hadoop学习第三天-MapReduce介绍&&WordCount示例&&倒排索引示例
一、MapReduce介绍
(最好以下面的两个示例来理解原理)
1. MapReduce的基本思想
Map-reduce的思想就是“分而治之”
Map Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”执行 “
简单的任务”有几个含义:
1 数据或计算规模相对于原任务要大大缩小;
2 就近计算,即会被分配到存放了所需数据的节点进行计算;
3 这些小任务可以并行计算,彼此间几乎没有依赖关系 一个HDFS block (input split)执行一个Map task.
Map task运行在集群中数据块所存储在的slave节点上(data locality). 提供给Map task 的输入是key-value对.
Shuffle and Sort 排序和整合在Map阶段所有执行完的Map的中间输出数据
Reduce 对map阶段的结果进行汇总 Shuffle and Sort阶段产生的中间数据作为Reduce阶段的输入数据.
Reduce程序(开发者编写)生成最终的输出数据.
2. MapReduce的特点和组成
一个以高可靠,高容错的方式编写程序并行的处理在大的集群上存储的大量的数据的软件框架,这些集群可以由通用的硬件组成 在Hadoop2.0之前, MapReduce是在Hadoop上处理数据的唯一方式.
MapReduce job通常把输入数据切分为独立的数据块(chunk),这些数据块被map task以并行的方式处理. 该框架把maps的输出进行排序,然后把这些输出作为reduce task的输入数据. job的输入和输出数据都是存储在文件系统里.
MapReduce框架主要进行task调度,监听,以及对失败的task重新执行.
3. 基本实现原理(从Job到Reduce)
客户端向JobTracker (JT)提交一个job.
JT确定完成此job需要的资源.
JT检查从节点的状态和待执行的map和reduce的队列 当map可用时,
map task在从节点执行,
JT监视task的执行 当map task执行结束,
Shuffle and Sort在本地为每个mapper生成一个中间结果,以降低每个map的输出数据量.
reduce整合Shuffle and Sort阶段产生的中间结果,用于生成最终的结果. 结果集返回给客户端,并释放资源.
二、WordCount示例分析
当我们刚接触到mapreduce的第一个示例就是WordCount(也就是我们的"Hello World")
1.准备输入数据文件
在集群上新建文件/home/qjx用户目录下
vim ~/words.txt
hello tom
hello jerry
hello kitty
hello world
hello tom
将文件上传至集群
hadoop fs -mkdir /hadoop
hadoop fs -put ~/words.txt /hadoop/words.txt
2.编写WordCount程序代码
2.1 创建MapReduce项目
(需要添加MapReduce插件,启动eclipse,打开窗口 window-->preferences ,配置Hadoop MapReduce的安装路径,如我的路径为E:\Training-packages\hadoop\hadoop-2.6.0,之后即可以创建MapReduce项目,这样就不用每次都导入jar包)
2.2 新建类WCMapper,代码如下:
package com.testMapReduce8_1; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /*
* 继承Mapper类需要定义四个输出、输出类型泛型:
* 四个泛型类型分别代表:
* KeyIn Mapper的输入数据的Key,这里是每行文字的起始位置(0,11,...)
* ValueIn Mapper的输入数据的Value,这里是每行文字
* KeyOut Mapper的输出数据的Key,这里是每行文字中的单词"hello"
* ValueOut Mapper的输出数据的Value,这里是每行文字中的出现的次数
*
* Writable接口是一个实现了序列化协议的序列化对象。
* 在Hadoop中定义一个结构化对象都要实现Writable接口,使得该结构化对象可以序列化为字节流,字节流也可以反序列化为结构化对象。
* LongWritable类型:Hadoop.io对Long类型的封装类型
*/ public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException { // 获得每行文档内容,并且进行折分
String[] words = value.toString().split(" "); // 遍历折份的内容
for (String word : words) {
// 每出现一次则在原来的基础上:+1
context.write(new Text(word), new LongWritable());
}
}
}
2.3 创建WCReducer类,代码如下:
package com.testMapReduce8_1; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /*
* 继承Reducer类需要定义四个输出、输出类型泛型:
* 四个泛型类型分别代表:
* KeyIn Reducer的输入数据的Key,这里是每行文字中的单词"hello"
* ValueIn Reducer的输入数据的Value,这里是每行文字中的次数
* KeyOut Reducer的输出数据的Key,这里是每行文字中的单词"hello"
* ValueOut Reducer的输出数据的Value,这里是每行文字中的出现的总次数
*/ public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ @Override
protected void reduce(Text key, Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { long sum = ;
