《深入浅出 Java Concurrency》—并发容器 ConcurrentMap
(转自:http://blog.csdn.net/fg2006/article/details/6404226)
在JDK 1.4以下只有Vector和Hashtable是线程安全的集合(也称并发容器,Collections.synchronized*系列也可以看作是线程安全的实现)。从JDK 5开始增加了线程安全的Map接口ConcurrentMap和线程安全的队列BlockingQueue(尽管Queue也是同时期引入的新的集合,但是规范并没有规定一定是线程安全的,事实上一些实现也不是线程安全的,比如PriorityQueue、ArrayDeque、LinkedList等,在Queue章节中会具体讨论这些队列的结构图和实现)。
在介绍ConcurrencyMap之前先来回顾下Map的体系结构。下图描述了Map的体系结构,其中蓝色字体的是JDK 5以后新增的并发容器。
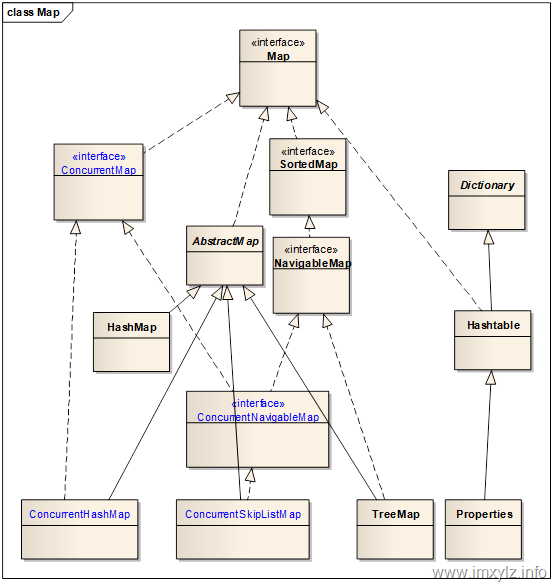
针对上图有以下几点说明:
- Hashtable是JDK 5之前Map唯一线程安全的内置实现(Collections.synchronizedMap不算)。特别说明的是Hashtable的t是小写的(不知道为啥),Hashtable继承的是Dictionary(Hashtable是其唯一公开的子类),并不继承AbstractMap或者HashMap。尽管Hashtable和HashMap的结构非常类似,但是他们之间并没有多大联系。
- ConcurrentHashMap是HashMap的线程安全版本,ConcurrentSkipListMap是TreeMap的线程安全版本。
- 最终可用的线程安全版本Map实现是ConcurrentHashMap/ConcurrentSkipListMap/Hashtable/Properties四个,但是Hashtable是过时的类库,因此如果可以的应该尽可能的使用ConcurrentHashMap和ConcurrentSkipListMap。
回到正题来,这个小节主要介绍ConcurrentHashMap的API以及应用,下一节才开始将原理和分析。

除了实现Map接口里面对象的方法外,ConcurrentHashMap还实现了ConcurrentMap里面的四个方法。
V putIfAbsent(K key,V value)
如果不存在key对应的值,则将value以key加入Map,否则返回key对应的旧值。这个等价于清单1 的操作:
清单1 putIfAbsent的等价操作
if (!map.containsKey(key))
return map.put(key, value);
else
return map.get(key);
在前面的章节中提到过,连续两个或多个原子操作的序列并不一定是原子操作。比如上面的操作即使在Hashtable中也不是原子操作。而putIfAbsent就是一个线程安全版本的操作的。
有些人喜欢用这种功能来实现单例模式,例如清单2。
清单2 一种单例模式的实现
package xylz.study.concurrency;
import Java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;public class ConcurrentDemo1 {
private static final ConcurrentMap<String, ConcurrentDemo1> map = new ConcurrentHashMap<String, ConcurrentDemo1>();
private static ConcurrentDemo1 instance;
public static ConcurrentDemo1 getInstance() {
if (instance == null) {map.putIfAbsent("INSTANCE", new ConcurrentDemo1());
instance = map.get("INSTANCE");
}
return instance;
}private ConcurrentDemo1() {
}}
当然这里只是一个操作的例子,实际上在单例模式文章中有很多的实现和比较。清单2 在存在大量单例的情况下可能有用,实际情况下很少用于单例模式。但是这个方法避免了向Map中的同一个Key提交多个结果的可能,有时候在去掉重复记录上很有用(如果记录的格式比较固定的话)。
boolean remove(Object key,Object value)
只有目前将键的条目映射到给定值时,才移除该键的条目。这等价于清单3 的操作。
清单3 remove(Object,Object)的等价操作
if (map.containsKey(key) && map.get(key).equals(value)) {
map.remove(key);
return true;
