Scala零基础教学【61-80】
第61讲:Scala中隐式参数与隐式转换的联合使用实战详解及其在Spark中的应用源码解析
第62讲:Scala中上下文界定内幕中的隐式参数与隐式参数的实战详解及其在Spark中的应用源码解析
/**
* Scala中上下文界定内幕中的隐式参数与隐式参数的实战详解及其在Spark中的应用源码解析
*/
//[T: Ordering] 这种写法 说明存在一个隐式类型Ordering[T]
class Pair_Implicits[T: Ordering](val first: T, val second: T){
//声明一个隐式类型对象传入函数
def bigger(implicit ordered: Ordering[T]) = {
if (ordered.compare(first, second) > 0) first else second
}
} class Pair_Implicitly[T: Ordering](val first: T, val second: T){
def bigger =
/**
* 在Predef中定义了implicitly一个方法 可以简化上面的写法
* @inline def implicitly[T](implicit e: T) = e
* 不使用implicit的隐形类型转换
*/
if (implicitly[Ordering[T]].compare(first, second) > 0) first else second
} class Pair_Implicitly_Ordereded[T: Ordering](val first: T, val second: T) {
def bigger = {
import Ordered._
if (first > second) first else second
}
} object Context_Bounds_Internals { def main(args: Array[String]): Unit = {
println(new Pair_Implicits(7, 9).bigger)
println(new Pair_Implicitly(7, 9).bigger)
println(new Pair_Implicitly_Ordereded(7, 9).bigger) }
}
第63讲:Scala中隐式类代码实战详解
import java.io.File
import scala.io.Source
object Context_Helper{
implicit class FileEnhancer(file : File){
def read = Source.fromFile(file.getPath).mkString
}
implicit class Op(x:Int){
def addSAP(second: Int) = x + second
}
}
object Implicits_Class {
def main(args: Array[String]){
import Context_Helper._
println(1.addSAP(2))
println(new File("F:\\1.txt").read)
}
}
第64讲:Scala中隐式对象代码实战详解
abstract class Template[T] {
def add(x: T, y: T): T
}
abstract class SubTemplate[T] extends Template[T] {
def unit: T
}
//执行过程检查当前作用是否有 implicit object 限定的 类型为 SubTemplate 的对象,
// 如有,则选取此对象。
object Implicits_Object {
def main(args: Array[String]) {
implicit object StringAdd extends SubTemplate[String] {
override def add(x: String, y: String) = x concat y
override def unit: String = ""
}
implicit object IntAdd extends SubTemplate[Int] {
override def add(x: Int, y: Int) = x + y
override def unit: Int = 0
}
//含有隐式参数,m是隐式对象部分
def sum[T](xs: List[T])(implicit m: SubTemplate[T]): T =
{println(xs,m)
if (xs.isEmpty) m.unit
else m.add(xs.head, sum(xs.tail))}
println(sum(List(1, 2, 3, 4, 5)))
println(sum(List("Scala", "Spark", "Kafka")))
}
}
运行结果:
(List(1, 2, 3, 4, 5),com.wanji.scala.implicits.Implicits_Object$IntAdd$2$@6b143ee9)
(List(2, 3, 4, 5),com.wanji.scala.implicits.Implicits_Object$IntAdd$2$@6b143ee9)
(List(3, 4, 5),com.wanji.scala.implicits.Implicits_Object$IntAdd$2$@6b143ee9)
(List(4, 5),com.wanji.scala.implicits.Implicits_Object$IntAdd$2$@6b143ee9)
