GFS文件系统
1.1 分布式文件系统
1.1.1 什么是分布式文件系统
相对于本机端的文件系统而言,分布式文件系统(英语:Distributed file system, DFS),或是网络文件系统(英语:Network File System),是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
在这样的文件系统中,客户端并非直接访问底层的数据存储区块,而是通过网络,以特定的通信协议和服务器沟通。借由通信协议的设计,可以让客户端和服务器端都能根据访问控制清单或是授权,来限制对于文件系统的访问。
1.1.2 glusterfs是什么
Gluster是一个分布式文件系统。它是各种不同的存储服务器之上的组合,这些服务器由以太网或无限带宽技术Infiniband以及远程直接内存访问RDMA互相融汇,最终所形成的一个大的并行文件系统网络。
它有包括云计算在内的多重应用,诸如:生物医药科学,文档存储。Gluster是由GNU托管的自由软件,证书是AGPL。Gluster公司是Gluster的首要商业赞助商,且提供商业产品以及基于Gluster的解决方案。
1.2 快速部署GlusterFS
1.2.1 环境说明
注意:最少需要拥有两块硬盘
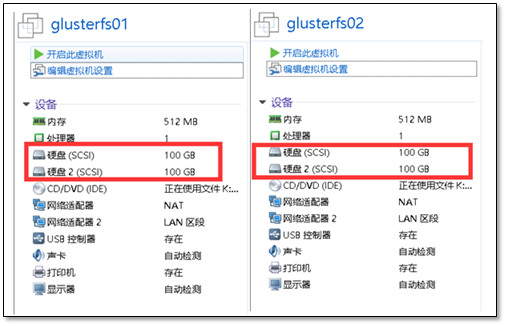
系统环境说明
glusterfs01信息
[root@glusterfs01 ~]# hostname
glusterfs01
[root@glusterfs01 ~]# uname -r
3.10.0-693.el7.x86_64
[root@glusterfs01 ~]# sestatus
SELinux status: disabled
[root@glusterfs01 ~]# systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
[root@glusterfs01 ~]# hostname -I
10.0.0.120 172.16.1.120
glusterfs02信息
[root@glusterfs02 ~]# uname -r
3.10.0-693.el7.x86_64
[root@glusterfs02 ~]# sestatus
SELinux status: disabled
[root@glusterfs02 ~]# systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
[root@glusterfs02 ~]# hostname -I
10.0.0.121 172.16.1.121
注意配置好hosts解析
1.2.2 前期准备
gluster01主机挂载磁盘
[root@glusterfs01 ~]# mkfs.xfs /dev/sdb [root@glusterfs01 ~]# mkdir -p /data/brick1 [root@glusterfs01 ~]# echo '/dev/sdb /data/brick1 xfs defaults 0 0' >> /etc/fstab [root@glusterfs01 ~]# mount -a && mount
gluster02主机挂载磁盘
[root@glusterfs02 ~]# mkfs.xfs /dev/sdb [root@glusterfs02 ~]# mkdir -p /data/brick1 [root@glusterfs02 ~]# echo '/dev/sdb /data/brick1 xfs defaults 0 0' >> /etc/fstab [root@glusterfs02 ~]# mount -a && mount
1.3 部署GlusterFS
1.3.1 安装软件
在两个节点上操作
yum install centos-release-gluster -y # 修改镜像源加速 sed -i 's#http://mirror.centos.org#https://mirrors.shuosc.org#g' /etc/yum.repos.d/CentOS-Gluster-3.12.repo yum install -y glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
软件版本
[root@glusterfs01 ~]# rpm -qa glusterfs glusterfs-3.12.5-2.el7.x86_64
1.3.2 启动GlusterFS
在两个节点上都进行操作
[root@glusterfs01 ~]# systemctl start glusterd.service
[root@glusterfs01 ~]# systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/usr/lib/systemd/system/glusterd.service; disabled; vendor preset: disabled)
Active: active (running) since 三 2018-02-07 21:02:44 CST; 2s ago
Process: 1923 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 1924 (glusterd)
CGroup: /system.slice/glusterd.service
└─1924 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
2月 07 21:02:44 glusterfs01 systemd[1]: Starting GlusterFS, a clustered file-system server...