}
return false;
由于集合类通常比较的hashCode和equals方法,而这两个方法是在Object对象里面,因此两个对象如果hashCode一致,并且覆盖了equals方法后也一致,那么这两个对象在集合类里面就是“相同”的,不管是否是同一个对象或者同一类型的对象。也就是说只要key1.hashCode()==key2.hashCode() && key1.equals(key2),那么key1和key2在集合类里面就认为是一致,哪怕他们的Class类型不一致也没关系,所以在很多集合类里面允许通过Object来类型来比较(或者定位)。比如说Map尽管添加的时候只能通过制定的类型<K,V>,但是删除的时候却允许通过一个Object来操作,而不必是K类型。
既然Map里面有一个remove(Object)方法,为什么ConcurrentMap还需要remove(Object,Object)方法呢?这是因为尽管Map里面的key没有变化,但是value可能已经被其他线程修改了,如果修改后的值是我们期望的,那么我们就不能拿一个key来删除此值,尽管我们的期望值是删除此key对于的旧值。
这种特性在原子操作章节的AtomicMarkableReference和AtomicStampedReference里面介绍过。
boolean replace(K key,V oldValue,V newValue)
只有目前将键的条目映射到给定值时,才替换该键的条目。这等价于清单4 的操作。
清单4 replace(K,V,V)的等价操作
if (map.containsKey(key) && map.get(key).equals(oldValue)) {
map.put(key, newValue);
return true;
}
return false;
V replace(K key,V value)
只有当前键存在的时候更新此键对于的值。这等价于清单5 的操作。
清单5 replace(K,V)的等价操作
if (map.containsKey(key)) {
return map.put(key, value);
}
return null;
replace(K,V,V)相比replace(K,V)而言,就是增加了匹配oldValue的操作。
其实这4个扩展方法,是ConcurrentMap附送的四个操作,其实我们更关心的是Map本身的操作。当然如果没有这4个方法,要完成类似的功能我们可能需要额外的锁,所以有总比没有要好。比如清单6,如果没有putIfAbsent内置的方法,我们如果要完成此操作就需要完全锁住整个Map,这样就大大降低了ConcurrentMap的并发性。这在下一节中有详细的分析和讨论。
清单6 putIfAbsent的外部实现
public V putIfAbsent(K key, V value) {
synchronized (map) {
if (!map.containsKey(key)) return map.put(key, value);
return map.get(key);
}
}part2
本来想比较全面和深入的谈谈ConcurrentHashMap的,发现网上有很多对HashMap和ConcurrentHashMap分析的文章,因此本小节尽可能的分析其中的细节,少一点理论的东西,多谈谈内部设计的原理和思想。
要谈ConcurrentHashMap的构造,就不得不谈HashMap的构造,因此先从HashMap开始简单介绍。
HashMap原理
我们从头开始设想。要将对象存放在一起,如何设计这个容器。目前只有两条路可以走,一种是采用分格技术,每一个对象存放于一个格子中,这样通过对格子的编号就能取到或者遍历对象;另一种技术就是采用串联的方式,将各个对象串联起来,这需要各个对象至少带有下一个对象的索引(或者指针)。显然第一种就是数组的概念,第二种就是链表的概念。所有的容器的实现其实都是基于这两种方式的,不管是数组还是链表,或者二者俱有。HashMap采用的就是数组的方式。
有了存取对象的容器后还需要以下两个条件才能完成Map所需要的条件。
- 能够快速定位元素:Map的需求就是能够根据一个查询条件快速得到需要的结果,所以这个过程需要的就是尽可能的快。
- 能够自动扩充容量:显然对于容器而然,不需要人工的去控制容器的容量是最好的,这样对于外部使用者来说越少知道底部细节越好,不仅使用方便,也越安全。
首先条件1,快速定位元素。快速定位元素属于算法和数据结构的范畴,通常情况下哈希(Hash)算法是一种简单可行的算法。所谓哈希算法,是将任意长度的二进制值映射为固定长度的较小二进制值。常见的MD2,MD4,MD5,SHA-1等都属于Hash算法的范畴。具体的算法原理和介绍可以参考相应的算法和数据结构的书籍,但是这里特别提醒一句,由于将一个较大的集合映射到一个较小的集合上,所以必然就存在多个元素映射到同一个元素上的结果,这个叫“碰撞”,后面会用到此知识,暂且不表。
