自然语言26_perplexity信息
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

http://www.ithao123.cn/content-296918.html参考
Python 文本挖掘:简单的自然语言统计
2015-05-12 浏览(141)
[摘要:首要应用NLTK (Natural Language Toolkit)顺序包。 实在,之前正在用呆板进修方式剖析情绪的时间便已应用了简略的天然说话处置惩罚及统计。比方把分词后的文本变成单词拆配(或叫单词序]
其实,之前在用机器学习方法分析情感的时候就已经使用了简单的自然语言处理及统计。比如把分词后的文本变为双词搭配(或者叫双词序列),找出语料中出现频率最高的词,使用一定的统计方法找出信息量最丰富的词。回顾一下。
import nltk
example_1 = ['I','am','a','big','apple','.']
print nltk.bigrams(example_1)
>> [('I', 'am'), ('am', 'a'), ('a', 'big'), ('big', 'apple'), ('apple', '.')]
print nltk.trigrams(example)
>> [('I', 'am', 'a'), ('am', 'a', 'big'), ('a', 'big', 'apple'), ('big', 'apple', '.')]
from nltk.probability import FreqDist
example_2 = ['I','am','a','big','apple','.','I','am','delicious',',','I','smells','good','.','I','taste','good','.']
fdist = FreqDist(word for word in example_2) #把文本转化成词和词频的字典
print fdist.keys() #词按出现频率由高到低排列
>> ['I', '.', 'am', 'good', ',', 'a', 'apple', 'big', 'delicious', 'smells', 'taste']
print fdist.values() #语料中每个词的出现次数倒序排列
>> [4, 3, 2, 2, 1, 1, 1, 1, 1, 1, 1]
import nltk
from nltk.collocations import BigramCollocationFinder
from nltk.metrics import BigramAssocMeasures
bigrams = BigramCollocationFinder.from_words(example_2)
most_informative_chisq_bigrams = bigrams.nbest(BigramAssocMeasures.chi_sq, 3) #使用卡方统计法找
most_informative_pmi_bigrams = bigrams.nbest(BigramAssocMeasures.pmi, 3) #使用互信息方法找
print most_informative_chisq_bigrams
>> [('a', 'big'), ('big', 'apple'), ('delicious', ',')]
print most_informative_pmi_bigrams
>> [('a', 'big'), ('big', 'apple'), ('delicious', ',')]
sent_num = len(sents)
word_num = len(words)
import jieba.posseg
def postagger(sentence, para):
pos_data = jieba.posseg.cut(sentence)
pos_list = []
for w in pos_data:
pos_list.append((w.word, w.flag)) #make every word and tag as a tuple and add them to a list
return pos_list
def count_adj_adv(all_review): #只统计形容词、副词和动词的数量
adj_adv_num = []
a = 0
d = 0
v = 0
for review in all_review:
pos = tp.postagger(review, 'list')
for i in pos:
if i[1] == 'a':
a += 1
elif i[1] == 'd':
d += 1
elif i[1] == 'v':
v += 1
adj_adv_num.append((a, d, v))
a = 0
d = 0
v = 0
return adj_adv_num
from nltk.model.ngram import NgramModel
example_3 = [['I','am','a','big','apple','.'], ['I','am','delicious',','], ['I','smells','good','.','I','taste','good','.']]
train = list(itertools.chain(*example_3)) #把数据变成一个一维数组,用以训练模型
ent_per_model = NgramModel(1, train, estimator=None) #训练一元模型,该模型可计算信息熵和困惑值
def entropy_perplexity(model, dataset):
ep = []
for r in dataset:
ent = model.entropy(r)
per = model.perplexity(r)
ep.append((ent, per))
return ep
Python 文本挖掘:简单的自然语言统计
2015-05-12 浏览(141)
[摘要:首要应用NLTK (Natural Language Toolkit)顺序包。 实在,之前正在用呆板进修方式剖析情绪的时间便已应用了简略的天然说话处置惩罚及统计。比方把分词后的文本变成单词拆配(或叫单词序]
其实,之前在用机器学习方法分析情感的时候就已经使用了简单的自然语言处理及统计。比如把分词后的文本变为双词搭配(或者叫双词序列),找出语料中出现频率最高的词,使用一定的统计方法找出信息量最丰富的词。回顾一下。
import nltk
example_1 = ['I','am','a','big','apple','.']