2月 07 21:02:44 glusterfs01 systemd[1]: Started GlusterFS, a clustered file-system server.
Hint: Some lines were ellipsized, use -l to show in full.
1.3.3 配置互信(可信池)
在glusterfs01上操作
[root@glusterfs01 ~]# gluster peer probe glusterfs02 peer probe: success.
在glusterfs02上操作
[root@glusterfs02 ~]# gluster peer probe glusterfs01 peer probe: success.
注意:一旦建立了这个池,只有受信任的成员可能会将新的服务器探测到池中。新服务器无法探测池,必须从池中探测。
1.3.4 检查对等状态
[root@glusterfs01 ~]# gluster peer status Number of Peers: 1 Hostname: 10.0.0.121 Uuid: 61d043b0-5582-4354-b475-2626c88bc576 State: Peer in Cluster (Connected) Other names: glusterfs02
注意:看到的UUID应不相同。
[root@glusterfs02 ~]# gluster peer status Number of Peers: 1 Hostname: glusterfs01 Uuid: e2a9367c-fe96-446d-a631-194970c18750 State: Peer in Cluster (Connected)
1.3.5 建立一个GlusterFS卷
在两个节点上操作
mkdir -p /data/brick1/gv0
在任意一个节点上执行
[root@glusterfs01 ~]# gluster volume create gv0 replica 2 glusterfs01:/data/brick1/gv0 glusterfs02:/data/brick1/gv0 Replica 2 volumes are prone to split-brain. Use Arbiter or Replica 3 to avoid this. See: http://docs.gluster.org/en/latest/Administrator%20Guide/Split%20brain%20and%20ways%20to%20deal%20with%20it/. Do you still want to continue? (y/n) y volume create: gv0: success: please start the volume to access data
启用存储卷
[root@glusterfs01 ~]# gluster volume start gv0 volume start: gv0: success
查看信息
[root@glusterfs01 ~]# gluster volume info Volume Name: gv0 Type: Replicate Volume ID: 865899b9-1e5a-416a-8374-63f7df93e4f5 Status: Started Snapshot Count: 0 Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: glusterfs01:/data/brick1/gv0 Brick2: glusterfs02:/data/brick1/gv0 Options Reconfigured: transport.address-family: inet nfs.disable: on performance.client-io-threads: off
至此,服务端配置结束
1.4 客户端测试
1.4.1 安装客户端工具
挂载测试
[root@clsn6 ~]# yum install centos-release-gluster -y [root@clsn6 ~]# yum install -y glusterfs glusterfs-fuse
注意:要配置好hosts文件,否则连接会出错
[root@clsn6 ~]# mount.glusterfs glusterfs01:/gv0 /mnt [root@clsn6 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda3 19G 2.2G 16G 13% / tmpfs 238M 0 238M 0% /dev/shm /dev/sda1 190M 40M 141M 22% /boot glusterfs01:/gv0 100G 33M 100G 1% /mnt
1.4.2 复制文件测试
[root@clsn6 ~]# for i in `seq -w 1 100`; do cp -rp /var/log/messages /mnt/copy-test-$i; done
客户端检查文件
[root@clsn6 ~]# ls -lA /mnt/copy* | wc -l 10
服务节点检查文件
[root@glusterfs01 ~]# ls -lA /data/brick1/gv0/copy* |wc -l 100
服务节点检查文件
[root@glusterfs02 ~]# ls -lA /data/brick1/gv0/copy* |wc -l 100
至此Glusterfs简单配置完成
GFS文件系统的更多相关文章
- GFS文件系统和在RedHat Linux下的配置
GFS的全称是Google file System,为了满足Google迅速增长的数据处理要求,Google设计并实现的Google文件系统(GFS).Google文件系统是一个可扩展的分布式文件系统 ...
- Google GFS文件系统深入分析
Google GFS文件系统深入分析 现在云计算渐成潮流,对大规模数据应用.可伸缩.高容错的分布式文件系统的需求日渐增长.Google根据自身的经验打造的这套针对大量廉价客户机的Google GFS文 ...
- VMware下CentOS6.8配置GFS文件系统
1.GFS介绍 GFS简要说明,它有两种: 1. Google文件系统:GFS是GOOGLE实现的是一个可扩展的分布式文件系统,用于大型的.分布式的.对大量数据进行访问的应用.它运行于廉价的普通硬件上 ...
