Python之路第十二天,高级(4)-Python操作rabbitMQ
rabbitMQ
RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
RabbitMQ安装
CentOS:
1.安装epel源,其实就是一个yum配置文件,可以到/etc/yum.repo.d/里查看
[root@localhost ~]# yum -y install epel-release
2.安装erlang
[root@localhost ~]# yum -y install erlang
3.安装RabbitMQ
[root@localhost]# yum -y install rabbitmq-server
4.启动/停止
[root@localhost ~]# service rabbitmq-server start/stop
PYTHON API 安装
pip3 install pika
PYTHON 操作 rabbitMQ:
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
最基本的生产者消费者:
生产者代码:
import pika
# 连接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
# 创建频道
channel = connection.channel()
# 创建一个队列名叫hello
channel.queue_declare(queue='hello')
# exchange -- 它使我们能够确切地指定消息应该到哪个队列去。
# 向队列插入数值 routing_key是队列名 body是要插入的内容
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print("发送消息到队列里")
#缓冲区已经flush而且消息已经确认发送到了RabbitMQ中,关闭链接
connection.close()
消费者代码:
import pika
# 连接接rabbit
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
# 创建频道
channel = connection.channel()
# 如果生产者没有运行创建队列,那么消费者也许就找不到队列了。为了避免这个问题
# 所有消费者也创建这个队列,如果这个队列存在,这条语句就不起作用了
channel.queue_declare(queue='hello')
# 接收消息需要使用callback这个函数来接收,他会被pika库来调用
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 从队列取数据 callback是回调函数 如果拿到数据 那么将执行callback函数
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print(' [*] 等待信息. To exit press CTRL+C')
# 永远循环等待数据处理和callback处理的数据
channel.start_consuming()
acknowledgment消息不丢失
no-ack = False,如果消费者遇到情况(its channel is closed, connection is closed, or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。
生产者代码不变。
消费者:
import pika
# 链接rabbit
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
# 创建频道
channel = connection.channel()
# 如果生产者没有运行创建队列,那么消费者创建队列
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print 'ok'
# 主要使用此代码 手动回复ACK
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
durable消息不丢失(持久化)
生产者:
import pika
# 连接rabbit服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
# 创建频道
channel = connection.channel()
# 创建队列,使用durable方法
channel.queue_declare(queue='hello', durable=True)
#如果想让队列实现持久化那么加上durable=True
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode=2,
# 标记我们的消息为持久化的 - 通过设置 delivery_mode 属性为 2
# 这样必须设置,让消息实现持久化
))
# 这个exchange参数就是这个exchange的名字. 空字符串标识默认的或者匿名的exchange:如果存在routing_key, 消息路由到routing_key指定的队列中。
print(" [x] 开始队列'")
connection.close()
消费者:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
# 创建频道
channel = connection.channel()
# 创建队列,使用durable方法
channel.queue_declare(queue='hello', durable=True)
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print 'ok'
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] 等待队列. To exit press CTRL+C')
channel.start_consuming()
消息获取顺序
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者2去队列中获取 偶数 序列的任务。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列。
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello'durable=True) # 设置队列持久化
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print 'ok'
# 消息未处理完前不要发送信息的消息
ch.basic_ack(delivery_tag = method.delivery_tag)
# 表示谁来谁取,不再按照奇偶数排列
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
发布订阅

发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
exchange type = fanout
发布者:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r" % message)
connection.close()
订阅者:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='logs',
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
关键字发送
exchange type = direct
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。

发送者:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
订阅者:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
模糊匹配
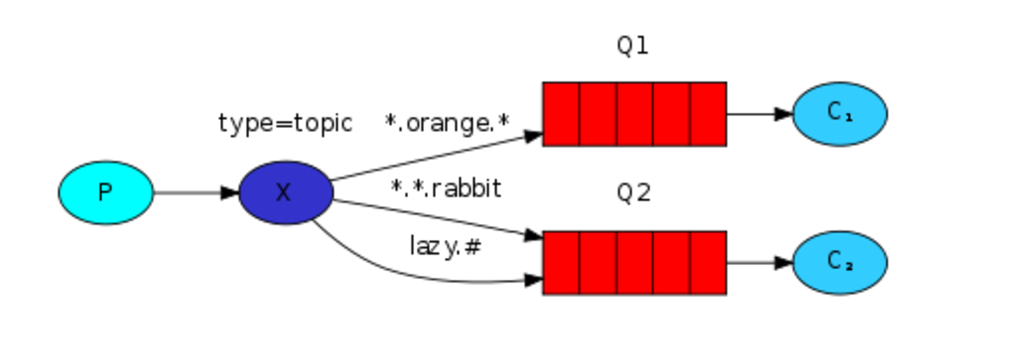
exchange type = topic
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
- # 表示可以匹配0个或多个单词
- * 表示只能匹配一个单词
发送者路由值 队列中
old.boy.python old.* -- 不匹配
old.boy.python old.# -- 匹配
发送者:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
订阅者:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
Python之路第十二天,高级(4)-Python操作rabbitMQ的更多相关文章
- Python之路【第一篇】python基础
一.python开发 1.开发: 1)高级语言:python .Java .PHP. C# Go ruby c++ ===>字节码 2)低级语言:c .汇编 2.语言之间的对比: 1)py ...