print nltk.bigrams(example_1)
>> [('I', 'am'), ('am', 'a'), ('a', 'big'), ('big', 'apple'), ('apple', '.')]
print nltk.trigrams(example)
>> [('I', 'am', 'a'), ('am', 'a', 'big'), ('a', 'big', 'apple'), ('big', 'apple', '.')]
from nltk.probability import FreqDist
example_2 = ['I','am','a','big','apple','.','I','am','delicious',',','I','smells','good','.','I','taste','good','.']
fdist = FreqDist(word for word in example_2) #把文本转化成词和词频的字典
print fdist.keys() #词按出现频率由高到低排列
>> ['I', '.', 'am', 'good', ',', 'a', 'apple', 'big', 'delicious', 'smells', 'taste']
print fdist.values() #语料中每个词的出现次数倒序排列
>> [4, 3, 2, 2, 1, 1, 1, 1, 1, 1, 1]
import nltk
from nltk.collocations import BigramCollocationFinder
from nltk.metrics import BigramAssocMeasures
bigrams = BigramCollocationFinder.from_words(example_2)
most_informative_chisq_bigrams = bigrams.nbest(BigramAssocMeasures.chi_sq, 3) #使用卡方统计法找
most_informative_pmi_bigrams = bigrams.nbest(BigramAssocMeasures.pmi, 3) #使用互信息方法找
print most_informative_chisq_bigrams
>> [('a', 'big'), ('big', 'apple'), ('delicious', ',')]
print most_informative_pmi_bigrams
>> [('a', 'big'), ('big', 'apple'), ('delicious', ',')]
sent_num = len(sents)
word_num = len(words)
import jieba.posseg
def postagger(sentence, para):
pos_data = jieba.posseg.cut(sentence)
pos_list = []
for w in pos_data:
pos_list.append((w.word, w.flag)) #make every word and tag as a tuple and add them to a list
return pos_list
def count_adj_adv(all_review): #只统计形容词、副词和动词的数量
adj_adv_num = []
a = 0
d = 0
v = 0
for review in all_review:
pos = tp.postagger(review, 'list')
for i in pos:
if i[1] == 'a':
a += 1
elif i[1] == 'd':
d += 1
elif i[1] == 'v':
v += 1
adj_adv_num.append((a, d, v))
a = 0
d = 0
v = 0
return adj_adv_num
from nltk.model.ngram import NgramModel
example_3 = [['I','am','a','big','apple','.'], ['I','am','delicious',','], ['I','smells','good','.','I','taste','good','.']]
train = list(itertools.chain(*example_3)) #把数据变成一个一维数组,用以训练模型
ent_per_model = NgramModel(1, train, estimator=None) #训练一元模型,该模型可计算信息熵和困惑值
def entropy_perplexity(model, dataset):
ep = []
for r in dataset:
ent = model.entropy(r)
per = model.perplexity(r)
ep.append((ent, per))
return ep
print entropy_perplexity(ent_per_model, example_3)
>> [(4.152825201361557, 17.787911185335403), (4.170127240384194, 18.002523441208137),
Entropy and Information Gain
import math,nltk
def entropy(labels):
freqdist = nltk.FreqDist(labels)
probs = [freqdist.freq(l) for l in freqdist]
return -sum(p * math.log(p,2) for p in probs)
As was mentioned before, there are several methods for identifying the most informative feature for a decision stump. One popular alternative, called information gain, measures how much more organized the input values become when we divide them up using a given feature. To measure how disorganized the original set of input values are, we calculate entropy of their labels, which will be high if the input values have highly varied labels, and low if many input values all have the same label. In particular, entropy is defined as the sum of the probability of each label times the log probability of that same label:
| (1) | H = −Σl |in| labelsP(l) × log2P(l). |
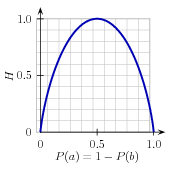
Figure 4.2: The entropy of labels in the name gender prediction task, as a function of the percentage of names in a given set that are male.