条件2,如果满足了条件1,一个元素映射到了某个位置,现在一旦扩充了容量,也就意味着元素映射的位置需要变化。因为对于Hash算法来说,调整了映射的小集合,那么原来映射的路径肯定就不复存在,那么就需要对现有重新计算映射路径,也就是所谓的rehash过程。
好了有了上面的理论知识后来看HashMap是如何实现的。
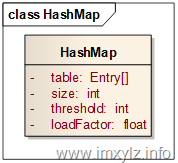
在HashMap中首先由一个对象数组table是不可避免的,修饰符transient只是表示序列号的时候不被存储而已。size描述的是Map中元素的大小,threshold描述的是达到指定元素个数后需要扩容,loadFactor是扩容因子(loadFactor>0),也就是计算threshold的。那么元素的容量就是table.length,也就是数组的大小。换句话说,如果存取的元素大小达到了整个容量(table.length)的loadFactor倍(也就是table.length*loadFactor个),那么就需要扩充容量了。在HashMap中每次扩容就是将扩大数组的一倍,使数组大小为原来的两倍。
然后接下来看如何将一个元素映射到数组table中。显然要映射的key是一个无尽的超大集合,而table是一个较小的有限集合,那么一种方式就是将key编码后的hashCode值取模映射到table上,这样看起来不错。但是在Java中采用了一种更高效的办法。由于与(&)是比取模(%)更高效的操作,因此Java中采用hash值与数组大小-1后取与来确定数组索引的。为什么这样做是更有效的?参考资料7对这一块进行非常详细的分析,这篇文章的作者非常认真,也非常仔细的分析了里面包含的思想。
清单1 indexFor片段
static int indexFor(int h, int length) {
return h & (length-1);
}前面说明,既然是大集合映射到小集合上,那么就必然存在“碰撞”,也就是不同的key映射到了相同的元素上。那么HashMap是怎么解决这个问题的?
在HashMap中采用了下面方式,解决了此问题。
- 同一个索引的数组元素组成一个链表,查找允许时循环链表找到需要的元素。
- 尽可能的将元素均匀的分布在数组上。
对于问题1,HashMap采用了上图的一种数据结构。table中每一个元素是一个Map.Entry,其中Entry包含了四个数据,key,value,hash,next。key和value是存储的数据;hash是元素key的Hash后的表现形式(最终要映射到数组上),这里链表上所有元素的hash经过清单1 的indexFor后将得到相同的数组索引;next是指向下一个元素的索引,同一个链表上的元素就是通过next串联起来的。
再来看问题2 尽可能的将元素均匀的分布在数组上这个问题是怎么解决的。首先清单2 是将key的hashCode经过一系列的变换,使之更符合小数据集合的散列模型。
清单2 hashCode的二次散列
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}至于清单2 为什么这样散列我没有找到依据,也没有什么好的参考资料。参考资料1 分析了此过程,认为是一种比较有效的方式,有兴趣的可以研究下。
第二点就是在清单1 的描述中,尽可能的与数组的长度减1的数与操作,使之分布均匀。这在参考资料7 中有介绍。
第三点就是构造数组时数组的长度是2的倍数。清单3 反映了这个过程。为什么要是2的倍数?在参考资料7 中分析说是使元素尽可能的分布均匀。
清单3 HashMap 构造数组
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];另外loadFactor的默认值0.75和capacity的默认值16是经过大量的统计分析得出的,很久以前我见过相关的数据分析,现在找不到了,有兴趣的可以查询相关资料。这里不再叙述了。
有了上述原理后再来分析HashMap的各种方法就不是什么问题的。
清单4 HashMap的get操作
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}清单4 描述的是HashMap的get操作,在这个操作中首先判断key是否为空,因为为空的话总是映射到table的第0个元素上(可以看上面的清单2和清单1)。然后就需要查找table的索引。一旦找到对应的Map.Entry元素后就开始遍历此链表。由于不同的hash可能映射到同一个table[index]上,而相同的key却同时映射到相同的hash上,所以一个key和Entry对应的条件就是hash(key)==e.hash 并且key.equals(e.key)。从这里我们看到,Object.hashCode()只是为了将相同的元素映射到相同的链表上(Map.Entry),而Object.equals()才是比较两个元素是否相同的关键!这就是为什么总是成对覆盖hashCode()和equals()的原因。
清单5 HashMap的put操作