for (LongWritable i : values) {
// i.get转换成long类型
sum += i.get();
}
// 输出总计结果
context.write(key, new LongWritable(sum));
}
}
2.4 创建运行类WordCount,代码如下:
package com.testMapReduce8_1; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {
// 创建job对象
Job job = Job.getInstance(new Configuration());
// 指定程序的入口
job.setJarByClass(WordCount.class); // 指定自定义的Mapper阶段的任务处理类
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 数据HDFS文件服务器读取数据路径
FileInputFormat.setInputPaths(job, new Path("/hadoop/words.txt")); // 指定自定义的Reducer阶段的任务处理类
job.setReducerClass(WCReducer.class);
// 设置最后输出结果的Key和Value的类型 x
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 将计算的结果上传到HDFS服务
FileOutputFormat.setOutputPath(job, new Path("/hadoop/wordsResult")); // 执行提交job方法,直到完成,参数true打印进度和详情
job.waitForCompletion(true);
System.out.println("Finished");
}
}
3.生成jar包
(1)在自己的包名右击,点击export,输入jar 点击JAR file
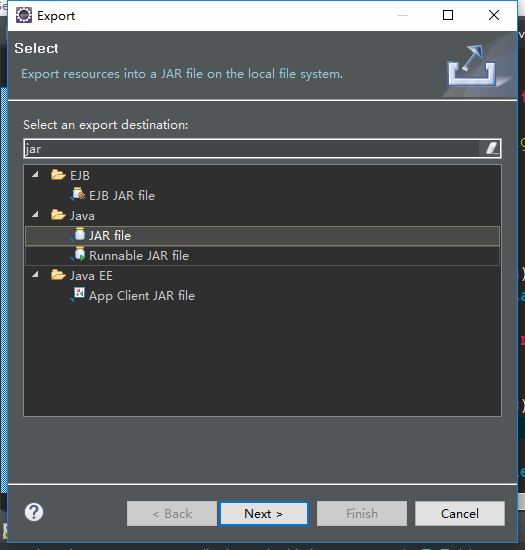
(2)next
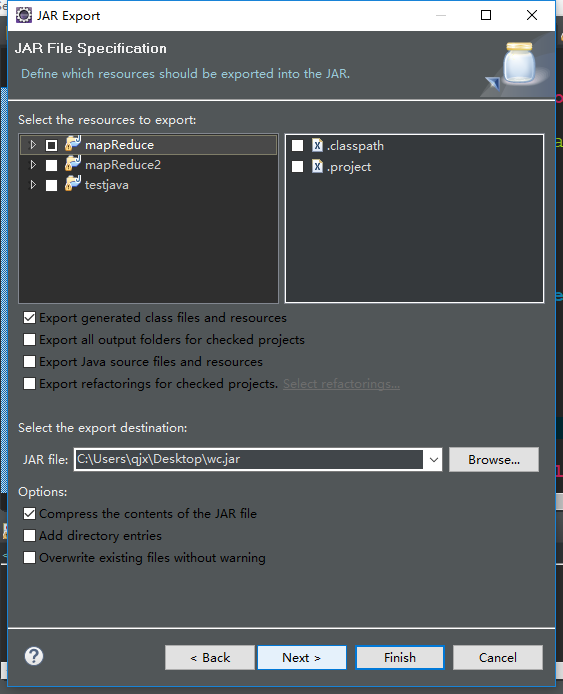
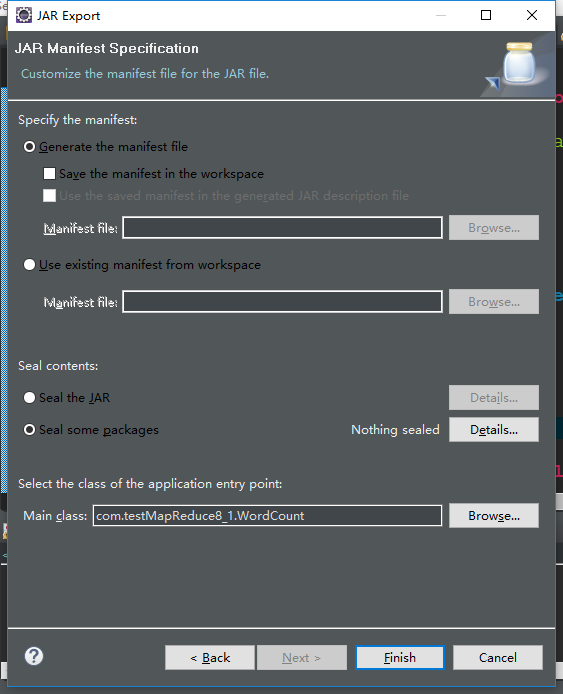
next 点击browers选择要执行的WordCount主函数(这样在linux就可以直接以jar就可以执行到主函数)
4.在linux执行jar运行
4.1 将wc.jar文件上传到自己的linux上/home/qjx目录下(可以通过xftp上传,虚拟机的话也可以通过增强功能直接拖拽,不过不推荐)
4.2 执行hadoop jar命令:
hadoop jar wc.jar
4.3 查看执行结果
hadoop fs -ls /hadoop/wordsResult
hadoop fs -cat /hadoop/wordsResult/part-r-00000
三、倒排索引示例分析
1. 倒排索引概念解释:
正常的索引思想是先将各个文件中的单词列出来,然后进行查找,而单排索引是将查找的关键字以格式(关键字,<文件名,出现次数>)的列表进行查询
我们以两个文件为例进行概念的解释
现在有1.txt,2.txt两个文件,内容分别为
1.txt
hello hadoop
hello java
2.txt
good good study
day day up java
把所有文件中的内容读取,分词结果为:
hello -- <1.txt, 2>
hadoop -- <1.txt, 1>
java -- <1.txt, 1> <2.txt, 1>
good -- <2.txt, 2>
study -- <2.txt, 1>
day -- <2.txt, 2>
up -- <2.txt, 1>
2. MapReduce输入输出分析
我们要得到这样的key-value,而且一个MapReduce只能生成一个<word-filename, sum>的key-value,所以需要两个MapReduce
map1
输入<key, value>
输出<word-filename, 1>
reduce1
输入<word-filename, [1,1,1,1,1]>
输出<word-filename, sum>
map2
输入<key, value>
//将value数据切分为三个值 为 word filename sum
输出<word, filename-sum>
reduce2
输入<word, [filename-sum]>
//将 [filename-sum]连接在一起就得到了输出结果
filename-sum += filename-sum;
输出<word, filename-sum,filename-sum>
3. 编写代码
3.1 编写inverseIndexMap1类,代码如下:
package com.testMapReduce8_1; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class inverseIndexMap1 extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String [] words = value.toString().split(" ");
String fileName = ((FileSplit)context.getInputSplit()).getPath().getName();
for (String word : words) {
if (word !=null && word.length()!=0) {
context.write(new Text(word + "\t" + fileName), new LongWritable(1));
}
}
}
}
3.2 编写inverseIndexReducer类,代码如下:
package com.testMapReduce8_1; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class inverseIndexReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ @Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
long sum = 0;
for (LongWritable value : values) {
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
}
3.3 编写inverseIndexMap2 ,代码如下:
package com.testMapReduce8_1; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class inverseIndexMap2 extends Mapper<LongWritable, Text, Text, Text>{ @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String [] args = value.toString().split("\t");
if (args!=null && args.length==3) {
context.write(new Text(args[0]), new Text(args[1] + "--" + args[2]));
}
}
}
3.4 编写inverseIndexReducer2,代码如下:
package com.testMapReduce8_1; import java.io.IOException; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class inverseIndexReducer2 extends Reducer<Text, Text, Text, Text>{ @Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException { String string = "";
for (Text value : values) {
if (string.length()>0) {
string += ",";
}
string += value;
}
context.write(key, new Text(string));
}
}
3.5 编写运行函数inverseTest,代码如下:
package com.testMapReduce8_1; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class inverseTest { public static void main(String[] args){
//三个命令参数分别为输入路径,map1的输出临时路径,输出路径
String inputPath = args[0];
String tmpPath = args[1];
String outputPath = args[2];
Configuration conf = new Configuration();
try {
Job job = Job.getInstance(conf);
job.setJarByClass(inverseTest.class);
job.setMapperClass(inverseIndexMap1.class);
job.setReducerClass(inverseIndexReducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); FileInputFormat.setInputPaths(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(tmpPath)); job.waitForCompletion(true); Job job2 = Job.getInstance(conf);
//job2.setJarByClass(inverseTest.class);
job2.setMapperClass(inverseIndexMap2.class);
job2.setReducerClass(inverseIndexReducer2.class); job2.setMapOutputKeyClass(Text.class);
job2.setMapOutputValueClass(Text.class); job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job2, new Path(tmpPath));
FileOutputFormat.setOutputPath(job2, new Path(outputPath)); job2.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.6 将三个路径加入到run configuration的输入参数中,分别作为输入路径,临时路径,输出路径,如:
E:\trainingPack\test\input
E:\trainingPack\test\tmp
E:\trainingPack\test\output
3.7准备输入文件
在input文件夹中加入多个文件(英文文档,因为没有做中文分词,只有对“ ”的分词)
3.8 运行
分别在 E:\trainingPack\test\tmp E:\trainingPack\test\output 中产生输出文件,查看文件,若查看part-r-00000文件中格式为 kslf 11.txt--1,14.txt--1 即正确
hadoop学习第三天-MapReduce介绍&&WordCount示例&&倒排索引示例的更多相关文章
- Hadoop学习基础之三:MapReduce
现在是讨论这个问题的不错的时机,因为最近媒体上到处充斥着新的革命所谓“云计算”的信息.这种模式需要利用大量的(低端)处理器并行工作来解决计算问题.实际上,这建议利用大量的低端处理器来构建数据中心,而不 ...