For example, 4.2 shows how the entropy of labels in the name gender prediction task depends on the ratio of male to female names. Note that if most input values have the same label (e.g., if P(male) is near 0 or near 1), then entropy is low. In particular, labels that have low frequency do not contribute much to the entropy (since P(l) is small), and labels with high frequency also do not contribute much to the entropy (since log2P(l) is small). On the other hand, if the input values have a wide variety of labels, then there are many labels with a "medium" frequency, where neither P(l) nor log2P(l) is small, so the entropy is high. 4.3 demonstrates how to calculate the entropy of a list of labels.
|
||
|
||
|
Example 4.3 (code_entropy.py): Figure 4.3: Calculating the Entropy of a List of Labels |
Once we have calculated the entropy of the original set of input values' labels, we can determine how much more organized the labels become once we apply the decision stump. To do so, we calculate the entropy for each of the decision stump's leaves, and take the average of those leaf entropy values (weighted by the number of samples in each leaf). The information gain is then equal to the original entropy minus this new, reduced entropy. The higher the information gain, the better job the decision stump does of dividing the input values into coherent groups, so we can build decision trees by selecting the decision stumps with the highest information gain.
Another consideration for decision trees is efficiency. The simple algorithm for selecting decision stumps described above must construct a candidate decision stump for every possible feature, and this process must be repeated for every node in the constructed decision tree. A number of algorithms have been developed to cut down on the training time by storing and reusing information about previously evaluated examples.
Decision trees have a number of useful qualities. To begin with, they're simple to understand, and easy to interpret. This is especially true near the top of the decision tree, where it is usually possible for the learning algorithm to find very useful features. Decision trees are especially well suited to cases where many hierarchical categorical distinctions can be made. For example, decision trees can be very effective at capturing phylogeny trees.
However, decision trees also have a few disadvantages. One problem is that, since each branch in the decision tree splits the training data, the amount of training data available to train nodes lower in the tree can become quite small. As a result, these lower decision nodes may
overfit the training set, learning patterns that reflect idiosyncrasies of the training set rather than linguistically significant patterns in the underlying problem. One solution to this problem is to stop dividing nodes once the amount of training data becomes too small. Another solution is to grow a full decision tree, but then to prune decision nodes that do not improve performance on a dev-test.
A second problem with decision trees is that they force features to be checked in a specific order, even when features may act relatively independently of one another. For example, when classifying documents into topics (such as sports, automotive, or murder mystery), features such as hasword(football) are highly indicative of a specific label, regardless of what other the feature values are. Since there is limited space near the top of the decision tree, most of these features will need to be repeated on many different branches in the tree. And since the number of branches increases exponentially as we go down the tree, the amount of repetition can be very large.
A related problem is that decision trees are not good at making use of features that are weak predictors of the correct label. Since these features make relatively small incremental improvements, they tend to occur very low in the decision tree. But by the time the decision tree learner has descended far enough to use these features, there is not enough training data left to reliably determine what effect they should have. If we could instead look at the effect of these features across the entire training set, then we might be able to make some conclusions about how they should affect the choice of label.
The fact that decision trees require that features be checked in a specific order limits their ability to exploit features that are relatively independent of one another. The naive Bayes classification method, which we'll discuss next, overcomes this limitation by allowing all features to act "in parallel."
https://study.163.com/provider/400000000398149/index.htm?share=2&shareId=400000000398149(博主视频教学主页)

自然语言26_perplexity信息的更多相关文章
- 初学者如何查阅自然语言处理(NLP)领域学术资料
1. 国际学术组织.学术会议与学术论文 自然语言处理(natural language processing,NLP)在很大程度上与计算语言学(computational linguistics,CL ...
- 《数学之美》--第一章:文字和语言 vs 数字和信息
PDF下载 第一章 文字和语言 vs 数字和信息 数字.文字和自然语言一样,都是信息的载体,它们之间原本有着天然的联系.语言和数学的产生都是为了同一个目的-记录和传播信息.但是,直到半个多世纪前香农博 ...