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}清单5 描述的是HashMap的put操作。对比get操作,可以发现,put实际上是先查找,一旦找到key对应的Entry就直接修改Entry的value值,否则就增加一个元素。增加的元素是在链表的头部,也就是占据table中的元素,如果table中对应索引原来有元素的话就将整个链表添加到新增加的元素的后面。也就是说新增加的元素再次查找的话是优于在它之前添加的同一个链表上的元素。这里涉及到就是扩容,也就是一旦元素的个数达到了扩容因子规定的数量(threhold=table.length*loadFactor),就将数组扩大一倍。
清单6 HashMap扩容过程
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}清单6 描述的是HashMap扩容的过程。可以看到扩充过程会导致元素数据的所有元素进行重新hash计算,这个过程也叫rehash。显然这是一个非常耗时的过程,否则扩容都会导致所有元素重新计算hash。因此尽可能的选择合适的初始化大小是有效提高HashMap效率的关键。太大了会导致过多的浪费空间,太小了就可能会导致繁重的rehash过程。在这个过程中loadFactor也可以考虑。
举个例子来说,如果要存储1000个元素,采用默认扩容因子0.75,那么1024显然是不够的,因为1000>0.75*1024了,所以选择2048是必须的,显然浪费了1048个空间。如果确定最多只有1000个元素,那么扩容因子为1,那么1024是不错的选择。另外需要强调的一点是扩容因此越大,从统计学角度讲意味着链表的长度就也大,也就是在查找元素的时候就需要更多次的循环。所以凡事必然是一个平衡的过程。
这里可能有人要问题,一旦我将Map的容量扩大后(也就是数组的大小),这个容量还能减小么?比如说刚开始Map中可能有10000个元素,运行一旦时间以后Map的大小永远不会超过10个,那么Map的容量能减小到10个或者16个么?答案就是不能,这个capacity一旦扩大后就不能减小了,只能通过构造一个新的Map来控制capacity了。
HashMap的几个内部迭代器也是非常重要的,这里限于篇幅就不再展开了,有兴趣的可以自己研究下。
Hashtable的原理和HashMap的原理几乎一样,所以就不讨论了。另外LinkedHashMap是在Map.Entry的基础上增加了before/after两个双向索引,用来将所有Map.Entry串联起来,这样就可以遍历或者做LRU Cache等。这里也不再展开讨论了。
memcached 内部数据结构就是采用了HashMap类似的思想来实现的,有兴趣的可以参考资料8,9,10。
为了不使这篇文章过长,因此将ConcurrentHashMap的原理放到下篇讲。需要说明的是,尽管ConcurrentHashMap与HashMap的名称有些渊源,而且实现原理有些相似,但是为了更好的支持并发,ConcurrentHashMap在内部也有一些比较大的调整,这个在下篇会具体介绍。
参考资料:
- HashMap hash方法分析
- 通过分析 JDK 源代码研究 Hash 存储机制
- Java 理论与实践: 哈希
- Java 理论与实践: 构建一个更好的 HashMap
- jdk1.6 ConcurrentHashMap
- ConcurrentHashMap之实现细节
- 深入理解HashMap
- memcached-数据结构
- memcached存储管理 数据结构
- memcached
part3
ConcurrentHashMap原理
在读写锁章节部分介绍过一种是用读写锁实现Map的方法。此种方法看起来可以实现Map响应的功能,而且吞吐量也应该不错。但是通过前面对读写锁原理的分析后知道,读写锁的适合场景是读操作>>写操作,也就是读操作应该占据大部分操作,另外读写锁存在一个很严重的问题是读写操作不能同时发生。要想解决读写同时进行问题(至少不同元素的读写分离),那么就只能将锁拆分,不同的元素拥有不同的锁,这种技术就是“锁分离”技术。
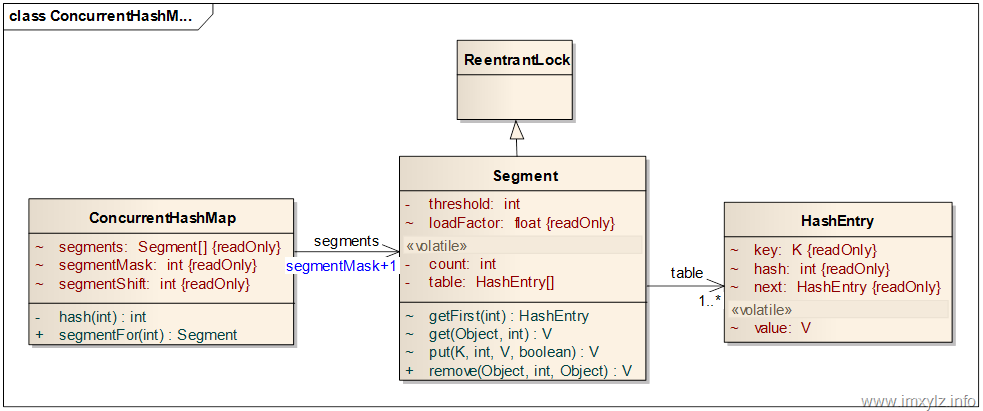
默认情况下ConcurrentHashMap是用了16个类似HashMap 的结构,其中每一个HashMap拥有一个独占锁。也就是说最终的效果就是通过某种Hash算法,将任何一个元素均匀的映射到某个HashMap的Map.Entry上面,而对某个一个元素的操作就集中在其分布的HashMap上,与其它HashMap无关。这样就支持最多16个并发的写操作。
上图就是ConcurrentHashMap的类图。参考上面的说明和HashMap的原理分析,可以看到ConcurrentHashMap将整个对象列表分为segmentMask+1个片段(Segment)。其中每一个片段是一个类似于HashMap的结构,它有一个HashEntry的数组,数组的每一项又是一个链表,通过HashEntry的next引用串联起来。