- Hadoop学习之第一个MapReduce程序
期望 通过这个mapreduce程序了解mapreduce程序执行的流程,着重从程序解执行的打印信息中提炼出有用信息. 执行前 程序代码 程序代码基本上是<hadoop权威指南>上原封不动 ...
- Hadoop学习之路(5)Mapreduce程序完成wordcount
程序使用的测试文本数据: Dear River Dear River Bear Spark Car Dear Car Bear Car Dear Car River Car Spark Spark D ...
- 【Hadoop学习之十一】MapReduce案例分析三-PageRank
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 什么是pagerank?算法原理- ...
- Hadoop学习笔记—4.初识MapReduce
一.神马是高大上的MapReduce MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算.对于大数据量的计算,通常采用的处理手法就是并行计算.但对许多开发者来 ...
- Hadoop学习(4)-- MapReduce
MapReduce是一种用于大规模数据集的并行计算编程模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.其主要思想Map(映射)和Reduce(规约)都是从函数是编程语言中借鉴而来的 ...
- Hadoop学习(1)-- 入门介绍
Hadoop是Apache基金会开发的一个分布式系统基础架构,是时下最流行的分布式系统架构之一.用户可以在不了解分布式底层的情况下,在Hadoop上快速进行分布式应用的开发,并利用集群的计算和存储能力 ...
- Hadoop学习总结之三:Map-Reduce入门
1.Map-Reduce的逻辑过程 假设我们需要处理一批有关天气的数据,其格式如下: 按照ASCII码存储,每行一条记录 每一行字符从0开始计数,第15个到第18个字符为年 第25个到第29个字符为温 ...
- Hadoop 6、第一个mapreduce程序 WordCount
1.程序代码 Map: import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.h ...
随机推荐
- Atitit.json类库的设计与实现 ati json lib
Atitit.json类库的设计与实现 ati json lib 1. 目前jsonlib库可能有问题,可能版本冲突,抛出ex1 2. 解决之道:1 2.1. 自定义json解析库,使用多个复合的js ...
- 影子寄存器(shadow register)
1.以下仅供参考:有阴影的寄存器,表示在物理上这个寄存器对应2个寄存器,一个是程序员可以写入或读出的寄存器,称为preload register(预装载寄存器),另一个是程序员看不见的.但在操作中真正 ...
- C#微信公众号学习 - (一)测试账号申请
主要分为两部分: 1.创建C#的项目,并发布, 2.微信填写发布的地址进行开发者验证. 一. VS环境为VS2017,创建项目时,自带的一些东西发布会导致各种错误,无奈,创建了空项目aspx窗体,如下 ...
- Scrapy系列教程(3)------Spider(爬虫核心,定义链接关系和网页信息抽取)
Spiders Spider类定义了怎样爬取某个(或某些)站点.包含了爬取的动作(比如:是否跟进链接)以及怎样从网页的内容中提取结构化数据(爬取item). 换句话说.Spider就是您定义爬取的动作 ...
- Windows Mobile X图标如何销毁窗体而非隐藏
在Windows Mobile窗体上,有“OK”和“X”两种形式按钮.1.在Form的属性里,设置“MinimizeBox=false”,则窗体显示”OK”,点击该按钮窗体销毁并退出.2.设置“Min ...
- 如何给unity3d工程加入依赖的android工程
最近在忙着接平台的事,需要接入各种各样的android平台sdk来发布.在接sdk的时候遇到了这样的一个情况,有点麻烦,所以纪录一下. 有些sdk的接入是提供jar包,这样的可以简单地将jar包制作成 ...
- 放苹果(整数划分变形题 水)poj1664
问题:把M个相同的苹果放在N个相同的盘子里.同意有的盘子空着不放,问共同拥有多少种不同的分法?(用K表示)5,1,1和1,5,1 是同一种分法. 例子 : 1 7 3 ---------------8 ...
- FFmpeg总结(六)AV系列结构体之AVPacket
AVPacket位置:libavcodec/avcodec.h下: watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvaGVqanVubGlu/font/5a6 ...
- sql server 2008 对字段的操作
添加,刪除字段 通用式: alter table [表名] add [字段名] 字段属性 default 缺省值 default 是可选参数 增加字段: 增加数字字段,整型,缺省值为0 增加数字 ...
- Linux 进程间通信(一)(经典IPC:消息队列、信号量、共享存储)
有3种称作XSI IPC的IPC:消息队列.信号量.共享存储.这种类型的IPC有如下共同的特性. 每个内核中的IPC都用一个非负整数标志.标识符是IPC对象的内部名称,为了使多个合作进程能够在同一IP ...