(List(5),com.wanji.scala.implicits.Implicits_Object$IntAdd$2$@6b143ee9)
(List(),com.wanji.scala.implicits.Implicits_Object$IntAdd$2$@6b143ee9)
15
(List(Scala, Spark, Kafka),com.wanji.scala.implicits.Implicits_Object$StringAdd$2$@1936f0f5)
(List(Spark, Kafka),com.wanji.scala.implicits.Implicits_Object$StringAdd$2$@1936f0f5)
(List(Kafka),com.wanji.scala.implicits.Implicits_Object$StringAdd$2$@1936f0f5)
(List(),com.wanji.scala.implicits.Implicits_Object$StringAdd$2$@1936f0f5)
ScalaSparkKafka
第65讲:Scala中隐式转换内幕操作规则揭秘、最佳实践及其在Spark中的应用源码解析
import scala.io.Source
import java.io.File class RicherFile(val file:File){
def read = Source.fromFile(file.getPath()).mkString
} class File_Implicits( path: String) extends File(path)
object File_Implicits{
implicit def file2RicherFile(file:File)= new RicherFile(file) //File -> RicherFile
} object Implicits_Internals {
def main(args: Array[String]) {
/**
* 这里没有导入隐式对象
*
* 通过给File_Impkicits类 构建一个伴生对象 在伴生对象内部顶一个隐式转换的方法
*
* 执行顺序:
* 1.搜索File_Impkicits有无read方法
* 2.在上下文上搜索(有无导入的隐式对象)
* 3.搜索File_Impkicits的伴生对象内有无隐式转换 发现implicit关键 尝试匹配类型
* 4.例如这里匹配file2RichFile(file: File) 返回类型为RichFile 在RichFile中发现read方法
*
* 规则:
* 1.编译器标记为implicit
* 2.作用域规则:单一标识符,关联类或者对象
* 3.隐式转换没有歧义
* 4.单一调用规则
*/
println(new File_Implicits("F:\\1.txt").read)
}
}
第66讲:Scala并发编程实战初体验及其在Spark源码中的应用解析
程序宏大的java并发编程非常复杂。
java并发编程的理念:基于共享数据和加锁。
java多线程同时访问一个加锁数据是容易发生死锁。
scala的并发编程:actor。与java实现方式完全不同,actor不共享数据,依赖消息传递。
A传给B消息,B不停看收件箱。
B看到邮件后处理。
object First_Actor extends Actor {
def act() {
println(Thread.currentThread().getName())
for (i <- 1 to 10) {
println("Step : " + i)
Thread.sleep(2000)
}
}
}
object Second_Actor extends Actor {
def act() {
println(Thread.currentThread().getName())
for (i <- 1 to 10) {
println("Step Further : " + i)
Thread.sleep(2000)
}
}
}
object Hello_Actor {
def main(args: Array[String]) {
First_Actor.start
Second_Actor.start
}
}
第67讲:Scala并发编程匿名Actor、消息传递、偏函数实战解析及其在Spark源码中的应用解析
import scala.actors.Actor._
import scala.actors.Actor object Actor_Message01 extends Actor {
def act() {
while(true){
receive {
case msg => println("Message content Actor from inbox: " + msg)
}
}
}
}
object Actor_Messages { def main(args: Array[String]) {
//匿名Actor
val actor_Message = actor{//Actor伴生对象带有一个actor方法,来创建和启动actor
while(true){
receive {
//偏函数,其中两个方法:apply()和isDefinedAt()。
//其中apply()负责在匹配时解析数据。
//isDefinedAt() 判断消息是否已经被定义成要处理的消息,如果是,返回true,交给apply()解析;否的话,返回false,不作处理。
//Actor只是处理receive中可以匹配上的情况,不匹配的话,则会静悄悄的忽略掉。
//Actor的邮箱里如果没有消息,或者没有匹配的消息,receive方案则会阻塞。
case msg => println("Message content from inbox: " + msg)
}
}
}
val double_Message = actor{
