load_img()函数的js。如下图:
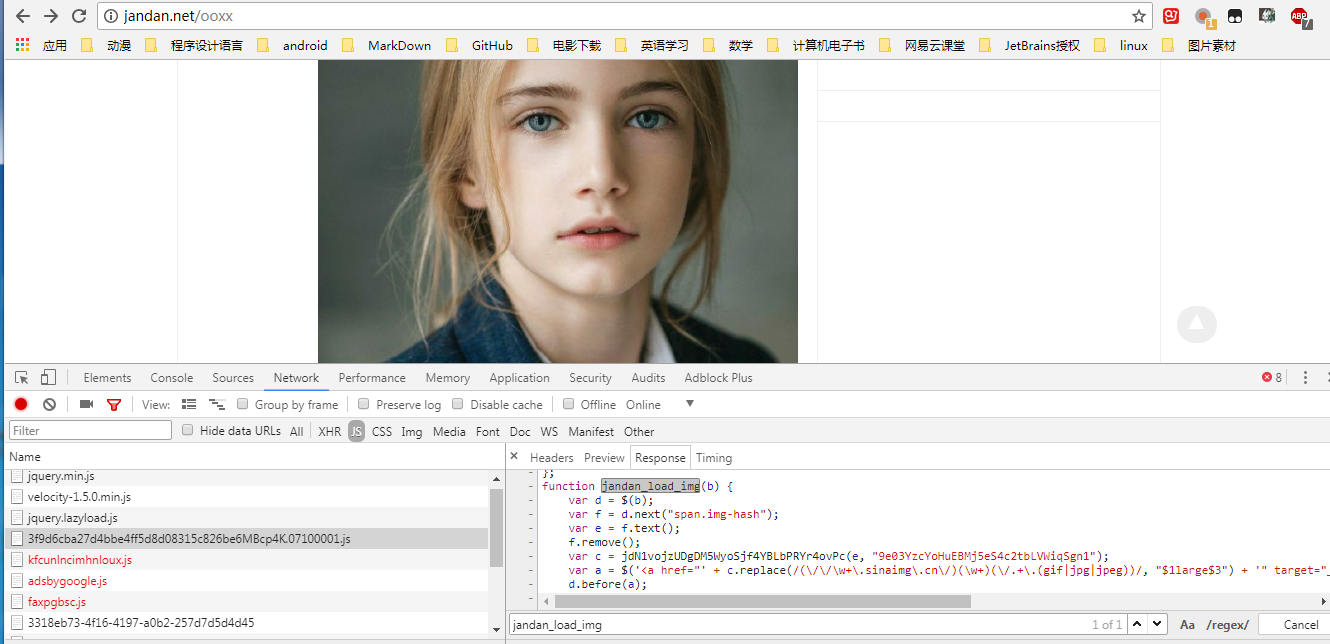
下面我们把这个函数拿出来分析下:
function jandan_load_img(b) {
// 传入一个参数b,把b赋值给变量d,把d的img-hash赋值给f,把f的文本提取出来。。。说白了就是e等于图片的hash值
var d = $(b);
var f = d.next("span.img-hash");
var e = f.text();
f.remove();
// 重点关注下面两句
var c = jdN1vojzUDgDM5WyoSjf4YBLbPRYr4ovPc(e, "9e03YzcYoHuEBMj5eS4c2tbLVWiqSgn1");
var a = $('<a href="' + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.(gif|jpg|jpeg))/, "$1large$3") +
'" target="_blank" class="view_img_link">[查看原图]</a>');
d.before(a);
d.before("<br>");
d.removeAttr("onload");
d.attr("src", location.protocol + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)/, "$1thumb180$3"));
if (/\.gif$/.test(c)) {
d.attr("org_src", location.protocol + c);
b.onload = function() {
add_img_loading_mask(this, load_sina_gif)
}
}
}
很明显可以看到里面有句话,查看原图,说明这个原始图片链接在这里。所以这个a就是我们所需要的,但是a是拼接起来的一个标签,真实的图片地址应该是c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.(gif|jpg|jpeg))/, "$1large$3"),所以现在算出c就可以了,看到变量c=jdN1vojzUDgDM5WyoSjf4YBLbPRYr4ovPc(e, "9e03YzcYoHuEBMj5eS4c2tbLVWiqSgn1"),这是一个函数,传入了两个参数,一个e(图片hash值),还有一个字符串,返回值赋值给了c。那我们继续找jdN1vojzUDgDM5WyoSjf4YBLbPRYr4ovPc函数,和jandan_load_img()在同一个js文件中。
函数如下:
var jdN1vojzUDgDM5WyoSjf4YBLbPRYr4ovPc = function(n, t, e) {
var f = "DECODE";
var t = t ? t : "";
var e = e ? e : 0;
var r = 4;
t = md5(t);
// 将n也就是图片的hash值赋值给变量d
var d = n;
var p = md5(t.substr(0, 16));
var o = md5(t.substr(16, 16));
if (r) {
if (f == "DECODE") {
var m = n.substr(0, r)
}
} else {
var m = ""
}
var c = p + md5(p + m);
var l;
if (f == "DECODE") {
n = n.substr(r);
l = base64_decode(n)
}
var k = new Array(256);
for (var h = 0; h < 256; h++) {
k[h] = h
}
var b = new Array();
for (var h = 0; h < 256; h++) {
b[h] = c.charCodeAt(h % c.length)
}
for (var g = h = 0; h < 256; h++) {
g = (g + k[h] + b[h]) % 256;
tmp = k[h];
k[h] = k[g];
k[g] = tmp
}
var u = "";
l = l.split("");
for (var q = g = h = 0; h < l.length; h++) {
q = (q + 1) % 256;
g = (g + k[q]) % 256;
tmp = k[q];
k[q] = k[g];
k[g] = tmp;
u += chr(ord(l[h]) ^ (k[(k[q] + k[g]) % 256]))
}
if (f == "DECODE") {
if ((u.substr(0, 10) == 0 || u.substr(0, 10) - time() > 0) && u.substr(10, 16) == md5(u.substr(26) + o).substr(0, 16)) {
u = u.substr(26)
} else {
u = ""
}
//进行base64解码
u = base64_decode(d)
}
return u
};
这个代码写的真。。。长,但是我们只分析自己需要的部分,上面jandan_load_img函数里的c是这个函数的返回值,也就是说我们只需要关注返回值就好。注意到这个返回值是y一个u,找到离return语句最近的u的赋值情况,可以看到,就是那句u=base64_decode(d),这个是一个base64解码,参数是d。我们再找这个d是神马玩意。主要到这个函数只有一句与d有关,就是var d = n,这个n是函数的第一个函数,也就是图片的hash值。也就是说,这个图片hash值经过一个base64解码后返回值就是c,也就是图片地址。
纳尼!!!!!!!!!你写这么长的代码就是整这么个事情么?!