- 【Python之路】第二篇--初识Python
Python简介 Python可以应用于众多领域,如:数据分析.组件集成.网络服务.图像处理.数值计算和科学计算等众多领域.目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube.D ...
- Python之路【第一篇】:Python简介和入门
python简介: 一.什么是python Python(英国发音:/ pa θ n/ 美国发音:/ pa θɑ n/),是一种面向对象.直译式的计算机程序语言. 每一门语言都有自己的哲学: pyth ...
- 【Python之路】第六篇--Python基础之模块
模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要多个函数才 ...
- Python之路【第九篇】:Python面向对象
阅读目录 一.三大编程范式 编程范式即编程的方法论,标识一种编程风格: 大家学习了基本的python语法后,大家可以写python代码了,然后每个人写代码的风格不同,这些不同的风格就代表了不同的流派: ...
- Python之路第十二天,高级(5)-Python操作Mysql,SqlAlchemy
Mysql基础 一.安装 Windows: 1.下载 http://dev.mysql.com/get/Downloads/MySQL-5.6/mysql-5.6.31-winx64.zip 2.解压 ...
- Python之路第十二天,高级(6)-paramiko
paramiko 一.安装 pip3 install paramiko 二.使用 SSHClient 用于连接远程服务器并执行基本命令 1. 基于用户和密码链接 import paramiko # 创 ...
- 【Python之路】第八篇--Python基础之网络编程
Socket socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过"套接字"向网络发出请求或者应答网络请求. sock ...
- Python之路,第一篇:Python入门与基础
第一篇:Python入门与基础 1,什么是python? Python 是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言. 2,python的特征: (1)易于学习,易于利用: (2)开 ...
随机推荐
- Lua 字符串 匹配模式 总结
字符类 %a --字母alpha %d --数字double %l --小写字母lower %u --大写字母upper %w --字母和数字word %x -- 十六进制 %z --代表0 zero ...
- python 学习(三)
按照上次python 学习(二)的思路,第一步要实现从一个网站的页面上自动获取指定列表中的信息.折腾数日,得到一段可以正常运行的代码,如下: #web2.py import re import url ...
- Max Min
def main(): n = int(raw_input()) k = int(raw_input()) k_arr = [] min_dif = 9999999999 # 根据input要求,规定 ...
- MVC过滤器详解和示例
原文 http://blog.csdn.net/ankeyuan/article/details/29624005 MVC过滤器一共分为四个:ActionFilter(方法过滤器),ResultFi ...
- 深入理解Azure自动扩展集VMSS(2)
VMSS中Auto Scale基本原理及诊断 在前面的介绍中,我们看到通过定义规则可以实现虚拟机扩展集的auto scale,那么在后台执行上VMSS的扩展依赖于哪些组件,出现问题(比如自动扩展没有发 ...
- tomcat server.xml 配置示例
规划: 网站网页目录:/web/www 域名:www.test1.com 论坛网页目录:/web/bbs URL:bbs.test1.com/bbs 网站管理 ...
- [TYVJ] P1005 采药
采药 背景 Background NOIP2005复赛普及组第三题 描述 Description 辰辰是个天资聪颖的孩子,他的梦想是成为世界上最伟大的医师.为此,他想拜附近最有威望的医师为师.医师 ...
- 记事本创建servlet在tomcat中发布基本思路
在webapps中新建文件夹H,在其中再创建WEB-INF文件夹,在创建classes文件夹和web.xml文件,web.xml需要配置一下,classes文件夹中存放Servlet经编译过的clas ...
- Effective Java2读书笔记-对于所有对象都通用的方法(三)
第12条:考虑实现Comparable接口 这一条非常简单.就是说,如果类实现了Comparable接口,覆盖comparaTo方法. 就可以使用Arrays.sort(a)对数组a进行排序. 它与e ...
- PostgreSQL与MySQL比较(转)
Mysql 使用太广泛了,以至于我不得不将一些应用从mysql 迁移到postgresql, 很多开源软件都是以Mysql 作为数据库标准,并且以Mysql 作为抽象基础的,但是具体使用过程中,发现M ...