while(true){
/*创建匿名actor,此处actor的a是小写,一定要注意*/
receive {
case msg : Double => println("Double Number from inbox: " + msg)
case _ => println("Something Unkown" )
}
}
}
/*
receive是偏函数,使用case匹配,如果没有匹配时会报错。
偏函数,有apply isDefinedAt方法(判断消息是否已被定义为要处理的消息)
receive中如果没有case,不会报错,只会忽略。
偏函数只会对收到的消息中第一个定义为isDefinedAt为true的消息传递给偏函数的apply方法,apply方法再通过case匹配
如果邮箱中没有isDefinedAt为true的消息,receive所在的actor处于阻塞状态。一直等待消息到来。
*/
Actor_Message01.start
//!函数定义send(msg, Actor.rawSelf(scheduler))
//向actor发送msg
Actor_Message01 ! "Hadoop"
actor_Message.start
actor_Message ! "Spark"
double_Message ! Math.PI
double_Message ! "Hadoop" } }
第68讲:Scala并发编程原生线程Actor、Cass Class下的消息传递和偏函数实战解析及其在Spark中的应用源码解析
(1)Scala的原生线程(Main主线程)也可以看做是一个Actor,当它需要接受并处理消息的时候,会直接调用Actor伴生对象的self方法返回一个Actor实例对象,这样通过这个Actor实例对象的receive方法来接受并处理其他Actor发送给主线程的消息。
(2)在Scala语言中,消息的传递常常通过Case Class(Case Object)和模式匹配相结合的方式进行,使用Case Class既可以保证消息在传递过程中的不变性,同时在使用模式匹配进行消息的处理时可以很方便地提取Case Class中的数据来使用。
(3)一个Actor本身可以向其他的Actor发送消息,比如,向一个作为类的成员变量的全局Actor发送消息;向一个或多个Actor的引用发送消息;向该Actor的消息发送方发送消息;如果该Actor接受到的消息中包含指向另一个Actor的引用,这时也可以通过这个引用向另外的Actor发送消息。
(4)为了避免Actor接受到的消息无法匹配到消息处理中的偏函数,导致该Actor邮箱中被一些无关的消息占满,一般情况下,都会在该Actor的receive方法中增加一个 case _ 选项,使得receive方法可以处理掉邮箱中收到的所有消息。
//定义一个case class作为消息体
case class Person(name: String, age: Int) class HelloActor extends Actor{
def act(){
while(true){
receive {
//用case class进行模式匹配消息
case Person(name, age) => {
println("Name: " + name + " : " + "Age: " + age)
//向主线程发消息
sender ! "Echo!!!"}
case _ => println("Something else...")
}
}
}
}
object Actor_With_CaseClass { def main(args: Array[String]) {
val hiActor = new HelloActor
hiActor.start
hiActor ! Person("Spark", 6)
//让主线程接受消息(把主线程作为Actor使用) 默认是阻塞的
self.receive{
case msg => println("receive new msg:"+msg)
}
//receiveWithin偏函数 参数设置是超时时间
self.receiveWithin(1000){case msg => println(msg)}
} }
第69讲:Scala并发编程react、loop代码实战详解
(1)在Actor类的act方法中,可以使用react方法来替代receive方法进行消息的处理,使用react方法的好处是可以在一个线程中执行多个Actor的消息处理函数,需要注意的是当react方法接受到的消息匹配到它方法体中的一个偏函数时并进行消息的处理后会导致该react方法的退出,这时一般常常在react方法中每个偏函数的最后一行加上 act()方法 使得react方法可以重新关联Actor的邮箱。
(2)由于让消息处理器中的每个偏函数末行加上一个 act()方法 来负责保持循环继续下去是一件很麻烦且很不公平的事情,Scala语言提供了loop组合子来简化这个问题,在Actor的act()方法和react方法之间使用loop组合子可以生成一个无限的循环,如果想给循环加上一个条件,可以把loop换成loopWhile,然后在其后面加上条件判断语句。
object NameResolver extends Actor{
def act(){
//用react方法来替代receive方法进行消息的处理,
// react允许共享线程资料,react方法匹配一次并执行完成,然后会退出,
// 通过再次调用act()方法来重新关联Actor的邮箱。
// react {
// case Net (name, actor) =>
// actor ! getIp(name)
// act //通过调用继续处理邮箱信息
// case "EXIT" => println("Name resolver exiting.")