这个类图上面的数据结构的定义非常有学问,接下来会一个个有针对性的分析。
首先如何从ConcurrentHashMap定位到HashEntry。在HashMap的原理分析部分说过,对于一个Hash的数据结构来说,为了减少浪费的空间和快速定位数据,那么就需要数据在Hash上的分布比较均匀。对于一次Map的查找来说,首先就需要定位到Segment,然后从过Segment定位到HashEntry链表,最后才是通过遍历链表得到需要的元素。
在不讨论并发的前提下先来讨论如何定位到HashEntry的。在ConcurrentHashMap中是通过hash(key.hashCode())和segmentFor(hash)来得到Segment的。清单1 描述了如何定位Segment的过程。其中hash(int)是将key的hashCode进行二次编码,使之能够在segmentMask+1个Segment上均匀分布(默认是16个)。可以看到的是这里和HashMap还是有点不同的,这里采用的算法叫Wang/Jenkins hash,有兴趣的可以参考资料1和参考资料2。总之它的目的就是使元素能够均匀的分布在不同的Segment上,这样才能够支持最多segmentMask+1个并发,这里segmentMask+1是segments的大小。
清单1 定位Segment
private static int hash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}显然在不能够对Segment扩容的情况下,segments的大小就应该是固定的。所以在ConcurrentHashMap中segments/segmentMask/segmentShift都是常量,一旦初始化后就不能被再次修改,其中segmentShift是查找Segment的一个常量偏移量。
有了Segment以后再定位HashEntry就和HashMap中定位HashEntry一样了,先将hash值与Segment中HashEntry的大小减1进行与操作定位到HashEntry链表,然后遍历链表就可以完成相应的操作了。
能够定位元素以后ConcurrentHashMap就已经具有了HashMap的功能了,现在要解决的就是如何并发的问题。要解决并发问题,加锁是必不可免的。再回头看Segment的类图,可以看到Segment除了有一个volatile类型的元素大小count外,Segment还是集成自ReentrantLock的。另外在前面的原子操作和锁机制中介绍过,要想最大限度的支持并发,那么能够利用的思路就是尽量读操作不加锁,写操作不加锁。如果是读操作不加锁,写操作加锁,对于竞争资源来说就需要定义为volatile类型的。volatile类型能够保证happens-before法则,所以volatile能够近似保证正确性的情况下最大程度的降低加锁带来的影响,同时还与写操作的锁不产生冲突。
同时为了防止在遍历HashEntry的时候被破坏,那么对于HashEntry的数据结构来说,除了value之外其他属性就应该是常量,否则不可避免的会得到ConcurrentModificationException。这就是为什么HashEntry数据结构中key,hash,next是常量的原因(final类型)。
有了上面的分析和条件后再来看Segment的get/put/remove就容易多了。
get操作
清单2 Segment定位元素
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
return tab[hash & (tab.length - 1)];
}V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}清单2 描述的是Segment如何定位元素。首先判断Segment的大小count>0,Segment的大小描述的是HashEntry不为空(key不为空)的个数。如果Segment中存在元素那么就通过getFirst定位到指定的HashEntry链表的头节点上,然后遍历此节点,一旦找到key对应的元素后就返回其对应的值。但是在清单2 中可以看到拿到HashEntry的value后还进行了一次判断操作,如果为空还需要加锁再读取一次(readValueUnderLock)。为什么会有这样的操作?尽管ConcurrentHashMap不允许将value为null的值加入,但现在仍然能够读到一个为空的value就意味着此值对当前线程还不可见(这是因为HashEntry还没有完全构造完成就赋值导致的,后面还会谈到此机制)。
put操作
清单3 描述的是Segment的put操作。首先就需要加锁了,修改一个竞争资源肯定是要加锁的,这个毫无疑问。需要说明的是Segment集成的是ReentrantLock,所以这里加的锁也就是独占锁,也就是说同一个Segment在同一时刻只有能一个put操作。
接下来来就是检查是否需要扩容,这和HashMap一样,如果需要的话就扩大一倍,同时进行rehash操作。