- CS(计算机科学)知识体
附 录 A CS( 计算机科学)知识体 计算教程 2001 报告的这篇附录定义了计算机科学本科教学计划中可能讲授的知识领域.该分类方案的依据及其历史.结构和应用的其 ...
- java笔记整理
Java 笔记整理 包含内容 Unix Java 基础, 数据库(Oracle jdbc Hibernate pl/sql), web, JSP, Struts, Ajax Spring, E ...
- Atitit.自然语言处理--摘要算法---圣经章节旧约39卷概览bible overview v2 qa1.docx
Atitit.自然语言处理--摘要算法---圣经章节旧约39卷概览bible overview v2 qa1.docx 1. 摘要算法的大概流程2 2. 旧约圣经 (39卷)2 2.1. 与古兰经的对 ...
- Atitit attilax在自然语言处理领域的成果
Atitit attilax在自然语言处理领域的成果 1.1. 完整的自然语言架构方案(词汇,语法,文字的选型与搭配)1 1.2. 中文分词1 1.3. 全文检索1 1.4. 中文 阿拉伯文 英文的简 ...
- 自然语言20.1 WordNet介绍和使用 _
http://blog.csdn.net/ictextr9/article/details/4008703 Wordnet是一个词典.每个词语(word)可能有多个不同的语义,对应不同的sense.而 ...
- 自然语言21_Wordnet
QQ:231469242 欢迎喜欢nltk朋友交流 http://baike.baidu.com/link?url=YFVbJFMkZO9A5CAvtCoKbI609HxXXSFd8flFG_Lg ...
- 自然语言0_nltk中文使用和学习资料汇总
http://blog.csdn.net/huyoo/article/details/12188573 官方数据 http://www.nltk.org/book/ Natural Language ...
随机推荐
- Elasticsearch-HttpServerModule
HttpServerModule的请求主要由HttpServer中的HttpServerTransport(默认为NettyHttpServerTransport)类处理. NettyHttpServ ...
- [Java入门笔记] Java语言基础(二):常量、变量与数据类型
常量与变量 什么是常量和变量 常量与变量都是程序在运行时用来存储数据一块内存空间 常量: 常量的值在程序运行时不能被改变,Java中声明常量必须使用final关键字.常量还可以分为两种意思: 第1种意 ...
- 烂泥:openvpn配置文件详解
本文由秀依林枫提供友情赞助,首发于烂泥行天下 在上一篇文章<烂泥:ubuntu 14.04搭建OpenVPN服务器>中,我们主要讲解了openvpn的搭建与使用,这篇文章我们来详细介绍下有 ...
- strcpy 函数的实现
原型声明:extern char *strcpy(char *dest,const char *src); 头文件:string.h 功能:把从src地址开始且含有‘\0’结束符的字符串赋值到以d ...
- 3、DNS服务器功能(正向、反向解析)
实验目的: 建立gr.org域的主名称服务器.解析: 名称 IP 用途 ns.gr.org 192.168.170.3 名称服务器 www.gr.org 192 ...
- Microsoft Azure Point to Site VPN替代方案
Microsoft Azure提供了Point to Site VPN,但有时候这并不能满足我们的需求,例如:Point to Site VPN是SSTP VPN,只能支持Window客户端拨入,而且 ...
- Something Wrong or Something Right
其实,你还可以和高中一样 其实,你还可以和高中一样,每天不情愿的早早起床,走在冬天漆黑的清晨里.食堂还没有开门,你就去商店买面包和牛奶,接着快步走进教学楼,轻声咒骂一声老师要求的时间太早,然后打开一本 ...
- STL 堆
洛谷P3378 [模板]堆 #include <iostream> #include <cstdio> #include <algorithm> #include ...
- Jsp 错题分析
ArrayList删除元素通过RemoveAt(int index)来删除指定索引值的元素 运行时异常都是RuntimeException类及其子类异常,如NullPointerException.I ...
- redux的中间层 --reactjs学习
React只负责UI层,也就是我们通常在MVC框架中 所说的View层,所以在使用React开发中 我们得引入Redux 负责Model 一开始学习Redux的中间层 有点 摸不到头, 其实只要你注意 ...