// case msg =>
// println("Unhandled message : " + msg)
// act
// }
//loop可以循环调用react来处理邮箱的信息
loop {
react {
case Net (name, actor) =>
actor ! getIp(name)
case msg =>
println("Unhandled message : " + msg)
}
}
}
def getIp(name : String) : Option[InetAddress] = {
try{
println(InetAddress.getByName(name))
Some(InetAddress.getByName(name))
} catch {
case _ : UnknownHostException => None
}
}
}
case class Net(name : String, actor: Actor)
object Actor_More_Effective {
def main(args: Array[String]) {
NameResolver.start
NameResolver ! Net("www.baidu.com", self)
println(self.receiveWithin(1000){case x => x})
}
}
第70讲:Scala界面GUI编程实战详解
Scala中的界面编程是封装和改进了java的界面编程的swing库,当然我们在用scala进行界面编程的时候,要先引入此类库,下面让我们从代码实战出发。
import scala.swing._
object Hello_GUI extends SimpleSwingApplication{
def top = new MainFrame {
title = "Hello GUI"
contents = new Button {
text = "Scala and Spark!!!"
}
}
}
SimpleSwingApplication定义了界面的一些初步设置,里面包含了main方法,所以在上面的程序中,没有main方法,我们的程序也可以运行。
top方法这里其实是SimpleSwingApplication的top方法的复写,它的类型为Frame。
MainFrame是一个主框架的方法类,是一个容易,里面包含了title,contents等元素,所以我们在重写top方法时,设置了相应的组件的各种属性。
第74讲:从Spark源码的角度思考Scala中的模式匹配
从源码角度分析Scala中的模式匹配的功能。
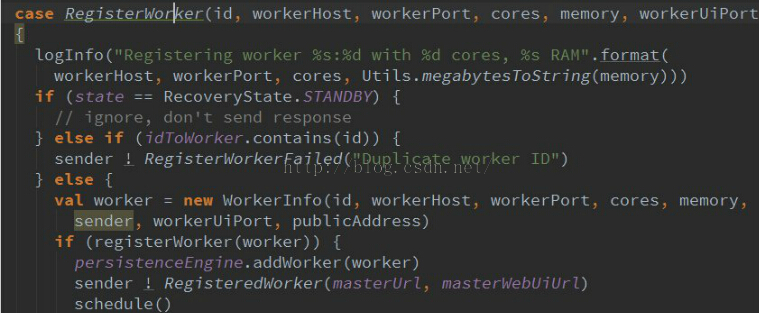
从代码中我们可以看到,case RegisterWorker(id,workerHost,……..){}这里为模式匹配,而我们的模式匹配类RegisterWorker之前就已定义好,如下图:
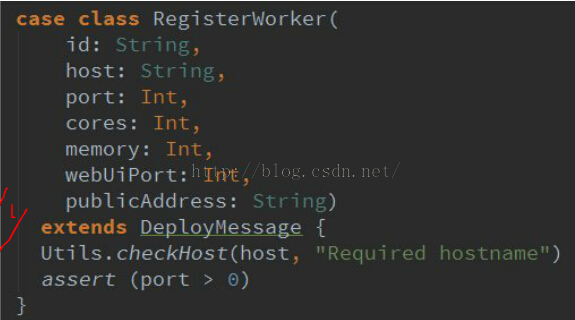
我们可以看到,我们的模式匹配类是已经定义好的,当我们的master接收到worker发来的消息时,进行模式匹配:

这里还有一个知识点,我们可以发现,当我们进行模式匹配时,我们并没有使用new方法新建一个实例,而是直接使用RegisterWorker(id,…..)。
而这里,我们使用的就是类的伴生对像里的apply方法。当进行模式匹配时,还会用到unapply方法来解析实例传过来的内容。
实现case class最最重要的是两个方法:apply/unapply
scala在case class伴生对象中定义了这两个方法。
apply用于对象的生成。所以在代码中直接使用case class,没有new case class
unapply是为模式匹配进行内容匹配的,RegisterWorker
匹配worker发过来的worker进程启动时的注册信息
RegisterWorker在匹配时调用RegisterWorker伴生的unapply方法
如果apply是工厂模式来构建具体的RegisterWorker,
unapply是结构模式,把传进来的对象的成员结构出来,
模式匹配时会暴露所有成员
所以extractor,主要指从对象中提取出相关成员
由于要提取时手动定义unapply,所以可以对对象进行很好的控制
对外暴露时只暴露对象的结构而不暴露对象的实现,
可以做到很好的面向结构编程。
手动定义一个类在类中定义伴生对象的unapply方法可带来更大灵活性
第75讲:模式匹配下的For循环
object For_Advanced {
def main(args: Array[String]): Unit = {
for(i <- List(1,2,3,4,5) ) {println(i)}
//配数据中含有 Flink 的数据,并将打印出来
for(index@"Flink" <- List("Hadoop","Spark","Flink") ) {println(index)}
//匹配第2个元素为 hadoop的的key值