我们以刚才那个图片hash值为例,用python代码写一下,看看到底是不是能得到图片的url。
#! usr/bin/env python
# coding:utf-8 import base64 img_hash = 'Ly93eDQuc2luYWltZy5jbi9tdzYwMC8wMDc2QlNTNWx5MWZzbWRxd2F1dzBqMzBnazBrcGFkOS5qcGc='
url = base64.b64decode(img_hash)
print(url)

用浏览器打开这个链接看一下。

我感觉我收到了侮辱!!!!!!我先吃碗面压压惊。相信大家看到这里,应该都会爬取煎蛋妹子图片了吧。代码改天再补,我是真的吃面去了。。
仅供学习,请勿用于商业用途哦。
python3爬虫爬取煎蛋网妹纸图片(上篇)的更多相关文章
- python3爬虫爬取煎蛋网妹纸图片(下篇)2018.6.25有效
分析完了真实图片链接地址,下面要做的就是写代码去实现了.想直接看源代码的可以点击这里 大致思路是:获取一个页面的的html---->使用正则表达式提取出图片hash值并进行base64解码--- ...
- python3爬虫.4.下载煎蛋网妹子图
开始我学习爬虫的目标 ----> 煎蛋网 通过设置User-Agent获取网页,发现本该是图片链接的地方被一个js函数代替了 于是全局搜索到该函数 function jandan_load_im ...
- python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做. 一直对爬虫很好奇,所以不妨从爬虫先入手吧. Python版本:3.6 这是我看的教程:Python - Jack -Cui ...
- Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代 ...
- python爬虫爬取煎蛋网妹子图片
import urllib.request import os def url_open(url): req = urllib.request.Request(url) req.add_header( ...
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
- 爬虫实例——爬取煎蛋网OOXX频道(反反爬虫——伪装成浏览器)
煎蛋网在反爬虫方面做了不少工作,无法通过正常的方式爬取,比如用下面这段代码爬取无法得到我们想要的源代码. import requests url = 'http://jandan.net/ooxx' ...
- scrapy从安装到爬取煎蛋网图片
下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/pip install wheelpip install lxmlpip install pyopens ...
随机推荐
- 【题解】AHOI2009中国象棋
还记得第一次看见这题的时候好像还是联赛前后的事了,那时感觉这题好强……其实现在看来蛮简单的,分类讨论一下即可.题意非常的简单:每一行,每一列都不能超过两个棋子.考虑我们的dp,如果一行一行转移的话行上 ...
- [CF620E]New Year Tree
题目大意:有一棵以$1$为根的有根树,有$n$个点,每个节点初始有颜色$c_i$.有两种操作: $1 v c:$将以$v$为根的子树中所有点颜色更改为$c$ $2 v:$ 查询以$v$为根的子树中的节 ...
- taotao前台页面显示登录用户名的处理
思路: 在每个页面上都引入一个 jsp,这个 jsp 可以是页面的头 head 或者脚 footer.jsp 然后在这个 jsp 中引入 一个 js,这个 js 中 有个 随页面加载 而执行的 方法, ...
- ng依赖注入
依赖注入 1.注入器在组件的构造函数中写服务constructor(private httpreq:HttpService) { } 2.提供器 providers: [HttpService],
- springboot之模板
转:http://jisonami.iteye.com/blog/2301387,http://412887952-qq-com.iteye.com/blog/2292402 整体步骤:(1) ...
- scrapy 为每个pipeline配置spider
在settings.py里面配置pipeline,这里的配置的pipeline会作用于所有的spider,我们可以为每一个spider配置不同的pipeline, 设置 Spider 的 custom ...
- 解读dbcp自动重连那些事
转载自:http://agapple.iteye.com/blog/791943 可以后另一篇做对比:http://agapple.iteye.com/blog/772507 同样的内容,不同的描述方 ...
- maven工程开启jetty调试
转摘自:http://czj4451.iteye.com/blog/1942437 准备工作: a. 在pom.xml中配置jetty插件: <plugins> <plugin> ...
- Linux 安装编译 FFMPEG
资源准备: ffmpeg-3.4.tar.bz2 yasm-1.3.0.tar.gz 编译安装: 本人二进制包存放在 /opt/moudles中, 解压缩在 /opt/softwares 解包 ffm ...
- SpringBoot入门学习(一): Idea 创建 SpringBoot 的 HelloWorld
创建项目: 项目结构: 程序启动入口: 正式开始: package com.example.demo; import org.springframework.boot.SpringApplicatio ...