查找元素就和get操作是一样的,得到元素就直接修改其值就好了。这里onlyIfAbsent只是为了实现ConcurrentMap的putIfAbsent操作而已。需要说明以下几点:
- 如果找到key对于的HashEntry后直接修改就好了,如果找不到那么就需要构造一个新的HashEntry出来加到hash对于的HashEntry的头部,同时就的头部就加到新的头部后面。这是因为HashEntry的next是final类型的,所以只能修改头节点才能加元素加入链表中。
- 如果增加了新的操作后,就需要将count+1写回去。前面说过count是volatile类型,而读取操作没有加锁,所以只能把元素真正写回Segment中的时候才能修改count值,这个要放到整个操作的最后。
- 在将新的HashEntry写入table中时是通过构造函数来设置value值的,这意味对table的赋值可能在设置value之前,也就是说得到了一个半构造完的HashEntry。这就是重排序可能引起的问题。所以在读取操作中,一旦读到了一个value为空的value是就需要加锁重新读取一次。为什么要加锁?加锁意味着前一个写操作的锁释放,也就是前一个锁的数据已经完成写完了了,根据happens-before法则,前一个写操作的结果对当前读线程就可见了。当然在JDK 6.0以后不一定存在此问题。
- 在Segment中table变量是volatile类型,多次读取volatile类型的开销要不非volatile开销要大,而且编译器也无法优化,所以在put操作中首先建立一个临时变量tab指向table,多次读写tab的效率要比volatile类型的table要高,JVM也能够对此进行优化。
清单3 Segment的put操作
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}remove 操作
清单4 描述了Segment删除一个元素的过程。同put一样,remove也需要加锁,这是因为对table可能会有变更。由于HashEntry的next节点是final类型的,所以一旦删除链表中间一个元素,就需要将删除之前或者之后的元素重新加入新的链表。而Segment采用的是将删除元素之前的元素一个个重新加入删除之后的元素之前(也就是链表头结点)来完成新链表的构造。
清单4 Segment的remove操作
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
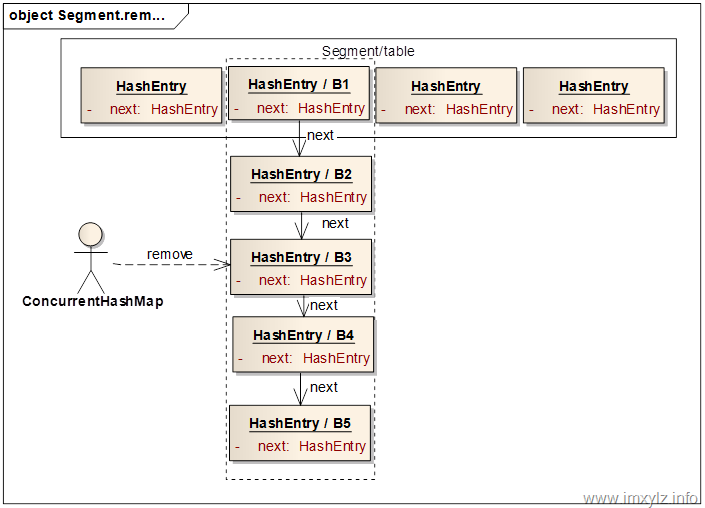
}下面的示意图描述了如何删除一个已经存在的元素的。假设我们要删除B3元素。首先定位到B3所在的Segment,然后再定位到Segment的table中的B1元素,也就是Bx所在的链表。然后遍历链表找到B3,找到之后就从头结点B1开始构建新的节点B1(蓝色)加到B4的前面,继续B1后面的节点B2构造B2(蓝色),加到由蓝色的B1和B4构成的新的链表。继续下去,直到遇到B3后终止,这样就构造出来一个新的链表B2(蓝色)->B1(蓝色)->B4->B5,然后将此链表的头结点B2(蓝色)设置到Segment的table中。这样就完成了元素B3的删除操作。需要说明的是,尽管就的链表仍然存在(B1->B2->B3->B4->B5),但是由于没有引用指向此链表,所以此链表中无引用的(B1->B2->B3)最终会被GC回收掉。这样做的一个好处是,如果某个读操作在删除时已经定位到了旧的链表上,那么此操作仍然将能读到数据,只不过读取到的是旧数据而已,这在多线程里面是没有问题的。
除了对单个元素操作外,还有对全部的Segment的操作,比如size()操作等。
size操作
size操作涉及到统计所有Segment的大小,这样就会遍历所有的Segment,如果每次加锁就会导致整个Map都被锁住了,任何需要锁的操作都将无法进行。这里用到了一个比较巧妙的方案解决此问题。
在Segment中有一个变量modCount,用来记录Segment结构变更的次数,结构变更包括增加元素和删除元素,每增加一个元素操作就+1,每进行一次删除操作+1,每进行一次清空操作(clear)就+1。也就是说每次涉及到元素个数变更的操作modCount都会+1,而且一直是增大的,不会减小。
遍历两次ConcurrentHashMap中的segments,每次遍历是记录每一个Segment的modCount,比较两次遍历的modCount值的和是否相同,如果相同就返回在遍历过程中获取的Segment的count的和,也就是所有元素的个数。如果不相同就重复再做一次。重复一次还不相同就将所有Segment锁住,一个一个的获取其大小(count),最后将这些count加起来得到总的大小。当然了最后需要将锁一一释放。清单5 描述了这个过程。
这里有一个比较高级的话题是为什么在读取modCount的时候总是先要读取count一下。为什么不是先读取modCount然后再读取count的呢?也就是说下面的两条语句能否交换下顺序?