for ((language,"Hadoop") <- Set("Scala"->"Spark","Java"->"Hadoop") ) println(language)
//匹配第二个元素的数据类型为 Int的tuple,并将该tutple 的第一个元素打印出来
for((k,v:Int) <- List(("Spark"->5),("Hadoop"->"Big Data"))) {println(k)}
}
}
第76讲:模式匹配下的赋值语句
本讲重点掌握内容:
(1)元组方式的赋值,函数可能返回很多不同类型的值,元组就可以容纳不同类型的值
(2)数组进行成员的匹配
def main(args: Array[String]) {
val a@b = 1000
//@是别名的意思,a@b形成了tuple2二元元组
//把1000赋值给a和b,并返回二元组的内容给val a@b
println("a = " + a + ", b = " + b)
val (c,d) = (1000,2000)
// val (e,F) = (1000,2000)
val Array(g,h) = Array(1000,2000)
// val Array(i,J) = Array(1000,2000)
// object Test { val 1 = 1 }
object Test { val 1 = 2 }
第77讲:模式匹配下的提取器动手构造实战
object :>{ //定义提取器 :>
def unapply[A](list:List[A]) = {
Some(list.init,list.last)
}
}
object Extractor_Pattern_Match {
def main(args: Array[String]) {
(1 to 9).toList match { case :>(_,9) => println("aa")}
(1 to 9).toList match { case _ :> 9 => println("spark")}
(1 to 9).toList match { case x :> 8 :>9 => println("hadoop") }
(1 to 9).toList match { case :>(:>(_,8),9)=>println("flink")}
}
}
当进行匹配时,调用提取器(:>) 的方法 unapply方法,
输入参数:(1 to 9).toList
输出参数:Some(list.init,list.last) (这里结果为((1 to 8),9)
然后用输出参数与 case 语句比较
如 case :>(_,9) => println(“aa”) ,发现最后一个元素为9 ,满足要求 直接打印,就这个例子可以理解为
参入参数 必须是list 类型,同时要求 此list的最后一个元素为9
小技巧:
scala :表示是 右结合
:>( _,9) 与 _ :> 9 写法的功能相同
第78讲:Type与Class实战详解
本讲主要讲解scala中的type与class的区别
由于在scala中非常强调泛型或者说类型系统
Java和scala是基于jvm的,
java1.5以前具体对象的类型与class一一对应
后来引入泛型,如字符串数组或整数数组,都是数组
但其实类型是不一样的,在虚拟机内部,并不关心泛型或类型系统
对泛型支持是基于运行时角度考虑的,在虚拟机中泛型被编译运行时是被擦除的,
在运行时泛型是通过反射方式获取,在scala中类型系统非常强大
在scala中有一个scala.reflect.runtime.universe
与class比,type更具体,任何数据都有类型,
class其实是一种数据结构和基于该数据结构的一种抽象,
例如array,或file有自己的成员和方法,更宏观。
type本身更具体 。
import scala.reflect.runtime.universe._ class Spark
trait Hadoop
object Flink
class Java{
class Scala
}
object Type_Advanced { def main(args: Array[String]) {
println(typeOf[Spark])
println(classOf[Spark]) //Class[_ <: Spark]表明子类 val spark = new Spark
println(spark.getClass==classOf[Spark])//true println(typeOf[Hadoop])
println(classOf[Hadoop]) println(Flink.getClass)
//运行结果打印class com.dt.scala.bestpractice.Flink$
//生动地告诉我们object背后是有具体的class的 //println(classOf[Flink]) 报没有找到Flink类错误
//classOf与getClass基本是没有区别的,
//但getClass是获得具体的类的子类,
//classOf是类本身,
println("********************************")
val java1 = new Java