- hadoop学习笔记:hadoop文件系统浅析
1.什么是分布式文件系统? 管理网络中跨多台计算机存储的文件系统称为分布式文件系统. 2.为什么需要分布式文件系统了? 原因很简单,当数据集的大小超过一台独立物理计算机的存储能力时候,就有必要对它进行 ...
- linux概念之分区与文件系统
分区类型 [root@-shiyan dev]# fdisk /dev/sda WARNING: DOS-compatible mode is deprecated. It's strongly re ...
- 大数据时代之hadoop(四):hadoop 分布式文件系统(HDFS)
分布式文件系统即是网络中多台计算机组合在一起提供一个统一存储及管理的系统. Hadoop提供了一个文件系统接口和多个分布式文件系统实现,其中比较重要的就是HDFS(Hadoop Distributed ...
- hadoop文件系统浅析
1.什么是分布式文件系统? 管理网络中跨多台计算机存储的文件系统称为分布式文件系统. 2.为什么需要分布式文件系统了? 原因很简单,当数据集的大小超过一台独立物理计算机的存储能力时候,就有必要对它进行 ...
- google GFS
我们设计并实现了Google GFS文件系统,一个面向大规模数据密集型应用的.可伸缩的分布式文件系统.GFS虽然运行在廉价的普遍硬件设备上,但是它依然了提供灾难冗余的能力,为大量客户机提供了高性能的服 ...
- 阅读GFS的一点总结
这是我第一次阅读学术论文,文章中充斥的一些学术名词给我的阅读带来了一些困难,因为此前没有接触过这方面的内容,在同学的帮助下,查阅了一些资料,终于对GFS有了一点认识,写出这一些感悟,文章措辞不严谨之处 ...
随机推荐
- CGAL 4.6 - Surface Reconstruction from Point Sets
http://doc.cgal.org/latest/Surface_reconstruction_points_3/ The following example reads a point set, ...
- Extjs treePanel 的treestore重复加载问题解决
在Extjs 4.2.2 中构建一个treePanel 发现设置rootVisible后 ,treeStore中设置的autoLoad:false不启作用,在组件初始化的时候即加载数据源,造成数据重复 ...
- SpringMvc获取上下文
import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpSession; import org.spri ...
- Kong Api 初体验
请查看原文: https://www.fangzhipeng.com/nginx/kong/2016/07/11/kong-api-gateway/ Kong是一个可扩展的开源API层(也称为API网 ...
- update、commit、trancate,delete
update 用于更新表的数据,使用方式为: update table_name set column_name=值 条件 顺便一提:date数据插入更新应该使用 to_date()格式转换函数例如: ...
- 零基础Python知识点回顾(三)
元组 元组是用圆括号括起来的,其中的元素之间用逗号隔开.(都是英文半角)tuple(元组)跟列表类似是一种序列类型的数据,特点就是其中的元素不能更改 既然是有序的,那么,嘿嘿,不错,它也可以有索引,能 ...
- Oracle 11g行字段拼接WMSYS.WM_CONCAT问题Not A LOB
Oracle 11g行字段拼接WMSYS.WM_CONCAT问题Not A LOB 一.问题出现 项目中的某个查询需要将表中某个字段不重复地拼接起来,百度得到该函数WMSYS.WM_CONCAT(字段 ...
- iOS:常用属性、方法
前言:一段时间没接触,很容易就忘记以前的知识.专写一篇,供几个月没接触,拿起却忘记了. 0.宏定义.系统相关 0-1).宏定义.规范 变量: //全局变量通常用小写g来提示 int gNumb=0; ...
- 带你解析Java类加载机制
目录 Java类加载机制的七个阶段 加载 验证 准备(重点) 解析 初始化(重点) 使用 卸载 实战分析 方法论 树义有话说 在许多Java面试中,我们经常会看到关于Java类加载机制的考察,例如 ...
- 洛谷P1709 [USACO5.5]隐藏口令Hidden Password(最小表示法)
题目描述 有时候程序员有很奇怪的方法来隐藏他们的口令.Binny会选择一个字符串S(由N个小写字母组成,5<=N<=5,000,000),然后他把S顺时针绕成一个圈,每次取一个做开头字母并 ...