sum += segments[i].count;
mcsum += mc[i] = segments[i].modCount;
答案是不能!为什么?这是因为modCount总是在加锁的情况下才发生变化,所以不会发生多线程同时修改的情况,也就是没必要时volatile类型。另外总是在count修改的情况下修改modCount,而count是一个volatile变量。于是这里就充分利用了volatile的特性。
根据happens-before法则,第(3)条:对volatile字段的写入操作happens-before于每一个后续的同一个字段的读操作。也就是说一个操作C在volatile字段的写操作之后,那么volatile写操作之前的所有操作都对此操作C可见。所以修改modCount总是在修改count之前,也就是说如果读取到了一个count的值,那么在count变化之前的modCount也就能够读取到,换句话说就是如果看到了count值的变化,那么就一定看到了modCount值的变化。而如果上面两条语句交换下顺序就无法保证这个结果一定存在了。
在ConcurrentHashMap.containsValue中,可以看到每次遍历segments时都会执行int c = segments[i].count;,但是接下来的语句中又不用此变量c,尽管如此JVM仍然不能将此语句优化掉,因为这是一个volatile字段的读取操作,它保证了一些列操作的happens-before顺序,所以是至关重要的。在这里可以看到:
ConcurrentHashMap将volatile发挥到了极致!
另外isEmpty操作于size操作类似,不再累述。
清单5 ConcurrentHashMap的size操作
public int size() {
final Segment<K,V>[] segments = this.segments;
long sum = 0;
long check = 0;
int[] mc = new int[segments.length];
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
check = 0;
sum = 0;
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {
sum += segments[i].count;
mcsum += mc[i] = segments[i].modCount;
}
if (mcsum != 0) {
for (int i = 0; i < segments.length; ++i) {
check += segments[i].count;
if (mc[i] != segments[i].modCount) {
check = -1; // force retry
break;
}
}
}
if (check == sum)
break;
}
if (check != sum) { // Resort to locking all segments
sum = 0;
for (int i = 0; i < segments.length; ++i)
segments[i].lock();
for (int i = 0; i < segments.length; ++i)
sum += segments[i].count;
for (int i = 0; i < segments.length; ++i)
segments[i].unlock();
}
if (sum > Integer.MAX_VALUE)
return Integer.MAX_VALUE;
else
return (int)sum;
}ConcurrentSkipListMap/Set
本来打算介绍下ConcurrentSkipListMap的,结果打开源码一看,彻底放弃了。那里面的数据结构和算法我估计研究一周也未必能够完全弄懂。很久以前我看TreeMap的时候就头大,想想那些复杂的“红黑二叉树”我头都大了。这些都归咎于从前没有好好学习《数据结构和算法》,现在再回头看这些复杂的算法感觉非常头疼,为了减少脑细胞的死亡,暂且还是不要惹这些“玩意儿”。有兴趣的可以看看参考资料4 中对TreeMap的介绍。
参考资料:

《深入浅出 Java Concurrency》—并发容器 ConcurrentMap的更多相关文章
- Java多线程-并发容器
Java多线程-并发容器 在Java1.5之后,通过几个并发容器类来改进同步容器类,同步容器类是通过将容器的状态串行访问,从而实现它们的线程安全的,这样做会消弱了并发性,当多个线程并发的竞争容器锁的时 ...