val java2 = new Java
val scala1 = new java1.Scala
val scala2 = new java2.Scala
println(scala1.getClass==scala2.getClass)//上面两例打印结果都是:Java$Scala
println(scala1.getClass)
println(scala2.getClass)
println(typeOf[java1.Scala] == typeOf[java2.Scala])
println(typeOf[java1.Scala]) //打印结果:java1.Scala
println(typeOf[java2.Scala])//打印结果:java2.Scala
//从打印结果可以看出typeOf返回具体信息,而getClass返回更高层的信息
println("=========================================")
println(classOf[List[Int]] == classOf[List[String]])//true
println(typeOf[List[Int]] == typeOf[List[String]])//false } }
第79讲:单例深入讲解及单例背后的链式表达式
import scala.reflect.runtime.universe._
class Animal {
def breathe : this.type = this
}
class Cat extends Animal {
def eat : this.type = this
}
object Scala
class Java1
class JVM { def method1: this.type = this }
class JVM_Language extends JVM { def method2 : this.type = this }
object Singleton_Type {
def main(args: Array[String]){
val cat=new Cat
/**
* 代码2 报错
* cat.breathe 返回的是Animal的this
* Animal实例没有eat方法,所以报错
*/
/**
*为了到达链式调用,采用代码1
* 注意:this.type=this
*
* Q:type是指什么?
* A:在Scala中任何类对象都有一个type属性
*
* 当执行cat.breathe其实返回cat类实例的type
* 而这个type有eat方法
*/
println("Test:"+cat.breathe)
println(Scala.getClass)
println(typeOf[Scala.type])
val java = new Java1
val java2 = new Java1
println(typeOf[java.type])
println(typeOf[java2.type])
val content:java.type = java
// val content:java.type = java2
//说明任何一个实例对象都有唯一的单例
//虽然背后的class是一样的,但typeOf是不一样的。
//意义非常大,
val jvm = new JVM_Language
println(jvm.method1)
println(jvm.method1.method2)
/*这是一个链式表达式,由于任何一个实例对象都有唯一的单例
所以可以采用实例的type的方式,this就是jvm实例。
所以jvm.method1返回的是jvm本身。这样就可以再返回.method2
this.type是依附于具体实例的,所以是动态的。
this.type就是利用this的动态特性完成了执行method1时返回的内容。
这样可很好地做链式表达式。
返回的是动态对象的单例本身。
链式方式在spark的RDD中非常常见。*/
}
}
第80讲:List的泛型分析以及::类和Nil对象
::类和Nil都是List的子类:
::表示一个非空列表,Nil与之相反,表示空列表。
Scala零基础教学【61-80】的更多相关文章
- Scala零基础教学【1-20】
基于王家林老师的Spark教程——共计111讲的<Scala零基础教学> 计划在9月24日内完成(中秋节假期之内) 目前18号初步学习到25讲,平均每天大约完成15讲,望各位监督. 初步计 ...
- Scala零基础教学【102-111】Akka 实战-深入解析
第102讲:通过案例解析Akka中的Actor运行机制以及Actor的生命周期 Actor是构建akka程序的核心基石,akka中actor提供了构建可伸缩的,容错的,分布式的应用程序的基本抽象, a ...
- Scala零基础教学【90-101】Akka 实战-代码实现
第90讲:基于Scala的Actor之上的分布式并发消息驱动框架Akka初体验 akka在业界使用非常广泛 spark背后就是由akka驱动的 要写消息驱动的编程模型都首推akka 下面将用30讲讲解 ...
- Scala零基础教学【81-89】
第81讲:Scala中List的构造是的类型约束逆变.协变.下界详解 首先复习四个概念——协变.逆变.上界.下界 对于一个带类型参数的类型,比如 List[T]: 如果对A及其子类型B,满足 List ...
- Scala零基础教学【41-60】
第41讲:List继承体系实现内幕和方法操作源码揭秘 def main(args: Array[String]) { /** * List继承体系实现内幕和方法操作源码揭秘 * * List本身是一个 ...
- Scala零基础教学【21-40】
第24讲:Scala中SAM转换实战详解 SAM:single abstract method 单个抽象方法 我们想传入一个函数来指明另一个函数具体化的工作细节,但是重复的样板代码很多. 我们不关 ...
- Android零基础入门第80节:Intent 属性详解(下)
上一期学习了Intent的前三个属性,本期接着学习其余四个属性,以及Android系统常用内置组件的启动. 四.Data和Type属性 Data属性通常用于向Action属性提供操作的数据.Data属 ...
- Scala实战高手****第2课:Scala零基础实战入门的第一堂课及如何成为Scala高手
val声明的不可变的战略意义:1.函数式编程中要求值不可变,val天然符合这一特性:2.在分布式系统中,一般都要求值不可变,这样才能够要求分布式系统的设计和实现,同时拥有更高的效率,val声明的内容都 ...
- Android零基础入门第89节:Fragment回退栈及弹出方法
在上一期分享的文章末尾留了一个课后作业,有去思考如何解决吗?如果已经会了那么恭喜你,如果还不会也没关系,本期一起来学习. 一.回退栈 在前面两期的示例中,当我们完成一些操作后,如果想要回到操作之前的状 ...
随机推荐
- Nginx替换过滤文本模块replace-filter-nginx-module
1.安装此模块需要先安装sregex运行库 apt-get update;apt-get install git make gcc -y #Centos改成yum git clone https:// ...
- vivo面试学习3(git和svn的区别)
git和svn有什么区别? svn: 系统特点: 1).集中式版本控制系统(存在一个中央版本库,所有开发人员所使用的代码都是来源于版本库,提交代码也是这个中央版本库) 2).企业内部并行集中开发 3) ...
- 【BZOJ3450】Easy [期望DP]
Easy Time Limit: 10 Sec Memory Limit: 128 MB[Submit][Status][Discuss] Description 某一天WJMZBMR在打osu~~ ...
- noip2013 提高组
T1 转圈游戏 题目传送门 果不其然 第一题还是模拟题 一波快速幂解决问题 #include<cstdio> #include<cstring> #include<alg ...
- [BZOJ1026][SCOI2009]windy数 解题报告|数位dp
Description windy定义了一种windy数.不含前导零且相邻两个数字之差至少为2的正整数被称为windy数. windy想知道,在A和B之间,包括A和B,总共有多少个windy数? 一直 ...
- [bzoj3532][Sdoi2014]Lis——拆点最小割+字典序+退流
题目大意 给定序列A,序列中的每一项Ai有删除代价Bi和附加属性Ci.请删除若 干项,使得4的最长上升子序列长度减少至少1,且付出的代价之和最小,并输出方案. 如果有多种方案,请输出将删去项的附加属性 ...
- bzoj 1876 高精
首先我们知道,对于两个数a,b,他们的gcd情况有如下形式的讨论 当a为奇数,b为偶数的时候gcd(a,b)=gcd(a div 2,b) 当b为奇数,a为偶数的时候gcd(a,b)=gcd(a,b ...
- bzoj 1208 HNOI2004宠物收养所 平衡树
裸平衡树,恢复手感用的 //By BLADEVIL var n :longint; i :longint; x, y :longint; t, tot :longint; key, s, left, ...
- web前端 html基础2
表单标签<form></form> input系列标签 text 文本输入框 placeholder 默认的属性,输入时消失 password 密码输入框 radio 单选框 ...
- phpstorm+xdebug详解
1.run->edit configurations StartUrl最好是网址,不然容易出错,Server选择的是配置时添加的Servers,详可参考:http://www.cnblogs.c ...