- 深入浅出 Java Concurrency (16): 并发容器 part 1 ConcurrentMap (1)[转]
从这一节开始正式进入并发容器的部分,来看看JDK 6带来了哪些并发容器. 在JDK 1.4以下只有Vector和Hashtable是线程安全的集合(也称并发容器,Collections.synchro ...
- 深入浅出 Java Concurrency (27): 并发容器 part 12 线程安全的List/Set[转]
本小节是<并发容器>的最后一部分,这一个小节描述的是针对List/Set接口的一个线程版本. 在<并发队列与Queue简介>中介绍了并发容器的一个概括,主要描述的是Queue的 ...
- 深入浅出 Java Concurrency (21): 并发容器 part 6 可阻塞的BlockingQueue (1)[转]
在<并发容器 part 4 并发队列与Queue简介>节中的类图中可以看到,对于Queue来说,BlockingQueue是主要的线程安全版本.这是一个可阻塞的版本,也就是允许添加/删除元 ...
- [转] 多线程 《深入浅出 Java Concurrency》目录
http://ifeve.com/java-concurrency-thread-directory/ synchronized使用的内置锁和ReentrantLock这种显式锁在java6以后性能没 ...
- 《深入浅出 Java Concurrency》目录
最近在学习J.U.C,看到一个大神 关于这个系列写的非常精辟,由于想做笔记,故系列转载并记录之. 原文:http://www.blogjava.net/xylz/archive/2010/07/08/ ...
- 深入浅出 Java Concurrency (35): 线程池 part 8 线程池的实现及原理 (3)[转]
线程池任务执行结果 这一节来探讨下线程池中任务执行的结果以及如何阻塞线程.取消任务等等. 1 package info.imxylz.study.concurrency.future;2 3 publ ...
- 深入浅出 Java Concurrency - 目录 [转]
这是一份完整的Java 并发整理笔记,记录了我最近几年学习Java并发的一些心得和体会. J.U.C 整体认识 原子操作 part 1 从AtomicInteger开始 原子操作 part 2 数组. ...
- 深入浅出 Java Concurrency (4): 原子操作 part 3 指令重排序与happens-before法则
转: http://www.blogjava.net/xylz/archive/2010/07/03/325168.html 在这个小结里面重点讨论原子操作的原理和设计思想. 由于在下一个章节中会谈到 ...
随机推荐
- CentOS上安装oracle11g报错处理
最近,在处理oracle gateway的报错问题.只因个人的测试环境已经迁移到docker上了,又懒得装一套环境就直接在机器上安装oracle11g.今天分享的故事就从此开始-- 运行环境 项目 ...
- thinkphp5 分页带参数的解决办法
文档有说可以在paginate带参数,然后研究了下,大概就是这样的: $list=Db::name('member') ->where('member_name|member_mobile|se ...
- vue服务端渲染添加缓存
缓存 虽然 Vue 的服务器端渲染(SSR)相当快速,但是由于创建组件实例和虚拟 DOM 节点的开销,无法与纯基于字符串拼接(pure string-based)的模板的性能相当.在 SSR 性能至关 ...
- web前端总结面试问题<经常遇到的手写代码>
冒泡排序 var arr = [5,8,3,6,9] for(var i=0;i<arr.length;i++){ for(var j=i+1;j<arr.length;j++){ if( ...
- 使用deque保留有限的记录
# 使用deque保留有限的记录 >>> from collections import deque >>> q = deque(maxlen=3) # 指定队列的 ...
- 什么是mysql数据库安全 简单又通俗的mysql库安全简介
首先我们要了解一下什么是mysql数据库,mysql是目前网站以及APP应用上用的较多的一个开源的关系型数据库系统,可以对数据进行保存,分段化的数据保存,也可以对其数据进行检索,查询等功能的数据库. ...
- CentOS搭建Sqoop环境
Sqoop是一个用来将Hadoop(Hive.HBase)和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如:MySQL ,Oracle ,Postgres等)中的 ...
- 3124: [Sdoi2013]直径
3124: [Sdoi2013]直径 https://www.lydsy.com/JudgeOnline/problem.php?id=3124 分析: 所有直径都经过的边,一定都是连续的一段.(画个 ...
- android中的文件(图片)上传
android中的文件(图片)上传其实没什么复杂的,主要是对 multipart/form-data 协议要有所了解. 关于 multipart/form-data 协议,在 RFC文档中有详细的描述 ...
- css匹配规则及性能
一.CSS是如何匹配样式的 样式系统从最右边的选择符开始向左进行匹配规则.只要当前选择符的左边还有其他选择符,样式系统就会继续向左移动,直到找到和规则匹配的元素,或者因为不匹配而退出. 二.CSS选择 ...